Command Palette
Search for a command to run...
1000万時間分の音声データ!Higgs Audio V2音声モデルが感情表現能力を向上。MathCaptcha10kが認証コード認識技術を向上

「1000万時間の音声データをテキスト用の大規模言語モデルのトレーニングに追加したらどうなるだろうか?」この考えから、研究を経て、Li Mu氏と彼のチームBoson AIは大規模音声モデル「Higgs Audio V2」を正式にリリースした。
従来のTTS(テキスト読み上げ)システムは、機械的な音声出力を採用することが多く、感情への適応性や自然なリズムが欠けています。複数の登場人物が登場する会話では、手作業によるセグメンテーションが必要となり、モデルのみで声質と登場人物を一致させることは困難です。一方、Higgs Audio V2は、従来のTTSでは稀にしか見られない革新的な機能を導入しています。これには、ナレーション中の自動リズム適応、複数話者のダイアログを生成する機能、ゼロサンプルの音声複製とメロディックハミング、スピーチとバックグラウンドミュージックの同時生成が含まれており、オーディオ AI 機能の大きな飛躍を表しています。
EmergentTTS-Evalでは、このモデルは、感情と質問のカテゴリーでそれぞれ 75.7% と 55.7% 上回りました。これは、「感情的な相互作用」がオーディオ分野のモデルにとって重要なステップになっていることを反映しています。
現在、HyperAIの公式サイトでは「Higgs Audio V2:音声生成の表現力を再定義」が公開されています。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/Ty0CM
8月4日から8月8日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 質の高いチュートリアルの選択: 7
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
※8月提出締切:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. STRIDE-QA-Mini自動運転質問応答データセット
STRIDE-QA-Miniは、自動運転シナリオにおける視覚言語モデル(VLM)の時空間推論能力を研究するために設計された、自動運転のための質問応答データセットです。このデータセットには、103,220件の質問応答ペアと5,539枚の画像サンプルが含まれています。このデータは、東京で撮影された実際のドライブレコーダーの映像から得られています。
直接使用します:https://go.hyper.ai/9DVTI
2. MathCaptcha10k算術検証コード画像データセット
MathCaptcha10Kは、算術CAPTCHA画像のデータセットです。CAPTCHA認識アルゴリズムのテストとトレーニングを目的として設計されており、特に、背景がぼやけたり、テキストが歪んだりするCAPTCHAの認識に有効です。このデータセットには、ラベル付きの例が10,000件、ラベルなしの例が11,766件含まれています。ラベル付きの例にはそれぞれ、CAPTCHA画像、画像内の正確な文字、そしてその整数値の解答が含まれています。
直接使用します:https://go.hyper.ai/QERJt

3. CoSyn-400K マルチモーダル合成質問応答データセット
CoSyn-400Kは、ペンシルベニア大学とアレン人工知能研究所が共同で公開したマルチモーダル合成質問応答データセットです。マルチモーダルモデルの学習に高品質でスケーラブルな合成データリソースを提供することを目的としています。このデータセットには、画像とテキストによる質問と回答のペアが40万件以上含まれており、視覚的な回答タスクをサポートします。
直接使用します:https://go.hyper.ai/aNjiz
4. NonverbalTTS 非言語音声生成データセット
NonverbalTTSは、VK LabとYandexによって公開された非言語音声生成データセットです。表現力豊かなテキスト音声合成(TTS)研究を促進し、感情や非言語音を含む自然な音声を生成するモデルを支援することを目的としています。
直接使用します:https://go.hyper.ai/0Gz9V
5. GPT画像編集-150万画素画像生成データセット
GPT Image Edit-1.5Mは、カリフォルニア大学サンタクルーズ校とエディンバラ大学が公開した画像生成データセットです。画像編集モデルの学習と評価のための包括的なマルチモーダルデータリソースを提供することを目的としています。このデータセットには、150万点を超える高品質なトリプレット(指示画像、ソース画像、編集画像)が含まれています。
直接使用します:https://go.hyper.ai/ohpmD

6. UniRef50タンパク質配列データセット
UniRef50タンパク質配列データセットは、UniProt知識ベースから派生し、UniParc配列から反復クラスタリングによって生成されます。この反復プロセスにより、UniRef50の代表配列は高品質で、冗長性がなく、多様性に富み、タンパク質言語モデルのためのタンパク質配列空間を広範囲にカバーします。
直接使用します:https://go.hyper.ai/EcUF5
7. 差異認識公平性差異認識ベンチマークデータセット
Difference-Aware Fairnessは、スタンフォード大学が公開した差異認識ベンチマークデータセットです。差異認識とコンテキスト認識におけるモデルのパフォーマンスを測定することを目的としています。関連論文はACL 2025で発表され、最優秀論文賞を受賞しました。
直接使用します:https://go.hyper.ai/wwBos
8. T-Wix ロシア語 SFT データセット
T-Wix は、アルゴリズムや数学の問題の解決から会話、論理的思考、推論パターンに至るまでのモデルの機能を強化するために設計された、499,598 個のロシア語サンプルを含む SFT データセットです。
直接使用します:https://go.hyper.ai/p0sgT
9. WebInstruct検証済みマルチドメイン推論データセット
WebInstruct-verifiedは、ウォータールー大学とVector Instituteが共同で公開した多分野推論データセットです。法学修士(LLM)の数学における強みを維持しながら、多様な分野における推論能力の向上を目指しています。このデータセットには、多肢選択式問題や数式データセットなど、様々な回答形式の推論問題が約23万問収録されており、分野間でバランスよく配分されています。
直接使用します:https://go.hyper.ai/oCgsZ
10. Finance-Instruct-500k 金融推論データセット
Finance-Instruct-500kは、金融タスク、推論、およびマルチターン対話のための高度な言語モデルの学習用に設計された金融推論データセットです。このデータセットには、金融分野からの50万件を超える高品質なレコードが含まれており、金融に関する質問応答、推論、感情分析、トピック分類、多言語固有表現認識、会話型AIといった幅広い分野を網羅しています。
直接使用します:https://go.hyper.ai/03UVH
選択された公開チュートリアル
1. Higgs Audio V2: 音声生成の表現力を再定義
Higgs Audio V2は、Boson AIのLi Mu氏と彼のチームによってリリースされた大規模な音声モデルです。Seed-TTS EvalやEmotional Speech Dataset(ESD)といった従来のTTSベンチマークにおいて、最先端のパフォーマンスを達成しています。このモデルは、ナレーション中の自動韻律適応や、複数言語における自然な複数話者会話のゼロショット生成など、従来のシステムでは稀にしか見られなかった機能を備えています。
オンラインで実行:https://go.hyper.ai/BqZJD
2. Ovis-U1-3B: マルチモーダル理解・生成モデル
Ovis-U1-3Bは、アリババグループのOvisチームがリリースしたマルチモーダル統合モデルです。このモデルは、マルチモーダル理解、テキストから画像への生成、画像編集という3つのコア機能を統合しています。高度なアーキテクチャと協調的な統合学習を活用することで、高忠実度画像合成と効率的なテキストから画像へのインタラクションを実現します。
オンラインで実行:https://go.hyper.ai/oSA7p

3. Neta Lumina: 高品質な2Dスタイルの画像生成モデル
Neta Luminaは、Neta.artがリリースした高品質なアニメ風画像生成モデルです。上海人工知能研究所のAlpha-VLLMチームによるオープンソース開発であるLumina-Image-2.0をベースにしたこのモデルは、膨大な量の高品質なアニメ風画像と多言語ラベル付きデータを活用し、強力な需要理解・解釈機能を提供します。
オンラインで実行:https://go.hyper.ai/nxCwD

4. Qwen-Image: 高度なテキストレンダリング機能を備えた画像モデル
Qwen-Imageは、Alibaba Tongyi Qianwenチームによって開発された、高品質画像生成・編集のための大規模モデルです。このモデルはテキストレンダリングにおいて飛躍的な進歩を遂げ、中国語と英語の両方で複数行の段落レベルの高忠実度出力をサポートし、複雑なシーンやミリメートル単位の詳細を正確に再現します。
オンラインで実行:https://go.hyper.ai/8s00s

5. MediCLIP: CLIPを用いた少量サンプルの医用画像における異常検出
北京大学が発表したMediCLIPは、ごく少数の正常医用画像を用いて最先端の異常検出性能を実現する、効率的な少数ショット医用画像異常検出手法です。このモデルは、学習可能なキュー、アダプター、そして現実的な医用画像異常合成タスクを統合しています。
オンラインで実行:https://go.hyper.ai/3BnDy
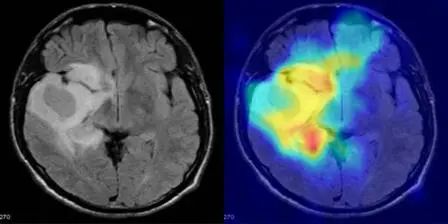
6. アイネイアスモデル:古代ローマの碑文の修復デモ
Aeneasは、Google DeepMindが複数の大学と共同で開発したマルチモーダル生成ニューラルネットワークです。ラテン語および古代ギリシャ語の碑文のテキスト修復、地理・年代推定に利用されています。このモデルの公開は、デジタル碑文学の新たな時代を告げるものです。古文書の修復、地理・年代推定、歴史研究支援といった分野におけるAeneasの潜在力は計り知れず、科学的発見や学際的な応用を加速させることが期待されています。
オンラインで実行:https://go.hyper.ai/8ROfT

7. Qwen3-Coder-30B-A3B-Instructのワンクリック展開
Qwen3-Coder-30B-A3B-Instructは、アリババのTongyi Wanxiang Labによって開発された大規模言語モデルです。プロキシコーディング、プロキシブラウザの使用、その他の基本的なコーディングタスクにおいて、オープンモデルにおいて卓越したパフォーマンスを発揮し、複数のプログラミング言語におけるコーディングタスクを効率的に処理できます。強力なコンテキスト理解機能と論理的推論機能により、複雑なプロジェクト開発やコード最適化に最適です。
オンラインで実行:https://go.hyper.ai/vYf3s
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. Qwen-Image技術レポート
Qwenファミリーの基盤となる画像生成モデルであるQwen-Imageは、複雑なテキストレンダリングと高精度な画像編集において大きな進歩を遂げました。複雑なテキストレンダリングに伴う課題に対処するため、研究者らは大規模データ取得、フィルタリング、アノテーション、合成、バランス調整を網羅した包括的なデータ処理パイプラインを設計しました。このモデルは複数のベンチマークにおいて最先端の性能を達成し、画像生成および編集タスクにおける強力な能力を存分に発揮しています。
論文リンク:https://go.hyper.ai/HWjVM
2. シード拡散:高速推論を備えた大規模拡散言語モデル
本論文では、非常に高速な推論速度を誇る離散状態拡散メカニズムに基づく大規模言語モデル「Seed Diffusion Preview」を提案する。この離散拡散モデルは、非逐次的かつ並列的な生成メカニズムによって推論効率を大幅に向上させ、従来のトークン単位のデコードに伴う遅延を効果的に軽減する。
論文リンク:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: ディープラーニングエージェントとエージェント基盤モデルの学習のためのフレームワーク
汎用AIエージェントは、複雑な推論、ネットワーク化されたインタラクション、プログラミング、そして自律的な研究を可能にする、次世代人工知能の基盤となるフレームワークとしてますます注目を集めています。本研究では、研究者らは、高度なAIエージェントの開発と評価を民主化するために設計された、完全にオープンソースで、ほぼ無料のマルチモジュール型インテリジェントエージェントフレームワークであるCognitive Kernel-Proを提案します。
論文リンク:https://go.hyper.ai/65j3v
4. 固定長を超えて:拡散大規模言語モデルのための可変長ノイズ除去
本論文では、DLLMの動的な適応的長さ拡張を可能にする、トレーニング不要の新たなノイズ除去戦略DAEDALを提案しています。様々なDLLMを用いた広範な実験により、DAEDALは、慎重に調整された固定長のベースラインモデルと同等、あるいは場合によってはそれを上回る性能を発揮し、計算効率を大幅に向上させ、より高い有効トークン比を実現することが実証されています。
論文リンク:https://go.hyper.ai/p7WxK
5. Skywork UniPic: 視覚的理解と生成のための統合自己回帰モデリング
本稿では、15億パラメータの自己回帰モデルであるSkywork UniPicを紹介します。このモデルは、タスク固有のアダプタやモジュール間コネクタに依存せず、画像理解、テキスト画像生成、画像編集を単一のアーキテクチャに統合します。Skywork UniPicは、高忠実度のマルチモーダル融合を法外なリソースコストなしで実現できることを実証することで、導入可能な高忠実度マルチモーダルAIの実用的なパラダイムを確立します。
論文リンク:https://go.hyper.ai/FiVaf
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. Nature 誌に掲載されたこの廃水疫学的評価は、遺伝子配列解析と機械学習に基づいており、最大 4 週間早くウイルスを検出できます。
ネバダ大学ラスベガス校の研究チームは、教師なし機械学習プロセス設計に基づくICA-Varと呼ばれる多変量解析手法を提案しました。この手法は、独立成分分析を用いて廃水データから共変動と時間経過に伴う変異パターンを抽出し、より早期かつ正確な変異検出を実現します。
レポート全体を表示します。https://go.hyper.ai/z1vVo
2. オンラインチュートリアル | Qwen3-Coder-Flash はオープンソース AI プログラミングの最先端技術を刷新し、Claude4 に匹敵するエージェント機能を備えています
Qwenチームは、プロキシコーディング、プロキシブラウザの利用、その他の基本的なコーディングタスクにおいて、オープンソースモデルの中でも優れたパフォーマンスを誇るQwen3-Coder-Flashをオープンソース化しました。複数のプログラミング言語でのコーディングタスクを効率的に処理できます。同時に、強力なコンテキスト理解機能と論理的推論機能により、複雑なプロジェクト開発やコード最適化においても優れたパフォーマンスを発揮します。
レポート全体を表示します。https://go.hyper.ai/FmOep
3. David Baker 氏のチームは Science 誌に、特に薬物治療が不可能なターゲットをターゲットとした、不規則領域結合タンパク質を設計するための新しいアプローチを提案しました。
天然変性タンパク質を標的とする問題に対処するため、David Bakerと彼のチームは、Logosと呼ばれるタンパク質設計戦略を提案しました。この戦略は、タンパク質が様々な拡張構造で天然変性領域に結合し、側鎖が相補的な結合ポケットに挿入されることを可能にします。本研究では、RF拡散モデルを活用してポケットを再編成し、幅広い配列に一般化することで、設計された結合タンパク質-標的ペプチドテンプレートに基づいて、タンパク質の変性領域を普遍的に認識することを可能にします。
レポート全体を表示します。https://go.hyper.ai/F0lti
4. 設計されたタンパク質変異体は活性が50倍に増加しました!清華大学AIRの周昊チームは、ベイズフローネットワークに基づくAMix-1を提案し、スケーラブルで汎用的なタンパク質設計を可能にしました。
清華大学知能産業研究所の周浩教授の研究グループは、上海人工知能研究所と共同で、ベイズフローネットワークに基づくタンパク質基礎モデルAMix-1を提案しました。彼らは、事前学習スケーリング則、創発能力、文脈学習、テスト時スケーリングといった体系的な手法を初めて用いてタンパク質基礎モデルを構築し、大規模言語モデルの成功パラダイムをタンパク質設計に導入しました。その効率性と汎用性は、テスト時スケーリングと実実験によって検証されました。
レポート全体を表示します。https://go.hyper.ai/X9iMe
5. GPT-5 がリリースされました。Sam Altman: プログラミング、ライティング、健康面で重要なアップグレードが行われており、博士号を持つ専門家と話しているような感じです。
OpenAIはGPT-5を正式にリリースし、ChatGPTの最も一般的な3つのユースケースであるライティング、プログラミング、健康におけるパフォーマンスをさらに向上させました。GPT-5は、ほとんどの質問に答えるためのインテリジェントで効率的なモデル(GPT-5-main)、より複雑な問題のための深層推論モデル(GPT-5-thinking)、そして会話の種類、質問の複雑さ、必要なツール、ユーザーの明示的な意図に基づいて使用するモデルを迅速に決定するリアルタイムルーターで構成される統合システムです。
レポート全体を表示します。https://go.hyper.ai/gFHQg
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。https://go.hyper.ai/wiki
サミットの締め切りは8月
8月21日 11:59:59 ASPLOS 2026
8月27日 7:59:59 USENIXセキュリティシンポジウム2025
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








