Command Palette
Search for a command to run...
オンラインチュートリアル: TTSモデルSOTAをリフレッシュしたOpenAudio S1は、200万時間のオーディオデータに基づいてトレーニングされ、感情やスピーチの詳細を深く理解します。

近年、TTS(Text-to-Speech)モデルは、連結音声合成から統計パラメータ合成、そしてニューラルネットワークTTS(Neural TTS)へと進化を遂げてきました。技術レベルではエンドツーエンドとモジュール融合のトレンドを示し、応用レベルでは多言語対応、高い自然性、豊かな感情表現といった効果の向上を見せています。
TTS モデルは、仮想音声アシスタント、デジタル ヒューマン、AI ダビング、インテリジェント カスタマー サービスなどの分野で広く使用されているため、業界におけるリアルタイム フィードバックの需要は徐々に高まっています。次に、推論速度とモデルパラメータの間でトレードオフが発生します。後者は、ある程度、TTS モデルの展開コストとアプリケーション シナリオを制限します。
これを考慮して、Fish Audio は、新しいオープンソース TTS モデル OpenAudio S1 をリリースしました。OpenAudio-S1とOpenAudio-S1-miniの2つのバージョンがあります。公式ドキュメントによると、OpenAudio S1は200万時間を超える大規模音声データセットで学習されています。開発チームはモデルパラメータを40億に拡張し、独自開発の報酬モデリングメカニズムを導入しました。同時に、人間のフィードバックに基づく強化学習(RLHF、GRPO法を使用)も適用しました。
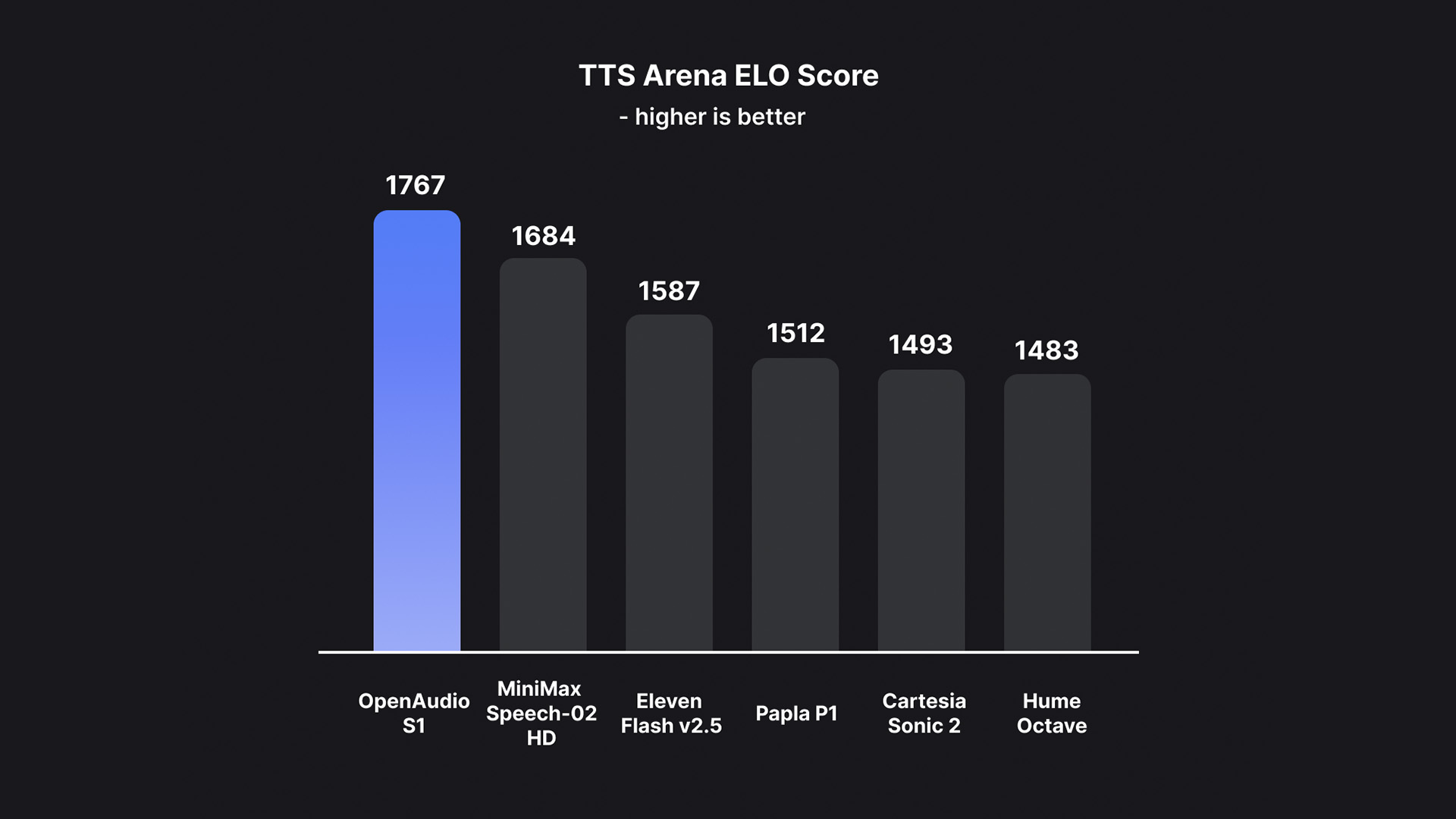
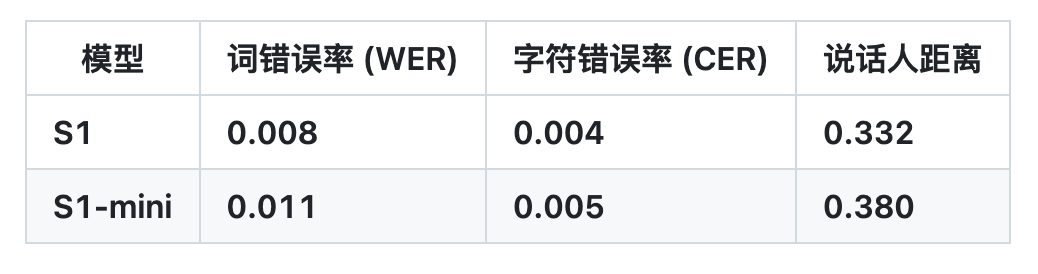
これに基づき、OpenAudio S1 は、他のほとんどのモデルがセマンティックのみのモデルを使用しているときに情報損失によって発生するアーティファクトと誤った語彙をうまく排除し、オーディオ品質、感情表現、および話者の類似性の点で以前のモデルをはるかに上回っています。わずか 10 ~ 30 秒の音声サンプル入力で、高品質の TTS 出力を生成できます。現在、HuggingFace TTS-Arena-V2の人間による主観評価ランキングでトップを獲得しており、Seed-TTS Evalでは約0.4%という低いCER(文字誤り率)と約0.8%というWER(単語誤り率)を達成しています。
チームによれば、OpenAudio S1 が本当にユニークなのは、人間の感情や会話の詳細を深く理解して表現する能力です。合成音声を正確に制御するための豊富なタグセットをサポートしています。TTSモデルが指示に従うように学習させるため、チームは感情、イントネーション、話者情報などを含む音声から字幕を生成できる音声テキスト変換モデル(近日公開予定)も構築しました。このモデルに基づいて、10万時間以上の音声にランダムにアノテーションが付与され、OpenAudio S1の学習に使用されました。
そのため、OpenAudio S1は音声合成を強化するために、複数の感情、イントネーション、特殊マーカーをサポートしています。怒り、驚き、喜びといった基本的な感情に加え、軽蔑、皮肉、ためらいといった高度な感情表現もサポートしています。イントネーションに関しては、ささやき声、叫び声、すすり泣きなどにも対応しています。言語に関しては、現在英語、中国語、日本語に対応しています。
さらに注目すべきは、パフォーマンスと導入コストのバランスという点です。チームは、これが 100 万バイトあたりわずか 15 ドル ($15/100 万バイト、1 時間あたり約 0.8 ドル) のコストで実現できる初の SOTA モデルであると主張しています。
OpenAudio S1のパワフルなパフォーマンスをより早く体験していただくために、HyperAI 公式サイト (hyper.ai) のチュートリアル セクションに、「OpenAudio-s1-mini: 効率的なテキスト読み上げ生成ツール」が公開されました。
チュートリアルのリンク:https://go.hyper.ai/rVvkS
新規登録ユーザー様には、RTX 4090リソースの無料利用特典もご用意しております。下記の招待コードを使用してご登録いただくと、高品質なTTSモデルを無料でご体験いただけます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
デモの実行
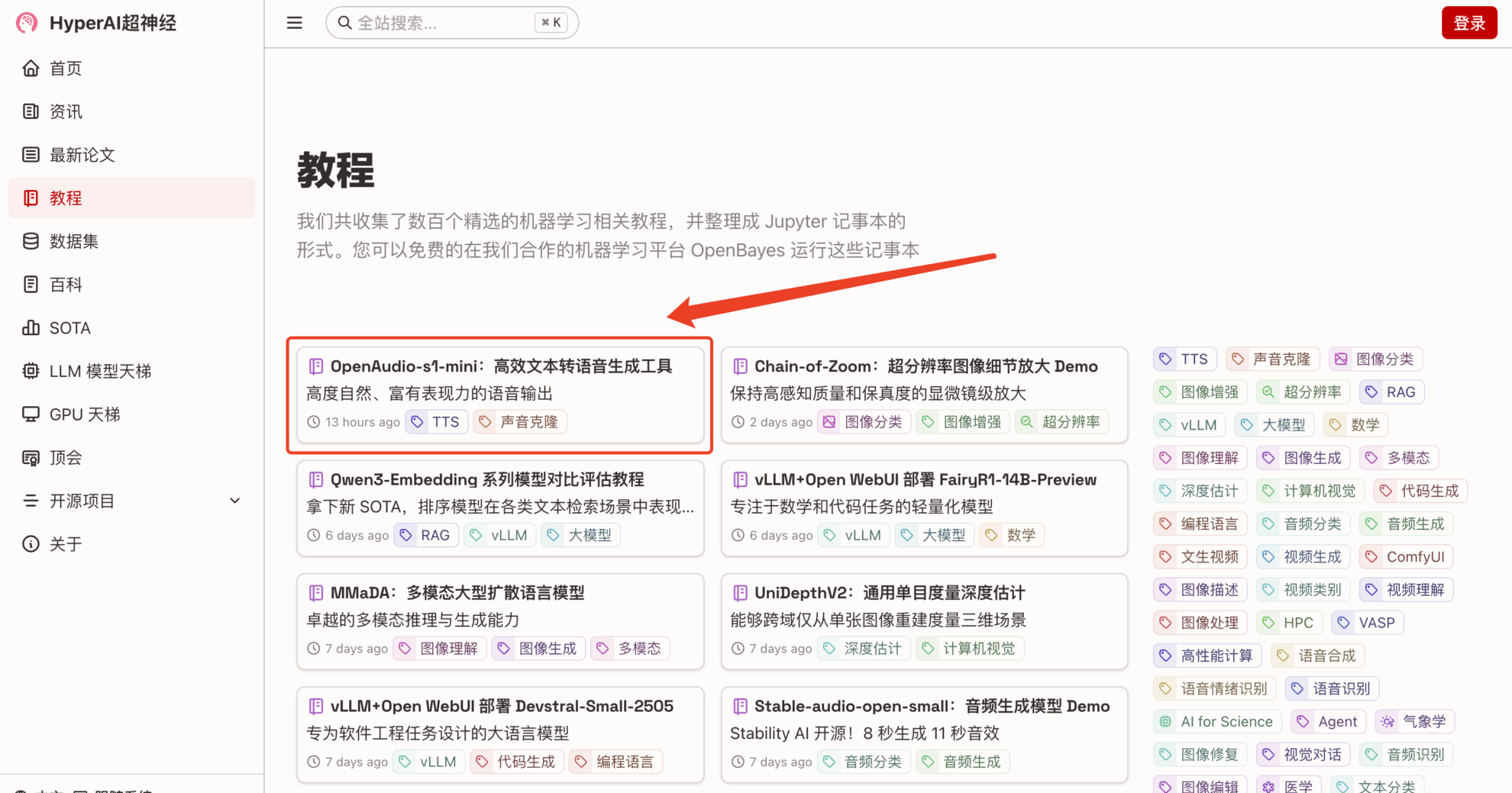
1. hyper.ai ホームページにアクセス後、「チュートリアル」ページを選択し、「OpenAudio-s1-mini: 効率的なテキスト読み上げ生成ツール」を選択して、「このチュートリアルをオンラインで実行」をクリックします。
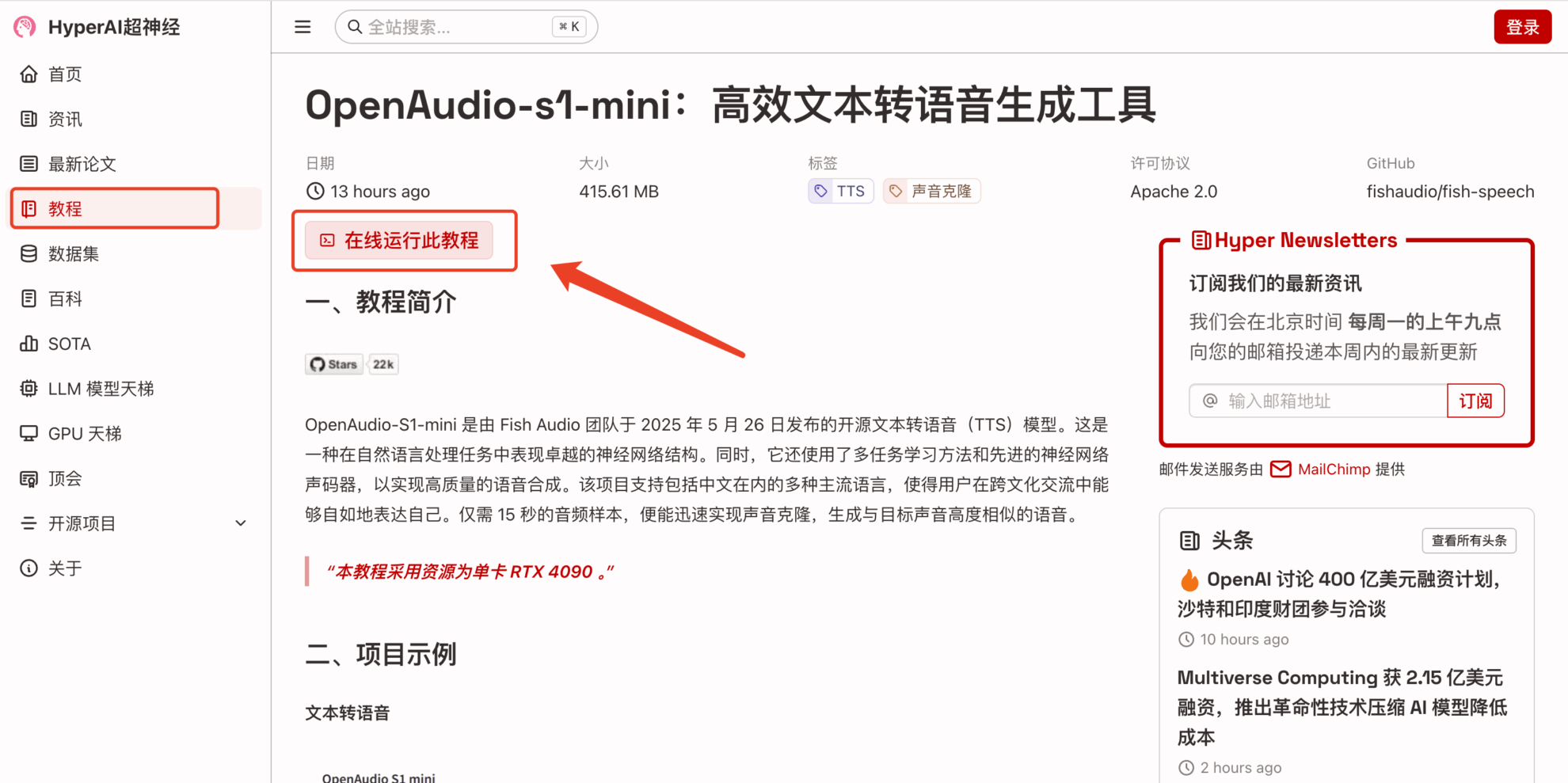
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
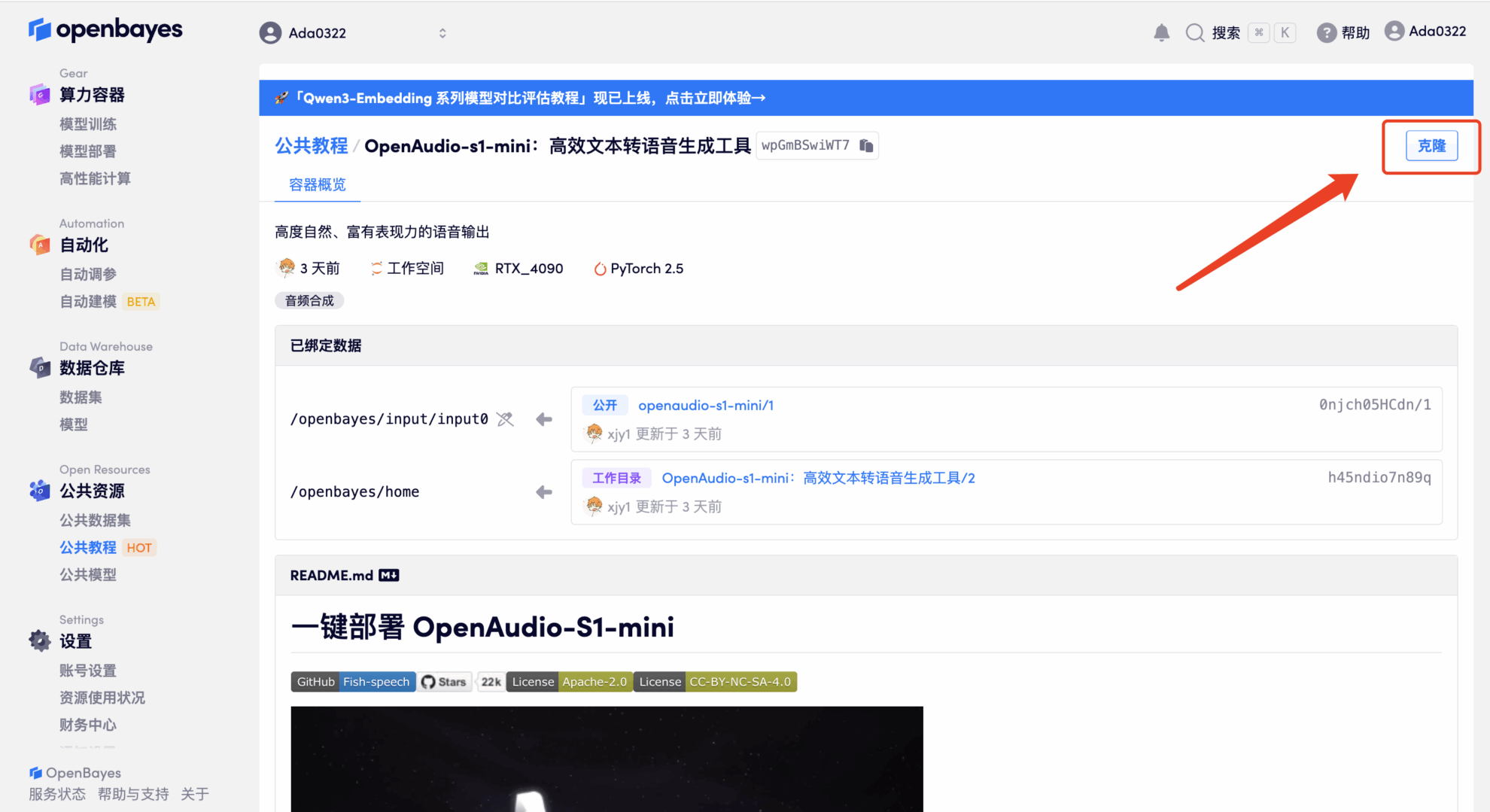
3. 「NVIDIA RTX 4090」と「PyTorch」のイメージを選択してください。OpenBayesプラットフォームでは4つの課金方法をご用意しています。ニーズに合わせて「従量課金制」または「日/週/月単位の課金」をお選びいただけます。「続行」をクリックしてください。新規ユーザーは、以下の招待リンクから登録すると、RTX 4090 4時間分とCPUフリータイム5時間分がプレゼントされます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
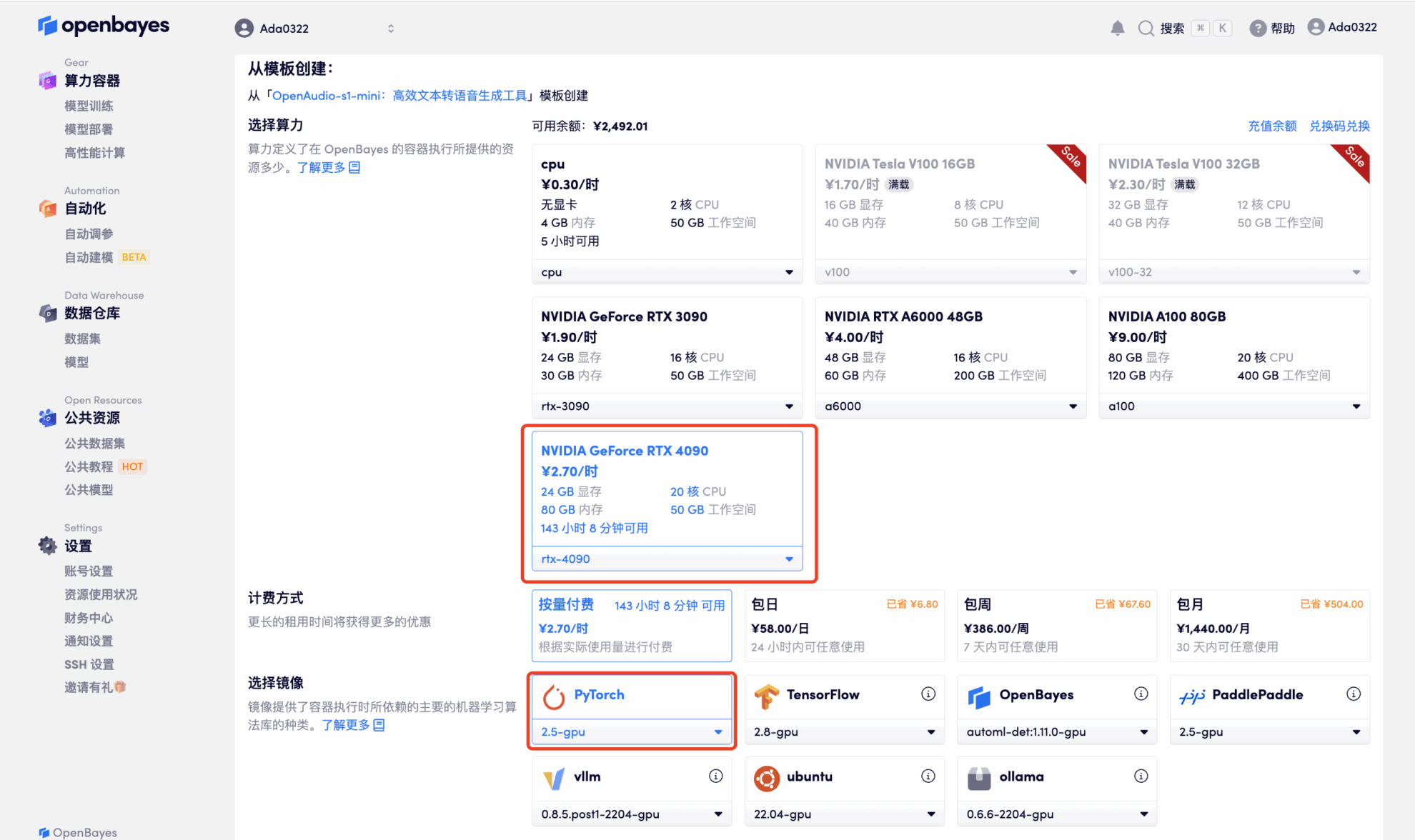
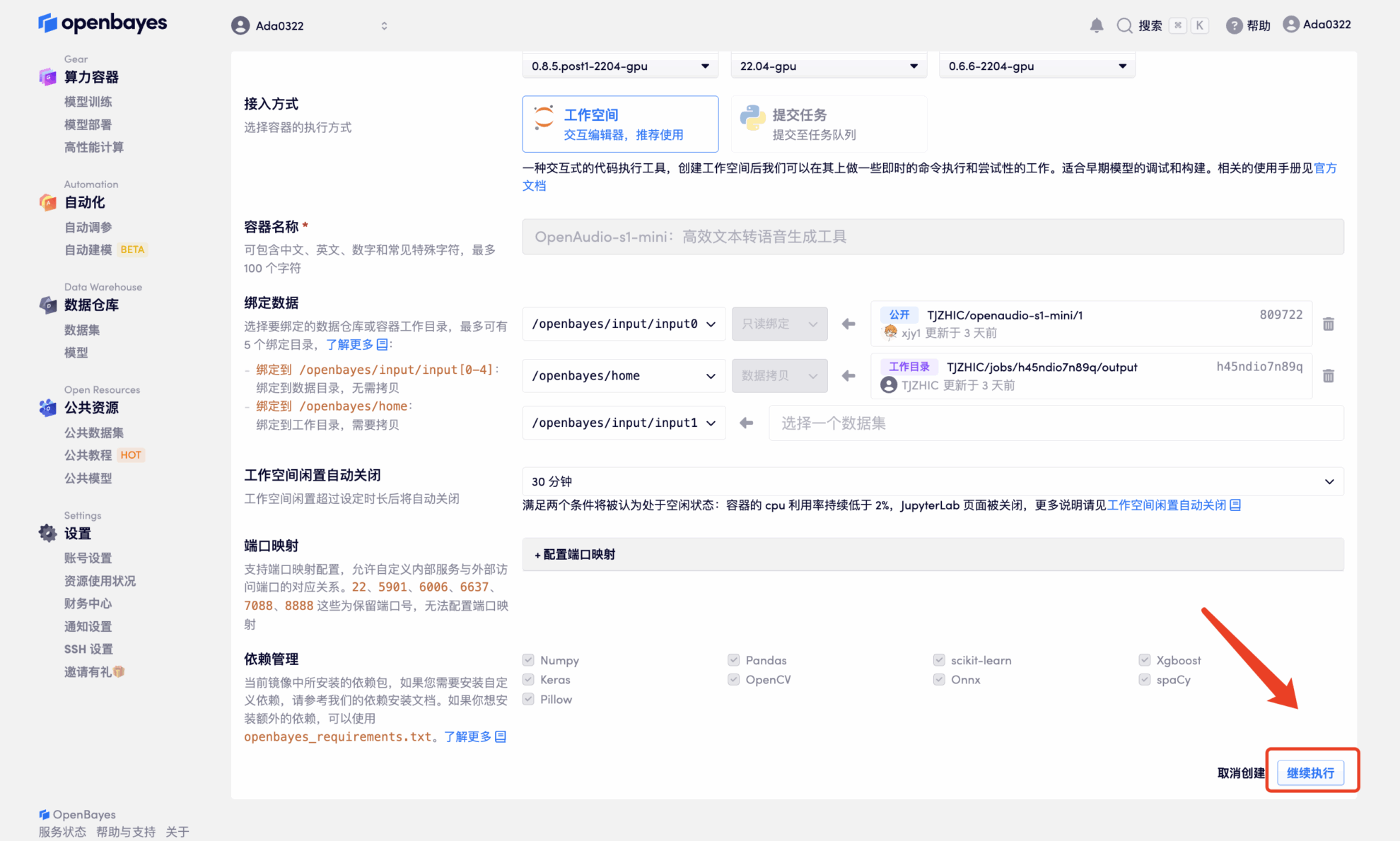
4. リソースが割り当てられるのを待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。モデルが大きいため、WebUI インターフェイスが表示されるまでに約 3 分かかります。そうでない場合は、「Bad Gateway」と表示されます。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。
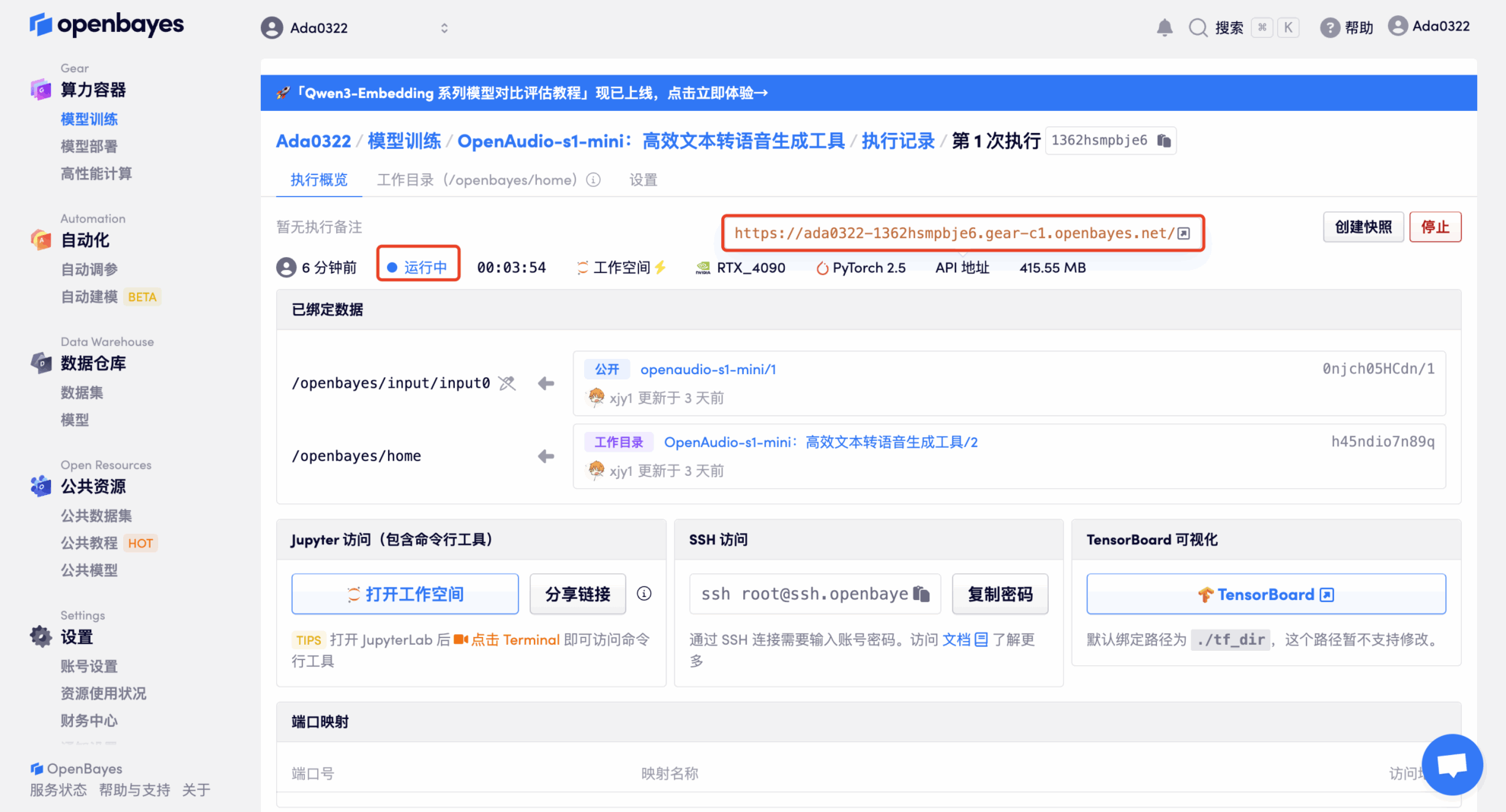
効果実証
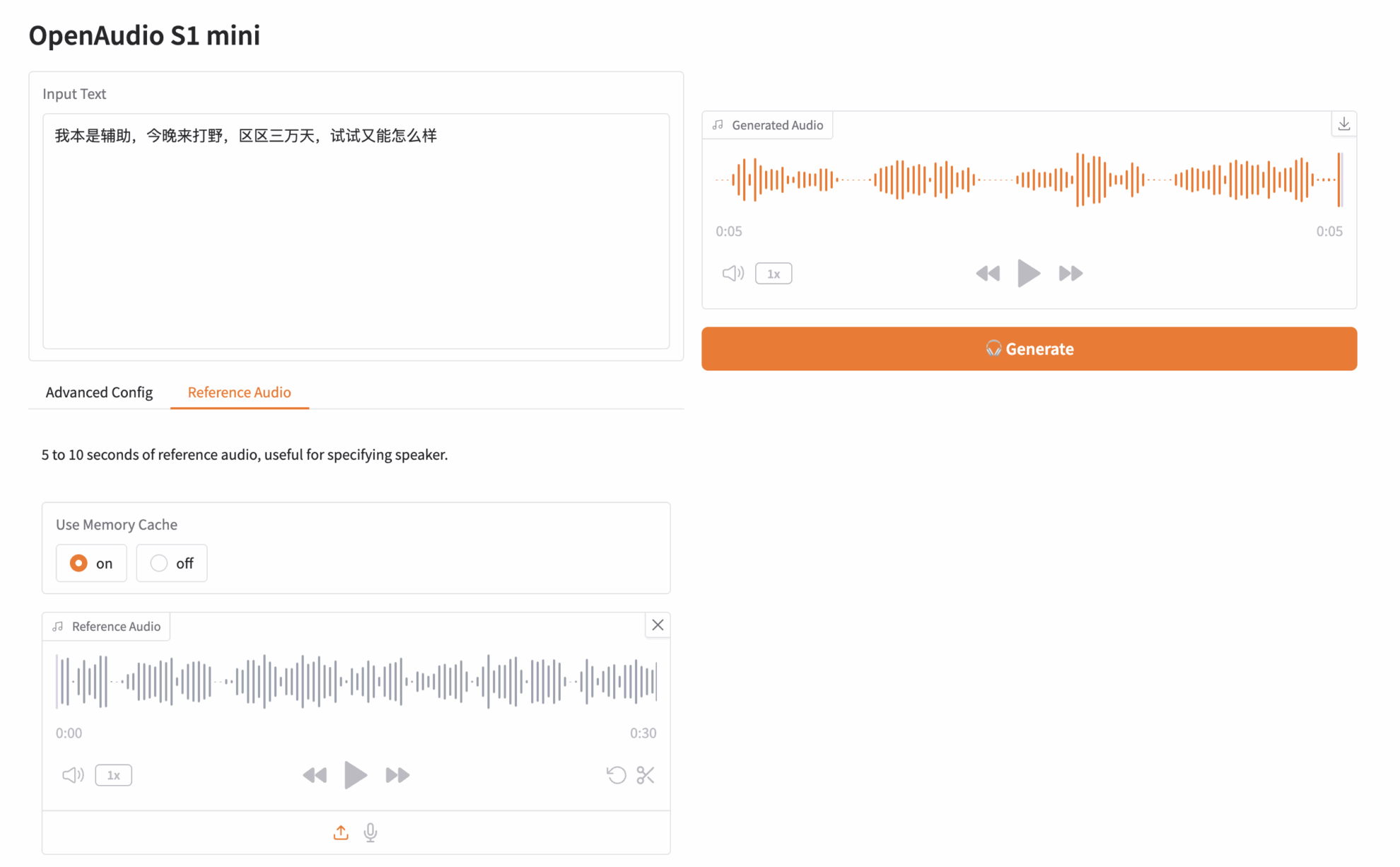
「APIアドレス」をクリックしてモデルを体験してください。原神のキャラクター「パイモン」の音声クリップをアップロードしました。入力テキストは以下の通りです。
元々はサポートだったんですが、今夜はジャングルをプレイしに来ました。まだ3万日だし、ちょっと試してみてもいいかな?
次に、右側の [生成] をクリックしてオーディオを生成します。
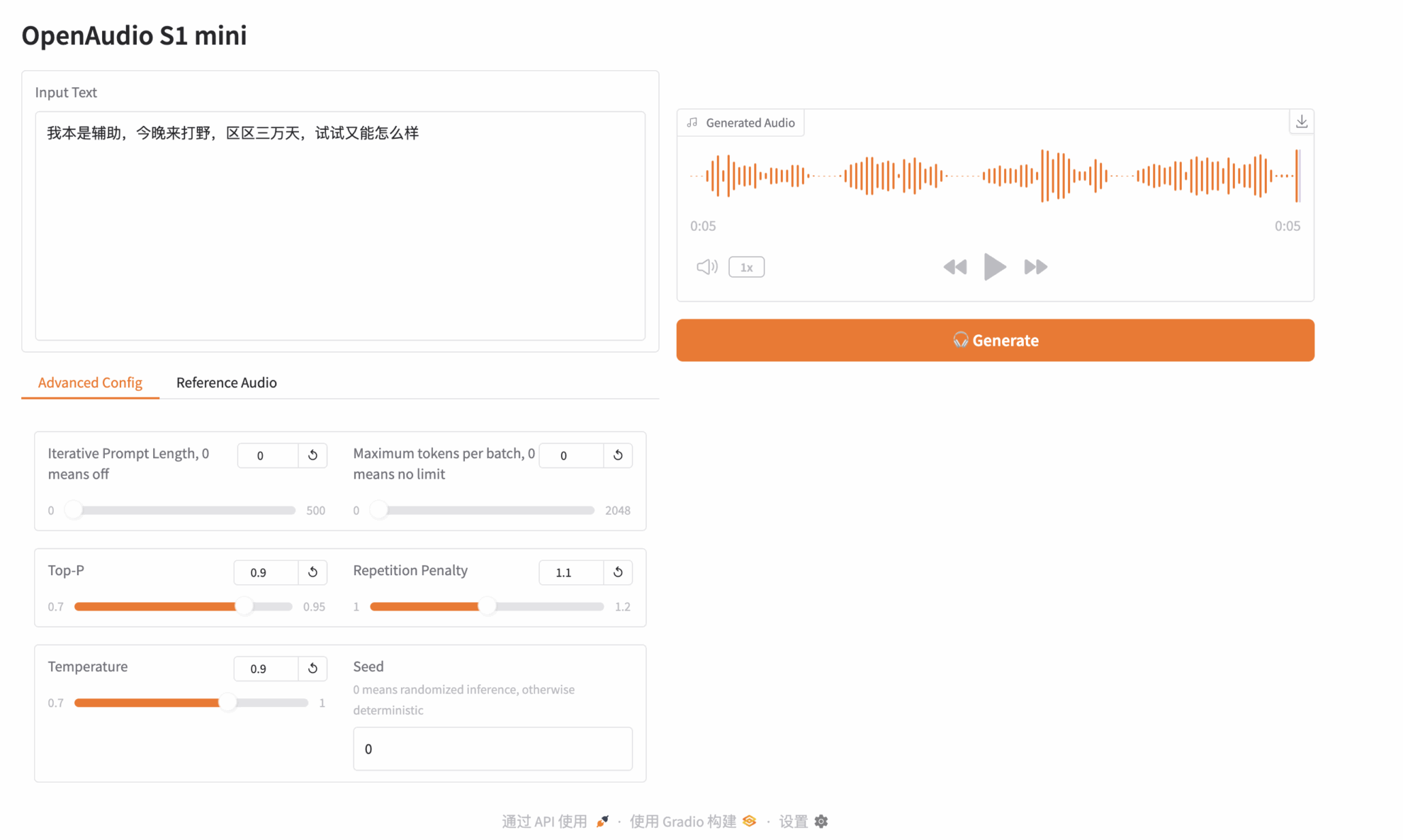
上記はHyperAIが今回おすすめするチュートリアルです。ぜひオンラインで体験してみてください。








