Command Palette
Search for a command to run...
ICML 2025に選出!ハーバード大学医学部らがHIE分野で世界初の臨床マインドマップモデルを発表、神経認知的成果予測タスクにおいて15%の性能向上を実現

人工知能技術が飛躍的に進歩するにつれ、大規模視覚言語モデル (LVLM) が複数の分野の認知境界を驚異的な速度で再形成しています。自然画像やビデオ解析の分野では、このタイプのモデルは、高度なニューラル ネットワーク アーキテクチャ、大規模なラベル付きデータ セット、強力なコンピューティング サポートを利用することで、オブジェクト認識やシーン分析などの高度なタスクを正確に完了できます。自然言語処理の分野では、LVLMは、TBレベルのテキストコーパスを学習することで、機械翻訳、テキスト要約、感情分析といったタスクにおいてプロフェッショナルレベルのパフォーマンスを実現しています。LVLMが生成する学術要約は、医学文献の核心的な結論を正確に抽出することさえ可能です。
しかし、テクノロジーの波が医療分野に押し寄せるにつれ、LVLMの導入は大きな抵抗に直面しています。臨床現場におけるインテリジェントな補助診断の需要は非常に切実であるにもかかわらず、こうしたモデルの医療応用は依然として初期段階にあります。根本的なボトルネックは、医療データの独特な特性に起因しています。患者のプライバシー保護規制、医療データアイランド効果、倫理審査メカニズムなどの複数の制約により、公開されている高品質の医療データセットの規模は、一般分野の 1 万分の 1 にすぎません。既存の医療データセットのほとんどは、基本的な視覚的な質問応答アーキテクチャを使用しており、「これはどの解剖学的構造ですか?」などの主要なパターン認識タスクに重点を置いています。——たとえば、公開データセットには 20 万件の X 線注釈が含まれていますが、90% の注釈コンテンツは臓器の局在レベルにとどまっており、病変の重症度分類や予後リスク評価などの中核的な臨床ニーズには対応できません。
このデータ供給と実際の需要の不一致により、モデルは新生児低酸素性虚血性脳症 (HIE) の MRI 画像に直面したときに基底核の異常な信号を識別できますが、妊娠期間や周産期の病歴などの多次元情報を統合して神経発達の予後を予測することはできません。
このジレンマを克服するために、ボストン小児病院、ハーバード大学医学大学院、ニューヨーク大学、MIT-IBMワトソン研究所の学際的チームが、低酸素性虚血性脳症(HIE)の患者133名の10年間のMRI画像と専門家の解釈を収集しました。専門レベルの医療推論ベンチマークデータセットを構築し、医療専門分野におけるLVLMの推論性能を正確に評価することを目的としています。研究チームは臨床マインドマップモデル(CGoT)も提案した。臨床知識に基づいたマインドマッピングプロンプトを通じて診断プロセスをシミュレートする機能により、ドメイン固有の臨床知識を視覚的およびテキスト入力として組み込むことができ、LVLM の予測力が大幅に強化されます。
「プロフェッショナルレベルの思考グラフによる医療推論のための視覚的およびドメイン知識」と題された関連研究成果が、ICML 2025 に選定されました。
研究のハイライト:
* 臨床視覚認識と専門的な医学知識を初めて組み合わせ、臨床意思決定プロセスをシミュレートし、医学的推論における LVLM の専門的なパフォーマンスを正確に評価する新しい HIE 推論ベンチマーク テストを作成します。
* 高度な一般 LVLM と医療 LVLM を包括的に比較して、医療分野の知識に関する限界を明らかにし、モデル改善の方向性を示します。
* 医療の専門知識と LVLM を統合し、臨床意思決定プロセスを模倣し、医療意思決定サポートを効果的に強化する CGoT モデルを提案しました。

用紙のアドレス:
https://openreview.net/forum?id=tnyxtaSve5
AIフロンティアに関するその他の論文:
https://go.hyper.ai/owxf6
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
HIE-推論:マルチモーダルデータセットの構築と専門的推論タスクシステムの作成
データ構築の観点から、本研究は重篤な新生児疾患である低酸素性虚血性脳症 (HIE) に焦点を当てています。10 年間にわたり、生後 0 〜 14 日の HIE 児童 133 名の高品質 MRI 画像が収集されました。同時に、多分野の専門家(30 年の経験を持つ上級神経放射線科医を含む)によって臨床的に検証された解釈レポートを取得し、長期追跡のための中核データ セットを形成します。
下の図に示すように、研究者は LVLM が専門的な臨床推論を実行するための 6 つのタスクを定義しました。
* タスク 1: 病変のグレーディング。このタスクでは、HIE 病変によって影響を受ける脳容積の割合を推定し、病変の重症度を評価することで、脳損傷を定量化します。
* タスク 2: 病変の解剖。このタスクでは、病変によって影響を受けた脳の特定の領域を特定します。
* ミッション 3: まれな場所の病変。このタスクは、HIE によって引き起こされた病変を識別し、影響を受けた領域を一般的な領域と一般的な領域に分類して、患者に追加の注意が必要かどうかを判断するのに役立ちます。
* タスク 4: MRI 損傷スコア。このタスクは、MRI から全体的な損傷スコアを出力し、治療の指針となり結果を予測するための損傷の重症度の標準化された尺度を提供します。
* タスク 5: 2 年間の神経認知的成果。このタスクは、患者の 2 年後の神経認知的結果を予測し、臨床医が長期的な影響を予想して適切な介入を計画するのに役立ちます。
* タスク 6: MRI 解釈の概要。このタスクは、放射線科医が推奨する新生児 MRI 概要テンプレートに基づいており、患者に対する包括的な MRI 解釈を生成することができます。
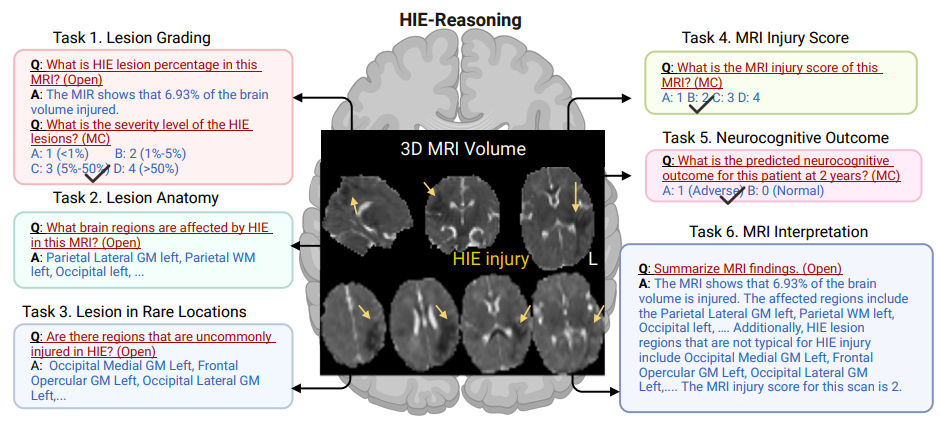
ファイナル、研究者らは、749 の質問と回答のペアと 133 の MRI 解釈の要約を含む、世界初の公開 HIE データセットである HIE-Reasoning を構築しました。VQAmedやOmiMed-VQAなどの従来の医療データセットは、画像化方法の認識や臓器の位置決めなどの基本的な問題に重点を置いていますが、このデータセットは、臨床専門家の深い推論プロセスを初めて計算可能な評価システムに変換します。データ構造の革新は、患者レベルのオリジナル画像とタスクファイル、症例横断的なメタ知識推論テンプレート、そして個々の病変確率マップという3層構造のアーキテクチャを採用しています。医療データの完全性を維持するだけでなく、病理学的メカニズムを含む明示的な知識入力をモデルに提供します。
サンプル数はわずか133例であったが、17年間(2001~2018年)にわたる多施設後ろ向き研究による収集と、三次医療機関におけるHIEの発生率が1~5‰と低いことと相まって、このデータセットは、画像、臨床、予後のマルチモーダル情報を統合した初の HIE 固有のベンチマークとなりました。そのラベル付けの精度と臨床的深さは規模の制限を補うのに十分であり、LVLM が「基本的な識別」のボトルネックを突破し、診断と治療の意思決定の深海に踏み込むための不可欠なベンチマークを提供します。
CGoTモデル:臨床思考マップに基づいて、解釈可能な階層的医学推論のための新しいフレームワークを構築
医療推論における従来の大規模視覚言語モデル(LVLM)の解釈可能性のボトルネック(下図A参照)を打破するため、研究チームは臨床目標マップモデル(CGoT)を提案しました(下図BC参照)。臨床知識を統合し、言語モデルをガイドして医師の診断プロセスをシミュレートすることで、神経認知結果の予測信頼性を大幅に向上させることができます。このモデルは構造化された「推論マインドマップ」を革新的に採用しています医療専門家の診断手順を階層的な推論パイプラインに変換し、徐々に知識を蓄積することで複雑なタスクを解決します。
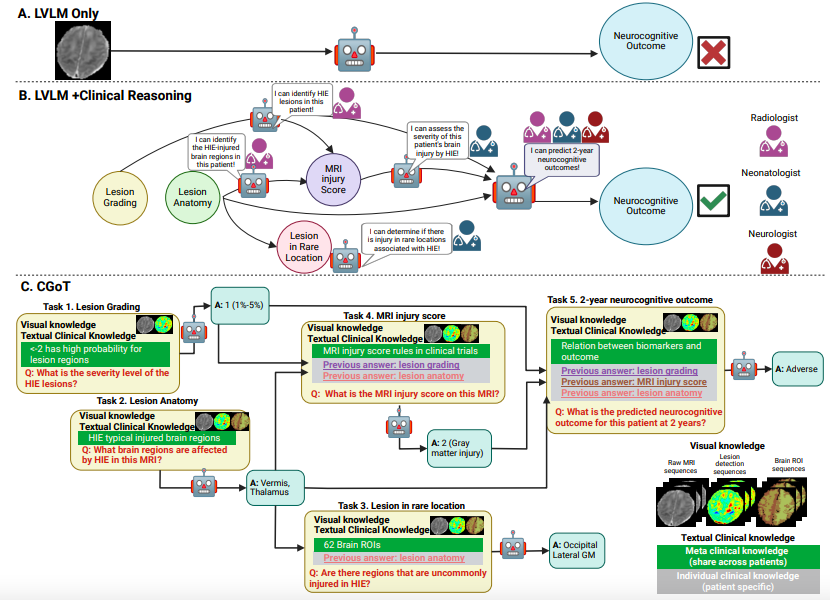
テキスト知識側は、メタ臨床知識(脳解剖図、病変分布パターン、MRIバイオマーカー予後関連などの一般的な医学的背景を含む)と個別臨床知識(過去のタスクの出力から動的に生成される患者固有の診断手がかり)に分かれています。これら2種類の知識は、迅速なエンジニアリング方式で構造化され、入力されます。これにより、LVLMは「臨床ガイドライン-画像特徴-個別病歴」という論理的な連鎖に沿って段階的に推論を進めます。
フレームワーク全体は、臨床グラフの構造化されたプロンプトとクロスモーダル知識を統合することで、暗黙的な医療診断ロジックを計算可能なモデル入力に変換します。これにより、LVLMのクロスモーダル処理能力が維持されるだけでなく、臨床知識をアンカーすることで推論プロセスのランダム性を回避します。
CGoT臨床推論パフォーマンス評価は、主要タスクにおいて画期的な改善を達成しました。
HIE-ReasoningベンチマークとCGoTモデルの有効性を検証するために、研究チームは多次元実験システムを設計しました。
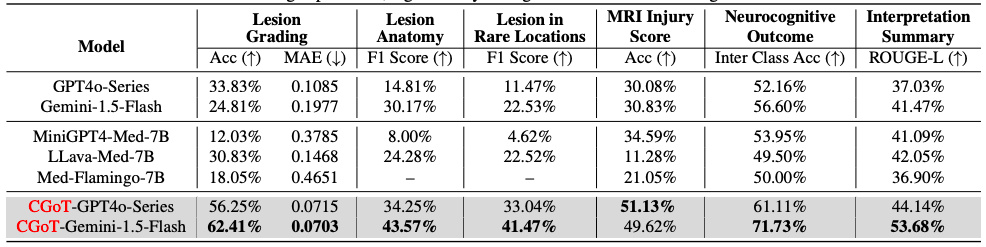
初め、研究者らは、6つの大規模な視覚言語モデルに対してゼロショット評価を実施しました。ベースラインモデルとして、3種類の汎用LVLM(Gemini1.5-Flash、GPT4o-Mini、GPT4o)と3種類の医療LVLM(MiniGPT4-Med、LLava-Med、Med-Flamingo)が選択されました。病変のグレード分類、解剖学的局在、予後予測を含む6つの主要な臨床タスクは、精度、MAE、F1スコア、ROUGE-Lなどのタスク固有の指標を用いて評価されました。2年間の神経認知アウトカム予測では、ラベル分布のバイアスを補正するために、カテゴリ間の平均精度を使用しました。
実験結果は、従来のLVLMの重大な限界を明らかにしました。MRIスライス画像とタスク記述を直接入力した場合、すべてのベースラインモデルは専門的な医療推論タスクにおいて低いパフォーマンスを示しました。一部のモデルは、回答の幻覚を示したり、臨床知識の不足により保守的に回答を拒否したりしました。例えば、Med-Flamingoは解剖学的位置決めタスクにおいて意味のない反復コンテンツを生成し、GPT4oシリーズはアライメント戦略のために不確実性が高い問題に対応できませんでした。
対照的に、次の表に示すように、CGoTモデルは、臨床マインドマップとクロスモーダル知識を統合することで、主要なタスクの画期的な改善を実現します。——特に、2年間の予後予測という中核的な臨床ニーズにおいては、ベースラインモデルと比較してパフォーマンスが15%以上向上し、病変のグレーディングや損傷スコアリングなどのタスクの精度と一貫性も対照群よりも大幅に向上しました。
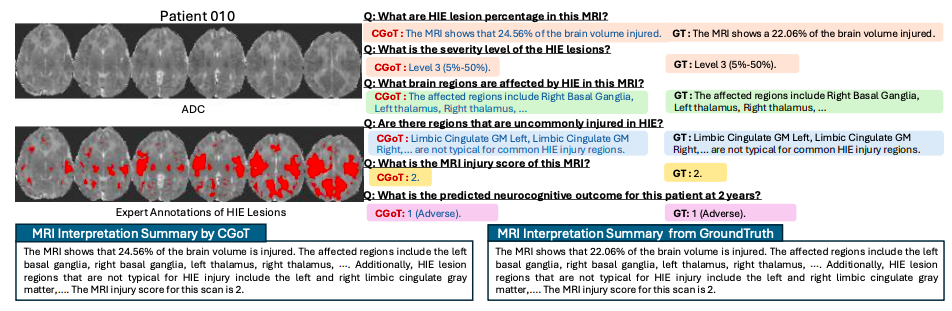
同時に、ロバスト性実験では、10%-30%の中間タスク結果に±1レベルのスコア変動を導入しても、モデルのパフォーマンスは緩やかな低下を示すのみであり、臨床現場でよく見られるデータノイズに適応できる能力があることが示されています。これらの知見は、CGoT は、臨床診断の階層的推論プロセスをシミュレートすることにより、従来のモデルの知識の盲点を打破するだけでなく、実際の診断および治療シナリオに近い信頼性の高い意思決定支援システムを構築します。
医療用LVLMの双輪駆動:学術界とビジネス界における革新的な実践とトレンド
世界的に、医療分野における大規模視覚言語モデル (LVLM) の研究と応用はパラダイムシフトを遂げつつあり、学界とビジネス界の革新的な実践が共同でこの分野のブレークスルーを推進しています。
学術研究レベルでは、上海人工知能研究所がワシントン大学、モナッシュ大学、華東師範大学などの研究機関と共同で、GMAI-MMBenchベンチマークテストをリリースしました。284 の臨床タスク データセットを統合し、38 の医用画像診断法と 18 の主要な臨床ニーズ (腫瘍診断、神経画像分析など) をカバーします。このベンチマークでは、語彙ツリー分類システムを使用して、部門、モダリティ、タスクの種類ごとにケースを正確に分類し、LVLM の臨床推論能力を評価するための標準化されたフレームワークを提供します。
* 完全なレポートを見るにはここをクリックしてください: 上海AIラボなどが、18の臨床タスクをカバーする284のデータセットを含むマルチモーダル医療ベンチマークGMAI-MMBenchをリリースしました。
