Command Palette
Search for a command to run...
画像編集における最新の技術!Qwen-Image-Edit は、セマンティック編集機能と外観編集機能の両方を兼ね備えています。Granary は、25 のヨーロッパ言語における多言語モデルのデータ不足を解決します。

画像モデルが開発され成熟するにつれて、大規模なモデルの使用に対するユーザーの要望は単一の画像生成に限定されなくなり、既存の画像に対してより詳細かつ制御可能な変更を加えたいと考えるようになりました。 「編集」は「生成」よりも詳細かつ微細な使用要件です。従来の画像編集ソフトウェア(Photoshop など)には一定の使用限界があり、ユーザーが体系的な学習を行う必要がある場合が多く、現在存在する画像編集 AI アプリケーションは、機能と効果の両方、特にテキストのレンダリングと編集機能において改善の余地があります。
これに基づいて、阿里通易千文チームは、意味と外観の二重編集機能を備えた万能画像編集モデルQwen-Image-Editをリリースしました。外観編集の指示意図を正確に理解できるだけでなく、画像の視覚スタイルの一貫性を維持しながら高度な視覚的セマンティック編集を実行できます。このモデルは、Qwen-Image の優れた中国語テキスト レンダリング機能を画像編集の分野にも拡張し、画像内のテキストを正確に編集できるようにします。
Qwen-Image の新バージョンである Qwen-Image-Edit では、画像生成からチェーン編集、最終効果のプレゼンテーションまでのクローズドループが改善され、画像の使いやすさが大幅に向上しました。複数の公開ベンチマークによる評価では、画像編集タスクにおける最先端のパフォーマンスが実証されています。
HyperAI公式サイトにて「Qwen-Image-Edit:オールインワン画像編集モデルデモ」を公開しました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/nmjYo
8月18日から8月22日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 高品質なチュートリアルの選択: 4
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
※8月提出締切:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. Granaryヨーロッパ音声認識・翻訳データセット
Granaryは、NVIDIAが公開した大規模な多言語音声データセットで、多言語ASR/ASTモデルの高品質な学習および評価用素材として設計されています。このデータセットには、ヨーロッパ25言語をカバーする約100万時間分の高品質な疑似ラベル付きASR音声データが含まれています。
直接使用します:https://go.hyper.ai/D3926
2. M3-Bench ロングビデオ質問応答ベンチマークデータセット
ByteDance Seedチームが公開した長尺動画による質問応答ベンチマークデータセット「M3-Bench」は、マルチモーダルエージェントの長期記憶および推論能力を評価するために設計されています。このデータセットには1,020本の動画サンプルが含まれており、各サンプルにはキャプション、中間出力、記憶グラフが含まれています。
直接使用します:https://go.hyper.ai/LIHsO
3. HiFiTTS-2 大規模高帯域幅音声データセット
HiFiTTS-2は、高品質なゼロショット音声合成(TTS)モデルの学習と評価を支援するために設計された、大規模で高帯域幅の音声データセットです。このデータセットには、5,000人の話者による音声メタデータが含まれており、22.05kHzで約36,700時間、44.1kHzで約31,700時間の英語音声録音が、帯域幅品質とサンプリングレートに基づいて階層化されています。
直接使用します:https://go.hyper.ai/XZwDD
4. CulturalGround多言語文化視覚質問応答データセット
CulturalGroundは、カーネギーメロン大学のNeuLabが公開した、文化知識の整合を目的とした多言語・マルチモーダルな視覚的質問応答データセットです。ニッチな文化実体やリソースの少ない言語を対象とした、マルチモーダル大規模言語モデルの理解と推論能力の向上を目指しています。
直接使用します:https://go.hyper.ai/wayAA
5. HPDv3 人間の嗜好データセット
HPDv3は、MizzenAIと香港中文大学のMMLabによって公開された、人間の嗜好に関する初の広域データセットです。関連論文はICCV 2025に選出されています。このデータセットは、テキストから画像を生成するモデルのアライメント、順列、評価を目的として設計されており、人間の美的感覚に合致したモデルの開発と意味的一貫性の向上を目指しています。
直接使用します:https://go.hyper.ai/xV8fK
6. COREVQA ビジュアル質問応答ベンチマークデータセット
アルゴバースAI研究センターが公開した視覚的質問応答ベンチマークデータセット「COREVQA」は、群衆シーンにおける視覚言語モデル(VLM)の推論能力を評価するために設計されています。このデータセットは主に現実世界の混雑シーンを特徴としており、オクルージョン、視点の変化、背景干渉といった課題に重点を置いています。複雑な社会的シナリオにおけるVLMのきめ細かな知覚と推論能力の向上を目指しています。
直接使用します:https://go.hyper.ai/tOFNw
7. DDOS UAV深度と障害物セグメンテーションデータセット
DDOSは、ドローンの自律飛行におけるアルゴリズム開発を促進するために設計された合成航空画像データセットです。データセットは環境タイプごとに厳密に分類されています。トレーニングセットは300回の飛行から合計30,000枚の画像、検証セットは20回の飛行から合計2,000枚の画像、テストセットは20回の飛行から合計2,000枚の画像で構成されています。
直接使用します:https://go.hyper.ai/XRE6R

8. Nemotron マルチドメイン推論データセット
Nemotronは、NVIDIAが公開したマルチドメイン推論データセットで、Llamaモデルの推論効率と精度を向上させるために設計されています。このデータセットには、会話、コード、数学、STEM、ツールコールの5つのカテゴリをカバーする2,566万のサンプルが含まれています。
直接使用します:https://go.hyper.ai/WP2Ym
9. Document Haystack マルチモーダルドキュメントベンチマークデータセット
Document Haystackは、Amazon AGIが公開したマルチモーダル文書ベンチマークデータセットです。400種類の文書バリアントと8,250件の検索質問が含まれており、長く複雑なコンテキストを持つ文書における視覚言語モデル(VLM)の情報検索および理解能力を評価することを目的としています。
直接使用します:https://go.hyper.ai/Q08Xt
10. CSEMOTIONS感情音声データセット
CSEMOTIONSは、制御性と自然言語音声生成の研究を支援するために設計された感情音声データセットです。このデータセットには、穏やか、幸せ、怒りなど7つの感情カテゴリーを網羅した約10時間分の高品質音声データが含まれており、10人のプロの声優によって録音されています。
直接使用します:https://go.hyper.ai/4fe7A
選択された公開チュートリアル
1. vLLM + Open-WebUI デプロイ Jan-v1-4B
Jan-v1-4Bは、Janチームによってリリースされた40億パラメータのオープンソース言語モデルです。インテリジェントなボディベース推論とツール呼び出しをターゲットとしたJanファミリーの最初のリリースであり、Janアプリにおける実際のワークフローシナリオに最適化されています。Qwen3-4B-Thinking-2507をベースに微調整と拡張が施されたこのモデルは、SimpleQAベンチマークで91.1%の精度を達成し、モデルの拡張とチューニングによって大幅なパフォーマンス向上が実現しました。
オンラインで実行:https://go.hyper.ai/CZf3s
2. 乳がん診断データセット機械学習分類予測チュートリアル
このチュートリアルは、ウィスコンシン乳がん診断データセット(WDBC)に基づいており、2値分類問題における機械学習プロセス全体を説明します。このチュートリアルは、特徴選択、モデルチューニング、結果の可視化といったコアロジックを理解するのに役立ち、他の疾患の診断モデル化の参考資料となります。
オンラインで実行:https://go.hyper.ai/zFjil
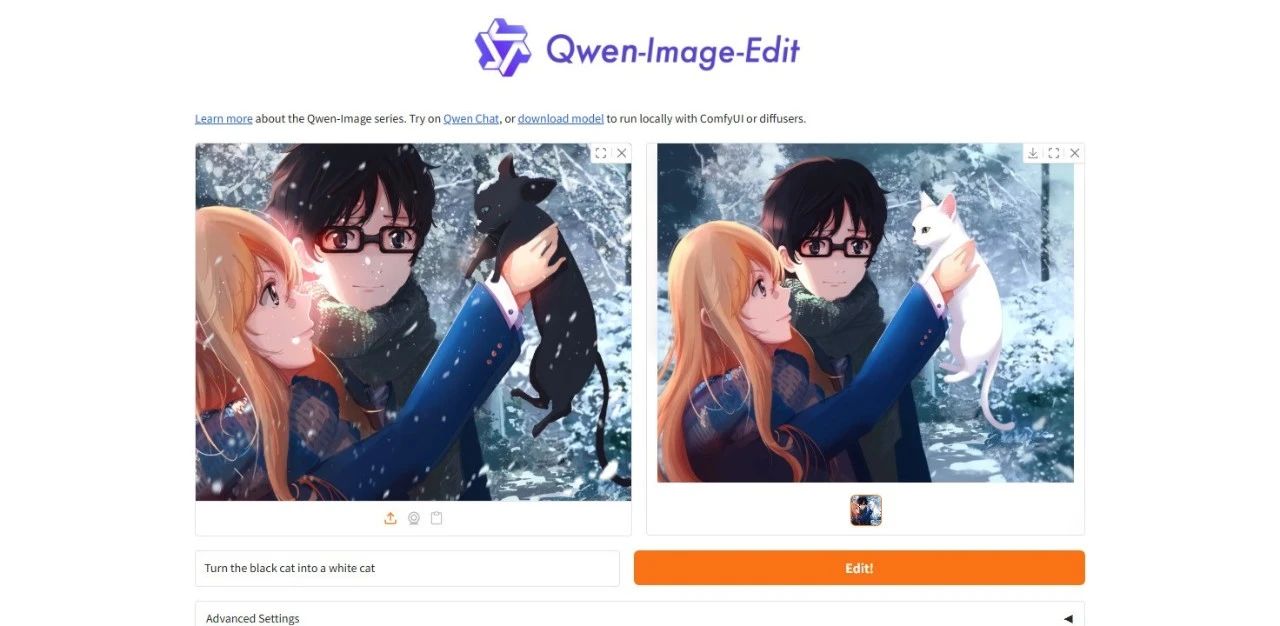
3. Qwen-Image-Edit: オールラウンドな画像編集モデルデモ
Qwen-Image-Editは、Alibaba Tongyi Qianwenチームによって開発された包括的な画像編集モデルです。セマンティック編集機能とビジュアル編集機能を組み合わせ、中国語と英語の両方でテキストの正確な編集をサポートし、画像内のテキストを元のフォント、サイズ、スタイルを維持しながら変更できます。
オンラインで実行:https://go.hyper.ai/nmjYo
4. Qwen3-4B-2507のワンクリック展開
Qwen3-4B-Thinking-2507とQwen3-4B-Instruct-2507は、アリババ同義千文チームによって開発された大規模言語モデルです。性能面では、Qwen3-4B-Thinking-2507は、複雑な問題の推論、数学的能力、コーディング能力、および複数ラウンドの関数呼び出し能力において、同規模の小型Qwen3モデルを大幅に上回っています。非推論領域では、Qwen3-4B-Instruct-2507は、知識、推論、プログラミング、アライメント、エージェント能力において、クローズドソースの小規模GPT-4.1-nanoモデルを総合的に上回り、中規模のQwen3-30B-A3B(非思考)と同等の性能に近づいています。
オンラインで実行:https://go.hyper.ai/HiqSR
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. DINOv3
本技術レポートでは、高品質な高密度特徴を生成し、幅広い視覚タスクにおいて非常に優れたパフォーマンスを発揮するDINOv3を紹介します。DINOv3は、従来の自己教師あり学習および弱教師あり学習のベースラインモデルを大幅に上回る性能を発揮します。研究者らは、多様なリソース制約や導入シナリオに対応できるスケーラブルなソリューションを提供することで、幅広いタスクとデータセットにおいて最先端の技術を進化させることを目指し、DINOv3ビジョンモデルファミリーもリリースしました。
論文リンク:https://go.hyper.ai/tBuYx
2. Ovis2.5 技術レポート
本稿では、Ovis2の後継となるOvis2.5を紹介します。Ovis2.5は、ネイティブ解像度の視覚認識と強力なマルチモーダル推論を実現するために設計されています。Ovis2.5は、ネイティブ解像度の視覚変換機能を統合し、画像をネイティブの可変解像度で直接処理することで、固定解像度のセグメンテーションに伴う画質劣化を回避しながら、細部と全体的なレイアウトを完全に維持します。
論文リンク:https://go.hyper.ai/jlEXl
3. SSRL: 自己探索強化学習
研究者らは、大規模言語モデル(LLM)が強化学習(RL)におけるエージェント探索タスクの効率的なシミュレータとして、高価な外部検索エンジンとのやり取りへの依存を低減する可能性を調査しています。実証的評価により、SSRLで学習されたポリシーモデルは、探索駆動型RL学習のための安価で安定した環境を提供し、外部検索エンジンへの依存を大幅に低減し、シミュレーションから現実世界への堅牢な移行を促進することが実証されました。
論文リンク:https://go.hyper.ai/4TFRe
4. タイム:画像を超えて考える
現時点では、オープンソースの作業ではプロプライエタリモデルに匹敵する機能セットは提供されていないため、本稿ではこの方向で予備調査を行い、マルチモーダル大規模言語モデル (MLLM) が既存の「画像を通して考える」手法を超えて、実行可能コードを通じてさまざまな画像処理と計算操作を自律的に生成および実行できるようにする Thyme (Think Beyond Images) を提案します。
論文リンク:https://go.hyper.ai/ZhLMI
5. エージェントの連鎖:マルチエージェント蒸留とエージェント強化学習によるエンドツーエンドのエージェント基盤モデル
既存のマルチエージェントシステムの多くは、手作業で作成されたプロンプトやワークフローエンジニアリングに依存し、複雑なエージェントフレームワーク上に構築されているため、計算効率が悪く、機能が限られており、データ中心学習のメリットを享受できません。本研究では、マルチエージェントシステムと同じメカニズムを用いて、単一モデル内でエンドツーエンドの複雑な問題解決をネイティブに可能にする、新たなLLM推論パラダイムであるChain-of-Agents(CoA)を提案します。
論文リンク:https://go.hyper.ai/5m3gV
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. ACL 2025 | オックスフォード大学らが医療用GraphRAGを提案し、質問回答精度の新記録を樹立し、11のデータセットでSOTA結果を達成した。
オックスフォード大学などの共同チームは、医療分野に特化したグラフベースのRAG手法「Medical GraphRAG」を提案しました。この手法は、エビデンスに基づいた回答と公式の医学用語解説を生成することで、医療分野における法学修士(LLM)の成績を効果的に向上させます。
レポート全体を表示します。https://go.hyper.ai/3458z
2. オンラインチュートリアルのまとめ | Qwenはテキストレンダリング/ビデオ作成/プログラミング支援をカバーするSOTAレベルのモデルを継続的にリリースしています
Tongyi Qianwenチームは、オープンソースモデルマトリックスの拡充を継続しており、アーキテクチャの革新、効率性の向上、そしてディープダイブシナリオにおけるブレークスルーに注力することで、業界リーダーに匹敵するパフォーマンスを実現しています。HyperAI公式サイトの「チュートリアル」セクションでは、Tongyiオープンソースモデルのチュートリアルがいくつか公開されています。
レポート全体を表示します。https://go.hyper.ai/JKJTY
3. コーネル大学は、超高速データと無線通信信号を同時に処理し、176ミリワットの電力で75%の精度を達成する「マイクロ波脳」チップを開発しました。
コーネル大学の研究チームは、超高速データと無線通信信号を同時に処理できるマイクロ波ニューラルネットワーク(MNN)と呼ばれる集積回路を提案しました。低消費電力と小型化により、高帯域幅アプリケーションに新たなソリューションを提供します。
レポート全体を表示します。https://go.hyper.ai/Cki2I
4. AIが効率的なバイオ製造を促進。華東理工大学の荘英平教授が、インテリジェントバイオ製造技術システムとその実践成果について詳細な分析を提供します。
上海交通大学2025年AIバイオエンジニアリングサマースクールにおいて、華東科技大学の荘英平教授が「AIによる効率的なバイオ製造プロセス支援」について講演しました。荘教授は、バイオ製造と合成生物学の関係、合成生物学製品の応用分野、そしてインテリジェントバイオ製造技術と実践という3つの側面から、技術システムとチームの成果を紹介しました。
レポート全体を表示します。https://go.hyper.ai/LgKcG
5. ワンストップタンパク質ゼロサンプル変異予測/機能予測:上海交通大学VenusFactoryがフルスタックタンパク質工学開発を実現
タンパク質工学分野での人工知能の広範な応用を促進するために、上海交通大学のHong Liang教授の研究グループは、生物学的データの検索、標準化されたタスクのベンチマーク、および事前トレーニング済みのタンパク質言語モデルを統合するワンストップオープンソースタンパク質工学ワークベンチVenusFactoryを開発しました。
レポート全体を表示します。https://go.hyper.ai/p3llU
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。https://go.hyper.ai/wiki

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








