Command Palette
Search for a command to run...
2,500問!HLEは大規模言語モデルの正確な評価システムの構築において画期的な進歩を遂げました。40億のパラメータを持つ軽量な大規模言語モデルであるJan-Nanoは、深い研究タスク向けに設計されています。

近年、大規模言語モデル(LLM)は飛躍的な進歩を遂げ、質問への回答やコンテンツ作成といった多様なタスクを処理できるようになり、その高い能力を発揮しています。ベンチマークはLLMの開発能力を評価するための重要なツールであり、LLMの能力向上・強化のための参考資料として重要です。しかし、現在広く普及しているベンチマークは難易度設計が不十分であり、最先端のLLMは既存の多くの評価において類似した高スコアを達成しています。そのため、LLMの能力測定の精度が制限され、大規模モデルの能力向上の余地が曖昧になっています。
これを基に、AI Safety CenterとScale AIが共同で、マルチモーダルな人間の問題ベンチマークデータセット「Humanity's Last Exam (HLE)」をリリースしました。人類の知識の限界をカバーする究極の印章の構築を目指す閉鎖評価するシステム。このデータセットは、数十の科目領域からの 2,500 の質問で構成されており、正確で効果的な LLM 能力測定基準を提供し、現在の LLM 能力と専門学者との間のギャップを明確にし、最先端の知識領域における LLM 能力の急速な向上をより良く達成することに取り組んでいます。
現在、HyperAI Super Neural Network公式サイトでは「HLE Human Problem Reasoning Benchmark Dataset」が公開されていますので、ぜひお試しください。
データセットのダウンロード:
7月14日から7月18日まで、hyper.ai公式サイトが更新されました。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 5
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 7月に締め切りを迎えるトップカンファレンス:4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. GSM8K数学推論データセット
GSM8Kは、OpenAIが2022年に公開した数学推論データセットで、複雑な数学問題の理解と解決における機械学習モデルの性能向上を目指しています。このデータセットには、代数、算術、幾何学などの分野を網羅した、高品質で言語多様性に富んだ小学校向け算数文章題が8,500問収録されています。問題の解答手順は2~8ステップで、基本的な算術演算(加算、減算、乗算、除算)を用いた一連の簡単な計算で最終的な答えを導き出します。
直接使用します:https://go.hyper.ai/ZqNLt
2. 作物病害データセット
Crops Diseaseは、様々な作物の病気を自動的に検出・分類するコンピュータビジョンモデルの開発を支援するために設計された、農作物病害画像データセットです。このデータセットには、トウモロコシ、トマト、ジャガイモなど、様々な作物に共通する病気を網羅した約1,300枚の農作物病害画像が含まれており、各画像には特定の病気カテゴリーがアノテーションされています。
直接使用します:https://go.hyper.ai/GEDTA

3. OpenScience マルチドメイン合成データセット
OpenScienceは、NVIDIAが2023年にリリースしたマルチドメイン合成データセットであり、教師ありファインチューニングまたは強化学習を通じて、GPQA-DiamondやMMLU-Proといった高度なベンチマークの精度向上を目指しています。このデータセットには、STEM、法律、経済学、人文科学など、複数の科学分野を網羅する、詳細な推論トレースを備えた600万件の多肢選択式質問と回答のペアが含まれています。
直接使用します:https://go.hyper.ai/YvAo7
4. Skywork-OR1-RL 数理計画問題推論データセット
Skywork-OR1-RLは、Skywork-OR1(Open Reasoner 1)数理計画法推論モデルの学習用に設計された数理計画法問題推論データセットです。このデータセットには、検証可能で難易度が高く、多様性に富んだ10万5千個の数学問題と1万4千個のプログラミング問題が含まれています。
直接使用します:https://go.hyper.ai/mxoAv
5. 鳥類分類画像データセット
Bird Speciesは、鳥類の種を識別・分類するためのコンピュータービジョンモデルの学習に適した鳥類画像分類データセットです。このデータセットには7種類の鳥類が含まれており、それぞれ1,200枚の画像が含まれています。各種の画像には、その種の鳥の羽の模様、色、体の構造が含まれています。一部の画像は意図的にぼかしや傾きが加えられており、異なる種の鳥が2羽写っているため、現実世界の複雑さが増し、自然環境における正確な分類を可能にする堅牢なモデルとなっています。
直接使用します:https://go.hyper.ai/X2X2M

6. NextCoder コード編集データセット
NextCoderは、Microsoftが2025年にリリースした合成対話コーディング編集データセットです。大規模言語モデルの微調整に使用され、コード修復、リファクタリング、最適化におけるモデルのパフォーマンス向上に役立ちます。AIプログラミングアシスタントのトレーニング、コード読み取りおよびマルチラウンドインタラクション機能の向上に非常に適しています。このデータセットには、約381,000個のシングルラウンド命令サンプル(NextCoderDataset)と約57,000個のマルチラウンド対話サンプル(Conversational version)が含まれており、PythonやJavaなど8つの言語をカバーしています。
直接使用します:https://go.hyper.ai/e4MIs
7. Psych-101 心理学知識質問応答データセット
Psych-101は、心理学知識に基づく質問応答データセットです。心理学知識に基づく質問応答タスクのための自然言語処理モデルの開発を支援し、心理学関連のAI研究、特に心理学教育、感情分析、メンタルヘルス分野における研究を促進することを目的としています。このデータセットには、160件の心理学実験と60,092人の参加者から得られた試行ごとのデータが含まれており、合計10,681,650の選択肢が含まれています。
直接使用します:https://go.hyper.ai/NUshw
8. 白血病 白血病画像データセット
白血病は、白血病細胞を自動的に検出・分類するコンピュータービジョンモデルの学習用に設計された白血病細胞画像データセットです。このデータセットには、正常細胞(3,389個)と白血病細胞(3,389個)を含む6,778枚の細胞画像が含まれています。
直接使用します:https://go.hyper.ai/Lwxwj
9. X線胸部肺炎X線画像データセット
胸部肺炎のX線画像は、コンピュータービジョンモデルの学習と評価を目的として設計された胸部X線画像のデータセットです。自動診断システムが肺炎などの呼吸器疾患を検出できるよう支援します。このデータセットには、約5,800枚の胸部X線画像が含まれており、正常と肺炎(細菌性およびウイルス性)の2つのカテゴリに分類されています。
直接使用します:https://go.hyper.ai/Pgra4
10. 土壌水分 土壌水分画像データセット
土壌水分は、土壌水分が作物の生育に及ぼす影響の研究、灌漑システムの最適化、農業生産効率の向上を目的とした、測定に基づく土壌水分データセットです。気候変動や水資源管理といった分野においても重要な応用が期待されています。このデータセットには、インドネシア、ボンドウォソの天水農業地域の土壌表面画像200枚が含まれています。
直接使用します:https://go.hyper.ai/TtpgP

選択された公開チュートリアル
今週は、質の高い公開チュートリアルを 4 つのカテゴリにまとめました。
*AI for Scienceチュートリアル:2
*テキスト認識チュートリアル: 1
*マルチモーダルチュートリアル:1
*大型モデルチュートリアル:1
AI科学チュートリアル
1. RF拡散:拡散タンパク質設計モデル
RFdiffusionはタンパク質構造生成フレームワークです。RoseTTAFoldをバックボーンネットワークとして利用し、ノイズ除去拡散確率モデル(DDPM)を導入することで、ゼロから新しいタンパク質構造を設計できます。このフレームワークは、複雑な形状(αヘリックスやβフォールドなど)を持つタンパク質を設計し、酵素の触媒部位の骨格を正確に予測することができます。
オンラインで実行:https://go.hyper.ai/q7Ajs
2. バイオムニ:初の汎用バイオ医薬品
Biomni は、遺伝学、ゲノミクス、微生物学、薬理学、臨床医学など、複数の生物医学分野にわたる複雑な研究タスクを自律的に完了できる汎用生物医学 AI エージェントであり、AI 主導の科学的発見の発展における新たな段階を示しています。
オンラインで実行:https://go.hyper.ai/aameS
テキスト認識チュートリアル
1. OCRFlux-3B: インテリジェントテキスト認識ツールキット
OCRFlux-3Bは、PDFや画像をクリーンで読みやすいプレーンなMarkdownテキストに変換するための、マルチモーダル大規模言語モデルに基づくツールキットです。ページレベルのテキスト変換機能だけでなく、ページをまたがる表や段落の結合もサポートしており、複雑な文書構造の処理を強力にサポートします。
オンラインで実行:https://go.hyper.ai/BGqmR
マルチモーダルチュートリアル
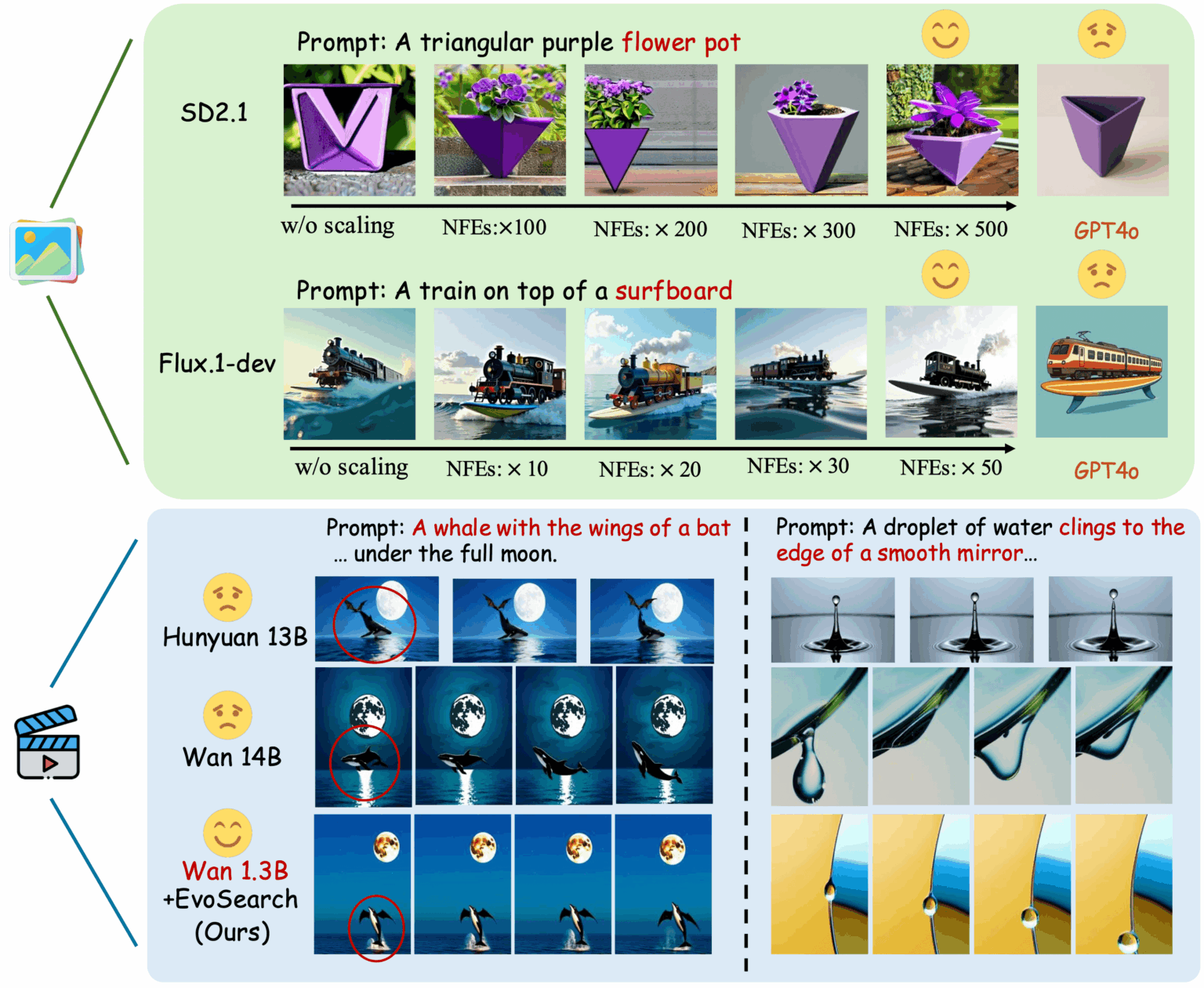
1. EvoSearch-codes: 進化的アルゴリズムフレームワーク
EvoSearch-codesは、香港科技大学と快手克玲チームによって開発された進化的探索手法です。推論時の計算量を増やすことでモデル生成品質を大幅に向上させ、画像・動画生成をサポートし、最先端の拡散ベースおよびフローベースモデルをサポートします。このモデルは、学習や勾配更新を必要とせず、一連のタスクにおいて優れた最適結果を達成でき、優れたスケールアップ能力、堅牢性、汎化性を備えています。
オンラインで実行:https://go.hyper.ai/zjzrE
大規模モデルのチュートリアル
1. Jan-Nano: コンパクトな研究専用言語モデル
Jan-Nano は、Menlo Research チームによって 2025 年 7 月 1 日にリリースされた 40 億パラメータの軽量大規模言語モデルです。これは、詳細な研究タスク向けに設計されており、さまざまな研究ツールやデータ ソースとの効率的な統合を容易にするために、Model Context Protocol (MCP) サーバー向けに最適化されています。
オンラインで実行:https://go.hyper.ai/mC8gx
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. 反射型生成モデルによるテスト時間のスケーリング
本論文では、自己教師ありプロセス報酬モデル(SPRM)を用いてOpenAI o3と同等の性能を実現する、初の反射型生成モデルであるMetaStone-S1を紹介します。バックボーンネットワークを共有し、次トークン予測とプロセススコアリングにそれぞれタスク固有のヘッドを用いることで、SPRMはポリシーモデルとプロセス報酬モデル(PRM)を統合インターフェースに統合することに成功しました。これにより、追加のプロセスアノテーションを必要とせず、PRMパラメータを99%以上削減し、効率的な推論を実現しています。
論文リンク:https://go.hyper.ai/zFLhf
2. Open Vision Reasoner:言語認知行動を視覚推論に応用する
本論文では、Qwen2.5-VL-7Bに基づく2段階パラダイムを提案します。まず、大規模な言語コールドスタートによる微調整を行い、続いて約1000ステップのマルチモーダル強化学習(RL)を実施します。これは、これまでのオープンソースの試みを凌駕するものです。最終モデルであるOpen-Vision-Reasoner(OVR)は、MATH500で95.3%、MathVisionで51.8%、MathVerseで54.6%など、様々な推論ベンチマークにおいて最先端のパフォーマンスを達成しました。
論文リンク:https://go.hyper.ai/WucU8
3.推論か記憶か?データ汚染による強化学習の信頼性の低い結果
研究者らは、Qwen2.5は数学的推論において優れた性能を発揮するものの、大規模なウェブコーパスを用いた事前学習によって、一般的なベンチマークにおけるデータ汚染の影響を受けやすく、その結果、これらのベンチマークから得られる結果の信頼性に影響を与えることを発見しました。この問題に対処するため、研究者らは任意の長さと難易度の完全に合成された算術問題を生成できるジェネレータを導入し、「RandomCalculation」と呼ばれるクリーンなデータセットを作成しました。このリークフリーデータセットを用いることで、正確な報酬信号のみが継続的にパフォーマンスを向上させることができ、ノイズや誤りのある信号はパフォーマンスを向上させることができないことが証明されました。
論文リンク:https://go.hyper.ai/WZp4V
4. NeuralOS: ニューラル生成モデルによるオペレーティングシステムのシミュレーションに向けて
本稿では、マウスの動き、クリック、キーボードイベントなどのユーザー入力に応じて画面フレームを直接予測することで、オペレーティングシステムのグラフィカルユーザーインターフェース(GUI)をシミュレートするニューラルフレームワーク、NeuralOSを紹介します。NeuralOSは、コンピュータの状態を追跡するリカレントニューラルネットワーク(RNN)と、画面イメージを生成する拡散ベースのニューラルレンダラーを組み合わせています。NeuralOSは、将来のヒューマンコンピュータインタラクションシステムのための、完全に適応型の生成型ニューラルインターフェースを構築するための道筋を提供します。
論文リンク:https://go.hyper.ai/hceCb
5. CLiFT: 計算効率と適応性に優れたニューラルレンダリングのための圧縮ライトフィールドトークン
本論文では、シーンの豊かな外観と形状を維持しながら、シーンを「圧縮ライトフィールドトークン(CLiFT)」として表現するニューラルレンダリング手法を提案します。CLiFTは、圧縮トークンを用いることで計算効率の高いレンダリングを実現すると同時に、単一の学習済みネットワーク内でトークンの数を変更することで、シーンを表現したり、新たな視点をレンダリングしたりすることも可能です。
論文リンク:https://go.hyper.ai/aqzHX
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
Meta FAIR、ケンブリッジ大学、MITの共同研究チームは、全原子拡散Transformer ADiTを提案しました。これは、周期系と非周期系の間のモデリング障壁を打ち破るものです。全原子統合潜在表現とTransformer潜在拡散という2つの大きな革新により、単一モデルによる分子と結晶の生成において画期的な進歩を遂げました。
レポート全体を表示します。https://go.hyper.ai/Dnw5r
2. タンパク質の主鎖と側鎖の情報を同時に処理し、スタンフォードらはメッセージパッシングニューラルネットワークに基づく完全な原子構造モデリングを実現した。
スタンフォード大学の研究チームとカリフォルニア州パロアルトのアーク研究所は共同で、各アミノ酸残基の配列同一性と側鎖構造を明示的にモデル化できる新たなタンパク質配列設計手法FAMPNN(Full-Atom MPNN)を提案しました。このモデルは、グラフニューラルネットワークに基づくメッセージパッシングアーキテクチャを採用し、改良されたMPNNとGVPモジュールを組み合わせ、フルアトムエンコーディングを実現することで、タンパク質の主鎖と側鎖の情報を同時に処理できます。
レポート全体を表示します。https://go.hyper.ai/x04Am
3. オンラインチュートリアル | 150の専門ツール/59のデータベース/105のソフトウェアパッケージを備えたBiomniは、8つの実際の研究タスクで専門家レベルの効率性を超えています
スタンフォード大学は、ジェネンテック、アーク研究所、カリフォルニア大学サンフランシスコ校(UCSF)などの機関と共同で、世界初の汎用バイオメディカルAIエージェント「Biomni」を開発しました。Biomniは、様々なバイオメディカル分野にまたがる幅広い研究タスクを自律的に実行し、25のバイオメディカル分野における数万件もの論文から必要なツール、データベース、ソリューションをマイニングする、世界初の統合環境エージェントを構築できます。システムベンチマークでは、Biomniがタスク固有のプロンプト調整なしに、異種バイオメディカルタスクにおいて強力な汎化能力を発揮することが示されています。
レポート全体を表示します。https://go.hyper.ai/VHpMD
4. アーキテクチャの特徴からエコシステムの構築まで、Muxi Dong Zhaohuaは国産GPUにおけるTVMの応用実践を深く分析しています。
7月5日、HyperAI主催の第7回Meet AIコンパイラ技術サロンが盛況のうちに終了しました。Muxi Integrated Circuitのシニアディレクターである董兆華氏は、Muxi GPUへのTVMの適用方法について詳しく説明し、同社GPU製品の技術的特徴、TVMコンパイラ適応ソリューション、実際の応用事例、エコシステム構築ビジョンを紹介しました。また、高性能コンピューティング(HyperAI)分野における国産GPUの技術革新と応用ポテンシャルを示しました。
レポート全体を表示します。https://go.hyper.ai/rxxX3
5. NVIDIAは原子レベルのタンパク質設計で画期的な進歩を達成し、最大800残基のタンパク質を高精度で生成しました。
NVIDIAの研究チームは、カナダのケベック人工知能研究所のMilaと共同で、部分的な潜在フローマッチングに基づく原子レベルのタンパク質設計手法であるLa-Proteinaを提案しました。この手法は、タンパク質生成における明示的な側鎖表現の次元変動という重要な課題に対処し、タンパク質設計分野に新たなブレークスルーをもたらします。
レポート全体を表示します。https://go.hyper.ai/0Sw8R
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは7月
7月11日 7:59:59 ポピュラリティ 2026
7月15日 7:59:59 ソーダ2026
7月18日 7:59:59 シグモッド 2026
7月19日 7:59:59 ICSE2026
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








