HyperAI
Command Palette
Search for a command to run...
PixelReasoner-RL: ピクセルレベルの視覚推論モデル
1. チュートリアルの概要
PixelReasoner-RL-v1は、TIGER AI Labが2025年5月にリリースした画期的な視覚言語モデルです。関連する研究論文は以下の通りです。 Pixel Reasoner: 好奇心主導型強化学習によるピクセル空間推論の促進 。
Qwen2.5-VLアーキテクチャをベースとするこのプロジェクトは、革新的な好奇心駆動型強化学習トレーニング手法により、テキストベースの推論のみに依存する従来の視覚言語モデルの限界を打ち破ります。PixelReasonerはピクセル空間で直接推論を実行できるため、スケーリングやフレーム選択などの視覚操作をサポートし、画像の詳細、空間関係、動画コンテンツの理解能力を大幅に向上させます。
コア機能:
- ピクセルレベルの推論: モデルは、画像のピクセル空間で直接分析および操作できます。
- グローバルな理解とローカルな理解を組み合わせることで、画像全体の内容を把握できると同時に、特定の領域にズームインして焦点を当てる機能も実現します。
- 好奇心主導型トレーニング: 好奇心の報酬メカニズムを導入して、モデルがピクセルレベルの操作を積極的に探索するように促します。
- 強化された推論能力: 小さな物体の認識や微妙な空間関係の理解など、複雑な視覚タスクで優れたパフォーマンスを発揮します。
このチュートリアルでは、Grado を使用して、単一の RTX 5090 カードのコンピューティング パワー リソースを備えた PixelReasoner-RL-v1 をデモとして展開します。
2. エフェクト表示
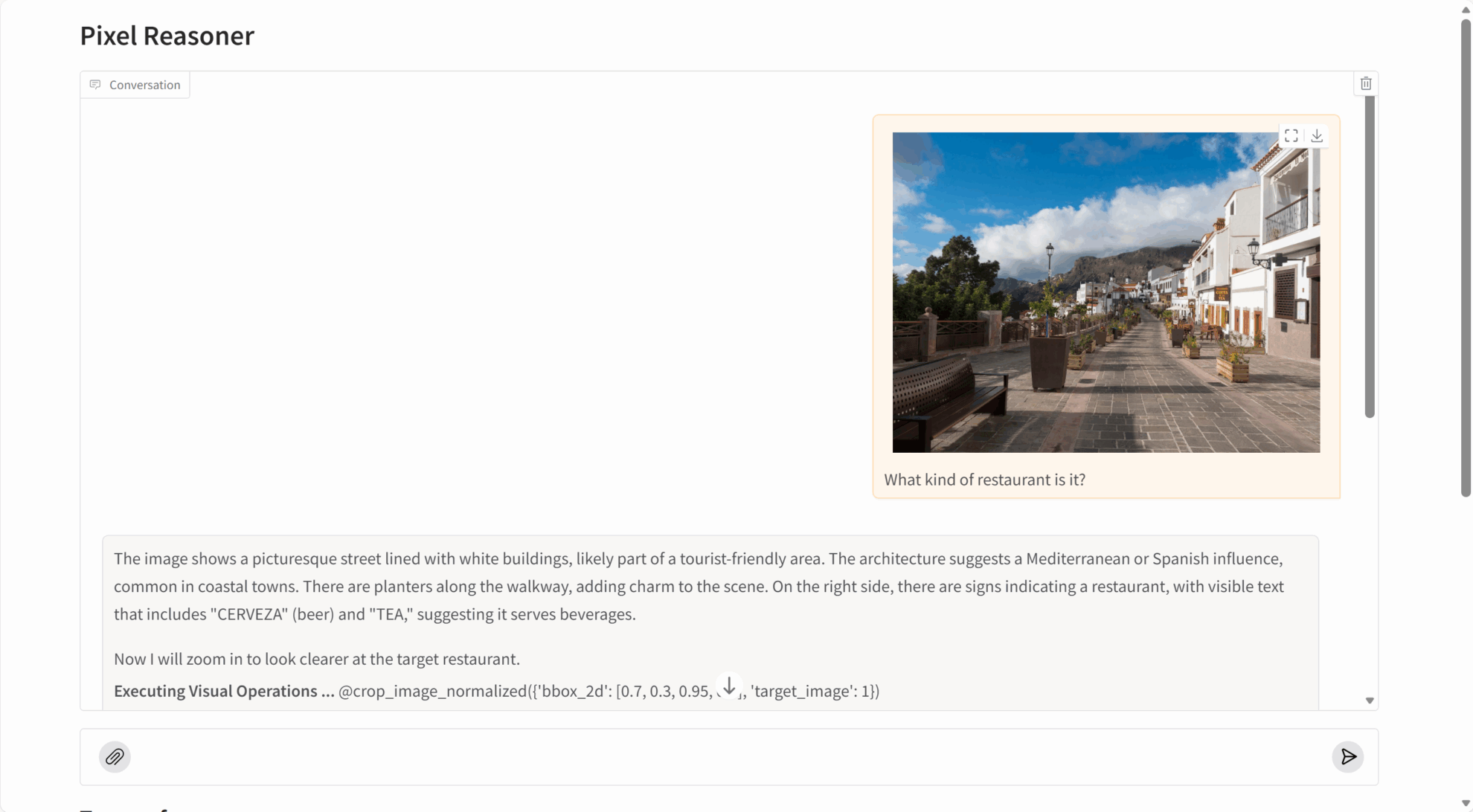
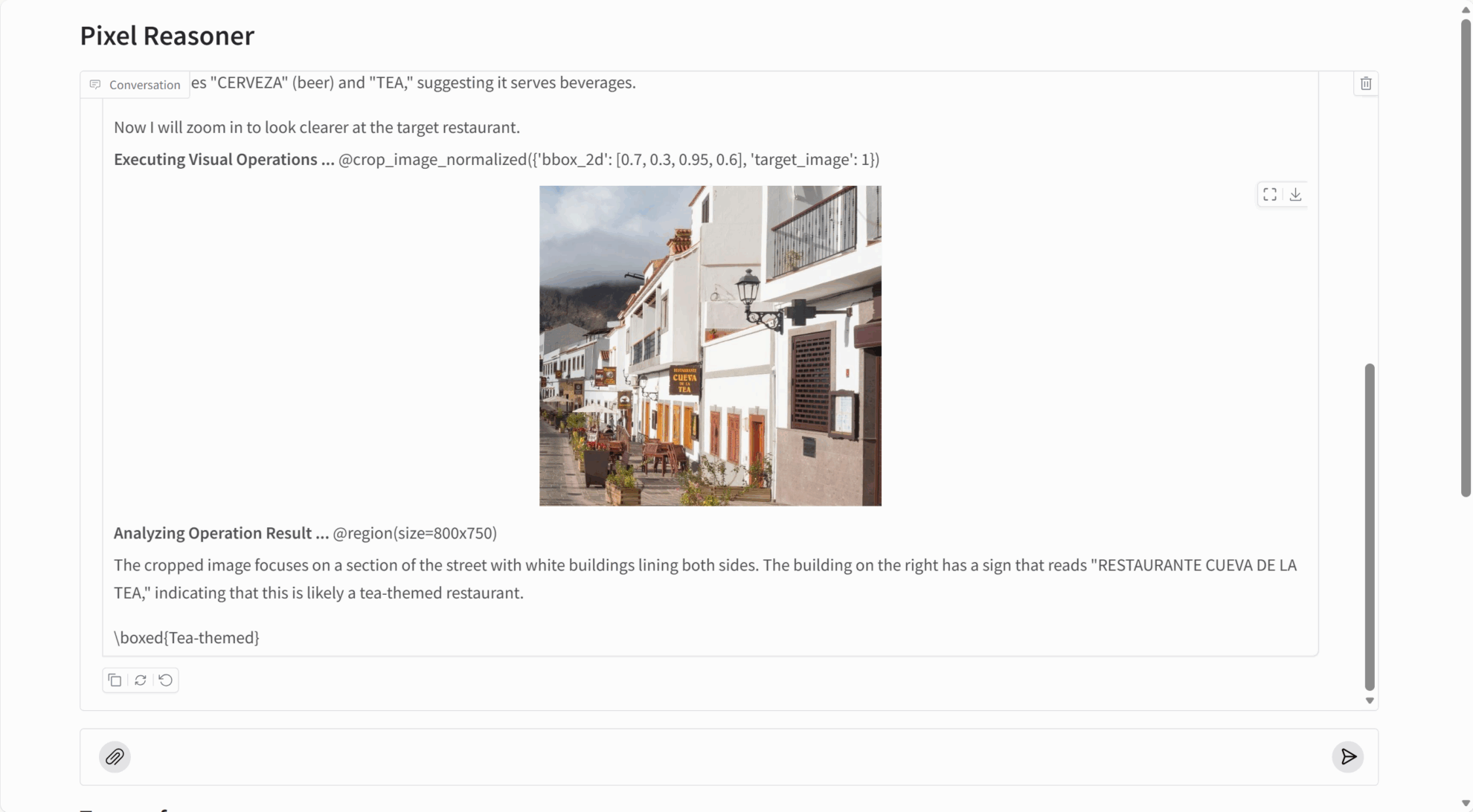
PixelReasoner-RL-v1 は、複数の視覚的推論タスクで非常に優れたパフォーマンスを発揮します。
- 画像理解: 画像の内容、オブジェクトの関係、シーンの詳細を正確に識別します。
- 詳細キャプチャ: 画像内の微細なオブジェクト、埋め込まれたテキスト、その他の細かい情報を検出できます。
- ビデオ分析: キーフレームを選択してビデオのコンテンツとアクション シーケンスを理解します。
- 空間的推論: 物体の空間的な位置と相対的な関係を正確に理解すること。
3. 操作手順
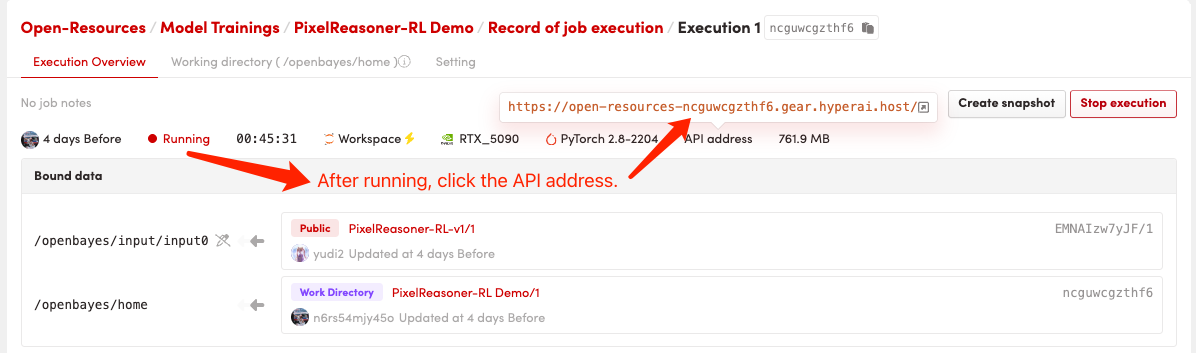
1. コンテナを起動します
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
初回起動には約2~3分かかりますので、しばらくお待ちください。デプロイが完了したら、「APIアドレス」をクリックしてGradoインターフェースに直接アクセスしてください。
2. はじめに
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{pixelreasoner2025,
title={Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning},
author={Su, Alex and Wang, Haozhe and Ren, Weiming and Lin, Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2505.15966},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
トピック
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています