Command Palette
Search for a command to run...
英国の研究チームは、スタック型アンサンブル学習を用いることで、251個のデルタ・スクティ型星の地震指数を高精度で予測することに成功した。

星震学は、星の自然な振動を分析することで、星の内部構造と進化状態を逆転させ、現代の恒星物理学において最も鋭敏な研究方法の1つです。その多くの研究対象の中でも、デルタ・スクティ型星(太陽の約1.5~2.5倍の質量)は、豊かな脈動パターンと非常に密度の高い振動スペクトルを持つことで知られている。これは恒星地震学における重要な実験分野となっている。これらの恒星の脈動は主にヘリウム電離領域の不透明度(κ)機構によって引き起こされるが、内部の対流核は対流オーバーシュート、化学混合、角運動量再分配などの複雑なプロセスをさらに誘発する。同時に、比較的速い自転は振動モードの結合と周波数分裂を引き起こし、パターン認識とパラメータ抽出の難易度を大幅に高める。
星震解析では、パワースペクトルにおける最高ピークに対応する周波数、最大振動パワーの周波数、および大きな周波数間隔Δνは、特に重要なパラメータである。Δνは恒星の平均密度に非常に敏感であり、恒星の全体構造を特徴づける重要な指標である。しかし、δ Scuti型星の場合、高速回転とマルチモードエイリアシングによって本来規則的な周波数間隔が乱され、Δνを測定する従来の方法にとって大きな課題となっている。
近年、TESS衛星によって取得された大規模かつ高精度の光度曲線データは、この種の恒星の研究対象を大幅に拡大させた。しかしながら、データ処理は依然として計算負荷が高く、経験に依存しており、高精度なパラメータ抽出は依然として容易ではない。こうした背景のもと、機械学習は新たな技術的道筋を示しています。従来の手法と比較して、アンサンブル学習は複数のモデルの予測を組み合わせることで、複雑なデータ環境においてより高い精度と安定性を実現できます。近年、ランダムフォレスト、勾配ブースティング、リッジ回帰といった手法は、天文学データの解析において大きな可能性を示しています。
この考えに基づき、英国ウォーリック大学の研究チームは、積み重ね型アンサンブル学習フレームワークを構築した。δ Scuti型星の主要な星震学的パラメータは、TESSの光度曲線から直接予測することができる。この手法は643個の恒星のサンプルにおいて目覚ましい成果を上げました。すべての目標パラメータにおける決定係数R²は0.77以上であり、訓練に使用されなかった60個の恒星に対しても良好な汎化能力を示しました。予測結果は従来の星震学解析の結果と高い一致を示しました。
関連する研究成果は、「TESSによって観測されたδ Scuti型星の星震度指数を推定するためのアンサンブル機械学習アプローチ」と題され、『アストロノミカル・ジャーナル』に掲載された。
研究のハイライト:
* 光度曲線から主要な星震学パラメータを直接推定するための機械学習フレームワークが提案されており、これは従来の方法の限界を打破し、パラメータ抽出の効率を大幅に向上させる。
