Command Palette
Search for a command to run...
オンラインチュートリアル | SAM 3 は、2 倍のパフォーマンス向上によりヒント付きコンセプトセグメンテーションを実現し、100 個の検出オブジェクトを 30 ミリ秒で処理します

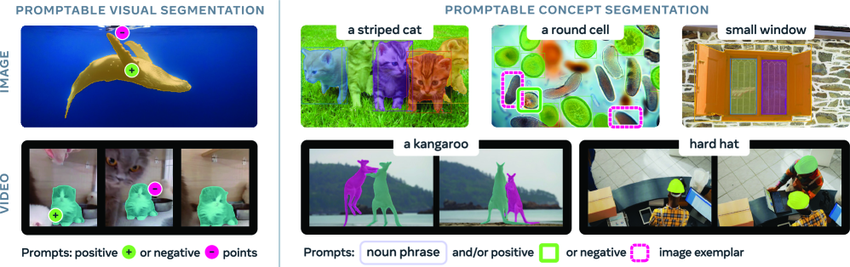
視覚シーン内の任意のオブジェクトを識別・セグメント化する能力は、マルチモーダル人工知能(AI)の重要な基盤であり、ロボット工学、コンテンツ制作、拡張現実(AR)、データアノテーションなど幅広い分野で応用されています。SAM(Segment Anything Model)は、Metaが2023年4月にリリースした汎用AIモデルであり、画像や動画を対象としたキュー対応のセグメンテーションタスクを提案しています。主に、ポイント、バウンディングボックス、マスクなどのキューに基づいて個々のターゲットをセグメント化することをサポートします。
SAMとSAM2モデルは画像セグメンテーションにおいて大きな進歩を遂げましたが、入力コンテンツ内の概念のインスタンスをすべて自動的に検出してセグメンテーションする能力はまだ実現していません。このギャップを埋めるために、Meta は最新版である SAM 3 をリリースしました。これは、キュー可能な視覚セグメンテーション (PVS) において前バージョンのパフォーマンスを大幅に上回るだけでなく、キュー可能な概念セグメンテーション (PCS) タスクの新しい標準も設定します。
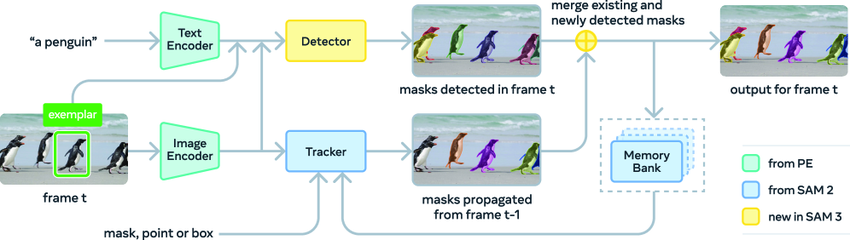
SAM 3 アーキテクチャには検出器とトラッカーが含まれており、どちらも同じビジュアル エンコーダを共有します。この検出器はDETRフレームワーク上に構築されており、条件付き入力としてテキスト、幾何学情報、またはサンプル画像を受け取ることができます。オープン語彙の概念検出の課題に対処するため、研究者らは認識プロセスと位置推定プロセスを分離する独立した「プレゼンスヘッド」を導入しました。
トラッカーはSAM 2のTransformerエンコーダ/デコーダアーキテクチャを採用し、ビデオセグメンテーションとインタラクティブな最適化をサポートしています。検出と追跡を分離するこの設計により、2つのタスク間の競合を効果的に回避できます。検出はIDの独立性を維持する必要があり、トラッカーの主要目的はビデオ内の異なるオブジェクトの識別とIDの維持です。
SAM 3 は、SA-Co ベンチマークの画像およびビデオ PCS タスクで最先端 (SOTA) の結果を達成し、パフォーマンスは前世代機の 2 倍になりました。さらに、新バージョンでは、H200 GPU 上で、100 個を超える検出オブジェクトを含む単一の画像をわずか 30 ミリ秒で処理できます。このモデルは 3D 再構築の分野にも拡張でき、家の装飾のプレビュー、クリエイティブなビデオ編集、科学研究などのアプリケーションを支援し、コンピューター ビジョンの将来の発展に強力な推進力を提供します。
「SAM3:ビジュアルセグメンテーションモデル」がHyperAIウェブサイト(hyper.ai)のチュートリアルセクションで公開されました。さあ、クリエイティブな旅を始めましょう!
チュートリアルのリンク:
論文を見る:
https://hyper.ai/papers/2511.16719
デモの実行
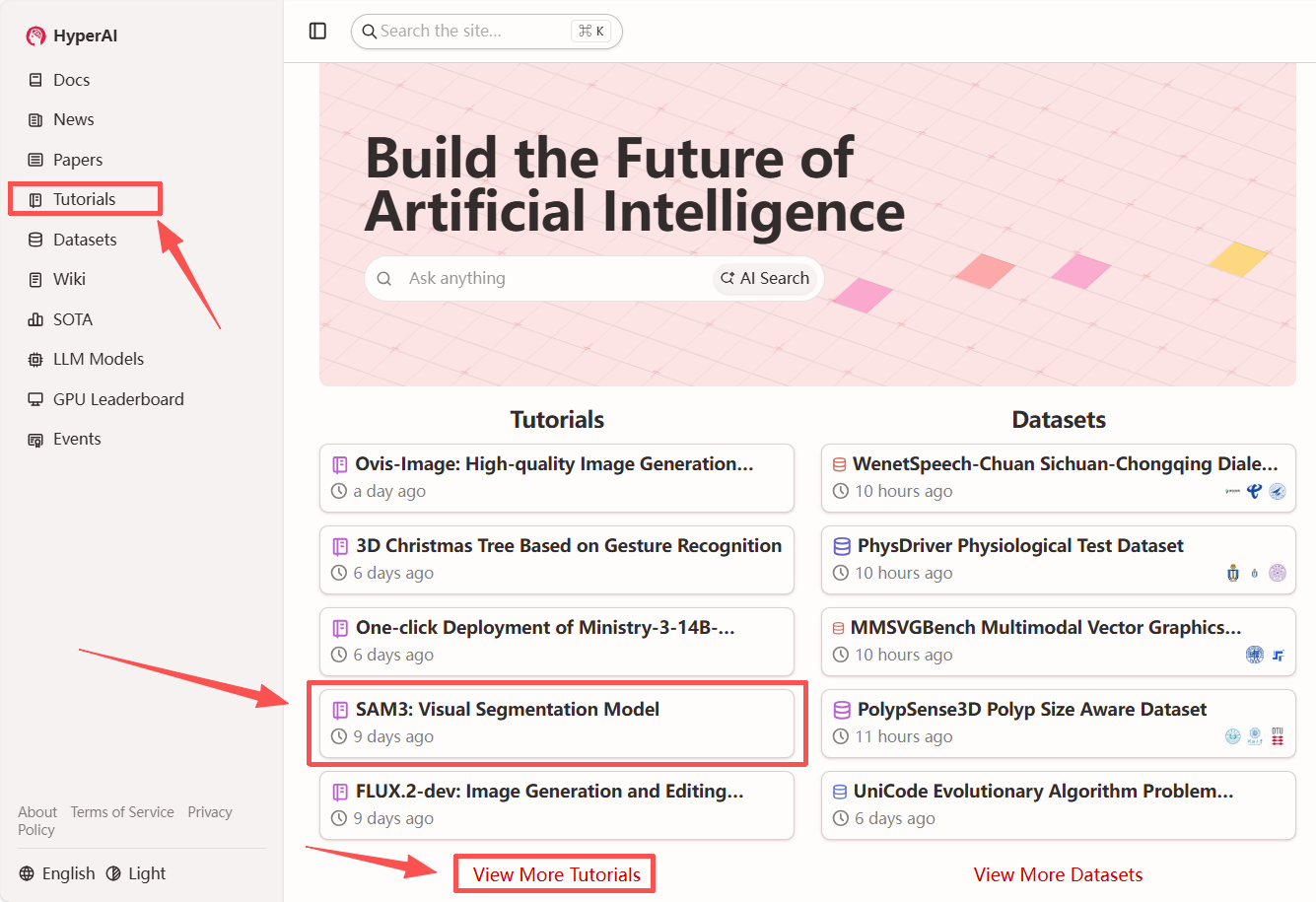
1. hyper.aiのホームページにアクセス後、「SAM3: Visual Segmentation Model」を選択するか、「チュートリアル」ページから選択し、「このチュートリアルをオンラインで実行」をクリックします。
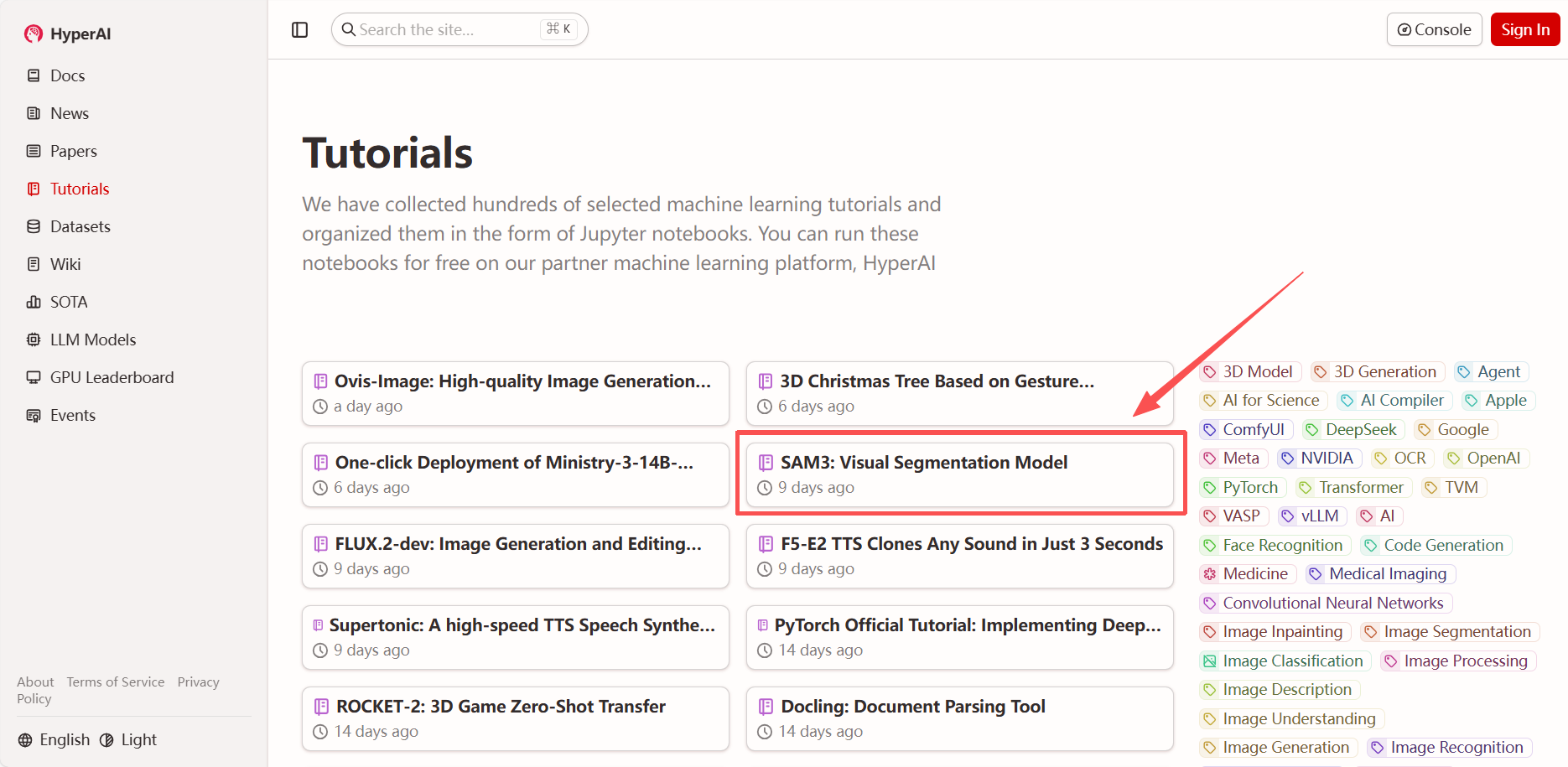
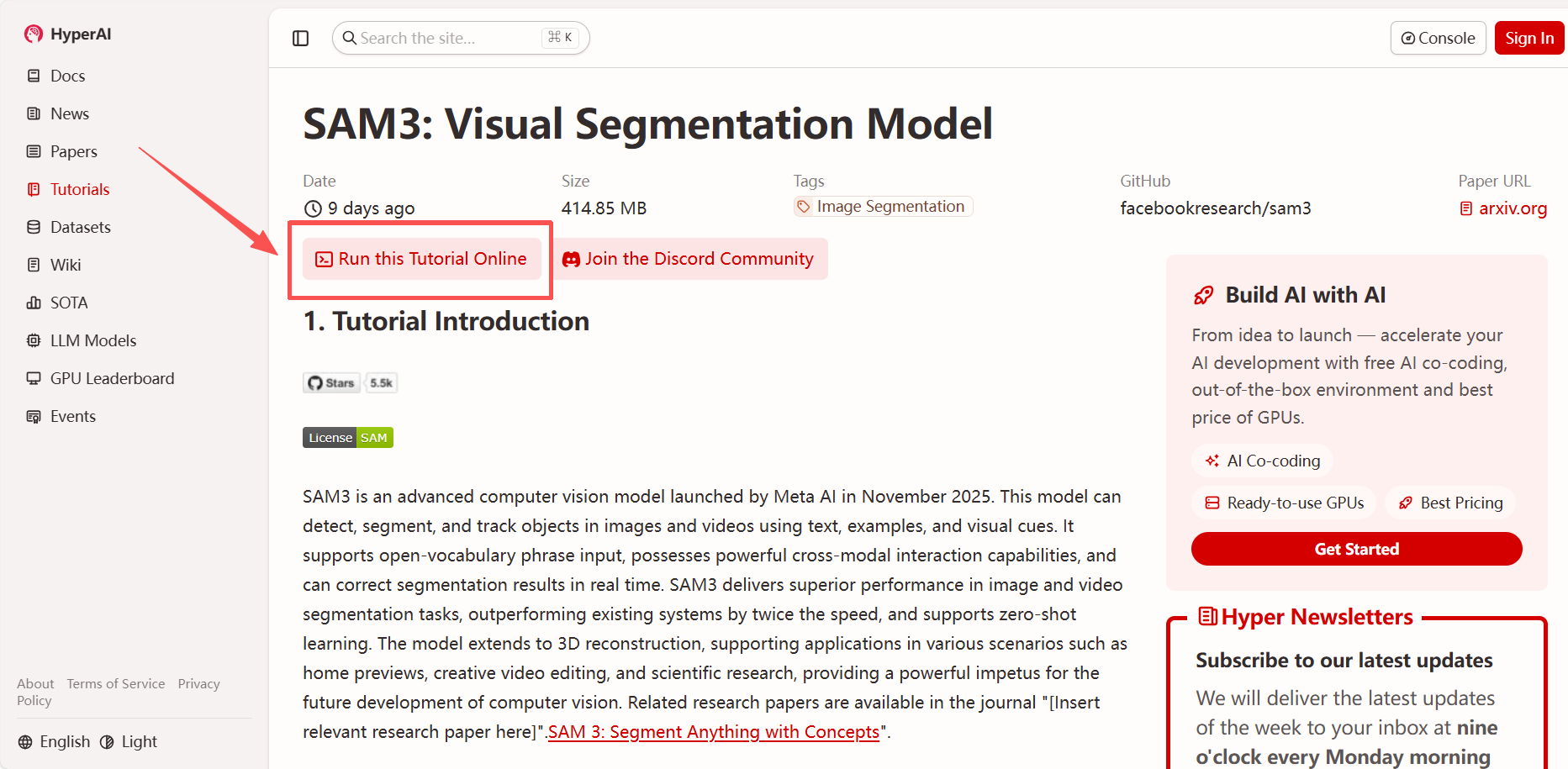
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
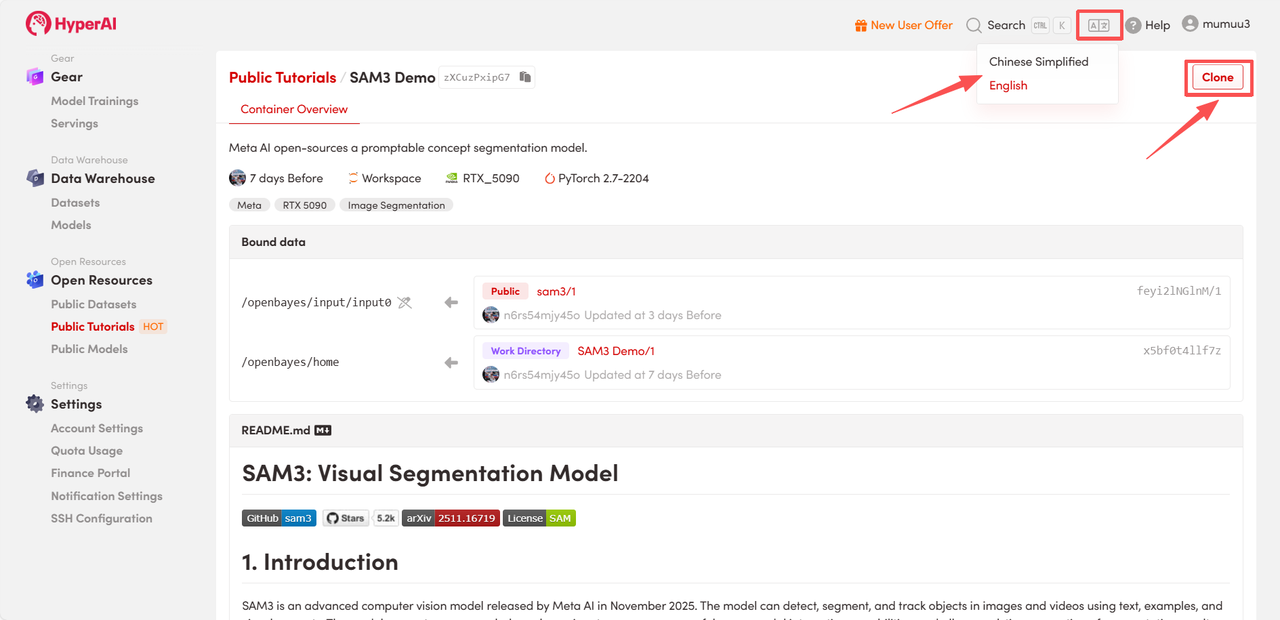
3. 「NVIDIA GeForce RTX 5090」と「PyTorch」のイメージを選択し、必要に応じて「Pay As You Go」または「Daily Plan/Weekly Plan/Monthly Plan」を選択し、「ジョブ実行を続行」をクリックします。
HyperAI は新規ユーザーに登録特典を提供しています。わずか $1 で、RTX 5090 のコンピューティング パワーを 5 時間利用できます (元の価格は $2.45)。リソースは永続的に有効です。
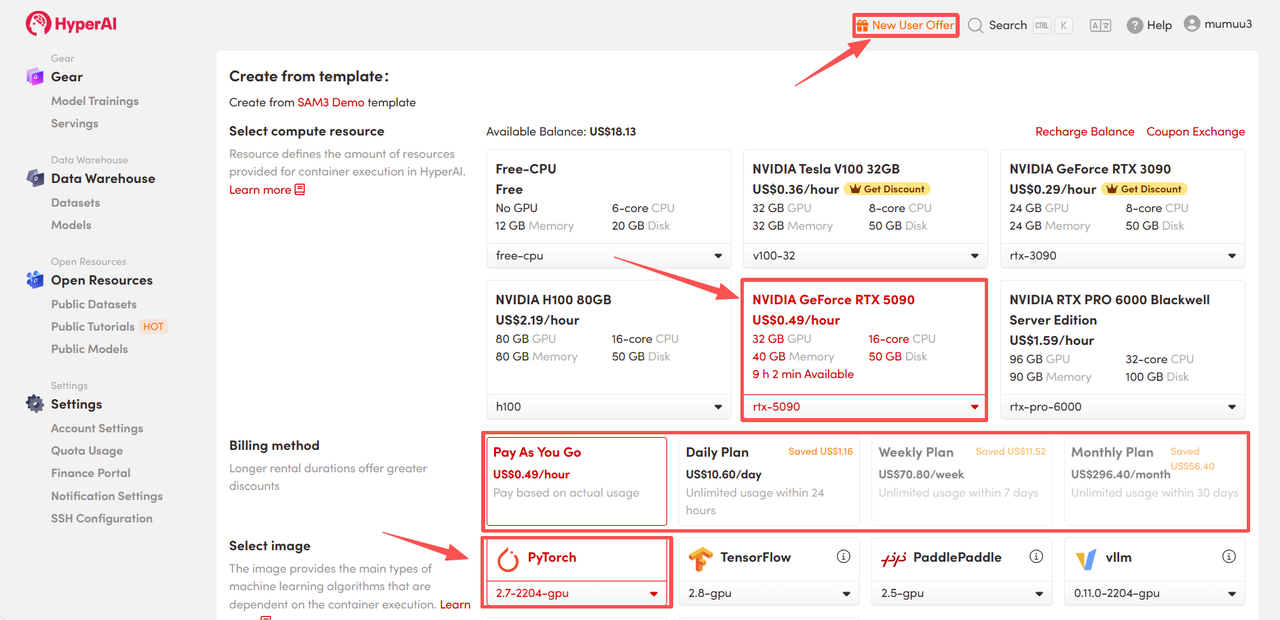
4. リソースの割り当てをお待ちください。最初のクローン作成には約3分かかります。ステータスが「実行中」に変わったら、「APIアドレス」の横にあるジャンプ矢印をクリックしてデモページへ移動してください。
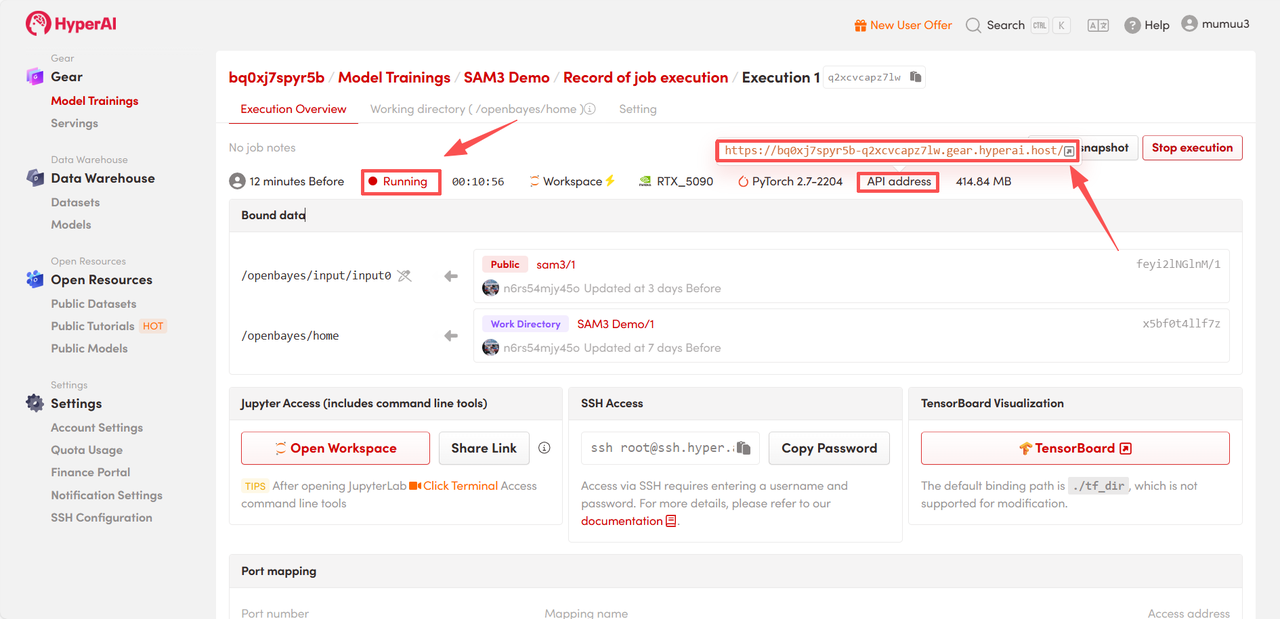
効果実証
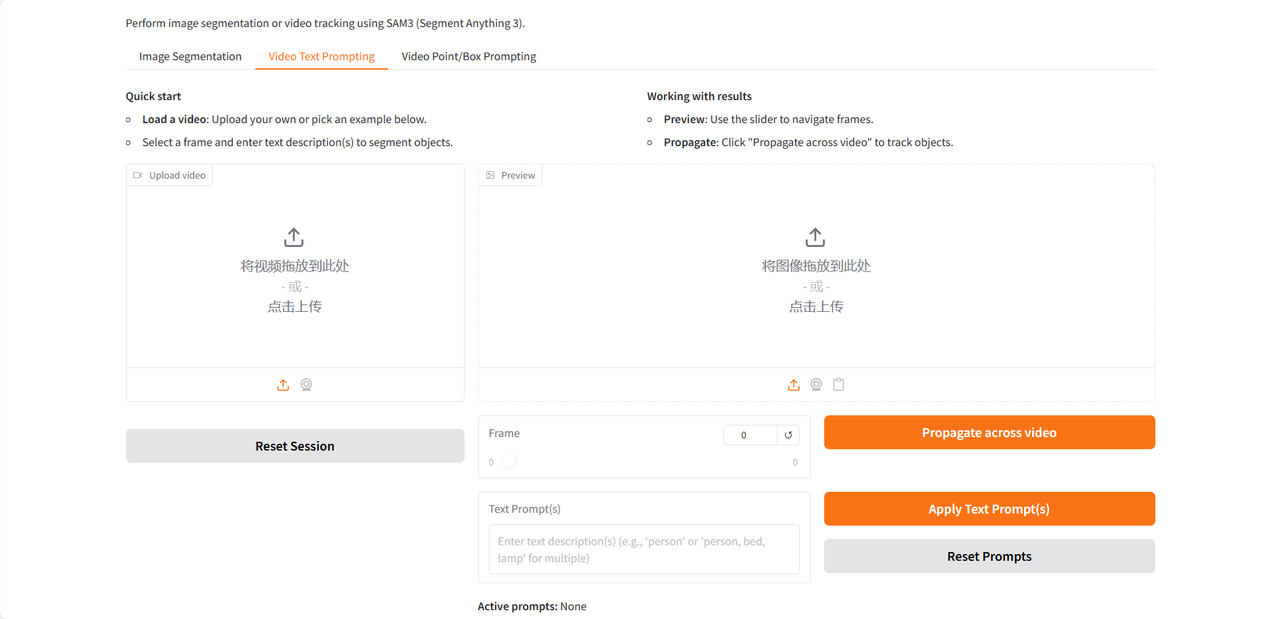
デモページには、画像セグメンテーション、ビデオテキストプロンプト、ビデオポイント/ボックスプロンプトの3つの機能があり、英語入力のみをサポートしています。このチュートリアルでは、ビデオテキストプロンプトを例として使用します。
テスト動画をアップロード後、「テキストプロンプト」欄に識別・分割する名詞句を入力し、「テキストプロンプトを適用」と「動画全体に反映」をクリックしてプロンプトを適用します。最後に「スムーズ再生用にMP4でレンダリング」をクリックすると、識別されたターゲットがハイライト表示された動画が生成されます。
最近公開された「ズートピア2」の予告編のクリップを使って行ったテストを見てみましょう👇
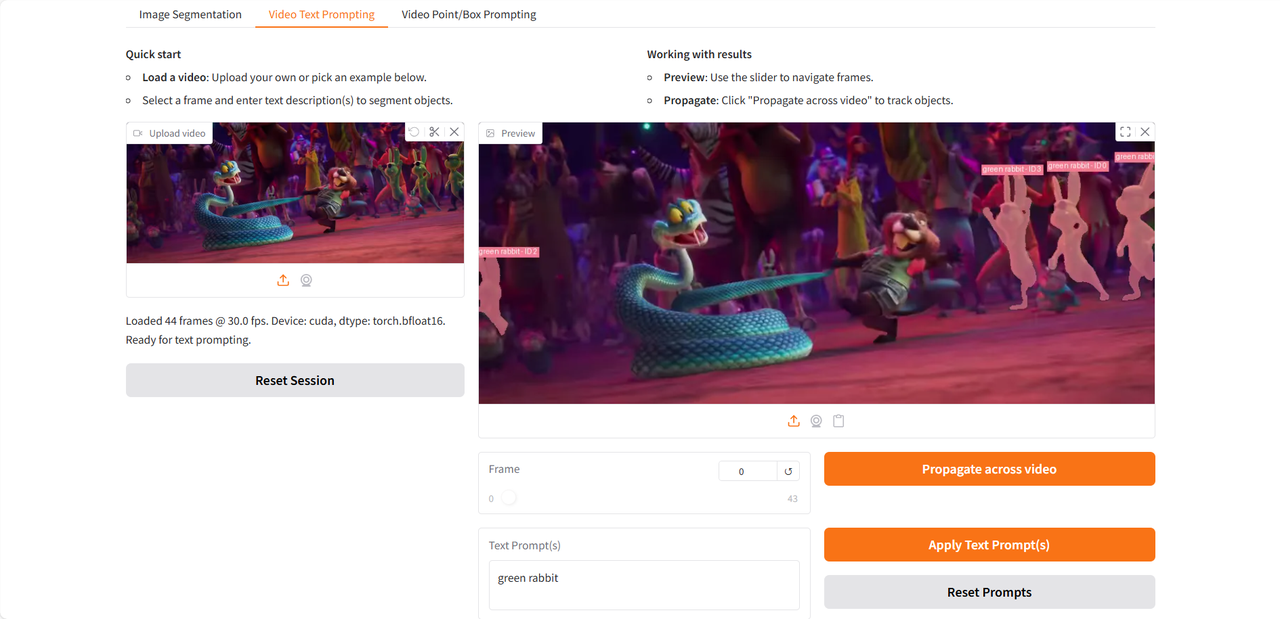
以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
チュートリアルのリンク:








