Command Palette
Search for a command to run...
Googleの対話型医療システムAMIEは、Gemini 1.5の長い文脈認識能力を活用することで、複数回の患者診察を含む100のシナリオにおいて、一般開業医と同等の推論レベルを達成した。

大規模言語モデルは急速に医療分野に進出しており、その応用範囲は文献検索や診療記録作成から臨床意思決定支援まで多岐に渡る。こうした応用の中でも、診断支援は比較的成熟した分野の一つである。医学的に精緻化されたモデルは、病歴、身体所見、検査結果に基づいて質の高い鑑別診断を提供できる。また、複数ターン対話機能を備えたシステムは、診察形式の対話を通じて病歴情報を補完することも可能だ。
しかし、診断は臨床意思決定の出発点に過ぎません。治療の質に真に影響を与えるのは、多くの場合、診断後に下される管理上の決定です。例えば、追加検査が必要かどうか、治療計画をどのように選択するか、投薬量を調整するタイミング、フォローアップ診察のスケジュールをどのように組むか、そして患者の状態の変化に基づいて計画をどのように継続的に修正するかといったことです。このような「管理上の推論」こそが、実際の臨床業務の中核に近いと言えるでしょう。また、このモデルがエビデンスに基づいたガイドライン、臨床経路、薬剤に関する知識、そして個々の患者の違いを包括的に理解しているかどうかも、より厳しく問われることになる。
診断推論と比較すると、経営推論の評価はより困難である。診断問題には通常、比較的明確な標準的な解答が存在するが、経営上の意思決定には単一の解決策が存在しないことが多く、医療資源、ガイドライン、医薬品の入手可能性、医師の経験といった制約を受ける。現在、医学教育においてこの種の総合的な能力を評価する主な方法は客観的構造化臨床試験(OSCE)であるが、これは実際の人とのやり取りと専門家による採点に依存しているため、大規模な言語モデルの自動評価に直接適用することは難しい。
このギャップに対処するため、Google DeepMindとGoogle Researchは、対話型ヘルスケアシステムAMIEをベースとした、LLM(長文論理モデル)に基づく新たなインテリジェントエージェントシステムを開発しました。このシステムは、複数のフォローアップシナリオにおける臨床管理と医師・患者間の対話の最適化を可能にします。AMIEは、Geminiモデルの長文コンテキスト機能を活用し、コンテキスト内検索と構造化推論を組み合わせることで、最新の臨床診療ガイドラインや処方薬カタログに沿った出力を実現します。
無作為化二重盲検仮想客観的構造化臨床試験(OSCE)研究において、研究者らはAMIEを21名のプライマリケア医(PCP)と比較した。この試験は100の複数回受診シナリオを対象とし、症例設計は英国NICEガイドラインおよびBMJベストプラクティス臨床ガイドラインを参照した。結果は…専門家による疾患管理推論能力の評価において、AMIEは(劣らない)人間の医師と同等の成績を収めた。一方、AMIEは、治療計画や検査推奨の正確性、臨床ガイドラインへの遵守度、知識ベースの信頼性といった点で、医師グループよりも高いスコアを獲得した。
「疾病管理のための対話型AIに向けて」と題された関連研究成果は、科学誌『ネイチャー』に掲載された。
研究のハイライト:
* この研究は、対話型ヘルスケアシステムAMIEの機能を、単回の診断から、疾患の進行、複数回の受診決定、治療反応のフィードバック、投薬処方を含む完全なプロセス臨床管理推論へと発展させるものです。
* このシステムは、Geminiの長期コンテキスト機能を活用し、コンテキスト検索と構造化推論を組み合わせることで、管理プロトコルがNICEガイドラインやBMJのベストプラクティスなどの権威ある臨床知識と高い整合性を保つようにします。
* このシステムは、プロトコルの全体的な適切性、治療推奨の質、検査推奨の正確性など、複数の指標において、一般開業医と同等以上の性能を発揮しました。
論文を見る:
https://www.nature.com/articles/s41586-026-10764-5
データセット:単一の質問と回答から垂直的な臨床シナリオまで
対話型ヘルスケアAIの長期的な管理推論における実世界での能力を評価するため、研究チームは多層データシステムを構築した。本書は、複数回の通院を伴う臨床シナリオを網羅しており、エビデンスに基づいたガイドラインや薬剤に関する知識も取り入れている。モデルのトレーニング、スキームの生成、および標準化された評価に使用されます。
中核となる評価ツールは、「複数回訪問型仮想OSCEシナリオデータセット」である。この研究では、合計100件の独立した事例研究を収集した。症例は、心臓病学、呼吸器病学、産婦人科・泌尿器科、消化器病学、神経学・筋骨格医学の5つの専門分野に均等に配分され、各専門分野につき20症例ずつとなっている。すべての症例は、カナダとインドの臨床医が共同で設計し、NICE臨床ガイドラインおよびBMJベストプラクティスガイドラインの治療経路を参考に作成された。
通常の1ラウンドの医療Q&Aセッションとは異なり、これらのケースは3回の連続した診察を含むように設計されています。各シナリオには、患者の最初の訴えだけでなく、また、症状の経過、治療への反応、補助検査の結果報告など、長期的な情報も含まれています。その目的は、慢性疾患の管理や複雑な症例のフォローアップにおける、現実世界の意思決定プロセスを正確に反映することであった。臨床的な難易度を高めるため、一部の症例には情報の矛盾や複数の臓器に及ぶ併存疾患といった要素も組み込まれており、非標準的な条件下でのシステムの判断能力をテストした。本研究では、100件の正式な評価事例に加えて、事前実験とスコアリングの調整のために20件の検証シナリオも設定した。
