Command Palette
Search for a command to run...
ACL 25 最優秀論文!スタンフォード大学が差異を考慮した公平性構築のための差異を考慮したベンチマークデータセットを公開。セルフフォーシングにより、1秒未満の遅延でリアルタイムストリーミング動画生成を実現

AI モデルは、従来の「平等な扱い」を公平性と同一視することがよくあります。法的な文脈や損害評価のシナリオでは、公平性を実現するために「非差別的取扱い」の原則を機械的に適用することは、普遍的な解決策ではありません。公平性の単一の側面では偏った結果になりやすいため、グループ間の違いを考慮する必要があることが示唆されます。そのため、大規模モデルを推進し、「区別のない公平性」から「認識された違いに基づく公平性」へのパラダイムシフトを段階的に達成することがますます重要になっています。
これに基づいて、スタンフォード大学は、差異認識とコンテキスト認識におけるモデルのパフォーマンスを測定することを目的とした Difference Aware Fairness ベンチマーク データセットをリリースしました。関連する研究成果は、ACLの25のベストペーパーに選出されました。データセットには8つのベンチマークが含まれており、記述型タスクと規範型タスクの2種類に分かれており、法律、専門職、文化など、様々な現実世界のシナリオを網羅しています。各ベンチマークには2,000問の質問が含まれており、そのうち1,000問は異なるグループ間の差別化を必要とするため、合計16,000問となっています。このベンチマークの公開は、大規模モデルの公平性という側面を改善し、技術開発と社会価値のギャップを埋めるための貴重な補足となり、AIエコシステムのより多様で正確な方向への深層的な進化を強力に促進します。
Difference Aware Fairness Benchmark Dataset が HyperAI の公式ウェブサイトで公開されました。今すぐダウンロードしてお試しください!
オンラインでの使用:https://go.hyper.ai/XOx97
7月28日から8月1日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 5
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 8月に締め切りを迎えるトップカンファレンス:9
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
B3DBは、カナダのマクマスター大学が公開した大規模な生物学的ベンチマークデータセットです。低分子血液脳関門透過性モデリングのベンチマークを提供することを目的としています。このデータセットは50の公開リソースから編集されており、これらの分子の物理化学的特性のサブセットを提供しています。一部の分子については数値logBB値が提供されていますが、データセット全体には数値データとカテゴリデータの両方が含まれています。
直接使用します:https://go.hyper.ai/0mPpP
アニメは、 http://MyAnimeList.net このデータベースは、データサイエンティスト、機械学習エンジニア、そしてアニメ愛好家のために、リッチでクリーン、かつアクセスしやすいリソースを提供することを目的としています。データセットには28,000作品以上のアニメ作品に関する情報が収録されており、アニメ界のトレンドに関する洞察を提供します。
直接使用します:https://go.hyper.ai/MxrqC
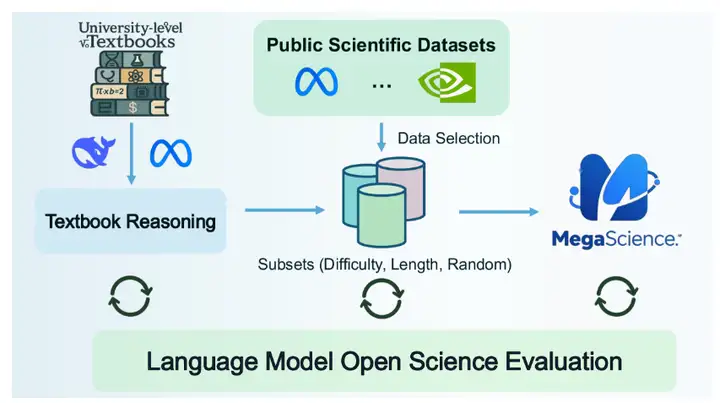
MegaScienceは、上海交通大学が公開した科学的推論データセットです。このデータセットには125万件のインスタンスが含まれており、自然言語処理(NLP)と機械学習モデルをサポートするように設計されています。特に、科学研究分野における文献検索、情報抽出、自動要約、引用分析といったタスクに適しています。
直接使用します:https://go.hyper.ai/694qh
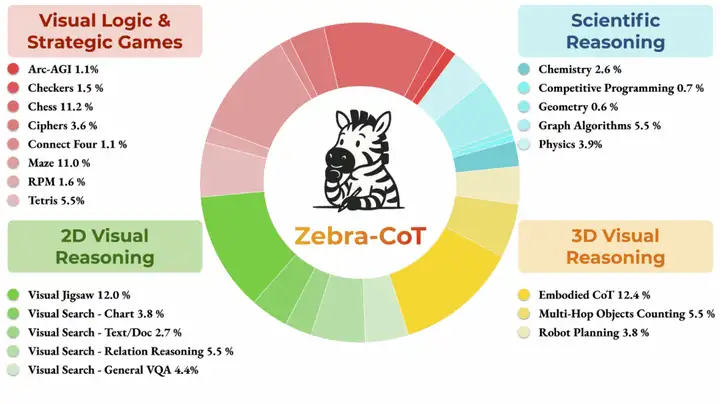
4. Zebra-CoTテキストから画像への推論データセット
Zebra-CoTは、コロンビア大学、メリーランド大学、南カリフォルニア大学、ニューヨーク大学が共同で公開した視覚言語推論データセットです。画像とテキスト間の論理的関係をモデルがより深く理解できるようにすることを目的としています。視覚的な質問応答や画像説明生成などの分野で広く利用されており、推論能力と精度の向上に貢献しています。データセットには182,384件のサンプルが含まれており、科学的推論、2D視覚推論、3D視覚推論、ビジュアルロジックおよび戦略ゲームの4つの主要カテゴリを網羅しています。
直接使用します:https://go.hyper.ai/y2a1e
PolyMathは、アリババと上海交通大学が共同で公開した数学的推論データセットです。博学者の研究を促進することを目的としています。このデータセットには、各言語レベルごとに125問ずつ、合計500問の高品質な数学的推論問題が含まれています。
直接使用します:https://go.hyper.ai/yRVfY
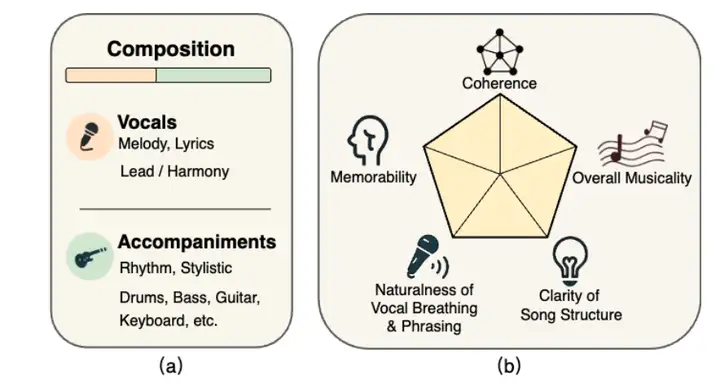
SongEvalは、上海音楽学院、西北理工大学、サリー大学、香港科技大学が共同で公開した音楽評価データセットです。楽曲全体の美的評価を目的としています。このデータセットには、ボーカルとインストゥルメンタルを含む2,399曲以上が収録されており、16人の専門評価者によって、全体的な一貫性、記憶しやすさ、ボーカルの呼吸とフレージングの自然さ、楽曲構成の明瞭さ、そして全体的な音楽性の5つの知覚的側面についてアノテーションが付けられています。このデータセットには、中国語と英語の楽曲、そして9つの主要ジャンルを網羅した約140時間分の高品質オーディオが含まれています。
直接使用します:https://go.hyper.ai/ohp0k
7. Vchitect T2Vビデオ生成データセット
Vchitect T2Vは、上海人工知能研究所が公開した動画生成データセットです。テキストと視覚コンテンツ間の翻訳モデル能力の向上を目指しており、研究者や開発者が画像生成、意味理解、クロスモーダルタスクの進歩に貢献します。このデータセットには、詳細なテキストキャプションが付与された1,400万本の高品質動画が含まれています。
直接使用します:https://go.hyper.ai/vLs9z
LEDは、176,861点の碑文を収録した、これまでで最大の機械可読ラテン語碑文データセットです。しかし、これらの碑文のほとんどは部分的に損傷しており、使用可能な画像が得られたTP3T碑文はわずか51点です。このデータは、最も包括的なラテン語碑文データベースである3つのデータベース、すなわちローマ碑文データベース(EDR)、ハイデルベルク碑文データベース(EDH)、そしてクラウス=スラビーデータベースから取得されています。
直接使用します:https://go.hyper.ai/O8noU
9. AutoCaptionビデオキャプションベンチマークデータセット
AutoCaptionデータセットは、Tjunlp Labsが公開した動画キャプション生成のベンチマークデータセットです。動画キャプション生成のためのマルチモーダル大規模言語モデル分野の研究を促進することを目的としています。データセットには2つのサブセットが含まれており、合計11,184個のサンプルが含まれています。
直接使用します:https://go.hyper.ai/pgOCw
ArtVIPは、北京ヒューマノイドロボットイノベーションセンターが公開した機械インタラクティブ画像データセットです。このデータセットには、26のカテゴリーにわたる206個の関節オブジェクトが含まれています。精密な幾何学メッシュと高解像度テクスチャによる視覚的なリアリティを確保し、細かく調整された動的パラメータによる物理的な忠実度を実現しています。また、アセット内にモジュール式のインタラクティブな動作を組み込むことで、ピクセルレベルのアフォーダンスアノテーションを可能にした初のデータセットです。
直接使用します:https://go.hyper.ai/vGYek

選択された公開チュートリアル
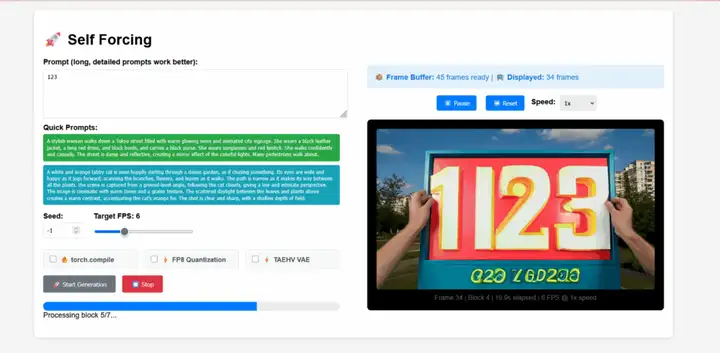
Self-Forcingは、Xun Huangのチームが提案した自己回帰型動画拡散モデルのための新しい学習パラダイムです。長年の課題である露出バイアス、つまり実環境下で学習したモデルが推論時に自身の不完全な出力に基づいてシーケンスを生成しなければならないという問題に対処します。このモデルは、単一のGPUで1秒未満のレイテンシでリアルタイムストリーミング動画生成を実現し、同時に、はるかに低速で因果関係のない拡散モデルと同等、あるいはそれ以上の精度を実現します。
オンラインで実行:https://go.hyper.ai/j19Hx
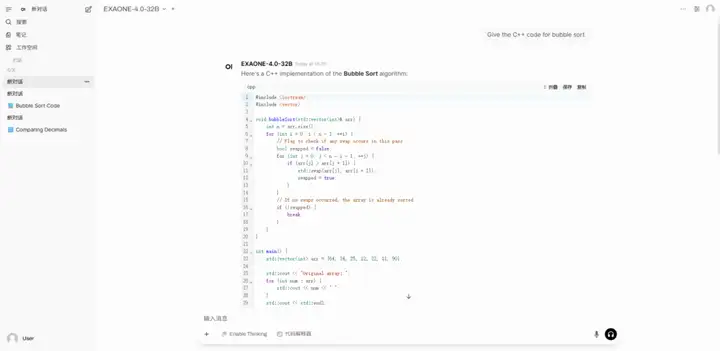
2. vLLM + Open WebUIを使用してEXAONE-4.0-32Bをデプロイする
EXAONE-4.0は、韓国のLG AI Researchが発表した次世代ハイブリッド推論AIモデルです。韓国初のハイブリッド推論AIモデルでもあります。このモデルは、一般的な自然言語処理能力とEXAONE Deepで検証された高度な推論能力を融合し、数学、科学、プログラミングといった難解な分野における画期的な進歩を実現します。
オンラインで実行:https://go.hyper.ai/7XiZM
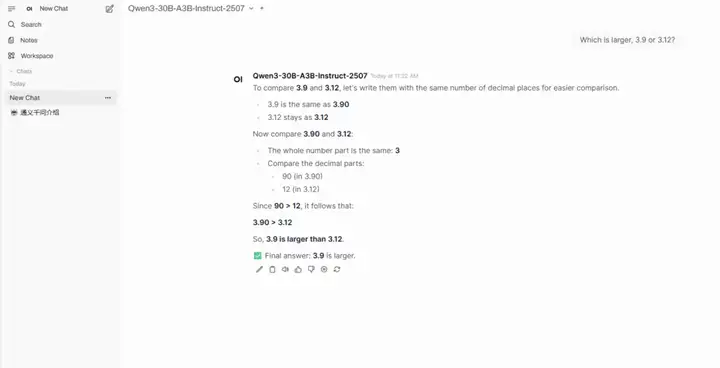
3. Qwen3-30B-A3B-Instruct-2507のワンクリック展開
Qwen3-30B-A3B-Instruct-2507は、アリババの同益万向研究所が開発した大規模言語モデルです。このモデルは、Qwen3-30B-A3Bの非思考モードのアップデート版です。その最大の特徴は、わずか30億(3B)のパラメータをアクティブにしただけで、GoogleのGemini 2.5-Flash(非思考モード)やOpenAIのGPT-4oに匹敵する驚異的な性能を発揮することです。これは、モデル効率と性能最適化における大きな進歩です。
オンラインで実行:https://go.hyper.ai/hr1o6
4. Wan2.2: オープンな先進的大規模ビデオ生成モデル
Wan-2.2は、アリババのTongyi Wanxiang Labが開発したオープンソースの高度なAI動画生成モデルです。このモデルはMixture of Experts(MoE)アーキテクチャを導入し、生成品質と計算効率を効果的に向上させます。また、映画美学制御システムの先駆者であり、照明、色、構図、その他の美的効果を精密に制御できます。
オンラインで実行:https://go.hyper.ai/AG6CE
5. PE3R: 効率的な認識と3D再構成のためのフレームワーク
PE3R(Perception-Efficient 3D Reconstruction)は、シンガポール国立大学(NUS)のXMLラボがリリースした革新的なオープンソース3D再構築フレームワークです。マルチモーダル知覚技術を統合し、効率的でインテリジェントなシーンモデリングを実現します。最先端のコンピュータービジョン研究の成果に基づいて開発され、2D画像のみから3Dシーンを迅速に再構築します。RTX 3090グラフィックスカードでは、1シーンの平均再構築時間はわずか2.3分で、従来の手法と比較して65%以上の高速化を実現しています。
オンラインで実行:https://go.hyper.ai/3BnDy

今週のおすすめ紙
実世界の推論シナリオにおいて、大規模言語モデル(LLM)はタスク解決を支援する外部ツールの恩恵を受けることがよくあります。しかし、既存の強化学習アルゴリズムは、モデル固有の長距離推論能力と、複数ラウンドにわたるツールインタラクションにおける熟練度とのバランスを取るのに苦労しています。このギャップを埋めるために、本論文では、複数ラウンドのLLMベースエージェントのトレーニングに特化して設計された、新しいエージェント強化学習アルゴリズムであるエージェント強化ポリシー最適化(ARPO)を提案します。ARPOは、既存手法の半分のツール使用予算でパフォーマンス向上を実現し、LLMベースエージェントをリアルタイムの動的環境に適応させるためのスケーラブルなソリューションを提供します。
論文リンク:https://go.hyper.ai/lPyT2
2. HunyuanWorld 1.0: 言葉やピクセルから没入型、探索型、インタラクティブな3Dワールドを生成する
テキストや画像から没入型でインタラクティブな3D世界を生成することは、コンピュータビジョンとグラフィックスにおける根本的な課題です。既存の世界生成手法は、3Dの一貫性の不足やレンダリング効率の低さといった制約を抱えています。この課題を解決するため、本論文では、テキストや画像から没入型で探索可能かつインタラクティブな3Dシーンを生成する革新的なフレームワーク、HunyuanWorld 1.0を提案します。
論文リンク:https://go.hyper.ai/aMbdz
3. ScreenCoder: モジュール型マルチモーダルエージェントによるフロントエンド自動化のためのビジュアルからコードへの生成の進化
大規模言語モデル(LLM)を用いたテキストからコードへの生成は近年進歩しているものの、既存の手法の多くは自然言語の手がかりのみに依存しており、レイアウトの空間構造や視覚的なデザイン意図を効果的に捉えるのに苦労しています。一方、現実世界のUI開発は本質的にマルチモーダルであり、多くの場合、視覚的なスケッチやプロトタイプから始まります。このギャップを埋めるために、本稿では、ローカリゼーション、プランニング、生成という3つの解釈可能なフェーズを通じてUIからコードへの生成を可能にする、モジュール式のマルチエージェントフレームワークであるScreenCoderを提案します。
論文リンク:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: 実世界のショートビデオの構造化理解
現在の大規模マルチモーダルモデルは、効果的な動画検索・推奨、そして新たな動画アプリケーションの基盤となる、時間的に構造化された、詳細かつ深層的な動画理解能力を欠いています。本研究では、生の動画入力から映像、音声、テキスト信号をエンドツーエンドで処理し、構造化された理解を実現するマルチモーダルモデル、ARC-Hunyuan-Videoを提案します。このモデルは、多粒度のタイムスタンプ付き動画記述・要約、自由記述形式の動画質問応答、時間的視点からの動画位置推定、そして動画推論といった機能を備えています。
論文リンク:https://go.hyper.ai/ogYbH
複雑で長大な研究レポートを作成するために、一般的なテスト時間スケーリングアルゴリズムを使用すると、パフォーマンスがボトルネックになることがよくあります。人間の研究プロセスの反復的な性質に着想を得て、本論文ではテスト時間拡散ディープリサーチャー(TTD-DR)を提案します。TTD-DRは、研究の方向性を導く進化する基盤として機能する予備的なドラフト(更新可能なフレームワーク)からプロセスを開始します。このドラフト中心の設計により、レポート作成プロセスはよりタイムリーで一貫性のあるものになり、反復的な検索中の情報損失を削減します。
論文リンク:https://go.hyper.ai/D4gUK
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
北京大学のShi Boxin氏が率いるチームは、OpenBayesのベイジアンコンピューティングと共同で、テキスト誘導によるパノラマ動画生成フレームワーク「PanoWan」を発表しました。このアプローチは、ミニマルで効率的なモジュール型アーキテクチャを採用しており、事前学習済みのテキスト動画モデルの生成的事前分布をパノラマ領域にシームレスに移植します。
レポート全体を表示します。https://go.hyper.ai/9UWXl
2. 評価精度は99%を超えます!このYOLOv11ベースのインテリジェント陶磁器分類フレームワークは、視覚モデリングと経済分析を統合し、文化財の分類と価値評価を実現します。
マレーシア・プトラ大学(UPM)とニューサウスウェールズ大学(UNSW)シドニー校の研究チームは、YOLOv11モデルをベースとした陶磁器工芸品の自動分類と市場価値推定のためのインテリジェントフレームワークを共同で開発しました。最適化されたYOLOv11モデルは、装飾模様、形状、職人技といった陶磁器の主要な属性を識別し、抽出した視覚的特徴と複数のオークションデータに基づいて市場価格を予測することができます。これにより、陶磁器のインテリジェントな真贋判定とデジタル遺物のキュレーションのためのスケーラブルなソリューションが実現します。
レポート全体を表示します。https://go.hyper.ai/XcuLz
3. ペンシルバニア大学は、動物毒から 386 個の新しい抗菌ペプチドを特定し、潜在的な抗生物質候補をスクリーニングするためのディープラーニング モデル APEX を開発しました。
米国ペンシルベニア大学の研究チームは、4つの主要な毒データベースを統合してグローバルな毒データベースを構築し、毒液プロテオームから抗菌性候補物質を体系的に探索するために使用される「APEX」と呼ばれる配列関数深層学習モデルを適用しました。最終的に、抗菌性があり、既知のAMPとの配列類似性が低い386個の候補ペプチドを選別しました。
レポート全体を表示します。https://go.hyper.ai/u067l
4. NVIDIA/UC Berkeleyらは、15日間の予報を1分で完了し、シングルカードの超高速推論をサポートする機械学習天気予報システムFCN3を提案しました。
NVIDIA、ローレンス・バークレー国立研究所、カリフォルニア大学バークレー校、カリフォルニア工科大学の共同研究チームは、球面信号処理と隠れマルコフ集合フレームワークを組み合わせた確率的機械学習天気予報システム「FourCastNet 3(FCN3)」を発表しました。このシステムは、NVIDIA H100 GPU 1基で60秒以内に15日間の予報を生成できます。
レポート全体を表示します。https://go.hyper.ai/JQh25
5. オンラインチュートリアル | 世界初!萌え動画生成モデル!アリババWan2.2オープンソース化、コンシューマーグレードのグラフィックカードで映画のようなAI動画制作を実現
アリババのTongyi Wanxiang Labは最近、高度なAI動画生成モデル「Wan2.2」をオープンソース化しました。Mixture of Experts(MoE)アーキテクチャを導入したこのモデルは、動画生成の品質と計算効率を効果的に向上させ、NVIDIA RTX 4090などのコンシューマーグレードのグラフィックスカードでの効率的な動作を可能にします。また、照明、色、構図、その他の美的効果を正確に制御できる、映画美的制御システムの先駆者でもあります。
レポート全体を表示します。https://go.hyper.ai/RgFmY
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








