Command Palette
Search for a command to run...
オンラインチュートリアル | Deepseek-OCRは、最小限の視覚トークンでエンドツーエンドモデルの最先端技術を実現します

よく知られているように、大規模言語モデルが数千、数万、あるいはそれ以上のテキストを処理する場合、計算量は劇的に増加し、計算能力の「無駄遣い」につながることさえあります。これは、高密度テキスト情報シナリオの処理におけるLLMの効率限界にも影響を与えます。
業界が計算効率を最適化する方法を絶えず模索する中、Deepseek-OCRは全く新しい視点を提供します。それは、テキストを「見る」のと同じ方法で、効率的に「読む」ことができるかどうかです。この大胆なアイデアに基づき、研究者たちは、文書テキストを含む単一の画像が、同等の数値テキストよりもはるかに少ない記号で豊富な情報を表現できることを発見しました。これは、テキスト情報を画像として大規模モデルに入力し、理解と記憶を促すことで、全体的な効率を効果的に向上できることを意味します。これはもはや単なる画像処理の域を超えています。むしろ、これは巧妙な「光学圧縮」であり、視覚的な様式をテキスト情報の効果的な圧縮媒体として使用することで、従来のテキスト表現よりもはるかに高い圧縮率を実現します。
具体的には、DeepSeek-OCRはDeepEncoderとDeepSeek3B-MoE-A570Mという2つのコンポーネントで構成されています。エンコーダ(DeepEncoder)は画像の特徴抽出、単語のセグメント化、視覚表現の圧縮を担い、デコーダ(DeepSeek3B-MoE-A570M)は画像タグとプロンプトに基づいて目的の結果を生成します。コアエンジンである DeepEncoder は、高解像度の入力時に低いアクティベーション状態を維持しながら高い圧縮率を実現するように設計されており、ビジュアルトークンの数を最適化して管理しやすくします。実験の結果、テキストトークン数が画像トークン数の10倍未満(つまり圧縮率<10倍)の場合、モデルは971 TP3Tのデコード(OCR)精度を達成できることが示されています。圧縮率が20倍の場合でも、OCR精度は約601 TP3Tに留まります。
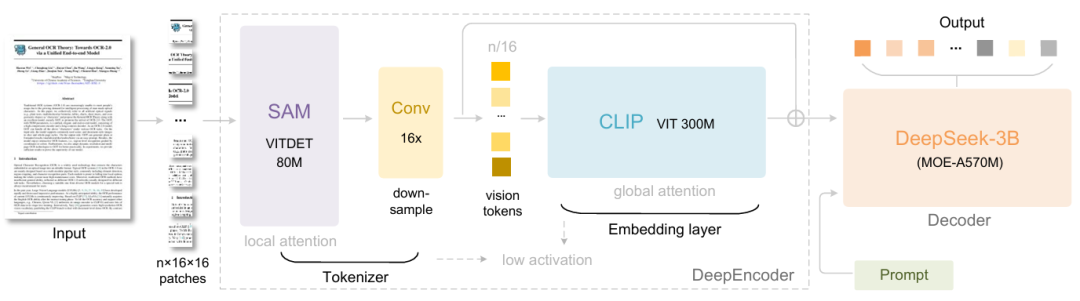
DeepSeek-OCR のリリースは、OCR タスクの進歩であるだけでなく、長いコンテキストの圧縮や LLM における記憶忘却メカニズムの調査など、最先端の研究分野における大きな可能性を示しています。
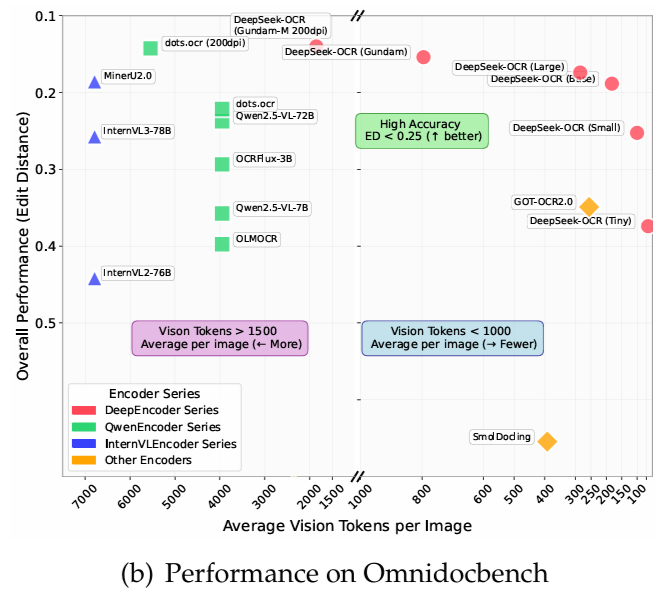
OmniDocBenchでは、わずか 100 個のビジュアル トークンを使用して、GOT-OCR2.0 (ページあたり 256 トークン) を上回ります。さらに、800個未満のビジュアルトークンを使用する場合、MinerU2.0(平均で1ページあたり6000個以上のトークン)よりも優れたパフォーマンスを発揮します。実稼働環境では、DeepSeek-OCRは1日あたり20万ページ以上のLLM/VLMトレーニングデータを生成できます(A100-40Gを1台使用)。
「DeepSeek-OCR:視覚的な圧縮技術で従来の文字認識を置き換える」が、HyperAIウェブサイト(hyper.ai)の「チュートリアル」セクションで公開されました。ワンクリックで導入して体験してみてください!
* チュートリアルリンク:
* 関連論文を見る:
https://hyper.ai/papers/DeepSeek_OCR
デモの実行
1. hyper.ai ホームページにアクセスした後、「DeepSeek-OCR: 従来の文字認識に代わる視覚的圧縮」を選択するか、「チュートリアル」ページに移動して「このチュートリアルをオンラインで実行」を選択します。
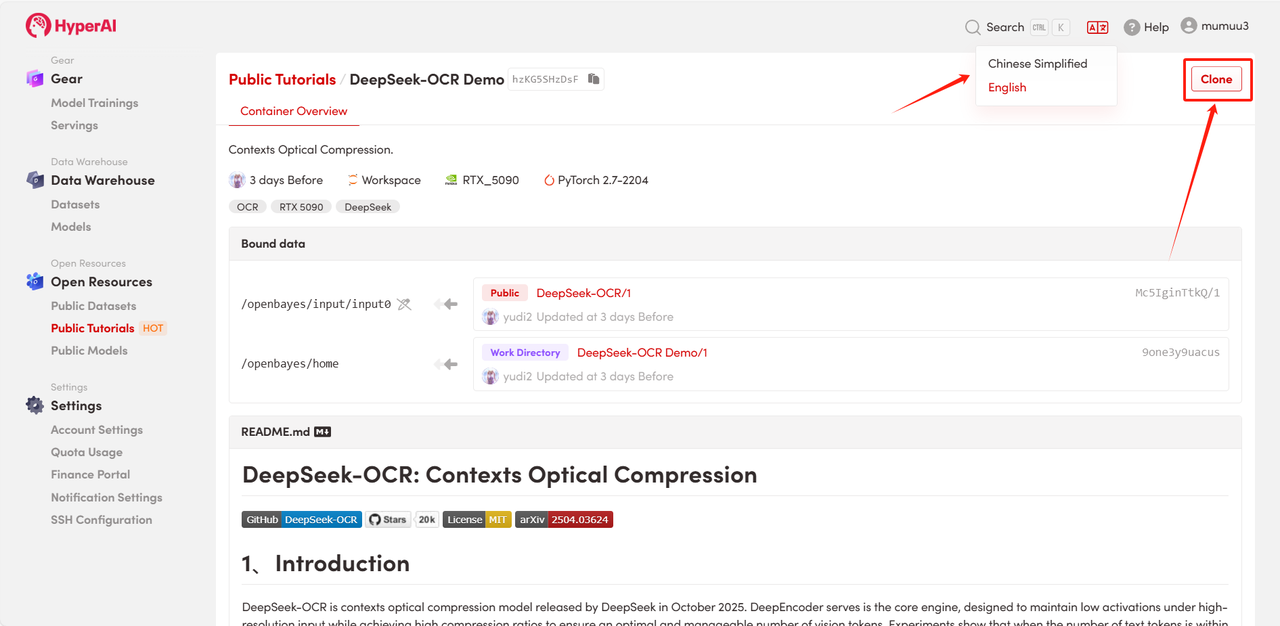
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
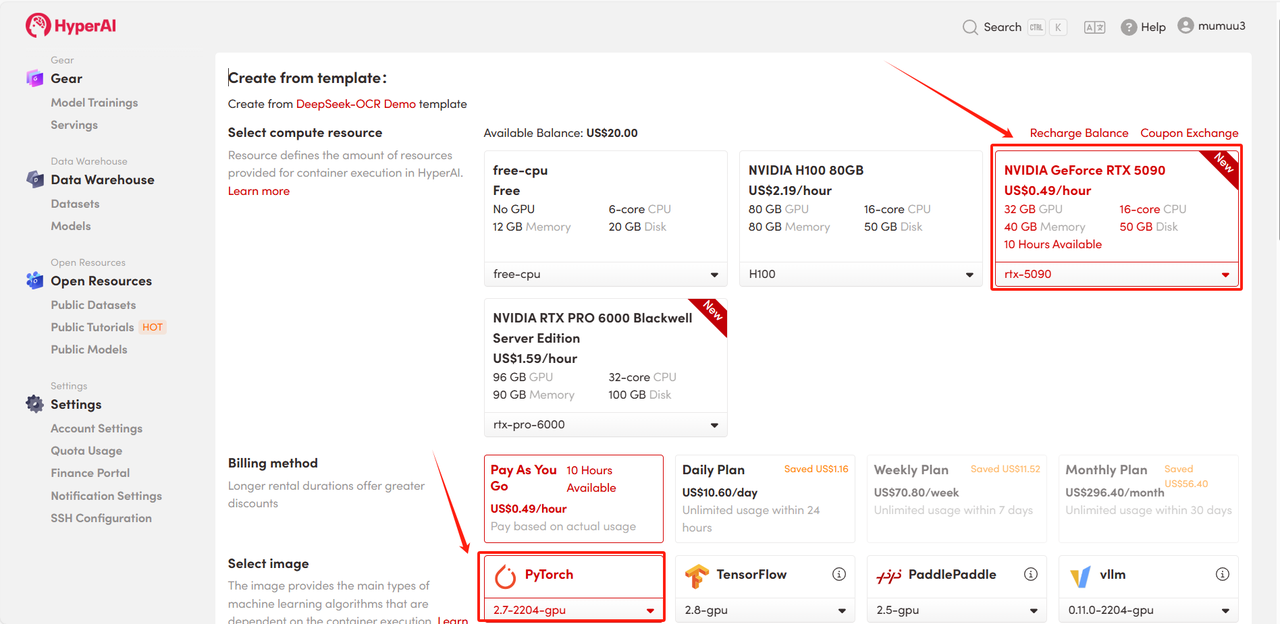
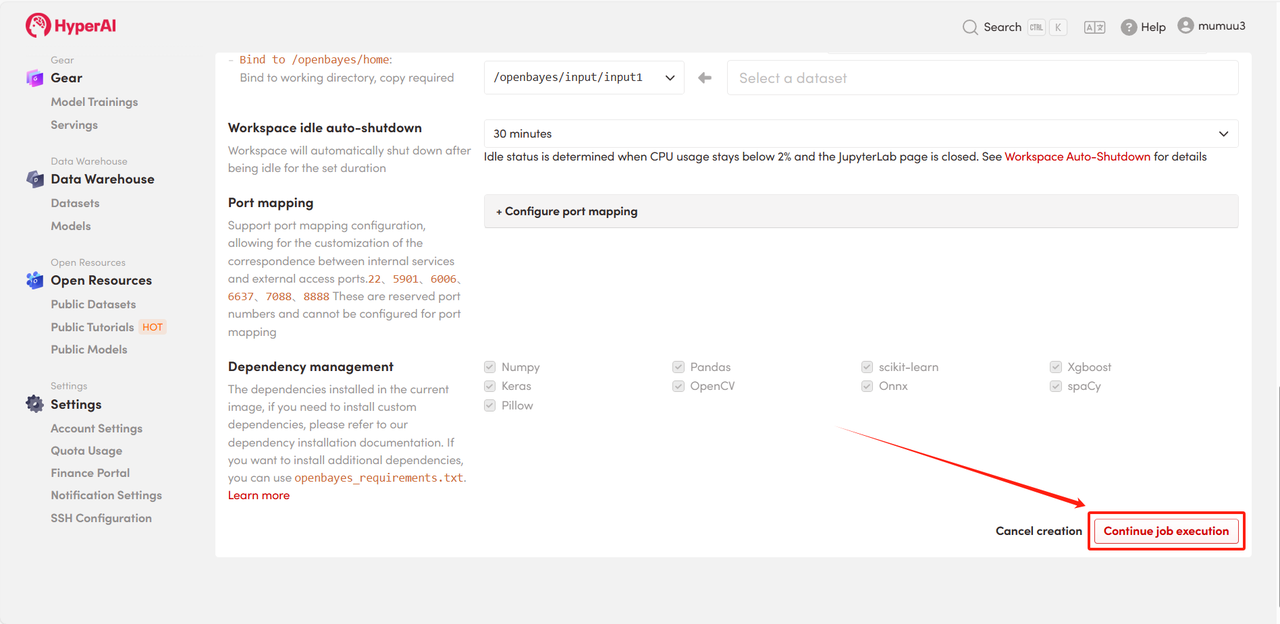
3. 「NVIDIA GeForce RTX 5090」と「PyTorch」のイメージを選択し、必要に応じて「Pay As You Go」または「Daily Plan/Weekly Plan/Monthly Plan」を選択し、「ジョブ実行を続行」をクリックします。
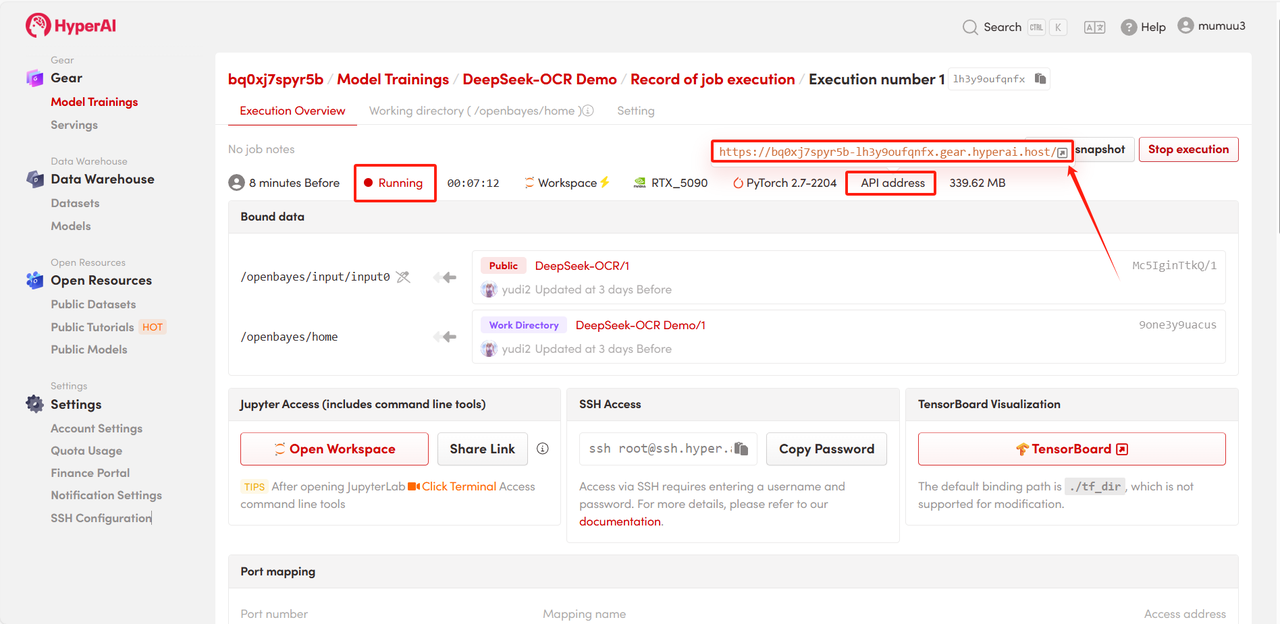
4. リソースの割り当てをお待ちください。最初のクローン作成には約3分かかります。ステータスが「実行中」に変わったら、「APIアドレス」の横にあるジャンプ矢印をクリックしてデモページに移動してください。
効果実証
デモ実行ページに入ったら、解析するドキュメント画像をアップロードし、「テキスト抽出」をクリックして解析を開始します。
モデルはまず画像内のテキストまたはチャート モジュールを分割し、次にテキストを Markdown 形式で出力します。

以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
* チュートリアルリンク:








