Command Palette
Search for a command to run...
VibeVoice-Realtime TTS: リアルタイム音声合成サービス
1. チュートリアルの概要

VibeVoice-Realtime TTSは、Microsoft Researchチームが2025年12月にリリースしたストリーミング音声合成モデルVibeVoice-Realtime-0.5Bをベースに構築された、高品質なリアルタイム音声合成(TTS)システムです。このシステムは、長時間の複数話者音声合成における連続データをモデル化するために、革新的な次トークン拡散法を採用しています。また、効率的な連続音声セグメンターを導入することで、最大4人の話者をサポートし、64Kのコンテキストウィンドウ内で最大90分の音声を生成できます。これにより、音声の忠実度を維持し、リアルな会話の雰囲気を捉えながら、計算効率を大幅に向上させます。関連研究論文もご覧いただけます。 VibeVoice: 高忠実度マルチスピーカーストリーミングテキスト読み上げ このシステムは、複数話者による音声生成、低遅延のリアルタイム推論、および Grado Web インターフェースを介した視覚的なインタラクションをサポートします。
コア機能:
- 複数の話者によるリアルタイム音声合成
- ストリーミング推論、低レイテンシ出力
- 高忠実度24000Hz音声サンプリングレート
- CFGスケール制御発電をサポート
- GPUアクセラレーション推論
- 外部ネットワークに依存せずに、ローカルオフライン展開を完了します。
このチュートリアルでは、Gradoを用いてVibeVoice-Realtime-0.5Bコアモデルをデプロイします。「RTX_5090」コンピューティングリソースを採用しており、リアルタイム音声合成サービスの安定した運用をサポートします。このモデルは英語のテキスト入力のみをサポートします。
2. エフェクト表示
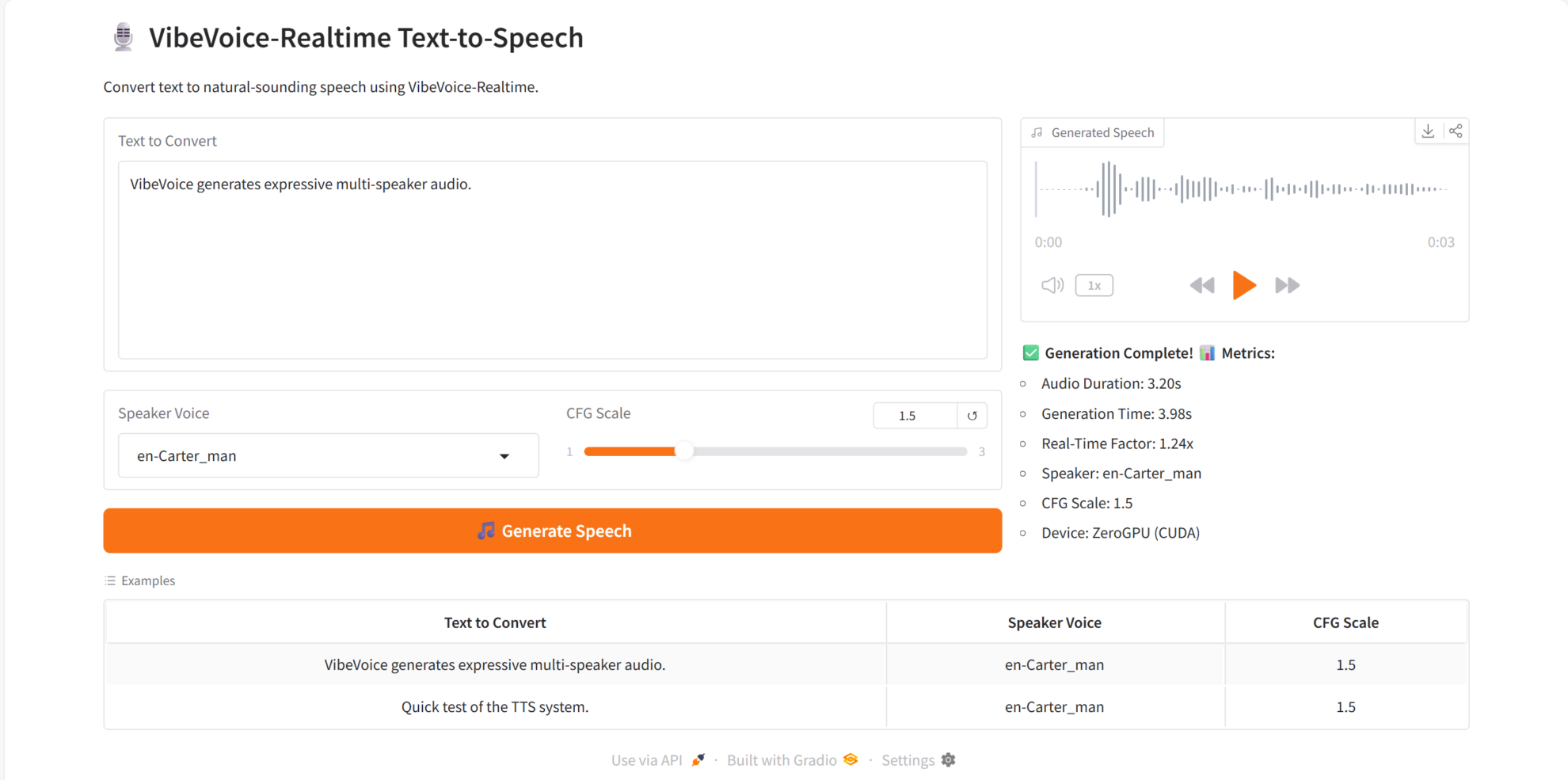
VibeVoice-Realtime は、コア機能において優れています。
- リアルタイム TTS: テキストを入力するとすぐに音声出力を生成します。
- マルチスピーカーのサポート: 同じテキストに対して異なる音声スタイルを切り替えることができます。
- 非常に自然な音声品質:クリアなサウンドと自然なイントネーション。
- 長いテキストの安定した合成: 明らかな句読点や歪みの問題はありません。
- 強力なリアルタイムインタラクティブ機能を備えており、対話システムや音声アシスタントなどのシナリオに適しています。
3. 操作手順
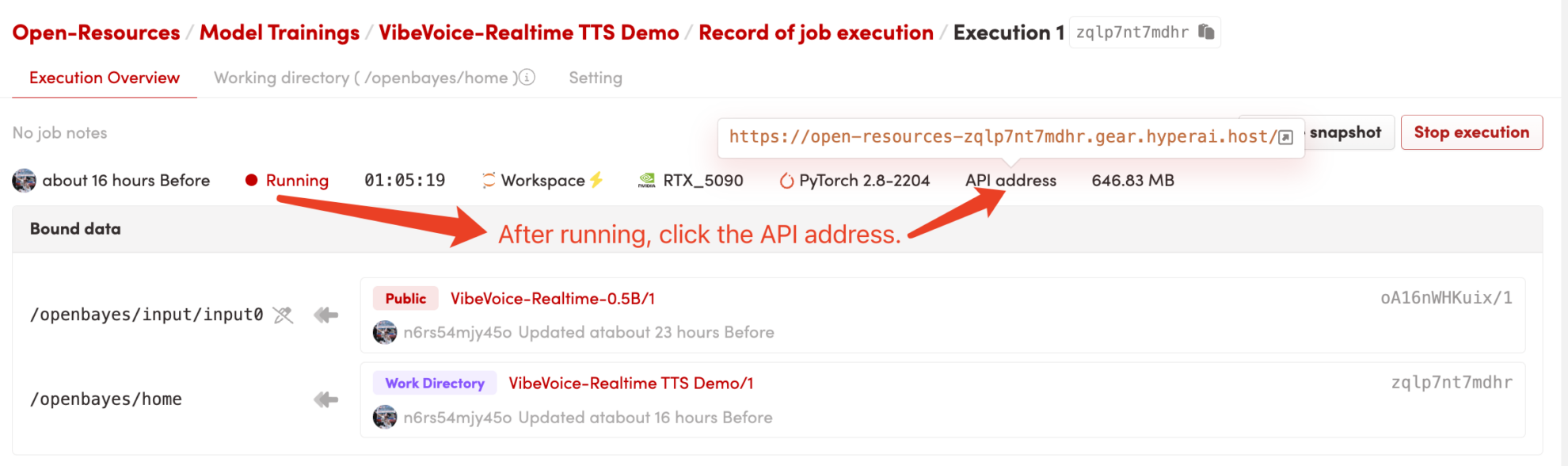
1. コンテナを起動します
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. はじめに
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルのサイズが大きいため、1~2分ほどお待ちいただいてからページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
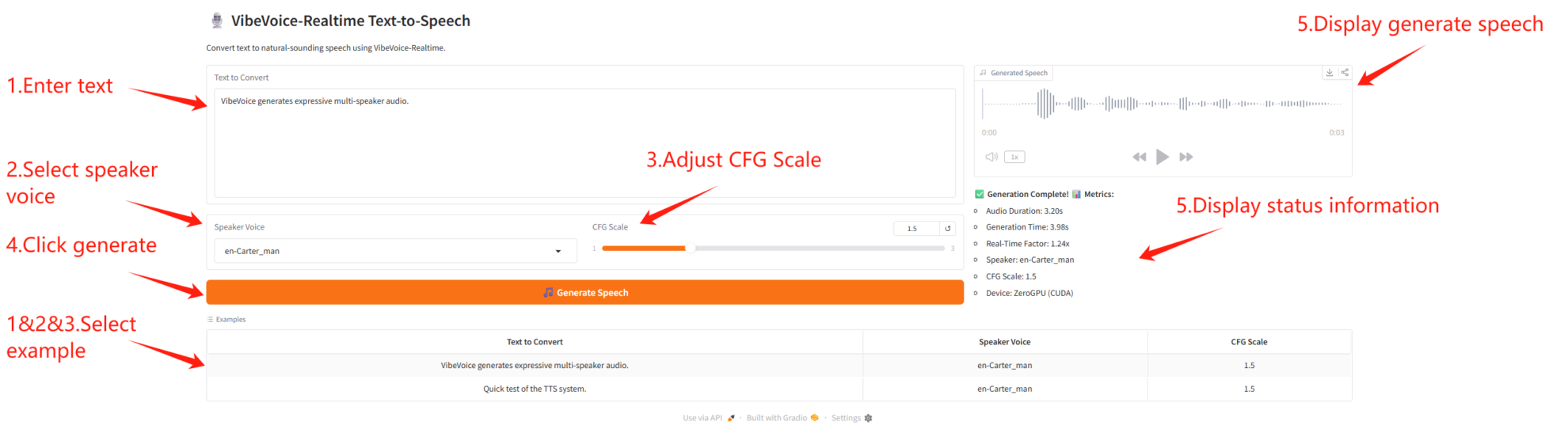
パラメータの説明
- 音声生成パラメータ
- CFG スケール: 話し方の強さを制御します。値が高いほど、感情が強くなります。
- スピーカーパラメータ
- スピーカーの音声: さまざまなスピーカーの音声を選択します。

引用情報
このプロジェクトの引用情報は次のとおりです。
@article{vibevoice2024,
title={VibeVoice: Real-Time Streaming Text-to-Speech with Multi-Speaker Support},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2412.08635},
year={2024}
}
@article{vibevoice2025,
title={VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2508.19205},
year={2025}
}