Command Palette
Search for a command to run...
科学データの可用性を向上させるために、中国科学院の張正徳氏のチームは、インテリジェントエージェントに基づく AI 対応のデータ処理および供給ソリューションを提案しました。

今日の高エネルギー物理学研究では、最先端の大規模科学施設が膨大な量のデータを絶えず生成しています。この前例のないデータの氾濫は従来の分析手法の処理限界をはるかに超えているため、人工知能(AI)技術、特に機械学習とディープニューラルネットワークは、高エネルギー物理学研究パイプライン全体にわたって急速に中核ツールとなりつつあります。AIアルゴリズムは、膨大な生データを効率的に処理し、その中に潜む暗黙的、非線形、複雑なパターンや相関関係を明らかにするだけでなく、加速器運用の最適化、検出器性能シミュレーション、実験トリガーシステムの設計、理論モデルの探究などにおいて応用上の利点を発揮しています。AI手法の継続的な革新と深層統合は、高エネルギー物理学の将来の発展を牽引する潜在的な原動力となっています。
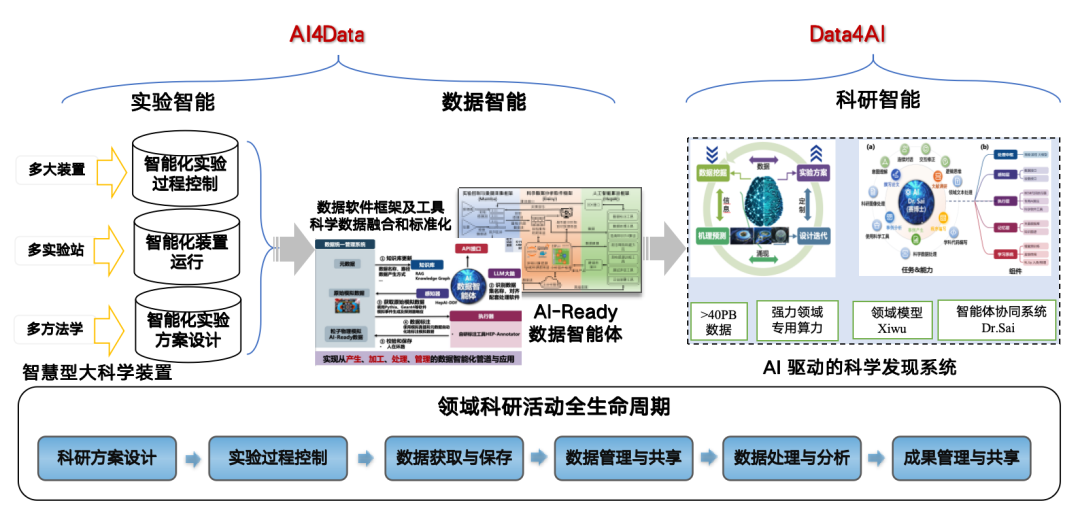
2025 CCF全国高性能コンピューティング学術会議において、高エネルギー物理学研究所コンピューティングセンターの研究者兼AI4S責任者である張正徳氏が「AI対応科学データ技術」フォーラムで「大規模モデルに基づくデータ処理インテリジェントエージェントの進歩と実践」をテーマに講演しました。本稿では、大規模施設からの科学データの現状から始めて、データの効率的かつ高品質な AI-Ready 構築計画、およびデータの注釈付けと供給におけるインテリジェントエージェントとマルチエージェントフレームワークの応用について体系的に説明します。

HyperAIは、張正徳教授の講演を、本来の趣旨を損なうことなく編集・要約しました。以下は講演の書き起こしです。
AI対応データと科学データの現状
オープンソースの AI4S アルゴリズムの文脈では、データが最も重要な中核問題となっています。 AI4Sでは、効率的な分析のためにデータの統一基準が求められます。大規模な科学施設から得られるデータは一般的に統一されたフォーマットとストレージアーキテクチャを備えていますが、実際には、ほとんどの科学データはAI対応ではありません。
高エネルギー物理学で生成される膨大なデータは、データの取得、処理、融合技術への高い要求を満たすだけでなく、AI手法の開発に不可欠なリソースも提供します。本日のレポートで言及されているデータの種類には、実験データだけでなく、シミュレーションデータ、デバイス動作データ、コーパスデータも含まれます。
AI 対応データセットの一般的な定義は、機械学習と人工知能のトレーニング、評価、展開に効率的、安全、かつ再現性のある方法で使用できるデータのコレクションです。高品質の AI 対応データには 10 の特徴があります。
* タスクの適応。対象シナリオおよびタスクとの関連性が高く、包括的に網羅され、代表性がある。
* 高品質と一貫性。正確、完全、一貫性があり、重複が排除され、ノイズが制御されています。
* ボディとマーキングの要件を満たし、高品質のラベル、階層、オントロジー マッピングがあり、監査による注釈が付けられています。
* エンジニアリングも利用可能。標準フォーマット、適切なシャーディング/バケット化、ストリーム可能性、並列化など、機械可読であること。
* 評価可能かつ再利用可能。トレーニング、テスト、検証データを厳密に分割し、ベンチマーク セットに明確かつ合理的な評価指標を設定します。
* メタデータとエンリッチメント。メタデータの収集方法、時間、デバイス システム、コンテキスト、バージョンなどの情報をカバーします。
* データ偏差制御。サンプリング バイアス、ラベル バイアス、履歴バイアスなど。
* 利用可能。安定したアクセス インターフェース、ドキュメント、および例。
* 合理的かつ準拠しています。許可と使用権、プライバシー保護、最適な PII。
* 安全で信頼性があります。暗号化(転送中/保存中)、最小権限、キー管理など。
実践的な研究では、データはモデルの学習だけでなく、モデルの評価にも利用されます。そのため、データセットには、適合率、再現率、F1スコアといった適切な評価指標を設定する必要があります。しかし、これらの指標は分類などの一部のタスクには一般的に適用可能ですが、回帰分析などの問題にはそれほど効果的ではありません。そのため、AI対応データセットの品質に対する要求は高まり、課題が生じています。
現在のところ、オントロジーとアノテーションが付与されたデータに加えて、AI対応データセットは、AIタスクの説明などのメタデータも提供する必要があります。さらに重要なのは、AI対応データセットが価値あるAIタスクに直接関連付けられていることです。光源を例にとると、AI アプリケーションは、イメージング、分光法、回折散乱などの特定の科学的タスクを効果的にサポートできる必要があります。
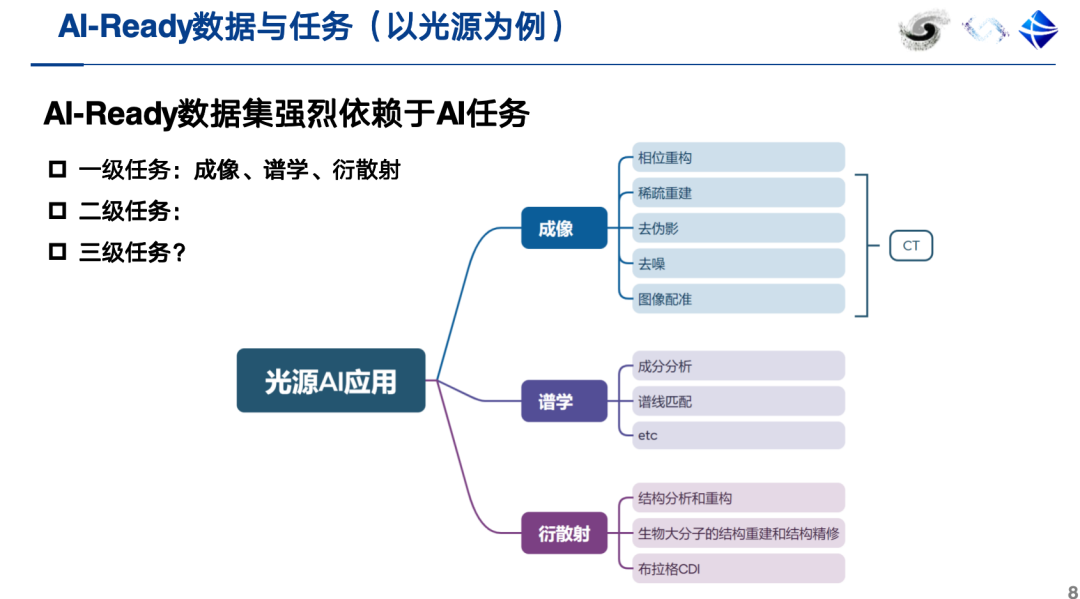
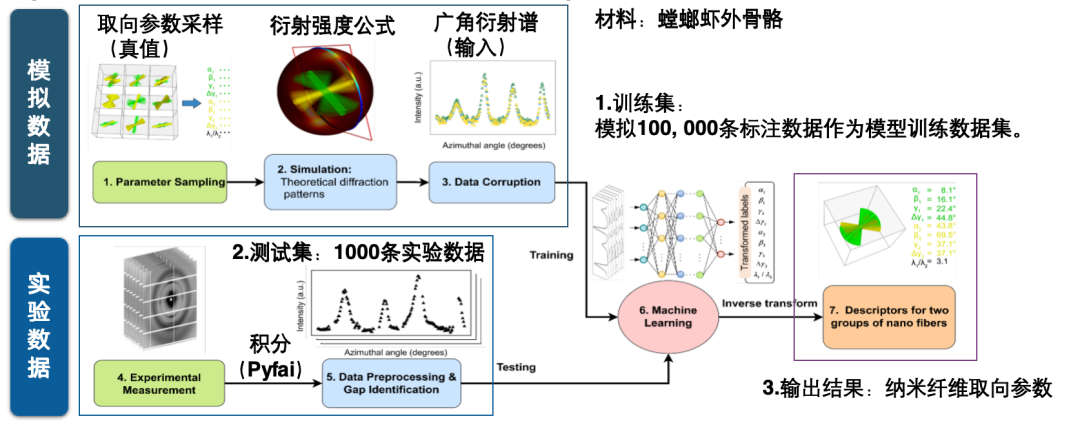
次に、AI対応データセットとは何かを2つの例を用いて説明します。例えば、ナノファイバー配向予測AIデータセットには、広角回折スペクトルに基づいてナノファイバーの配向パラメータを直接予測するという明確なAIタスクがあります。このようなデータセットを構築するには、シミュレーションデータと実験データの両方を組み合わせる必要があります。
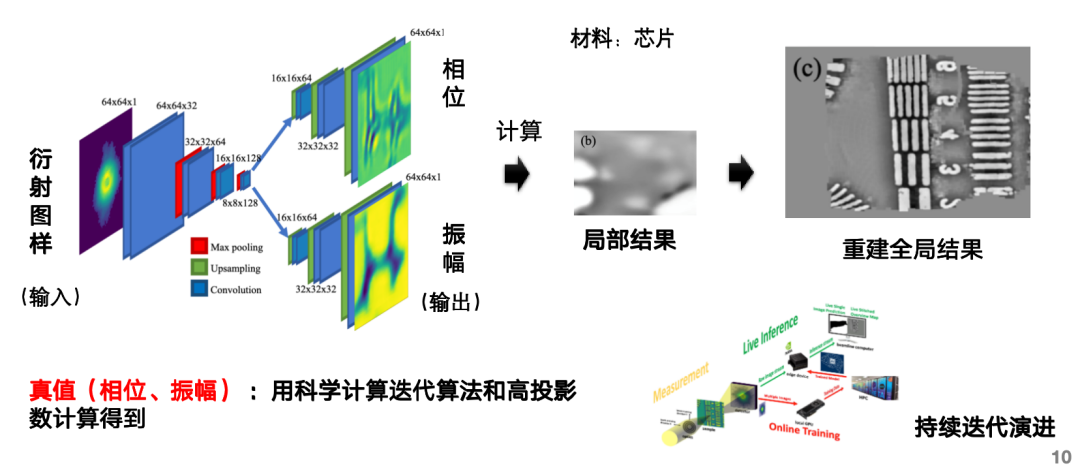
例えば、スタック画像の高速再構成のためのAIデータセットは、回折パターンの入力、位相と振幅の予測、再構成画像の計算というAIタスクを、画像再構成に伴う膨大な計算作業の完了まで実行できます。このアーキテクチャには、位相予測用と振幅予測用の2つのブランチが含まれています。真の値は、科学計算の反復アルゴリズムと多数の投影を用いて導出されます。
エージェント技術をデータ処理に適用する
エージェントの定義は、人工知能の本来の定義に非常に近く、ユーザーの知識、プログラム、環境、入力情報に基づいてユーザーに代わって決定を下したりアクションを実行したりできるソフトウェアまたはシステムを指します。
インテリジェントエージェントは自動化技術と類似点がありますが、自動化は通常、固定されたプロセスに基づいて動作します。従来の自動化とは異なり、インテリジェントエージェントは、決定論的なルールでは効果的にカバーできないワークフローの処理に特に適しており、従来のルールベースのコンピューティング手法では処理が困難なタスクを処理できます。インテリジェントエージェントはあらゆるシナリオに適しているわけではありません。その有効性は特定のタスク環境に大きく依存し、意思決定と処理の複雑さを十分に考慮する必要があります。したがって、インテリジェントエージェントを構築するには、システムが複雑な意思決定プロセスにどのように対処すべきかを再考する必要があります。
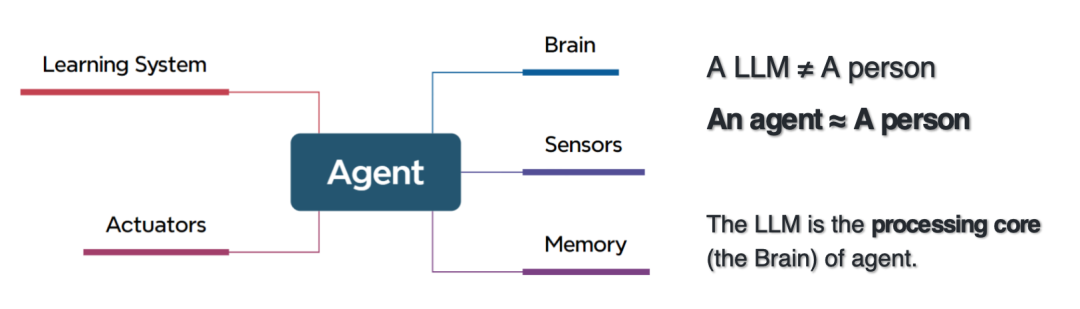
インテリジェント エージェントの脳は大きなモデルなので、インテリジェント エージェントと大きなモデルの関係は、実際には包含関係になります。インテリジェント エージェントと大規模モデルの違いは、インテリジェント エージェントには、認識層、実行層、メモリ層、および処理センターが含まれていることです。ドメイン専門知識、科学的分析ツール、データとメタデータの認識、コードの記述とプログラムの実行、タスク計画、役割の割り当てとコラボレーションなどを学習できるようになります。
同時に、シングルエージェントシステムとマルチエージェントシステムの適用シナリオも異なります。一般的に、シングルエージェントシステムは単一のツールを搭載しています。搭載するツールの数が増えると、ツール選択の精度が低下します。このような場合、マルチエージェントシステムを使用することで混乱を回避できます。
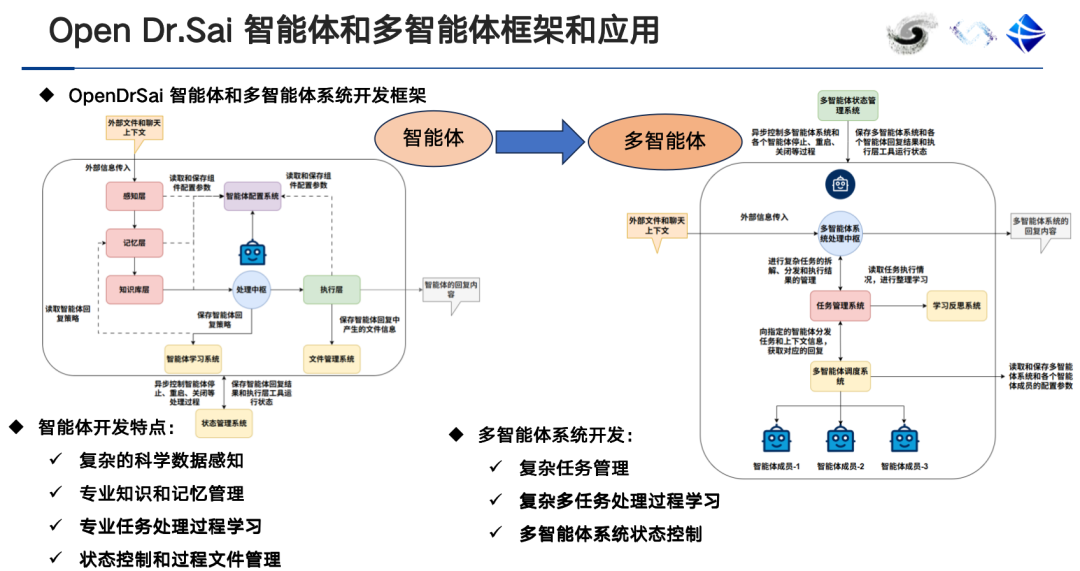
AI対応データラベリングはラベリングツールをベースとしており、高精度ですが、高度な手動介入が必要です。一方、インテリジェントエージェントをベースとするAI対応データラベリングは、高度に自動化され、効率的で、データ情報の理解と支援を提供します。学際的な研究に適していますが、初期精度は比較的低い場合があり、継続的な学習とフィードバックメカニズムを通じてラベリング精度を継続的に向上させる必要があります。現在、アノテーションに基づく多くのアノテーションツールは、「インテリジェントエージェントモジュール+ヒューマンコンピュータインタラクション+インテリジェントアシスタンス+レビューシステム+データベースを搭載」というモデルに徐々に移行しています。
光源シーンにデータエージェントを適用
当チームのデータエージェントは、主に光源(HEPS)/中性子源(CSNS)のシナリオで使用され、データの処理と供給をサポートします。エージェントの上流はDomasデータ管理システムで、これはビッグデータデバイスのデータ収集システムに接続され、データ収集システムは検出器自体に接続されます。
Data Agents の詳細については、以下を参照してください。
https://github.com/hepaihub/drsai
HepAIプラットフォームリンク:
エージェントのワークフローは 5 つのステップに分かれています。
* Domas に接続して、実験データやメタデータなどのデータ情報を取得します。
* 取得したデータに基づいて知識ベースを更新します。
* エージェントはさらに特定のタスクに基づいてデータを認識し、データ形式を変換してコマンドを実行することでデータ相互作用を完了します。
* さまざまな科学計算ツールを使用してデータを処理します。
* タスク実行を実行するためにエグゼキュータにデータを入力し、出力結果を Domas に入力します。
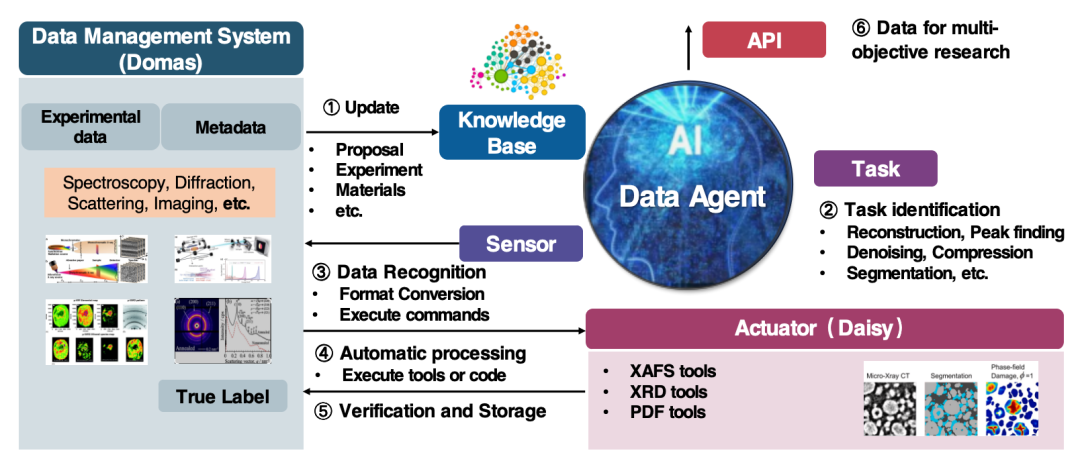
現在、このエージェントは、デバイス間X線回折および中性子粉末回折の実験とシミュレーションのAIデータセットの構築、およびペア分布関数(PDF)の実験シミュレーション融合データセットの構築に使用できます。
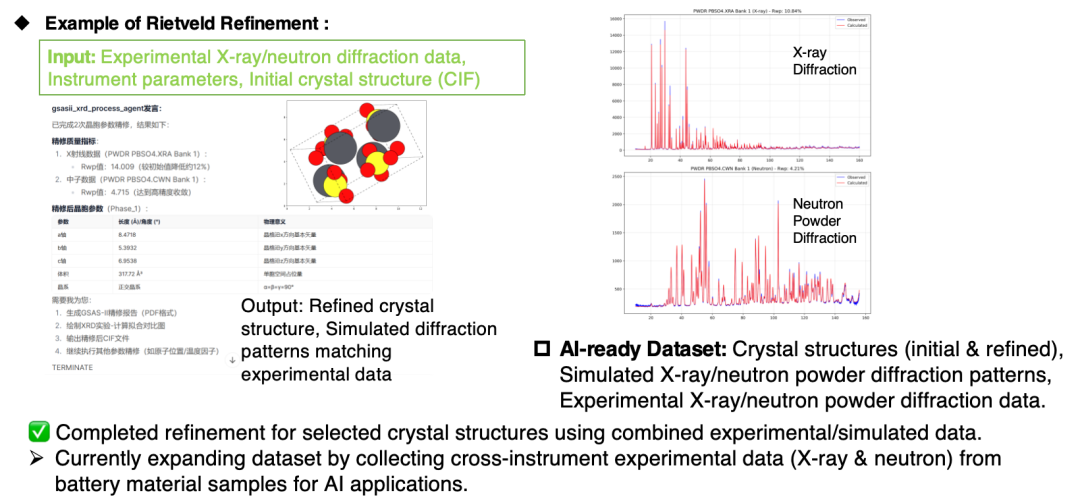
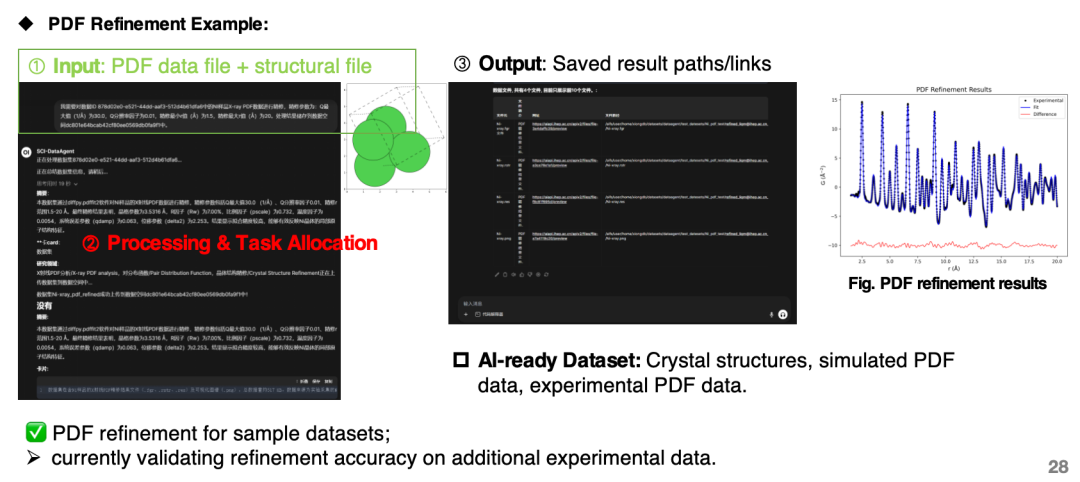
AI駆動型科学的発見システム
データ処理にインテリジェントエージェント技術を採用する理由は、AI4Sが徐々に開発トレンドとなっているためです。AIは高エネルギー物理学の研究と発見に役立ちますが、データに対する要件は高くなっています。そのため、当社は「AI4Data」から「Data4AI」の戦略を採用し、AIを使用して生データをAI対応形式に変換し、研究開発の成果を促進し、AI主導の科学的発見システムを構築しました。
張正徳研究員と彼のチームについて
張正徳博士は、中国科学院高能物理研究所の卓越した若手研究者です。中国科学院上海応用物理研究所で素粒子物理学および原子核物理学の博士号を取得しています。主な研究分野は、AIアルゴリズム、大規模モデル、科学的発見のためのインテリジェントエージェントであり、深層学習アルゴリズム、科学データ用大規模モデル、人工知能プラットフォーム、ソフトウェアシステムを網羅しています。彼の主な目標は、素粒子物理学、素粒子天体物理学、放射光、中性子科学、加速器におけるAIの応用を促進することです。

現在、張正徳研究者はGitHubで6つの代表的なオープンソースプロジェクトを発表し、CDNet、FINet、MWNetなどのニューラルネットワークの開発、高エネルギーXiwu言語モデルや科学研究エージェント「サイエンスドクター」の開発、高エネルギー物理学人工知能プラットフォームHepAI[4]の企画・構築などを行っている。同時に、「0から1プロジェクト-AIビッグモデル駆動型高エネルギー物理学科学的発見の研究」や「人工知能に基づく高エネルギー物理学ビッグデータ技術の研究と実証」など、数々の重要な科学研究プロジェクトを主宰している。
参考文献:
[1] 機械学習を用いたWAXDパターンからの3次元ナノファイバー配向の高速抽出。IUCrJ、10、3(2023)。https://doi.org/10.1107/S205225252300204X
[3] hepai-group. (nd). Open drsai [コンピュータソフトウェア]. GitHub. https://github.com/hepaihub/drsai
[4] hepai-group. (nd). HepAIプラットフォーム. https://ai.ihep.ac.cn
2023年から2024年にかけてのAI4S分野の高品質な論文と詳細な解釈記事をワンクリックで入手⬇️