さらに、エモリー大学、南カリフォルニア大学、東京大学、ジョンズ・ホプキンス大学が共同で開発した Med-R1 では、従来の教師あり微調整 (SFT) 手法の限界に対処するために、グループ相対ポリシー最適化 (GRPO) を革新的に導入しています。複雑な価値モデルを使用せずに、ルール報酬とグループ比較を通じて安定したポリシー更新を実現します。香港科技大学が立ち上げた MedDr などのオープンソース LVLM は、特定のタスク (病変のグレーディングなど) において商用モデルに近いパフォーマンスを達成しており、医療 AI 分野におけるオープンソース エコシステムの潜在能力を実証しています。
ビジネス界は、テクノロジーの導入を核として、LVLMの臨床変革を加速させています。例えば、Microsoft Azure Medical Cloud Platformは、AIツールと臨床データを統合することで、医用画像解析、電子カルテ自動化などの機能の高度な統合を実現しています。同社が多くの病院と共同で開発したインテリジェント放射線システムは、LVLM を使用して MRI 画像内の異常領域を迅速に識別し、構造化されたレポートを生成する機能。病変の等級分けと解剖学的位置決めの作業を医師が完了できるよう支援します。
Googleは、Gemma3アーキテクチャをベースとし、医療・健康分野向けに特化して設計されたオープンソースの医療モデル「MedGemma」を発表しました。MedGemmaは、医療画像とテキストデータの分析をシームレスに組み合わせることで、医療・健康アプリケーションの強化と、医療診断・治療の効率向上を目指しています。
* 詳細なレポートはこちらをクリックしてください: Googleが医療テキストと画像の理解に特化したGemma 3ベースのMedGemmaをリリース
これらの実践を合わせると、医療用 LVLM の開発における 2 つの大きな傾向が明らかになります。まず、臨床知識とモデル アーキテクチャの緊密な統合です。例えば、本稿で説明した HIE-Reasoning ベンチマークの専門家による注釈を通じて構築されたタスク システムや、CGoT モデルによって導入された臨床思考マップなどです。2 つ目は、学際的なコラボレーションとデータ ガバナンスのイノベーションです。例えば、GMAI-MMBenchは、統一されたアノテーションフォーマットと倫理コンプライアンスプロセスを通じて世界中のデータセットを統合し、医療データの不足を解消するためのモデルを提供しています。今後、連合学習や合成データ生成といった技術のさらなる応用により、学術界と産業界は、より複雑な臨床シナリオ(マルチモーダル予後予測やリアルタイム手術ナビゲーションなど)において画期的な成果を達成し、AIを補助ツールからインテリジェントな意思決定パートナーへと真に変革することが期待されます。
参考記事:
1.https://blog.csdn.net/Python_cocola/article/details/146590017
2.https://mp.weixin.qq.com/s/0SGHeV8OcXu8kFk68f-7Ww








