Command Palette
Search for a command to run...
オンラインチュートリアル: SpikingBrain-1.0: 100倍の高速化: 推論効率を桁違いに向上

人工知能の急速な発展は、コアアーキテクチャであるTransformerと切り離せない関係にあります。2017年の導入以来、並列計算能力と強力なモデリング結果を備えたTransformerは、大規模モデルアーキテクチャの主流標準となっています。GPTシリーズ、LLaMA、そして国内のQwenシリーズなど、これらはすべてTransformerを基盤として構築されています。
しかし、モデルのサイズが拡大し続けると、Transformer では無視することが難しいいくつかの問題が徐々に明らかになってきます。たとえば、トレーニング中のオーバーヘッドはシーケンスの長さに応じて二次的に増加し、推論中のメモリ使用量はシーケンスの長さに応じて線形に増加するため、リソースが消費され、非常に長いシーケンスを処理する能力が制限されます。
対照的に、生物学的脳はエネルギー効率と柔軟性に関して全く異なるアプローチをとっています。人間の脳はわずか20ワット程度の電力しか消費しませんが、知覚、記憶、言語、複雑な推論など、多岐にわたるタスクを処理できます。この対比から、研究者たちは次のような疑問を抱きました。大規模なモデルを脳に近づけて設計・計算すれば、Transformerが抱えるボトルネックを克服できるのではないか?
