Command Palette
Search for a command to run...
設計されたタンパク質変異体の活性が50倍に増加しました!清華大学AIRの周昊チームは、ベイズフローネットワークに基づくAMix-1を提案し、スケーラブルで汎用的なタンパク質設計を実現しました。

現在、タンパク質ペデスタルモデル分野の研究は「BERT」時代に停滞しており、タンパク質配列の生物学的特性に十分に適応できていません。これまで、AlphaFoldやESMなどのAIモデルは、構造予測、逆フォールディング、機能特性予測、変異効果評価、タンパク質設計など、複数の分野で大きな進歩を遂げてきました。しかし、これらのモデルには、最先端の大規模言語モデル (LLM) に類似したスケーラブルで体系的な方法論がまだ欠けており、データ量、モデル規模、コンピューティング リソースの増加に合わせて機能を継続的に向上させることはできません。
このようなモデルの普遍性の欠如は、タンパク質設計の分野で解決困難な課題をもたらしました。モデルはタンパク質の構造的異質性を捉えることができず、タンパク質設計に関する予測はトレーニングデータの範囲を超えることができません。また、NLP 方法論の転送に過度に依存しているため、タンパク質の特性をターゲットにした独自のアーキテクチャ設計が不足しています。
このような状況において、清華大学知能産業研究所(AIR)の周浩氏の研究グループは、上海人工知能研究所と共同で、ベイズフローネットワークに基づく体系的にトレーニングされたタンパク質ベースモデルAMix-1を提案し、タンパク質設計のためのスケーラブルで汎用的なパスを提供しました。このモデルは、「事前トレーニングスケーリング法則」、「創発能力」、「コンテキスト学習」、「テスト時間スケーリング」の体系的な方法論を初めて採用し、これに基づいて多重配列アライメント(MSA)に基づくコンテキスト学習戦略を設計し、モデルのスケーラビリティを確保しながら、タンパク質設計の一般的なフレームワークの一貫性を実現しました。
関連する研究結果は、「AMix-1: テスト時間スケーラブルなタンパク質基盤モデルへの道」というタイトルで arXiv プラットフォームで公開されました。
研究のハイライト:
* ベイズフローネットワークに基づくタンパク質生成モデルに対して予測可能なスケーリング則が確立されました。
* AMix-1 モデルは、明示的な構造監視を必要とせずに、シーケンス レベルのトレーニング目標のみを通じて、タンパク質構造の「知覚的理解」を自発的に開発します。
* 多重配列アライメント (MSA) に基づくコンテキスト学習フレームワークは、機能最適化におけるアライメント問題を解決し、進化的コンテキストでのモデルの推論および設計機能を向上させ、AMix-1 が保存された構造と機能を持つ新しいタンパク質を生成できるようにします。
* 検証予算が増加したときに新しい進化ベースの設計アプローチを可能にするために、検証コストに基づいたテスト時間延長アルゴリズムを提案します。
用紙のアドレス:
公式アカウントをフォローし、「AMix」と返信すると完全なPDFが手に入ります。
AIフロンティアに関するその他の論文:
UniRef50データセット:前処理と反復クラスタリング
研究者らは、モデルの事前学習に前処理済みのUniRef50データセットを使用しました。EvoDiffによって提供されるこのデータセットは、UniProtKBから派生し、反復クラスタリング(UniProtKB+UniParc → UniRef100 → UniRef90 → UniRef50)によってUniParc配列からフィルタリングされています。41,546,293個のトレーニング配列と82,929個の検証配列を含む。1,024残基を超える配列は、計算コストを削減し、多様なサブ配列を生成するために、ランダムプルーニング戦略を用いて1,024残基にトリミングされた。この反復プロセスにより、UniRef50配列の高品質で冗長性のない多様な表現が保証され、タンパク質言語モデルのためのタンパク質配列空間の広範なカバレッジが提供される。
UniRef50 データセットをダウンロードしてください:
体系的な技術的ソリューション
AMix-1 は、タンパク質台座モデルのテスト時間のスケーリングを実装するための体系的な技術ソリューションの完全なセットを提供します。
* 事前トレーニングのスケーリング則:モデルの能力を最大限に引き出すために、パラメータ、サンプル数、計算量のバランスをどのように取ればよいかは明らかです。
* 出現能力:トレーニングが進むにつれて、モデルがタンパク質構造の「知覚的理解」を獲得していくことが示されています。
* コンテキスト学習:機能最適化におけるアライメント問題を解決し、モデルが進化的コンテキストで推論と設計を学習できるようにします。
* テスト時間のスケーリング:AMix-1 は、検証予算の増加に応じて進化ベースの設計への新しいアプローチを実現します。
AMix-1 は、トレーニング、推論から設計に至るまで、タンパク質基盤モデルとしての汎用性と拡張性を実証し、実用的な実装への道を切り開きました。
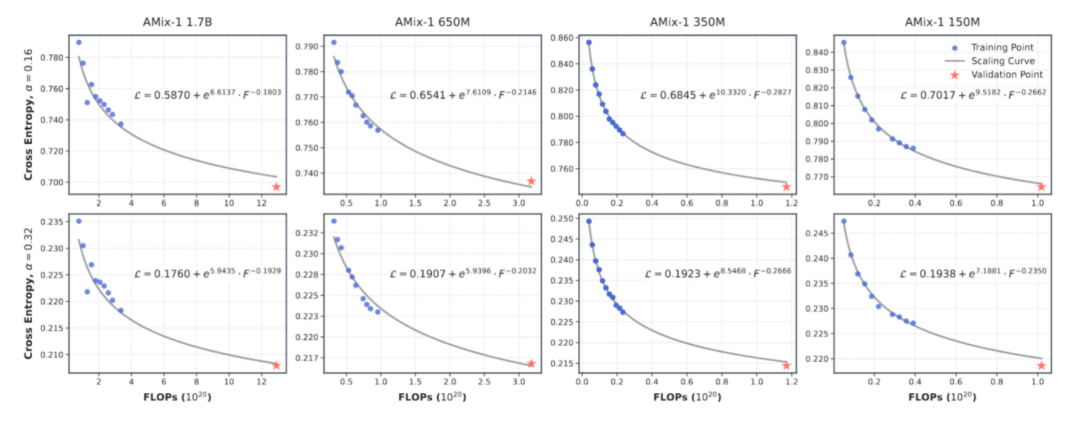
事前学習スケーリング則:予測可能なタンパク質モデル機能
AMix-1 の予測可能なスケーリング則を実現するために、本研究では、実験において 800 万から 17 億の範囲のパラメータを持つマルチスケール モデルの組み合わせを設計し、トレーニング浮動小数点演算 (FLOP) を統一された測定指標として使用して、モデルのクロスエントロピー損失と計算量との間のべき乗法則の関係を正確に適合および予測しました。
結果から判断すると、モデル損失と計算量の間のべき乗曲線は非常に一貫しており、ベイジアンフローネットワークに基づくモデルトレーニングプロセスが非常に予測可能であることが確認されます。
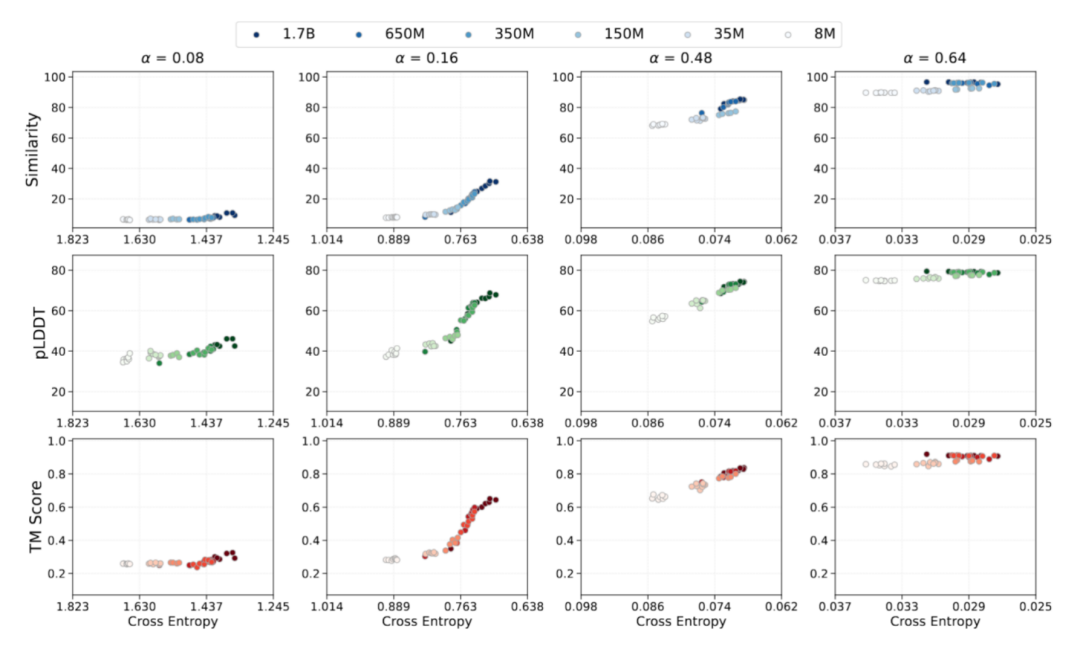
創発的能力:高度なモデル機能の実現
タンパク質配列学習において、構造創発の研究は一般的に「配列-構造-機能」パラダイムに基づいています。タンパク質モデリングにおける最適化ダイナミクスと機能的成果の関連性を検証するため、研究チームは予測可能なスケーリング則に基づく損失重視の観点から、創発挙動を分析しました。予測クロスエントロピー損失をアンカーとして用い、学習損失とタンパク質生成性能を経験的にマッピングしました。本研究では、モデルの創発能力を以下の3つの側面に焦点を当てて評価しました。
* シーケンスの一貫性の観察に基づいて、破損したシーケンス分布からシーケンス レベルを回復するモデルの能力。
* 折り畳み可能性の観点から、配列理解から構造実現可能性へのモデルの移行。
* 構造の一貫性からモデルの構造特性を維持する能力を判断する。
AMix-1 トレーニング中の関連データは、タンパク質ベースモデルの「配列の一貫性、折り畳み可能性、および構造の一貫性」機能の出現プロセスを完全に示しています。データは、トレーニング中のモデルのすべての能力指標がクロスエントロピー損失と高い相関関係にあることを示しており、スケーリング法則とクロスエントロピー損失を通じてモデルの能力を予測する可能性を検証しています。同時に、シーケンスレベルの自己教師あり学習のみで構造情報を導入せずにトレーニングすると、クロスエントロピー損失がしきい値まで低下した後もモデルは緊急能力を示し、pLDDT と TM スコア間の非線形遷移を示します。
インコンテキスト学習:タンパク質設計の一般的なパラダイム
研究者らはコンピュータシミュレーションケースを通じて、AMix-1の文脈内学習メカニズムを検証した。シミュレーションケース実験では、AMix-1 は、明示的なラベルや構造の監視に依存せずに、入力サンプルから構造的または機能的な制約を正確に抽出し、一般化することができます。
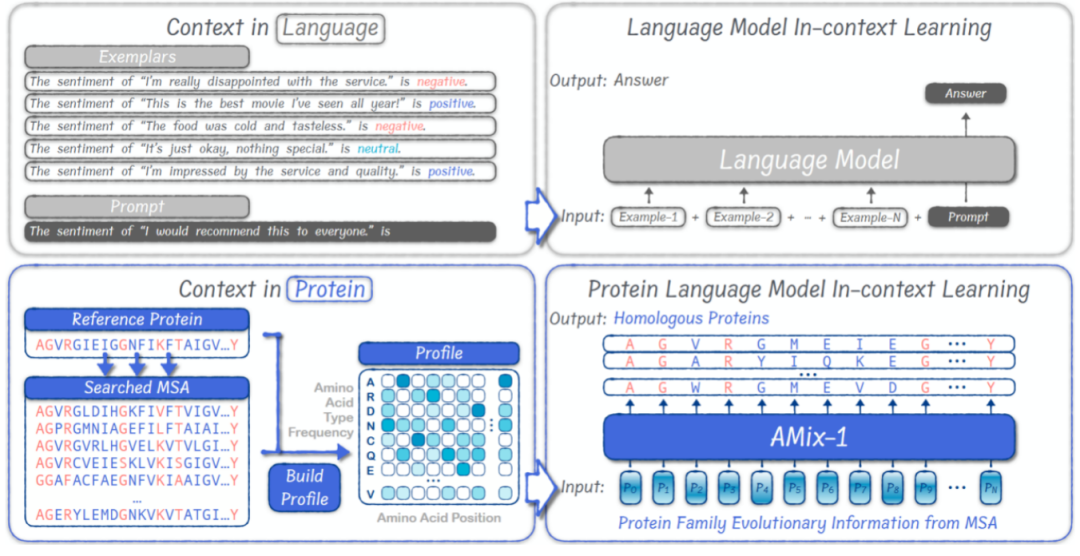
従来のタンパク質設計はタスクの種類に応じてカスタマイズされたプロセスを必要とし、統一されたタンパク質設計フレームワークが欠如していましたが、AMix-1は大規模言語モデル内にコンテキスト内学習(ICL)メカニズムを導入することで、構造と機能に基づいたタンパク質設計を実現します。実験では、構造タスクにおいて、AMix-1は従来の相同タンパク質、あるいは実質的に相同性のないタンパク質を手がかりとして、非常に一貫性のある予測構造を持つ新規タンパク質を生成できることが示されています。機能タスクにおいて、AMix-1は入力タンパク質の酵素機能と化学反応に基づいた設計に基づき、非常に一貫性のあるプロテアーゼを生成できます。
この一般的なメカニズムでは、このモデルは、特定のタンパク質グループ内の共通情報とルールを自動的に推測し、これらのルールを使用して共通ルールに準拠する新しいタンパク質の生成をガイドします。このメカニズムは、タンパク質のMSA群を位置レベルの確率分布(プロファイル)に圧縮し、モデルに入力します。入力されたタンパク質の構造と機能ルールを迅速に分析した後、モデルは意図を満たす新しいタンパク質を生成します。
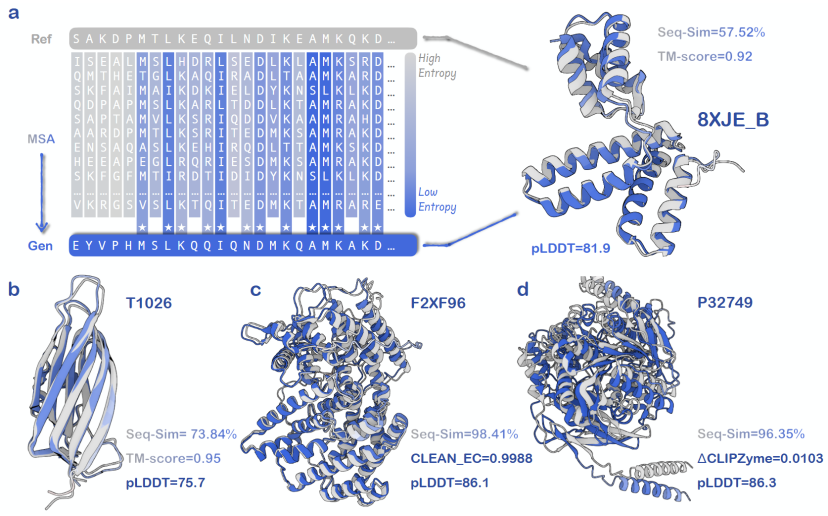
テスト時間のスケーリング:スケーラブルな汎用インテリジェンス
研究者たちは、テスト時間スケーリングアプローチに基づき、Proposer-Verifierフレームワークを用いてEvoAMix-1を構築しました。検証バジェットを継続的に増加させることで、AMix-1のモデル性能を向上させました。モデルの設計効率を高めると同時に、スケーラビリティも実現しました。さらに、互換性を確保するため、検証器のプロパティに対する事前定義された要件を排除しました。
EvoAMix-1は、確率モデルに内在するランダム性に基づく探索を促進します。タスク固有のコンピュータシミュレーション報酬関数や実験的検出フィードバックを統合することで、進化的制約下で候補タンパク質配列を反復的に生成・スクリーニングします。モデルの微調整なしに効率的なタンパク質指向進化を実現し、タンパク質設計において堅牢かつテスト時間スケーラブルな性能を実現します。6 つの設計タスクすべてにおいて、EvoAMix-1 は、In-Context Learning およびさまざまな強力なベースライン メソッドにおいて AMix-1 を一貫して上回ります。
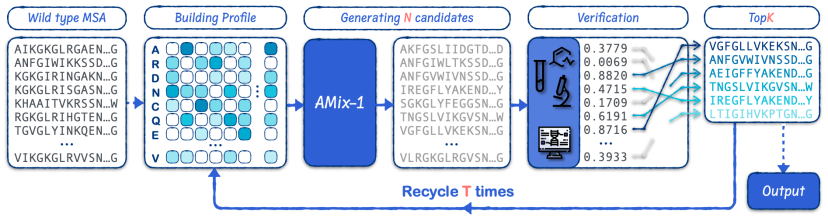
重要度サンプリングによる新しいタンパク質変異体を生成する従来の方法と比較して、EvoAMix-1 はモデルパラメータを更新せず、代わりにコンテキスト例を通じて提案分布を構築します。各ラウンドで、AMix-1 は、タンパク質基本モデルの入力条件として考慮される、多重配列アラインメント (MSA) のセットまたはそのスペクトルをヒントとして受け取り、次に隣接する配列をサンプリングして、新しい条件付き提案分布を効果的に定義します。
研究チームは、酵素の最適pHおよび温度進化、機能の維持と強化、オーファンタンパク質の設計、そして一般的な構造誘導最適化など、いくつかの代表的なタンパク質指向進化タスクにおいて、EvoAMix-1の汎用性と拡張性を体系的に検証しました。実験結果は、EvoAMix-1のテスト時間スケーリングの堅牢な拡張性を示し、タスクと目的全体にわたる高い汎用性を示しています。
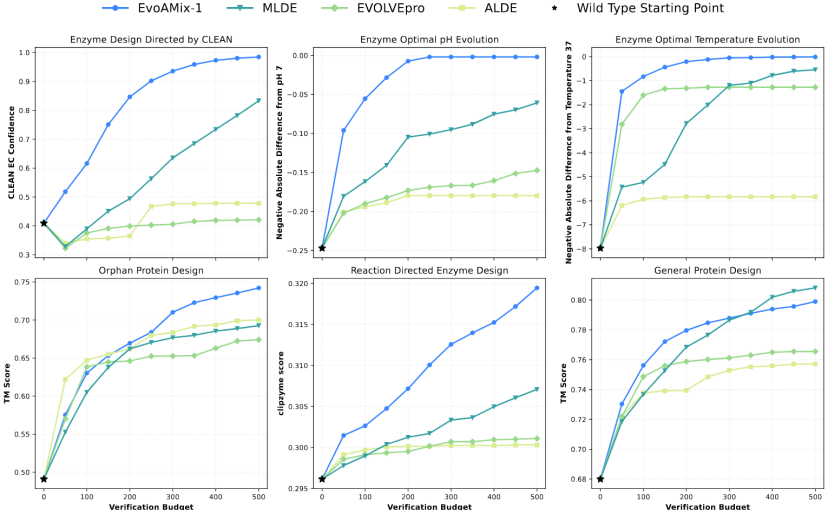
ウェット実験検証:AMix-1は活性を50倍に高めたタンパク質AmeR変異体の開発を支援する
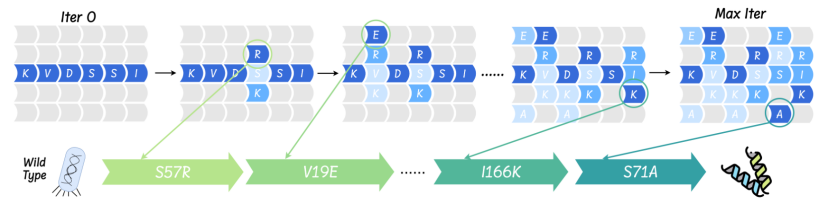
本研究では、「コンテキストキュード設計」戦略を実際のウェット実験で検証し、AMix-1が高活性AmeRバリアントを効率的に設計する上での利点をさらに検証しました。研究者らは標的タンパク質AmeRを選択し、AMixモデルを用いてAmeRファミリーの確率分布に基づいて40のバリアントを生成しました。各バリアントの阻害能力は蛍光レポーター遺伝子実験によって評価されました。各バリアントは10個以下のアミノ酸変異のみを含み、抑制係数が高いほど機能が強くなることが示されました。さらに、本研究では、AMix-1のタンパク質誘導進化への適用性を高めるための進化試験用スケーリングアルゴリズムを提案し、様々なコンピュータシミュレーション標的領域指標を用いてその性能を検証しました。
最終結果は、AMix-1 によって生成された最適なバリアントは、アクティビティが最大 50 倍向上し、現在の SOTA モデルと比較してパフォーマンスが約 77% 向上します。さらに、AMix-1 は繰り返しのスクリーニングや手動設計に依存せず、モデルによって完全に自動的に生成されます。「モデルから実験まで」の完全な閉ループを実現し、AIによる機能性タンパク質設計の初めてのブレークスルーを達成しました。
グローバルトポロジーと知覚がタンパク質設計に新たな次元を開く
現在、AIとタンパク質設計の融合研究が盛んに行われています。AMix-1に加え、清華大学生命科学学院の龔海鵬氏と北京生命科学研究所の徐春富氏によって提案された、形状を考慮した拡散モデルTopoDiffも、タンパク質設計において大きな進歩を遂げています。
RFDiffusionなどの従来の拡散モデルは、免疫グロブリンなどの特定のフォールドタイプを生成する際にカバレッジバイアスが発生するだけでなく、タンパク質全体のトポロジーに対する定量的な評価指標も欠いています。本研究では、CATHやSCOPeなどの構造データベースに基づき、教師なしシステムであるTopoDiffフレームワークを提案しました。このフレームワークは、グローバルな幾何学的潜在表現を学習・活用することで、拡散モデルに基づく無条件かつ制御可能なタンパク質生成を実現します。本研究では、新たな評価指標「カバレッジ」を提案します。これは、2段階のエンコーダー拡散モデルフレームワークを通じて、タンパク質構造をグローバルな幾何学的設計図とローカルな原子座標生成に分離することで、タンパク質フォールドカバレッジに関する研究上の課題を克服します。
さらに、NVIDIAはカナダのケベック人工知能研究所Milaと共同で、AlphaFoldアーキテクチャに基づく改良型全原子生成モデルを用いて、長鎖予測の課題を克服しました。従来の手法では、非常に長い鎖(500残基以上)の全原子構造生成が困難であるだけでなく、膜タンパク質特有のポケットといった非古典的なフォールディング構造を探索することもできません。研究チームは確率的意思決定メカニズムを導入し、決定論的なフォールディング軌跡を量子場理論に基づく経路積分サンプリングに置き換えることで、膜タンパク質設計の成功率を68%まで向上させました。
タンパク質の折り畳み構造を幾何学的にセンシングすることから、500残基を超える長鎖の設計、自然言語駆動型のタンパク質設計、そして「創薬不可能」なIDPの標的化まで、AIはタンパク質設計能力の限界を広げ、この分野の研究に新たなパラダイムを提供しています。将来的には、AI駆動型のタンパク質設計は、革新的な治療薬、酵素、生体材料の開発に向けたさらなる道を切り開くことが期待されています。
参考リンク:








