Command Palette
Search for a command to run...
NeurIPS 2025に選ばれた知源大学、北京大学、北京郵電大学は、オーディオデミキシングに基づいて正確なオーディオビジュアル同期を実現するマルチストリーム制御ビデオ生成フレームワークを提案しました。

テキストと比較して、音声は本質的に連続的な時間構造と豊富な動的情報を有しており、動画生成においてより正確な時間制御を可能にします。そのため、動画生成モデルの発展に伴い、音声駆動型動画生成は、マルチモーダル動画生成分野における重要な研究方向へと徐々に変化してきました。現在、関連研究は、話者アニメーション、音楽駆動型動画、音声と映像の同期生成など、複数のシナリオをカバーしていますが、複雑な動画コンテンツにおいて安定的かつ正確な音声と映像の整合を実現することは依然として非常に困難です。
既存の手法の主な限界は、音声信号のモデル化方法に起因しています。ほとんどのモデルは、入力音声を生成プロセスにおける全体的な条件として導入するため、音声、効果音、音楽といった様々な音声コンポーネントの機能的役割を視覚レベルで区別することができません。このアプローチは、モデリングの複雑さをある程度軽減します。しかし、これによってオーディオとビジュアルの対応が曖昧になり、リップシンク、イベントタイミングの調整、全体的なビジュアル雰囲気のコントロールの要件を同時に満たすことが難しくなります。
この問題に対処するために、北京人工知能研究院、北京大学、北京郵電大学は共同で、オーディオデミキシングに基づくオーディオビジュアル同期ビデオ生成のフレームワークを提案した。入力音声は、音声、効果音、音楽の3つの音声トラックに分割され、それぞれが異なるレベルの映像生成に使用されます。このフレームワークは、マルチストリームの時間制御ネットワークと、それに対応するデータセットおよび学習戦略を通じて、時間レベルと全体レベルの両方で、より明確な音声と映像の対応を実現します。実験データは、この手法が映像品質、音声と映像の整合、そしてリップシンクにおいて安定した改善を実現することを示しており、複雑な映像生成タスクにおける音声分離とマルチストリーム制御の有効性を検証しています。
「マルチストリーム時間制御によるオーディオ同期ビデオ生成」と題された関連研究成果が、NeurIPS 2025 に選出されました。
用紙のアドレス:
https://arxiv.org/abs/2506.08003
研究のハイライト:
* 音声同期ビデオ生成用の 5 つの重複サブセットで構成される DEMIX データセットを構築し、オーディオビジュアル関係を学習するための多段階トレーニング戦略を提案します。
* 音声を音声、効果音、音楽の3つのトラックに分割するMTVフレームワークを提案します。これらのトラックは、唇の動き、イベントのタイミング、全体的な視覚的雰囲気など、さまざまな視覚要素を制御することで、より正確なセマンティック制御を可能にします。
* マルチストリーム時間制御ネットワーク (MST-ControlNet) を設計し、同じ生成フレームワーク内でローカル時間間隔の細かい同期とグローバル スタイル調整を同時に処理し、時間スケール上で異なるオーディオ コンポーネントの差別化された制御を構造的にサポートします。
多機能発電能力
MTV には、キャラクター中心の物語、複数のキャラクターのやり取り、音によってトリガーされるイベント、音楽によって作り出される雰囲気、カメラの動きなど、多機能な生成機能があります。
DEMIX データセットでは、段階的なトレーニングを可能にするために、分離トラック注釈が導入されています。
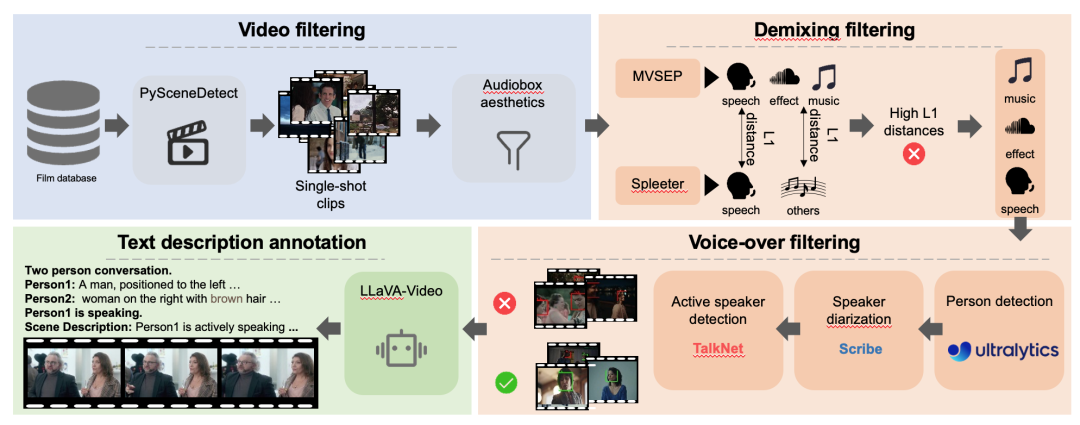
本論文では、まず詳細なフィルタリングプロセスを経てDEMIXデータセットを取得します。フィルタリングされたDEMIXデータは、以下の5つの重複するサブセットに構造化されます。基本的な顔の特徴、一人称効果、複数人称効果、イベント効果音、環境雰囲気。5つの重複するサブセットに基づいています。この論文では、多段階のトレーニング戦略を紹介します。モデルは段階的にスケールアップされます。まず、唇の動きを学習するために、基本的な顔のサブセットでモデルをトレーニングします。次に、一人の人物のサブセットで人間のポーズ、シーンの外観、カメラの動きを学習します。その後、複数の話者がいる複雑なシーンを処理するために、複数人物のサブセットでトレーニングします。次に、トレーニングの焦点はイベントのタイミングに移り、イベントの音響効果サブセットを使用して、主題の理解が人間から物体へと拡張されます。最後に、視覚的な感情表現を向上させるために、周囲の雰囲気のサブセットでモデルをトレーニングします。
マルチストリームタイミング制御メカニズムに基づいて、正確なオーディオビジュアルマッピングと正確な時間調整が実現されます。
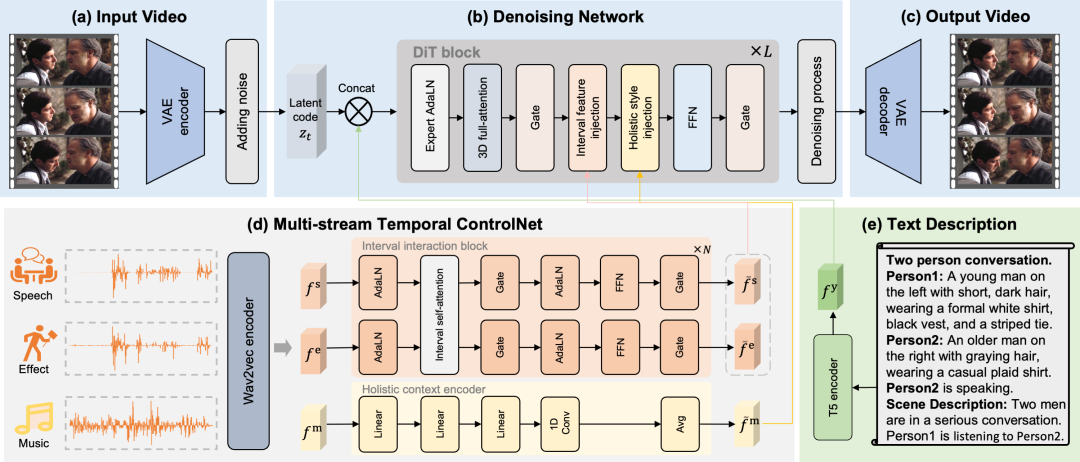
この記事では、オーディオを、音声、効果音、音楽の 3 つの異なる制御トラックに明示的に分割します。これらの明確なトラックにより、MTVフレームワークは唇の動き、イベントのタイミング、視覚的な感情を正確に制御することができ、曖昧なマッピングの問題を解決します。MTVフレームワークを様々なタスクに対応させるため、本稿ではテキスト記述を構築するためのテンプレートを作成します。このテンプレートは、「二人の会話」など、参加者の人数を示す文から始まります。次に、各人物をリストし、固有の識別子(Person1、Person2)で始まり、それぞれの外見を簡単に説明します。参加者をリストした後、テンプレートは現在話している人物を明示的に識別します。最後に、シーンの全体的な説明文が続きます。正確な時間調整を実現するために、本稿では、明示的に分離された音声、効果音、音楽トラックを通じて唇の動き、イベントのタイミング、視覚的な感情を制御するマルチストリーム時間制御ネットワークを提案します。
間隔特徴注入
音声および効果音機能についてこの論文では、唇の動きとイベントのタイミングを正確に制御するためのインターバルフローを設計します。各音声トラックの特徴は区間インタラクションモジュールによって抽出され、音声と効果音のインタラクションは自己注意メカニズムによってシミュレートされます。最後に、インタラクティブな音声と効果音の特徴は、クロスアテンションによって各時間区間に注入されます。これを区間特徴注入メカニズムと呼びます。
グローバル機能注入
音楽的特徴に関しては、この論文では、ビデオセグメント全体の視覚的な感情を制御するための全体的なフローを設計します。音楽的特徴は全体的な美的感覚を表現するものであるため、まずグローバルコンテキストエンコーダーを用いて音楽から全体的な視覚的感情を抽出し、平均プーリングを適用してセグメント全体のグローバル特徴量を取得します。最後に、これらのグローバル特徴量を埋め込み情報として用い、ビデオ潜在コードをAdaLN(グローバル特徴注入メカニズム)によって変調します。
映画品質のオーディオ同期ビデオを正確に生成します。
総合評価指標
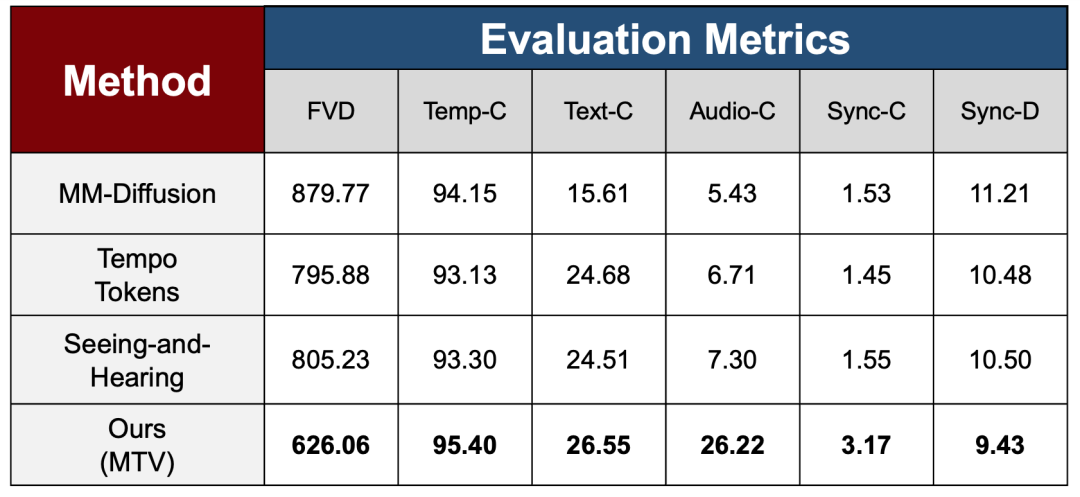
本論文では、異なる学習段階での多段階トレーニング戦略の有効性を検証するために、実験セクションでビデオ品質、時間的一貫性、マルチモーダルアライメント機能を含む一連の包括的な評価指標を使用して、複雑な制御信号を徐々に導入した後のモデルの全体的な安定性と一貫性のパフォーマンスを体系的に評価し、それを 3 つの最先端の方法と比較しています。
生成品質と時間的安定性に関して、本研究ではFVDを用いて生成動画と実動画の分布の差を測定し、Temp-Cを用いて隣接フレーム間の時間的連続性を評価しました。その結果、MTVはFVDにおいて既存手法を大幅に上回る性能を示しました。これは、より複雑な音声制御を導入しても、MTVモデルがTemp-Cにおいて高い時間的安定性を維持しながら、全体的な生成品質を犠牲にしていないことを示しています。
マルチモーダルアライメントレベルでは、本研究では、それぞれText-CメトリクスとAudio-Cメトリクスを用いて、ビデオとテキスト/オーディオ間の整合性を測定しました。MTVはAudio-Cメトリクスにおいて大幅な改善を示し、比較手法を大きく上回りました。これは、オーディオデミキシングとマルチストリーム制御メカニズムがオーディオとビジュアルの整合性を強化する上で有効であることを反映していました。
音声駆動型シナリオの主要な問題に対処するために、このホワイト ペーパーでは、同期の信頼性とエラーの大きさをそれぞれ評価し、最適なパフォーマンスを実現する 2 つの同期メトリック、Sync-C と Sync-D を紹介します。
結果を比較する

上図に示すように、研究者たちはMTVフレームワークと現在の最先端技術(SOTA)の結果を比較しました。視覚的な観点から見ると、既存の手法は複雑なテキスト記述や映画のようなシーンを扱う際に、一般的に安定性が不十分です。
例えば、MM-Diffusionを公式コードを用いて8基のNVIDIA A100 GPUで32万ステップ以上にわたって微調整した後でも、視覚的に一貫性があり物語性のある構造を持つ画像を生成するのに苦労しており、全体的なスタイルは断片をつなぎ合わせたようなものになっています。一方、TempoTokensは、複雑なシーン、特に複数人物や高ダイナミックレンジのシナリオにおいて、不自然な表情や動きを生成しやすく、生成される結果のリアリティに大きく影響します。オーディオとビジュアルの同期に関しては、Xingらの手法は特定のイベントシーケンスにおけるオーディオの同期に苦労しており、ギター演奏中のキャラクターのジェスチャーにレンダリングエラーが発生します(上図右側を参照)。
対照的に、MTV フレームワークは、さまざまなシナリオで高画質と安定したオーディオとビジュアルの同期を維持し、映画のような品質のオーディオ同期ビデオを正確に生成できます。
参考リンク:
1.https://arxiv.org/abs/2506.08003