この調査に基づいて、中国科学院自動化研究所は、国家脳認知・脳型知能重点実験室などの研究機関と共同で、脳ニューロンの複雑な動作メカニズムを基盤に、「内因的複雑性に基づく」大規模モデルアーキテクチャを提案した。そして今年9月、国産で独立制御可能な脳型パルス大規模モデル「SpikingBrain-1.0」を発表した。このモデルは、スパイキングニューロンの固有ダイナミクスと線形アテンションモデルとの関連性を理論的に確立し、既存の線形アテンション機構が樹状突起計算の特殊な単純化であることを明らかにし、モデルの複雑性と性能を継続的に向上させるための新たな実現可能な道筋を示しています。さらに、R&Dチームは、線形および混合線形複雑性を持つスパイキングニューロンに基づく、脳に着想を得た新たな基礎モデルを構築し、オープンソース化しました。また、国内GPUクラスター向けの効率的なトレーニングおよび推論フレームワーク、Triton演算子ライブラリ、モデル並列化戦略、クラスター通信プリミティブも開発しました。
実験的検証を通じて、SpikingBrain-1.0は、極めて少ないデータ量で効率的なトレーニングを実現すること、推論効率を桁違いに向上させること、国産で独立した制御可能な脳のような大規模モデルエコシステムを構築すること、動的閾値パルスに基づくマルチスケールスパースメカニズムを提案すること、という4つの性能面で飛躍的な進歩を遂げました。SpikingBrain-7Bモデルは、400万トークンのシーケンスにおいて、最初のトークンまでの時間(TTF)が100倍高速化されました。SpikingBrain-7Bモデルのトレーニングは、数百基のMetaX C550 GPU上で数週間にわたって安定して実行され、FLOP利用率は23.41 TP3Tを達成しました。提案されたパルス方式は 69.15% のスパース性を実現し、低電力動作を可能にします。
注目に値するのは、我が国が大規模な脳型線形基本モデルアーキテクチャを提案したのは今回が初めてであり、また、国内のGPUコンピューティングクラスター上に大規模な脳型脈拍モデルのトレーニングおよび推論フレームワークが構築されたのも今回が初めてです。超長シーケンス処理機能は、法的文書や医療文書の分析、複雑なマルチエージェントシミュレーション、高エネルギー粒子物理学実験、DNA シーケンス分析、分子動力学軌跡などの超長シーケンスタスクモデリングシナリオにおいて、潜在的に大きな効率上の利点をもたらします。
現在、「SpikingBrain-1.0:内在的複雑性に基づく脳型スパイキングモデル」は、HyperAI公式サイトの「チュートリアル」セクションで公開されています。以下のリンクをクリックして、ワンクリックでデプロイできるチュートリアルをお試しください⬇️
チュートリアルのリンク:
デモの実行
1. hyper.ai ホームページにアクセスした後、「チュートリアル」ページを選択し、「SpikingBrain-1.0: 固有の複雑性に基づく大規模な脳のようなスパイキング モデル」を選択して、「このチュートリアルをオンラインで実行」をクリックします。
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
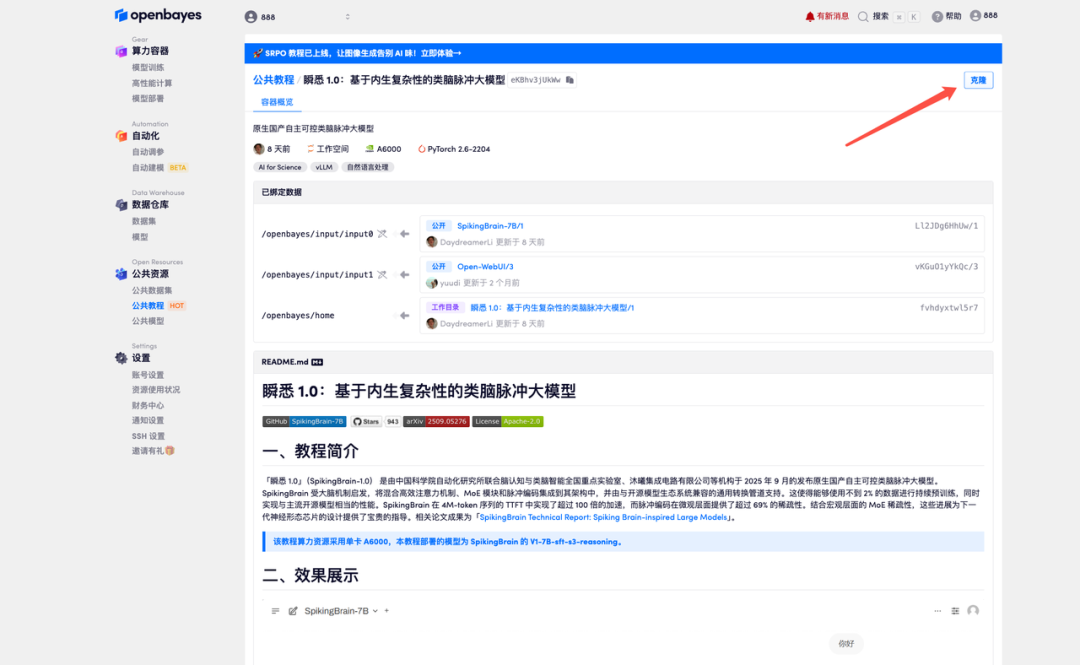
3. NVIDIA RTX A6000 48GBとPyTorchのイメージを選択し、「続行」をクリックします。OpenBayesプラットフォームでは、従量課金制、日単位/週単位/月単位の4つの課金オプションをご用意しています。新規ユーザーは、以下の招待リンクから登録すると、RTX 4090を4時間分、CPU時間を5時間分無料でご利用いただけます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
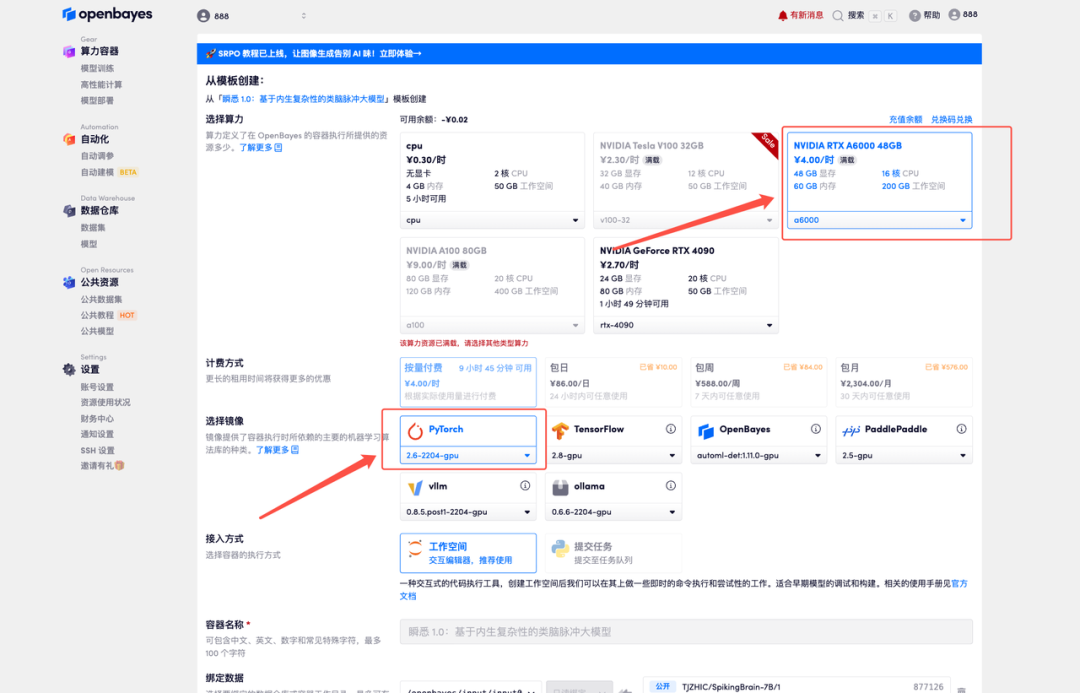
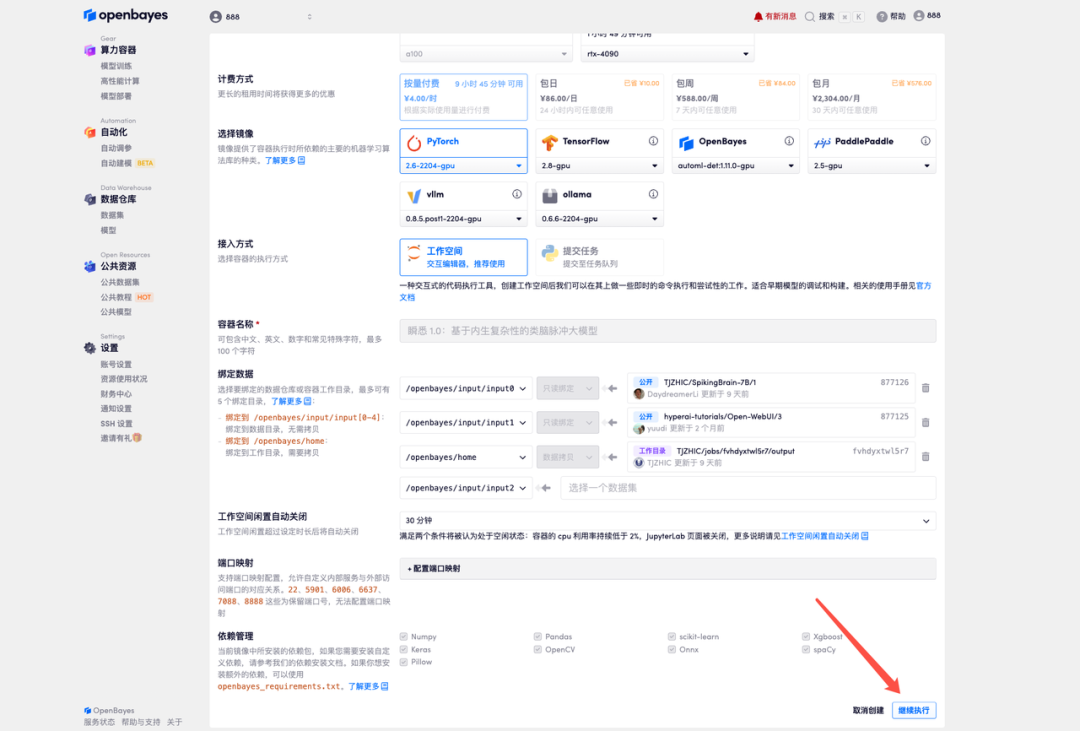
4. リソースが割り当てられるまでお待ちください。最初のクローン作成プロセスには約3分かかります。ステータスが「実行中」に変わったら、「APIアドレス」の横にある矢印をクリックしてデモページに移動します。APIアドレスを使用する前に、実名認証を完了する必要がありますのでご注意ください。
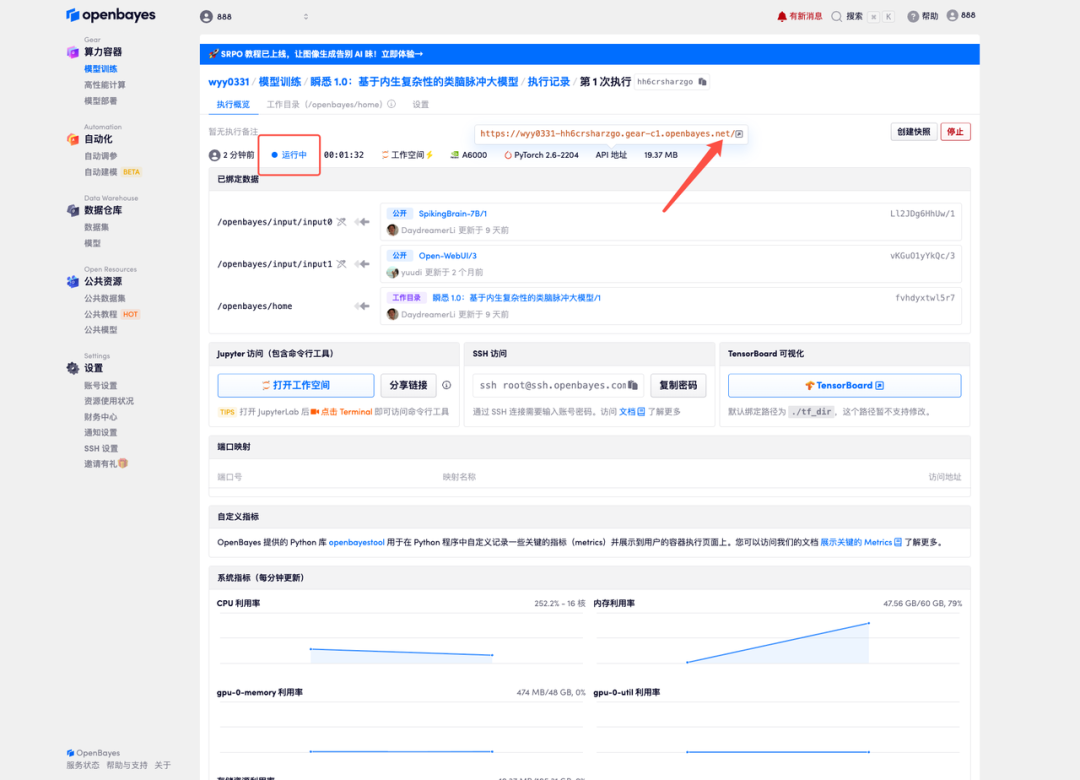
5. ダイアログ ボックスに質問を入力して回答を開始します。
効果実証
例として、「ウェブサイトの固定ヘッダーのCSSとJavaScriptのコードスニペットを見せてください」という質問をしました。結果は下の図のとおりです。

以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
チュートリアルのリンク:








