Command Palette
Search for a command to run...
TCR配列の詳細な特性評価を実現!ディープラーニングフレームワークDeepTCRは、5万人の肺がん患者データに基づき、免疫学研究の手法を拡張します。肺がんリスクは、肺がんのリスク要因を詳細に解説します。

T細胞受容体シーケンシング(TCR-Seq)は、次世代シーケンシング(NGS)技術の重要な応用分野であり、研究者が適応免疫応答の多様性を体系的に特徴づけることを可能にします。T細胞受容体シーケンシングデータの解析において、モチーフ検索や配列アライメントといった従来の手法は成果を上げてきましたが、その限界も徐々に明らかになってきました。体内の低頻度の抗原特異的 T 細胞反応を識別する場合、その信号は、多数の非特異的 T 細胞背景によって圧倒されることがよくあります。これは、従来の方法がノイズから信号を識別する際に直面する課題を反映しています。
TCR 配列のより精密な特性評価の需要が高まるにつれて、研究者は畳み込みニューラル ネットワーク (CNN) に代表されるディープラーニング テクノロジーに注目するようになりました。DeepTCR は、ディープラーニング ベースの免疫受容体配列解析フレームワークとして登場しました。このフレームワークは、TCR シーケンス免疫レパートリー データから CDR3 シーケンス、V/D/J 遺伝子の使用、および MHC 分子タイプ特性を学習し、非常に複雑な TCR シーケンス データをモデル化するための共同表現を構築できます。
DeepTCR は、ディープラーニング フレームワークを TCR 配列分析に体系的に適用することで、免疫学研究の分析方法を拡張するだけでなく、さまざまな分野でのディープラーニング テクノロジの幅広い応用をさらに実証します。
HyperAI公式サイトに「DeepTCR:ディープラーニングを用いたTCRペプチド親和性予測」が公開されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/gKmgi
9月8日から9月12日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 2
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
※9月締切:5日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 新しい植物病害 植物病害画像データセット
New Plant Diseasesは、植物病害の識別と葉の分類研究のための画像データセットです。健康な葉から様々な病害までを網羅しており、機械学習および深層学習モデルの開発と評価に広く適しており、特に作物の健康状態監視、病害識別、精密農業モデル、学術研究において重要なベンチマーク価値を有しています。
直接使用: https://go.hyper.ai/RKYtW

2. Intel Image Classification 自然シーン画像分類データセット
Intel Image Classificationは、Intelが公開した画像分類データセットで、自然風景と人工風景の画像を分類することを目的としています。このデータセットには、建物や森林など6つのカテゴリに分類された約25,000枚のカラー画像が含まれています。
直接使用: https://go.hyper.ai/qgbeX

3. LongPage小説推論データセット
LongPageは、複雑な推論能力を備えた完全な小説を書ける人工知能モデルを訓練するための、初の包括的なデータセットです。強化学習の訓練プロセスに対するコールドスタートの教師ありファインチューニングをサポートし、階層的推論能力を備えた大規模言語モデルの訓練や、長文文章の一貫性と計画性の向上に適しています。
直接使用: https://go.hyper.ai/odoKA
4. 肺がんリスクデータセット
肺がんリスクは、肺がんリスク予測と健康要因分析のための表形式のデータセットです。多次元特徴量を用いて、喫煙習慣、ライフスタイルと肺がんリスクの関連性を探求することを目的としています。肺がんリスクモデリング、医療機械学習研究、健康予測システム開発、教育実験に適しています。特に、分類モデリングとリスク評価のシナリオにおいて有用です。
直接使用する:https://go.hyper.ai/YGFzG
5. IFEval-逆命令評価データセット
IFEval-Inverseは、ByteDance Seedが南京大学、清華大学などの研究機関と共同で公開した、大規模言語モデル向けの敵対的命令評価データセットです。このデータセットは、逆命令や異常命令に直面した際に、モデルが訓練の慣性を打破し、真の命令遵守を達成できるかどうかを検証することを目的としています。
直接使用: https://go.hyper.ai/IcTqj
6. FinReflectKG金融ナレッジグラフデータセット
FinReflectKGは、金融分野向けの大規模ナレッジグラフデータセットです。企業の規制文書から構造化された意味関係を抽出し、金融分野におけるナレッジグラフ研究の発展を促進することを目的としています。金融分野におけるエンティティ認識、関係抽出、ナレッジグラフ構築、時系列分析、大規模言語モデル駆動型情報抽出評価、下流金融インテリジェントアプリケーション開発に適しています。
直接使用: https://go.hyper.ai/EB5em
7. WenetSpeech Yue 広東語コーパスデータセット
WenetSpeech Yueは、広東語の音声認識(ASR)および音声合成(TTS)のための大規模で多次元的なアノテーションが付与された音声コーパスです。広東語分野におけるリソース不足を補い、高品質な広東語モデルの学習と評価を促進することを目的としています。
直接アクセス: https://go.hyper.ai/cICOv
8. UCIT 継続的命令チューニングデータセット
UCITは、大規模マルチモーダル言語モデルの継続的な指示チューニングのためのベンチマークデータセットです。このデータセットの各サンプルは、タスク記述(プロンプト/指示)とそれに対応する正しい実行期待値(グラウンドトゥルース応答)で構成されており、ゼロショット条件下でのモデルのパフォーマンスを測定するために使用されます。
直接使用: https://go.hyper.ai/TZPwY
9. LoongBench マルチドメイン推論ベンチマークデータセット
LoongBenchは、LLMにマルチドメインかつ検証可能なトレーニングおよび評価リソースを提供するために設計された、マルチドメイン推論評価データセットです。このデータセットには、高度な数学や高度な物理学を含む12の推論集約型領域をカバーする8,729の自然言語問題が含まれています。
直接使用: https://go.hyper.ai/AcFOZ
10. CA-1 ヒト嗜好アライメントデータセット
CA-1は、AIモデルのデフォルト動作に対する人間の価値判断と選好に焦点を当てています。モデル生成コンテンツとアノテーターの評価を組み合わせた、人間のフィードバック行動データセットです。集団アライメントの違いの研究、モデルの行動規範の誘導、価値に敏感な報酬メカニズムの開発に適しています。
直接使用: https://go.hyper.ai/mXznO
選択された公開チュートリアル
1. Wan2.2-S2V-14B: 映画グレードのオーディオ駆動型ビデオ生成
Wan2.2-S2V-14Bは、Alibaba Tongyi Wanxiangチームによって開発されたオープンソースの音声駆動型動画生成モデルです。静止画1枚と音声のみを使用して、最長数分の映画品質のデジタルヒューマン動画を生成でき、様々な画像タイプと画像サイズに対応しています。このモデルは、複数の革新的な技術を統合し、複雑なシーンの音声駆動型動画生成を可能にし、長尺動画生成やマルチ解像度の学習・推論をサポートしています。
オンラインで実行: https://go.hyper.ai/TlSai
2. DeepTCR: TCR-ペプチド親和性を予測するディープラーニング
DeepTCRは、深層学習ベースの免疫受容体シーケンシング解析フレームワークです。TCRシーケンシング免疫レパートリーデータから親和性を予測し、TCR CDR3配列、V/D/J遺伝子使用率、MHC分子型特性を抽出・学習し、TCRを統合的に表現することで、高度に複雑なTCRシーケンシングデータをモデル化することができます。バックグラウンドノイズを含むシングルセルRNA-SeqやT細胞培養ベースのアッセイから、抗原特異的TCRを抽出できます。
オンラインで実行: https://go.hyper.ai/gKmgi
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. 共有は思いやり:集合的なRL体験の共有による効率的なLM後トレーニング
本論文では、完全分散型かつ非同期型の強化学習後学習アルゴリズムであるSwarm sAmpling Policy Optimization(SAPO)を提案する。SAPOは、異種コンピューティングノードからなる分散ネットワーク向けに設計されている。各ノードは、自身のポリシーモデルを自律的に管理しながら、他のノードと軌跡を「共有」する。このアルゴリズムは、レイテンシ、モデルの均一性、ハードウェア構成に関する明示的な仮定に依存せず、ノードは必要に応じて独立して動作することができる。
論文リンク: https://go.hyper.ai/MWeWF
2. 言語モデルが幻覚を起こす理由
本論文は、言語モデルが幻覚を経験する根本的な理由は、その学習および評価メカニズムが不確実性を認めるよりも推測を奨励する傾向があるためであると提唱する。さらに、現代の学習プロセスにおける幻覚の統計的根拠を分析する。大規模モデルが不確実な応答に対して課す体系的なペナルティは、幻覚を評価するための追加指標を導入するのではなく、現在主流でありながら偏りのあるベンチマークスコアリング手法を見直す必要があることを示唆している。
論文リンク: https://go.hyper.ai/eXoOR
3. オープンエンド生成のためのリバースエンジニアリングによる推論
本論文では、推論の構築方法を根本的に変える新たなパラダイム、リバースエンジニアリング推論(REER)を提案します。試行錯誤や模倣を通してボトムアップで推論プロセスを構築する従来の手法とは異なり、REERは「逆」戦略を採用します。既知の高品質な解を出発点として、それらの解を生成できる可能性のある段階的な深層推論パスを計算的に発見します。
論文リンク: https://go.hyper.ai/xFygJ
4. Parallel-R1: 強化学習による並列思考に向けて
本稿では、複雑な実世界推論タスクを扱い、並列思考行動を可能にする初の強化学習(RL)フレームワークであるParallel-R1を紹介します。このフレームワークは、漸進的なカリキュラム設計を用いることで、RLにおける並列思考の訓練におけるコールドスタート問題に明示的に対処します。
論文リンク: https://go.hyper.ai/s2OlH
5. WebExplorer: 長期的な Web エージェントのトレーニングのための探索と進化
本論文では、綿密に構築された高品質なデータセットを活用し、教師ありファインチューニングと強化学習を組み合わせることで、最先端のウェブプロキシモデルであるWebExplorer-8Bの学習に成功しました。このモデルは最大128KBのコンテキスト長をサポートし、最大100回のツール呼び出しを実行できるため、長期的な問題の解決を可能にします。複数の情報検索ベンチマークにおいて、WebExplorer-8Bは同規模のモデルの中で最高レベルの性能を達成しました。
論文リンク: https://go.hyper.ai/NusbG
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 香港中文大学とその他の研究チームは、遺伝子発現データと細胞形態画像を相関させることにより、表現型薬物開発を加速するためのトランスクリプトーム誘導拡散モデルを開発しました。
香港中文大学、モハメド・ビン・ザイード人工知能大学、その他の研究機関の研究者らは、スケーラブルなトランスクリプトーム誘導拡散モデルMorphDiffを提案しました。このモデルは、細胞形態の摂動に対する応答を高忠実度でシミュレートするために特別に設計されています。潜在的拡散モデル(LDM)アーキテクチャに基づくこのモデルは、L1000遺伝子発現プロファイルをノイズ除去学習の条件付き入力として使用します。
レポート全文はこちら:https://go.hyper.ai/f7WeP
2. 「ブラインドスクリーニング」から「正確な位置決め」まで、中国石油大学のチームは、PPI界面改質剤の予測において既存の方法を上回るAlphaPPIMIを立ち上げました。
中国石油大学と延世大学の共同研究チームは、複数の先進技術を統合し、AlphaPPIMIと呼ばれる新たなフレームワークを開発しました。大規模な事前学習済みモデルと適応学習メカニズムを組み合わせたこのツールは、PPIインターフェースを特異的に標的とする調節因子の発見という中核課題の解決を目指しており、将来のPPI標的薬開発を強力に支援します。
レポート全文はこちら:https://go.hyper.ai/4tp0M
3. Apple Intelligenceが完全に実装され、コア製品のAI機能がアップグレードされました:リアルタイム翻訳/ビジュアルインテリジェンス/高血圧モニタリング
9月10日午前1時(北京時間)、Appleは2025年秋季カンファレンスを開催し、AIに全面的に焦点を絞り、iPhone 17、Apple Watch Series 11、AirPods Pro 3という3つの主要製品のAIアップグレードを発表しました。Apple Intelligenceは、昨年のコンセプトショーケースから本格的な実装へと進化し、リアルタイム翻訳、健康モニタリング、ビジュアルインテリジェンスといったシナリオをカバーしています。次世代のA19チップとM19 Proチップは、そのコンピューティングパワーの基盤となっています。
レポート全文はこちら:https://go.hyper.ai/IimjS
4. 倫理的な安全対策から病歴管理まで、武漢大学などがヘルスケアエージェントを提案しており、その積極的かつ適切なコンサルテーションは GPT-4 などのクローズドソースモデルを上回っています。
武漢大学と南洋理工大学の研究チームは共同で、対話、記憶、処理の3つの要素からなるヘルスケアエージェントを発表しました。このエージェントは、患者の医療目的を特定し、医療倫理や安全性の問題を自動検出することができます。
レポート全文はこちら:https://go.hyper.ai/AdG2j
5. Apple買収の噂からASMLの13億ドルの投資による主要株主への転身まで、ミストラルAIの技術とビジネスの秘密を暴く
9月初旬、Appleがフランスのスタートアップ企業Mistral AIの買収に関心を示していると報じられました。半導体大手ASMLもこれに追随し、シリーズCの資金調達ラウンドを主導し、13億ユーロを調達しました。同社の評価額は現在140億ドルにまで急騰し、欧州のAI分野を牽引する存在となっています。
レポート全文はこちら:https://go.hyper.ai/zsQBu
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
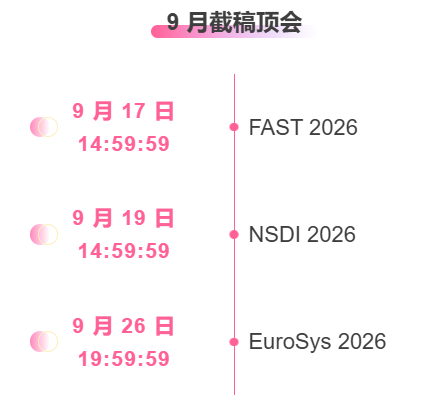
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