このエビデンスに基づいたアプローチは、臨床ガイドラインの知識ベースから生まれています。この知識ベースには、527件のNICEガイドラインと100件のBMJベストプラクティス文書を含む、627件の文書が収録されています。総容量は約1050万トークンで、診断基準、検査手順、治療計画、フォローアップガイドラインなどを網羅しています。評価プロセス中、この知識ベースはAIシステムと参加する一般開業医の両方に公開され、実際の臨床現場でガイドライン資料を参照するシナリオをシミュレートし、人間と機械の比較における公平性を最大限に確保します。
薬剤に関する意思決定は、経営判断において不可欠な部分である。したがって、研究チームはRxQAのための特別なベンチマークも構築した。このベンチマークは、モデルが薬剤の指示、適応症、禁忌、投与量、および投薬リスクをどの程度理解しているかを評価するために使用されます。米国OpenFDAと英国国民医薬品集(National Formulary)の薬剤指示に基づいた600問の多肢選択式問題で構成されており、基本的な短い質問と、長いシナリオに基づく包括的な質問の2つのカテゴリに分かれています。質問の最初の草案は、指示に従ってジェミニモデルによって作成され、その後、両国の8人の薬剤師によってレビュー、修正、難易度評価が行われた。ライセンス上の制限により、OpenFDAから公開されている問題は現在300問のみであり、医薬品に関する推論能力を比較するための標準化された参照資料として提供されています。
AMIEモデル:システムが「対話機能」と「高度な管理機能」の両方を備えることを可能にする
本研究は、Googleが以前提案した対話型ヘルスケアシステムAMIEを基盤としており、経営上の推論ニーズに対応するための具体的な改良が加えられている。新しいシステムは、認知科学における「二過程理論」から着想を得た、デュアルエージェント協調アーキテクチャを採用している。一方のエージェントは、迅速かつ継続的な医師と患者間の対話を担当し、もう一方のエージェントは、より時間はかかるものの、より深い経営判断を担当する。基盤となるモデルは、リアルタイム応答速度と長コンテキスト推論能力のバランスを取るために、Gemini 1.5 Flashを統一的に使用しています。
具体的には、本システムは、対話エージェントとMx管理推論エージェントで構成されています。対話エージェントは「システム1」に近い役割を担い、患者とのリアルタイムのコミュニケーション、病歴の照会、治療計画の説明、対話中の患者の状態の維持などを担当します。一方、Mxエージェントは「システム2」に近い役割を担い、疾患に関する完全な情報と臨床ガイドラインに基づいて、構造化された追跡可能な管理計画を生成することを主な役割としています。両者は共有状態モジュールを介して情報を同期し、対話エージェントがいつでもMxの推論結果にアクセスできるようにすることで、自然なコミュニケーションを維持しながら、医療アドバイスに確かな指針を与えることを保証します。
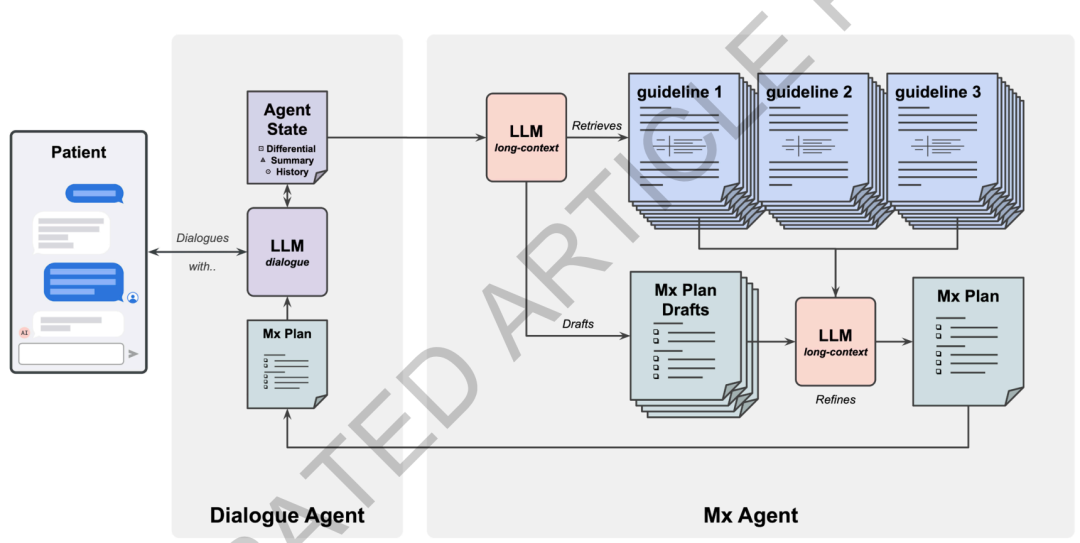
対話型ハブとして、この対話エージェントは、元の診断モデルと比較して3回のアップグレードを受けています。初め、基本モデルは、より長いコンテキスト処理機能を備えたGemini 1.5 Flashに置き換えられ、より長い医療記録や複数ターンにわたる対話情報を処理できるようになりました。2番、トレーニングデータには、疾患の進行と長期的な管理に対するシステムの理解を深めるために、複数の模擬医療相談が含まれていた。三番目、教師あり微調整の後、本研究ではさらに、対話の質と意思決定のパフォーマンスを最適化するために、人間とAIの両方からのフィードバックに基づく強化学習を組み込んだ。
リアルタイム推論において、対話エージェントは「計画-生成-洗練」という3段階のプロセスを採用する。まず、現在の状況に基づいて相談や対応の次のステップを計画し、次に患者向けに自然言語による応答を生成し、最後に自己チェックと修正を行います。また、異なる患者の診察にわたる継続的な管理をサポートするため、患者概要、鑑別診断、現在の治療計画などの情報を含むモジュール式のステータス構造を維持し、会話ごとに最初からやり直す必要がないようにバックグラウンドで継続的に更新します。
Mxエージェントは、システム全体の中核となるモジュールであり、高度な管理推論を担っています。Gemini 1.5 Flashの長文コンテキスト機能を最大限に活用し、「粗い検索+完全なコンテキスト推論」という戦略を採用しています。従来のチャンク検索によって生じる情報断片化を最小限に抑えるため、本システムはまずGecko 1B埋め込みモデルを用いてすべてのガイドライン文書をインデックス化します。次に、現在の患者の症例に基づいて自然言語クエリを生成し、ガイドラインライブラリから関連性の高い完全な文書を約6件(合計約25万6000トークン)選択します。その後、システムはこれらの全文ガイドラインと患者の完全な病歴をモデルに入力し、単一の呼び出しで文書と段階を横断した包括的な推論を実行できるようにします。
出力の使いやすさと監査可能性を向上させるため、MxエージェントはJSONスキーマ制約を使用して結果を生成し、「臨床状況の分析 - 管理目標の設定 - 管理手順の策定とガイドライン出典の引用」というフレームワークに従って出力します。各提案には、対応するガイドラインの引用を添える必要があります。同時に、システムはまず4つの管理案を独立して生成し、その後、元のガイドラインテキストに基づいてそれらを統合および改善することで、最終的な解決策の完全性と適応性を向上させます。
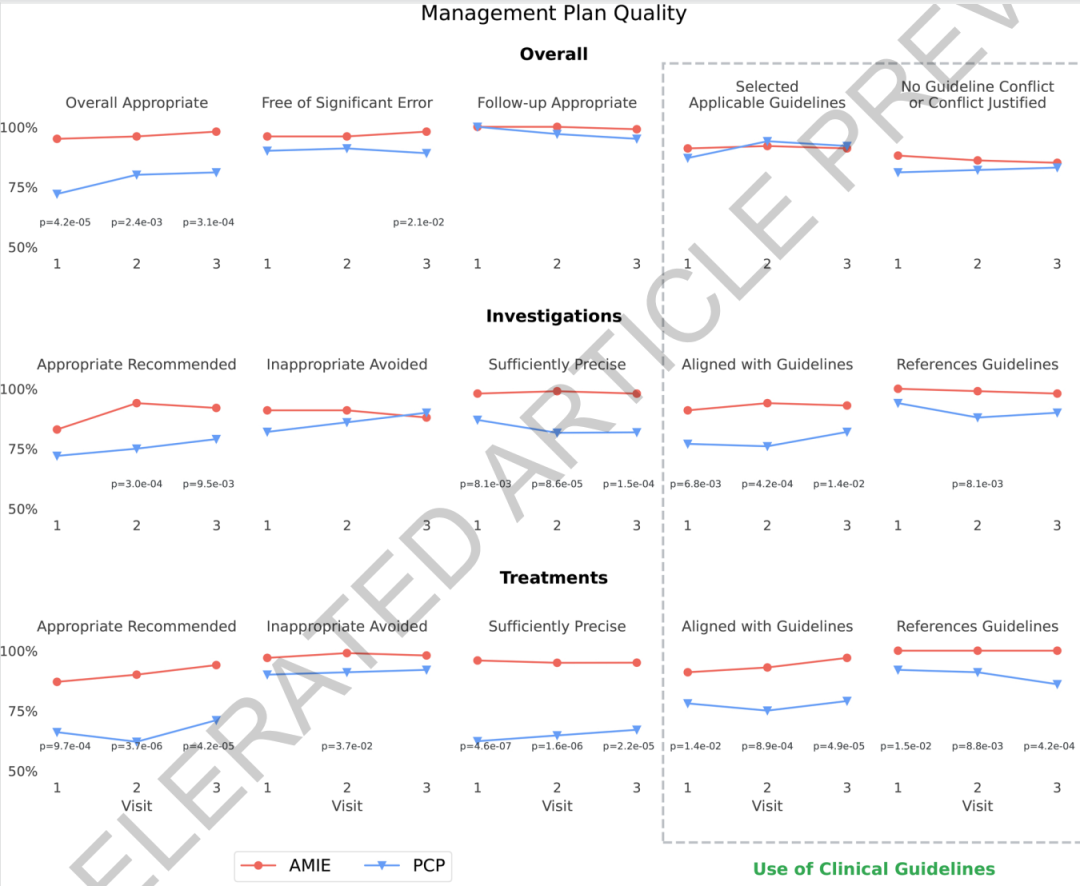
15の指標すべてにおいて、一般開業医に劣ることはなかった。
改良されたシステムの臨床管理推論能力を検証するために、本研究では、ランダム化盲検仮想OSCEフレームワークとRxQA薬剤ベンチマークテストを組み合わせた手法を用いた。AMIEシステムは、21人の一般開業医と比較された。総合的な評価は、管理計画の全体的な質、調査に関する推奨事項の質、および治療に関する推奨事項の質という3つの側面を中心に行われます。
臨床評価においては、全身療法医と一般開業医の両方が、複数の外来症例からなる100セットの診療を完了する必要がある。 30名の専門医と標準化患者が、専門性および患者体験という2つの観点から盲検評価を実施した。これは、評価者が治療計画がAIシステムによるものか人間の医師によるものかを知ることができないようにすることで、結果に対するアイデンティティバイアスの影響を最小限に抑えたことを意味する。薬剤試験では、外部データがシステムと医師のパフォーマンスに影響を与えるかどうかを観察するために、クローズドブック環境とオープンブック環境の両方が用いられた。
結果は次のようになります。治療計画の全体的な質という点では、このシステムは15の評価項目すべてにおいて一般開業医に劣ることはなく、多くの指標で統計的に優位性を示している。治療計画全体の適切性を例にとると、システムは3回の診察でそれぞれ95%、96%、98%のスコアを獲得し、一般開業医のスコアである72%、80%、81%を上回りました。治療推奨の適切性についても、システムはそれぞれ87%、90%、94%のスコアを獲得し、こちらも一般開業医のスコアである66%、62%、71%を上回りました。
このシステムは、検査および治療に関する推奨事項の精度においても、一貫して優位性を示している。その治療推奨の正確率は一貫して95%を超えているのに対し、一般開業医の正確率は62%から67%の間である。ガイドライン遵守に関して言えば、各推奨事項に明示的な引用が必要となるため、システムのトレーサビリティは人間の医師よりもはるかに優れている。この結果は、長文脈推論と元のガイドラインテキストの統合メカニズムが、複雑な管理タスクにおけるモデルの安定性と解釈性の向上に役立つ可能性を示唆している。
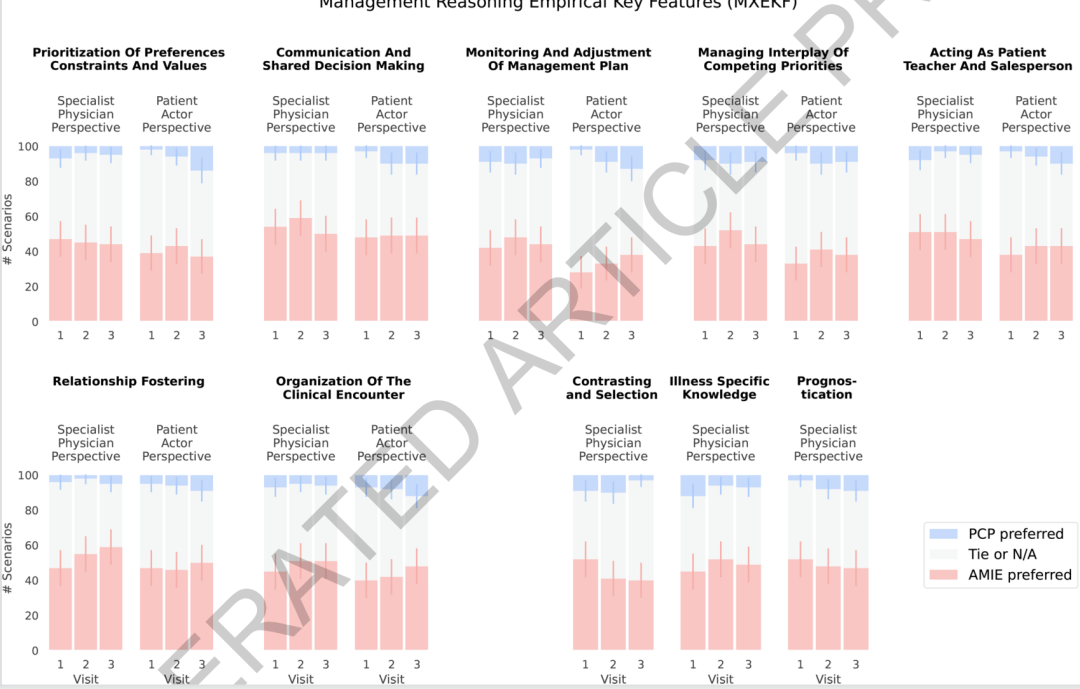
二重視点による選好評価において、本研究は経営判断の10の主要な側面を網羅し、51組の比較を行った。その結果、ほぼ半数のケースで、専門家と患者の両方が自身のパフォーマンスを同等と評価した。明確な選好が見られたケースでは、システムの勝率は47%であり、一般開業医の7%よりも大幅に高かった。さらに注目すべきは、専門医と患者の評価傾向が概ね一致していることであり、これはこのシステムの利点が専門家の判断だけでなく、患者の体験に関連する側面にも反映されていることを示している。
受診回数が増えるにつれて、動的なモニタリング、患者の流れ、医師と患者の関係といった時間的側面における本システムの利点がより明確になる。これは、研究の当初の目的と一致する。すなわち、推論管理の難しさは、単一の答えが正しいかどうかではなく、患者の状態の変化、治療に関するフィードバック、そして治療計画における次のステップを継続的に結びつける能力にあるということである。
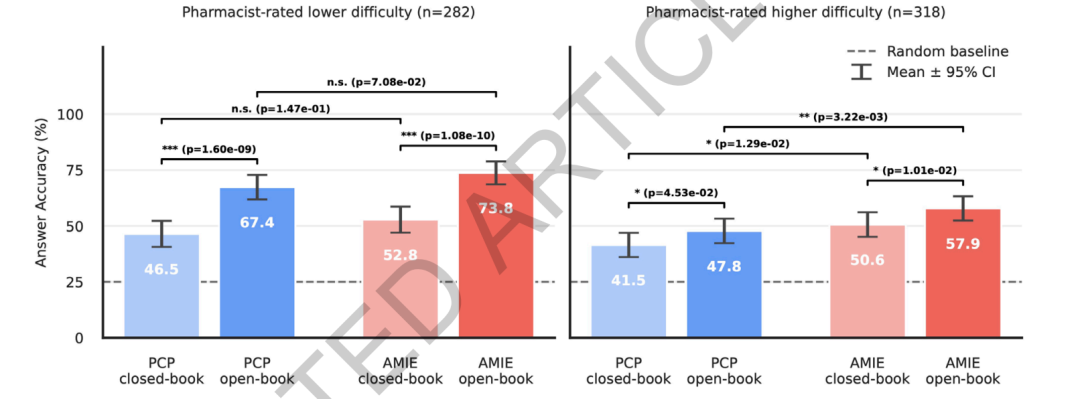
薬物に関する推論の観点から言えば、RxQAのベンチマークによると、このシステムは薬剤師が評価する非常に難しい質問において、一般開業医よりも優れた成績を収めている。資料が制限された環境では、システムの正答率は50.61 TP3T、一般開業医の正答率は41.51 TP3Tでした。資料が制限された環境では、システムの正答率は57.91 TP3T、一般開業医の正答率は47.81 TP3Tでした。簡単な質問については、両方法に有意差はありませんでした。資料が制限された環境は、システムと医師の両方にとって有益であり、特に簡単な質問では正答率が20パーセントポイント以上向上しました。難しい質問では改善幅は小さくなりましたが、統計的に有意でした。これは、複雑な薬剤情報統合タスクにおいて、このモデルが一定の相対的優位性を持っていることを示していますが、外部資料だけでは、非常に難しい薬剤推論問題を完全に解決することはできません。
最後に書きます
この研究の価値は、大規模な医療モデルが医師に取って代わることができることを証明することにあるのではなく、評価の焦点を「診断」から「継続的な管理」へと移すことにある。単発の質疑応答セッションと比較すると、管理推論は実際の臨床現場により近い。医師は、疾患の進行状況、治療フィードバック、ガイドラインのエビデンス、個々の患者の違いに基づいて、判断を絶えず調整する必要がある。本研究で提案されている複数回訪問型の仮想OSCE、ガイドライン知識ベース、薬剤固有のベンチマーク、およびデュアルエージェントシステムは、医療AIを評価するための、より臨床的に関連性の高いフレームワークを提供する。しかし、仮想環境は、現実世界の医療における身体診察、リソースの制約、患者のコンプライアンス、および責任範囲を完全に再現することはまだできない。
したがって、より慎重な評価としては、医療ビッグデータモデルは「診断支援」から「治療管理支援」へと移行しつつあると言えるでしょう。その短期的な価値は、医師が最終的な意思決定を行う役割を担うことではなく、疾患進行分析、ガイドラインとの照合、薬剤検証、フォローアップ計画、患者とのコミュニケーションといった分野において、追跡可能で監査可能、かつ継続的に更新される臨床意思決定支援ツールとなることにあります。