特徴選択とモデルアーキテクチャを最適化することで高精度の予測が実現され、独立したサンプルを用いてその信頼性が検証された。
* デルタ・スクティ星251個の星の星震度指数の決定が完了し、新しい星カタログが作成され、関連する星のパラメータデータベースが充実しました。これにより、将来の大規模サンプル統計分析および恒星進化研究のための重要なデータサポートが提供されます。

用紙のアドレス:
https://beta.iopscience.iop.org/article/10.3847/1538-3881/ae4bd8
最先端のAI論文をもっと読む:
データセット:TESS光度曲線スクリーニングと星震学サンプル構築
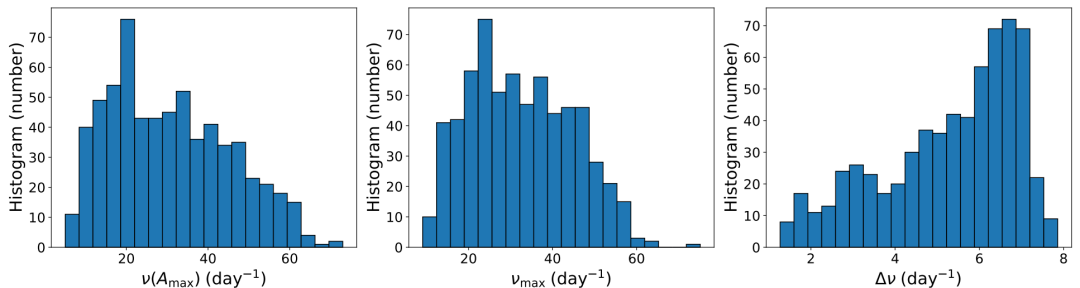
本研究で使用した主要データセットには、643個のデルタ・スクーティ型星のTESS光度曲線が含まれている。さらに、3 つの重要な星震指数、ν(Aₘₐₓ)、νₘₐₓ、および Δν が含まれました。最初のサンプルには 677 個の δ Scuti 星が含まれており、複数回の選択ラウンドの後、そのうち 643 個がコアデータセットとして保持されました。選択基準には、TESS 2 分間の短時間露光光度曲線 (MAST アーカイブから) があること、観測領域ごとに 7,000 点以上のデータポイントがあること、光度曲線が PDC-SAP で補正されていること、および完全で使用可能な星震パラメータがあることが含まれていました。
これを基に、研究者らは補足サンプルとしてデルタ・スクティ型星をさらに251個選択した。これらの星も高品質の光度曲線を持つが、対応する星震学的パラメータはまだ公表されていない。選択基準は、少なくとも3つの観測領域をカバーし、各領域に7,000以上のデータポイントが含まれていることであった。このサンプルは主に、モデルの実際の予測と検証に使用された。
モデル:スタック型マルチベースモデルに基づくアンサンブル回帰フレームワーク
本研究におけるモデルは、恒星の光度曲線の特性に基づいて、恒星の星震学的パラメータを推定することを目的としている。全体的なプロセスには、特徴抽出、データ前処理、アンサンブルモデリング、およびハイパーパラメータ最適化が含まれます。
特徴構築の観点から言えば、本研究では2種類の特徴量を用いた。1つは、輝度分布の基本的な特性を記述するために使用される統計的特徴量(平均値、標準偏差、中央値など)であり、もう1つは、振動信号から周期的かつ多スケールの構造情報を抽出するために使用される周波数領域の特徴量(主成分分析(PCA)、自己相関関数(ACF)、高速フーリエ変換(FFT)、離散ウェーブレット変換(DWT)など)である。
データ前処理段階では、まず、欠損値を含むサンプルを除去し、特徴量を正規化します。さらに、特徴量の分布の不均衡に対処するため、統計分布に基づくリサンプリング手法を導入し、合成データを生成してバイアスを軽減することで、モデル学習の安定性を向上させます。
フレームワークに関して言えば、このモデルはスタック型アンサンブル回帰フレームワークを採用しており、ランダムフォレスト、勾配ブースティング回帰、リッジ回帰をベースモデルとしています。最初の2つはそれぞれ分散とバイアスを低減することで予測性能を向上させ、リッジ回帰は正則化によって特徴量間の多重共線性問題を解決します。ベースモデルの出力は、融合のためのメタ回帰器の学習への入力として使用され、それによって全体的な汎化能力が向上し、予測誤差が低減されます。
モデルのトレーニング中、研究者たちはランダムサーチと交差検証を組み合わせて、主要なハイパーパラメータ(ツリーの数、最大深度、学習率など)を最適化し、安定した高性能なモデル構成を得た。
この一般化は60個の個々の恒星を用いて検証され、すべての星震度指数R² > 0.77であった。
実験的検証は、モデルのトレーニング、汎化能力の評価、および新しいサンプルの予測という3つの部分から構成されます。
トレーニング段階では、研究者らは643個の星からランダムに583個の星を選択し、モデル構築に用いた。これらの星を8:2の比率でトレーニングセットとテストセットに分割し、ランダム性の影響を軽減するためにこのプロセスを100回繰り返した。残りの60個の星は、モデルの汎化能力を評価するための独立したテストセットとして使用された。さらに、最終的な予測には、ラベル付けされていない251個のサンプルが使用された。
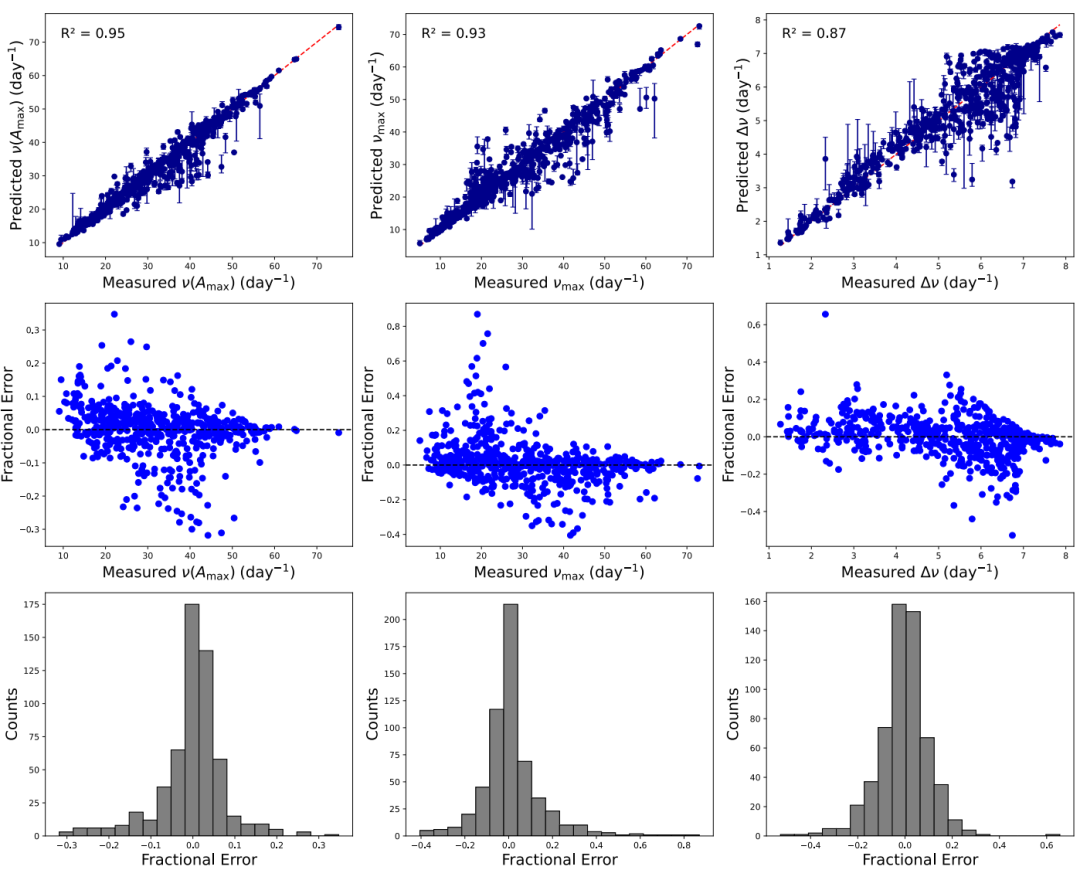
トレーニングサンプルとテストサンプルでは、ν(Aₘₐₓ)、νₘₐₓ、およびΔνに対するモデルの予測R²はそれぞれ0.95、0.93、および0.87であり、ほとんどのサンプルの相対誤差は0.2未満です。特徴量重要度分析の結果、自己相関関数(ACF)が最も寄与度が高く、次いでFFTとDWTが寄与度が高いことが分かりました。歪度や尖度などの統計的特徴量も影響を与えています。学習曲線を見ると、モデルは収束して安定しており、ハイパーパラメータ最適化が効果的であることが分かります。
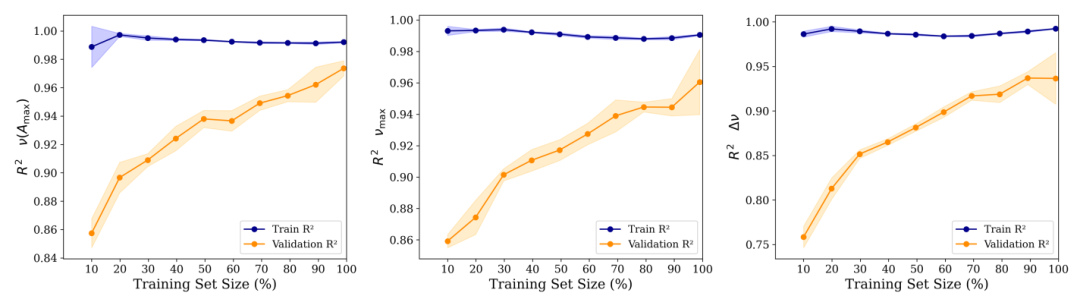
独立したテストセットにおいて、モデルは良好な性能を維持し、3つのパラメータのR²値はそれぞれ0.91、0.87、0.77となり、予測結果と観測値との間に高い一致性を示しました。繰り返し実験の結果は変動が最小限であり、モデルの安定性と堅牢性が高いことを示しています。最後に、研究者らはラベル付けされていない251個の恒星にモデルを適用し、予測された星震パラメータを取得しました。結果は概ねデルタ・スクティ型星の妥当な範囲内に収まりました。
結論
総じて、本研究は従来の星震学的手法に取って代わるものではなく、むしろそれを補完するものです。大規模な観測データが急速に蓄積される状況において、データ駆動型手法によって効率的なパラメータ予測を実現し、それを詳細な物理モデルと組み合わせることで、より深い分析を可能にします。このアプローチは、デルタ・スクティのように複雑な振動モードを持ち、標準化が難しい天体にとって特に有効です。








