Command Palette
Search for a command to run...
チェコ科学アカデミーは、2億の分子質量スペクトルを網羅し、世界最大の質量分析データセットGeMSを構築するためのDreaMSモデルをリリースしました。
統計によると、現在人類が探索している天然の小分子化学空間は総量の10%未満ですが、非標的メタボロミクス実験では、信頼できる注釈がないため、90%を超える質量スペクトルが「データ無駄」になっています。
分子を解読するというこの重要な戦いにおいて、核心的な課題はタンデム質量分析(MS/MS)という複雑な言語を解読することにあります。現代の化学分析における最先端ツールである液体クロマトグラフィー-タンデム質量分析(LC-MS/MS)システムは、液体クロマトグラフィーによって分子を効率的に分離し、衝突誘起解離技術を用いてフラグメントイオンの質量スペクトルを生成します。このプロセスは、分子を分解してフラグメントパズルを解析するプロセスに似ています。
しかし、既存の分析ツールでは、分子の全体像を組み立てる上で大きな限界があります。高度な SIRIUS アルゴリズムでさえ、限られたスペクトル ライブラリと人工的なルールに過度に依存しています。合計80%を超える未知の天然分子に直面すると、しばしば検証できるライブラリがないというジレンマに陥ります。2023年にNature Methodsに掲載された研究では、グローバルメタボロミクスデータベースにおいて、2%のMS/MSスペクトルのみがアノテーションに成功し、残りの98%は深海のサンゴ礁のように存在し、新薬の発見や疾患診断研究の進展を深刻に阻害していると指摘されています。
この問題を解決するため、チェコ科学アカデミー有機化学・生化学研究所の研究チームは、GPTシリーズの言語分野における画期的な成果を活用し、質量スペクトル専用の翻訳ツールの開発に取り組んでいます。研究者たちは、Global Natural Products Social Molecular Network(GNPS)から7億件のMS/MSスペクトルをマイニングし、史上最大の質量分析データセットGeMSの構築に成功しました。そして、1億1600万のパラメータを持つTransformerモデルDreaMSを学習させました。このモデルは、人工知能に分子の「壊れた文法」をゼロから学習させるようなものです。マスクされたスペクトルピークとクロマトグラフィーの保持順序を予測することで、ラベルのない質量スペクトルに隠された構造パターンを発見することに成功しました。生成される 1,024 次元の特性ベクトルは、分子間の構造的類似性を正確に反映し、さまざまな質量分析条件下での信号変動に対して高い堅牢性を示します。
研究によると、微調整された DreaMS は、さまざまな質量分析注釈タスクで優れたパフォーマンスを発揮します。スペクトルの類似性、分子指紋、化学特性、フッ素の存在の予測など、これらはすべて従来のアルゴリズムや最近開発された機械学習モデルを上回っています。DreaMSは、細菌、植物、人間の代謝物をカバーする超分子ネットワークを構築するために2億100万スペクトルを統合しました。リアルタイムで更新可能な化学コミュニティ向けの「分子百科事典」を作成し、関連分野の研究と応用に非常に貴重なリソースを提供しています。
関連する研究成果は、「DreaMS を用いた数百万のタンデム質量スペクトルからの分子表現の自己教師学習」というタイトルで、国際的に有名な Nature Biotechnology 誌に掲載されました。

用紙のアドレス:
AIフロンティアに関するその他の論文:
GeMS化学質量分析データセットのダウンロードアドレス:
https://go.hyper.ai/IC2yw
GeMSデータセット:質量スペクトルデータベースを構築するための7億スペクトル
この研究の核となるデータ基盤は、MassIVE GNPS リポジトリから徹底的にマイニングされた GeMS データ セットであり、その規模と品質はメタボロミクスの分野では画期的です。
GeMS化学質量分析データセットのダウンロードアドレス:
https://go.hyper.ai/IC2yw
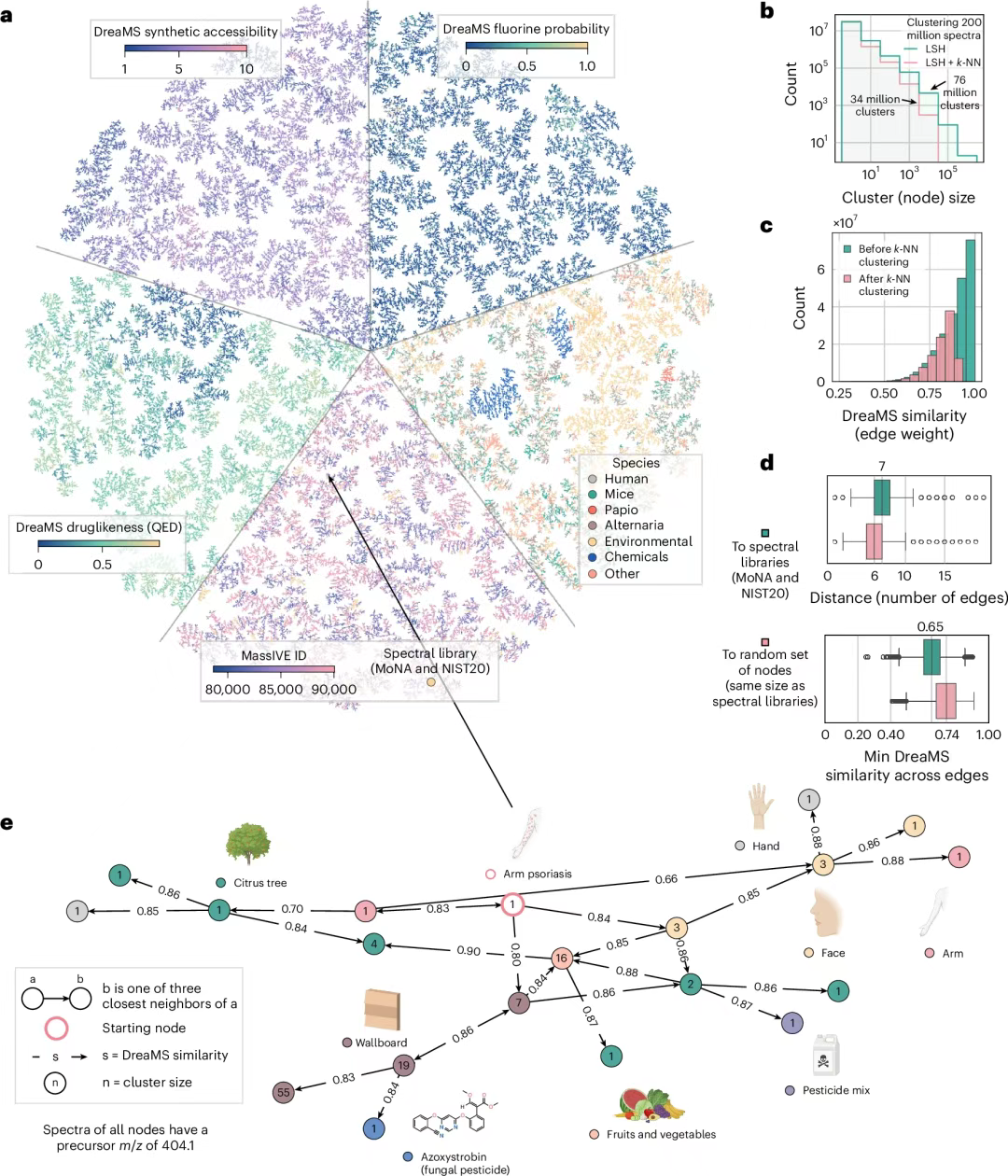
以下の図に示すように、研究チームは、生物学および環境分野にわたる25万件のLC-MS/MS実験データを統合し、そこから約7億個のMS/MSスペクトルを抽出し、厳格な品質管理アルゴリズムを通じてGeMS-A、GeMS-B、GeMS-Cの3つのサブセットに分割しました。このうち、GeMS-Aは主に97% Orbitrap質量分析計を用いてスペクトルを収集し、最高水準の品質を誇ります。一方、GeMS-Cは52% Orbitrapと41% QTOFスペクトルを統合し、一定の品質を確保しながらデータ規模を大幅に拡大します。この階層設計は、高精度機器データの信頼性を維持するだけでなく、より包括的なサブセットを通じてより広範な質量分析技術ソースをカバーし、データセットの多様性を確保します。
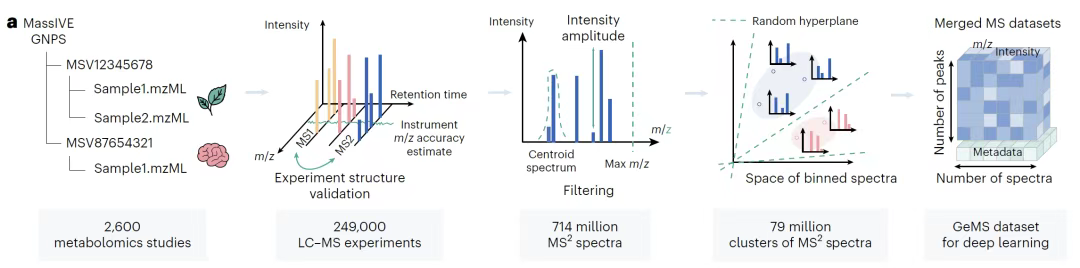
大規模データにおける冗長性の問題を解決するため、研究チームは局所性感受性ハッシュ(LSH)アルゴリズムを用いて類似スペクトルを効率的にクラスタリングし、クラスタ内のスペクトル数を制限して9つのバリアントを生成しました。これにより、データの代表性を維持しながら計算効率を最適化しました。GeMSデータセットは最終的にコンパクトなHDF5バイナリ形式で保存されました。生のスペクトルを固定次元の数値テンソルに変換する。GeMSは、従来のスペクトルライブラリの規模ボトルネックを打破します。下図に示すように、データ量は既存のライブラリより数桁大きく、構造は高度に標準化されており、これまでにないディープラーニングモデルのトレーニング教材を提供します。これらのデータ特性により、GeMSは教師なし学習/自己教師学習に適した初の超大規模質量分析データセットとなっています。DreaMSモデルの事前トレーニングの基盤を築くだけでなく、品質階層化とフォーマット最適化を通じて、後続のスペクトル類似性分析、分子構造特性評価などのタスクに、精度と幅の両方を備えたデータサポートを提供します。これにより、メタボロミクス研究を、限られた参照ライブラリに依存する従来のモデルから、膨大な生のスペクトルに基づくインテリジェントな分析パラダイムへと推進します。
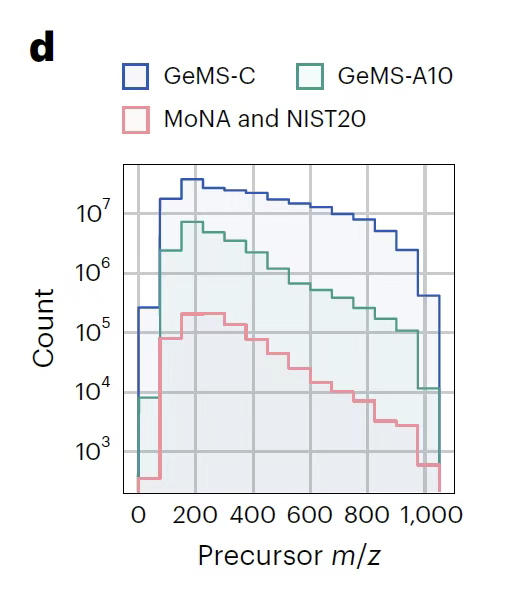
DreaMSモデル: 自己教師ありTransformerに基づく質量分析の新しいパラダイム
DreaMS モデルは、GeMS データセットに基づいて、自己教師学習により注釈のない MS/MS スペクトルから分子表現を抽出することを目的としています。このモデルは、自然言語処理の BERT アーキテクチャを活用し、小分子質量分析の分野で自己教師学習パラダイムの先駆者となりました。そのコア設計には、2 つのトレーニング目標が含まれています。1 つは、強度に比例してスペクトル内の 30% の質量電荷比 (m/z) をランダムにマスクし、マスクされたピークを再構築するようにモデルをトレーニングするとともに、「親イオン タグ」を導入してスペクトル レベルの情報を集約することです (言語モデルの文章レベルの表現に似ています)。もう 1 つは、同じ LC-MS/MS 実験のスペクトル ペアを通じてクロマトグラフィーの溶出順序を予測することを学習し、分子構造とピーク溶出ルール間の固有の関係を強化することです。
モデルアーキテクチャの観点から見ると、下の図に示すように、DreaMS は、8 ヘッドの自己注意メカニズムを備えた 7 層の Transformer エンコーダーに基づいており、1,024 次元の表現ベクトルを生成できます。高解像度の質量電荷比データの場合、モデルはフーリエ特徴の前処理技術を使用して連続質量値を正弦/余弦周波数成分に分解し、整数部分と浮動小数点部分の詳細を取得し、さらにフィードフォワードネットワークを介して元素組成予測を関連付けます。強度値は浅いネットワークで処理され、フーリエ特徴と連結されてTransformerの入力となります。さらに、DreaMS は、すべてのピーク ペアのフーリエ特徴の差を自己注意ヘッドに明示的に導入します (Graphormer アーキテクチャから借用)。追加のラベル付けや複雑な計算を回避しながら、中立損失関係を直接モデル化します。
この研究では、線形プローブ技術を使用して、トレーニング段階で獲得された表現の変化を評価しました。まず、トレーニングプロセス中に、親イオン埋め込みベクトルに基づくロジスティック回帰モデルは、MACCS結合フィンガープリントを徐々に予測することができ、モデルが自己監督で分子フラグメント情報を学習していることを示しています。次に、アテンションヘッド分析は、モデルがノイズではなく分子構造を表す特徴的なピークを優先していることを示しています。最後に、特性空間クラスタリングの結果は、異なるイオン化条件下のスペクトルであっても、分子構造に従って線形に分布できることを示し、構造的特徴を捉える能力を検証しています。
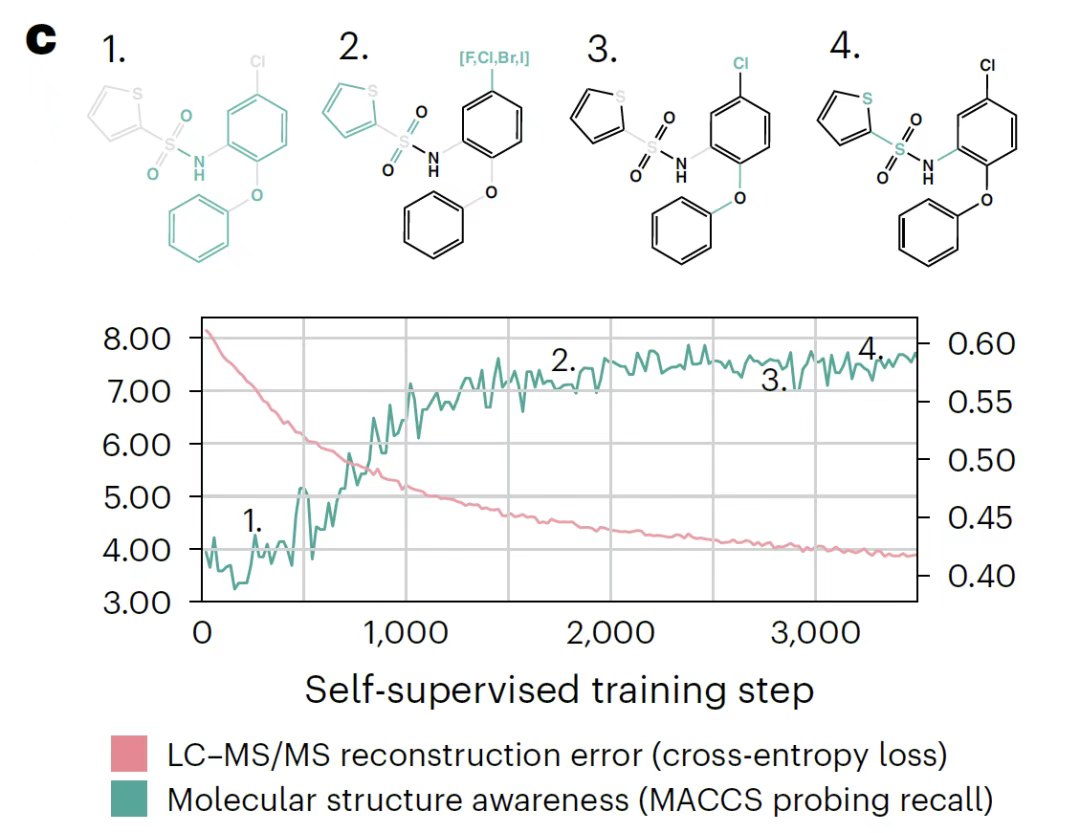
DreaMSモデルのクロスタスク移行:単一分子分析から全メタボローム相互接続までの質量分析
自己教師学習に基づく最初の質量分析モデルであるDreaMSモデルは、タスク間の移行機能において大きな利点を示しています。研究チームは、このモデルを以下の4つのコアタスクに適応させました。
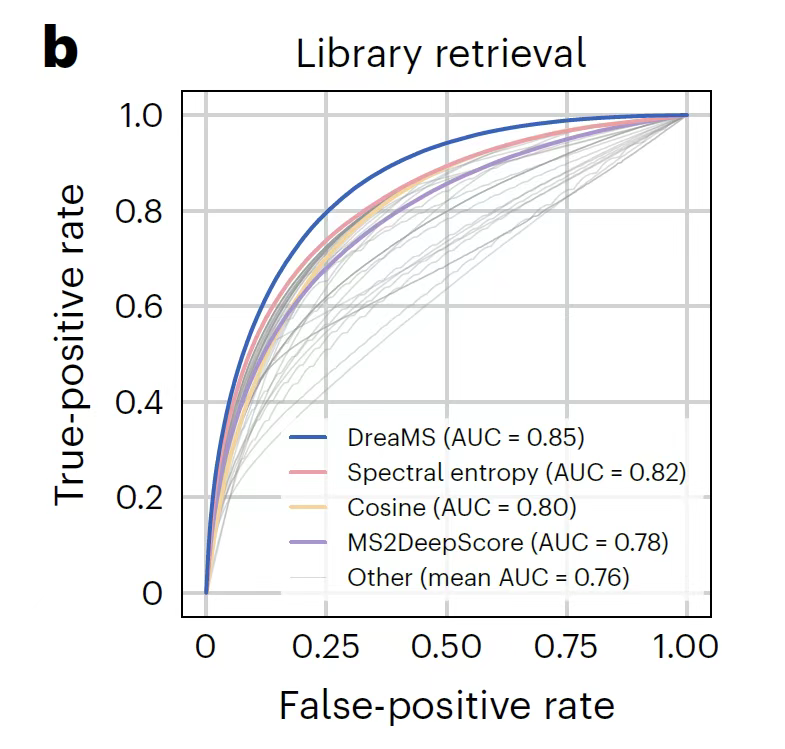
スペクトル類似性分析では、下図に示すように、モデルはまず自己教師あり学習によってゼロサンプルマッチングを実現します。埋め込み空間のコサイン類似度と分子構造の類似度(タニモト係数など)の相関は、ラベル付きデータに基づく教師あり学習アルゴリズムMS2DeepScoreを上回ります。ゼロサンプルは分子構造の微妙な違いに鈍感であるという制約を考慮し、参照スペクトル、同一分子の正のサンプル、類似質量の負のサンプルを含む3つの困難なサンプルを比較と微調整のために設計することで、前駆体質量の偏差が10ppm以内の検索タスクにおいて、微調整された DreaMS は、従来の 44 の類似性メトリックを大幅に上回ります。さらに、埋め込み結果は質量分析機器の違いに対してより堅牢であり、UMAP 分析ではその表現空間が分子の化学式と構造モチーフに従って厳密にクラスター化されていることが示されています。
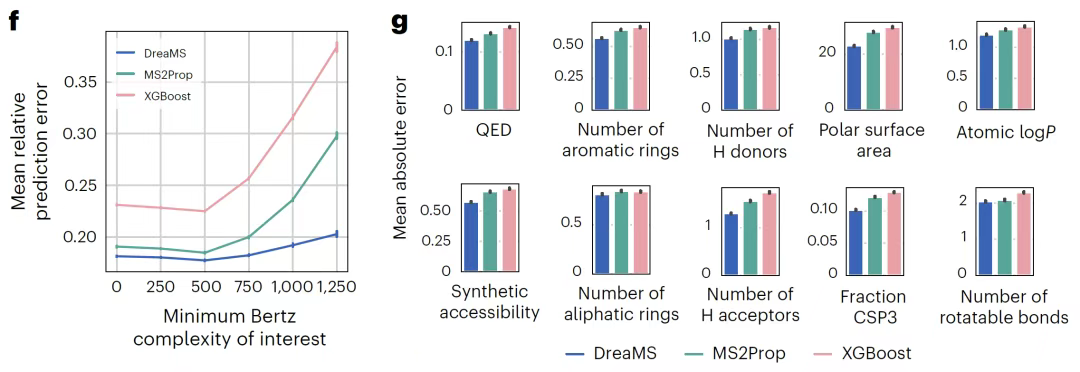
分子指紋予測タスクでは、下図に示すように、DreaMSは化学式の割り当てやフラグメントツリーの生成に依存する従来の手法の複雑なプロセスを打破します。1回のフォワードパスで、生のスペクトルからモルガンフィンガープリントを直接予測できます。PubChemデータベースの検索性能は、ピーク化学式のアノテーションに依存するディープラーニングモデルMISTに匹敵しますが、計算負荷の高い中間ステップは省略されます。医薬品関連の化学特性予測では、このモデルはリピンスキーの5つのルールパラメータ、ベルツの分子複雑性などの指標を微調整により出力します。大規模な薬物スクリーニングと地球外バイオマーカー探索の両方のシナリオにおいて、現在最高のパフォーマンスを達成しています。
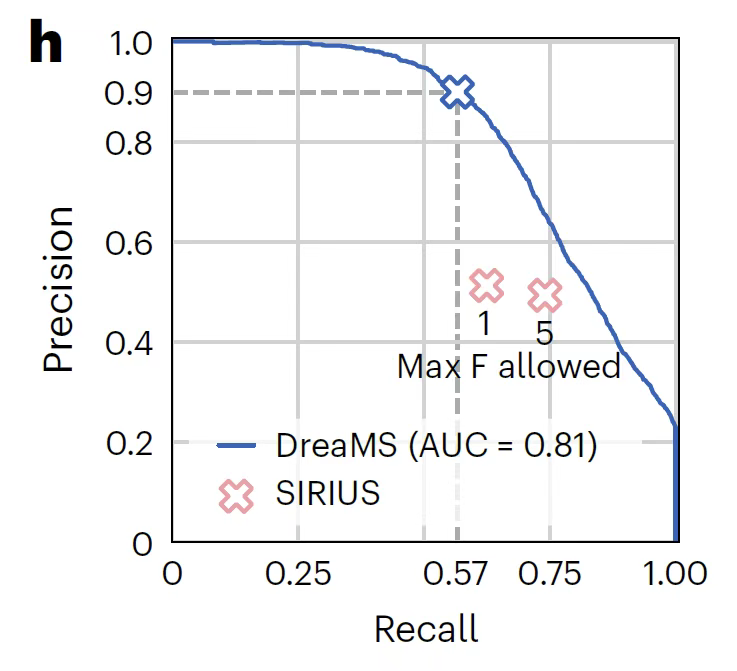
フッ素化分子を検出するという最も困難な課題において、下の図に示すように、DreaMS は確率予測モデルを通じて 0.91 の精度と 0.57 の再現率を達成しています。これは、断片化ルールの組み合わせ検索に依存し、精度がわずか 0.51 である SIRIUS アルゴリズムよりもはるかに優れています。特に、新規構造の分子の検出において強力な汎用性を示し、フッ化物関連の医薬品開発や環境モニタリングに重要なツールを提供します。
研究チームは、高い計算効率(NVIDIA A100 GPUで100万スペクトルの埋め込み計算にわずか1時間)に基づき、下図に示すように、2億100万個の質量スペクトルを含むDreaMSグラフを構築し、局所高感度ハッシュクラスタリングにより3,400万ノードからなる3近傍(3-NN)グラフを生成しました。67%のエッジ類似度は0.8を超え、99.7%ノードが単一の連結成分を形成しています。最短経路解析により、任意のスペクトルを6ステップ以内に既知のライブラリエントリに接続できることが示されました。
腕の乾癬のメタボロミクス研究では、下の図eに示すように、このマップはスペクトルのつながりを通して、疾患と殺菌剤ピラクロストロビンとの潜在的な関連性を明らかにしています。この関連性の経路には、汚染された食品や処理された樹木などの環境曝露源が関与しており、複雑な疾患の原因探究に新たなデータ主導の視点を提供します。単一のタスクを正確にアノテーションしてライブラリネットワーク全体を推測できるこの能力は、質量分析技術が「単一分子のデコード」から「メタボローム全体の相互接続」へと移行した新たな時代を象徴しています。
産学連携が質量分析技術の革新を推進
小分子質量分析およびメタボロミクス研究の分野では、世界中の大学や企業が革新的な技術を使用してこの分野の飛躍的進歩を促進しています。
大学の研究では、中国の清華大学の胡澤平研究室が開発したAI支援型マルチオミクス・ビッグデータ分析技術と高精度メタボロミクス手法を組み合わせることで、腫瘍微小環境におけるニューロンと癌細胞間の代謝相互作用機構を解明し、治療標的となり得る神経伝達物質調節経路を発見することに成功しました。その成果はネイチャー誌で何度も査読されています。中国科学院大連化学物理研究所が開発した「CataAI特性評価エキスパートシステム」は、ディープラーニング技術を質量分析データ分析プロセスに統合し、独自に構築したデータベースと新しいアルゴリズムを使用することで、質量スペクトルから分子構造までのインテリジェントな推奨を実現しました。エネルギー触媒材料の複雑な特性データ用に、2 段階ニューラル ネットワーク モデルが開発されました。
カリフォルニア大学サンディエゴ校(UCSD)のグローバル天然物社会分子ネットワーク(GNPS)プラットフォーム本稿で検討した DreaMS モデルのコアデータセット GeMS のソースとして、機関間の質量分析データの共有と統合を促進し続けています。最新の研究では、エタノールとメタノールの溶媒システムを比較することで腸内微生物叢の高スループットメタボロミクス分析法を確立し、宿主と微生物の相互作用メカニズムを分析するための標準化されたプロセスを提供しました。
企業のイノベーション実践において、米国企業アジレントは、優れた性能と感度を備え、複雑な生物学的分子のモニタリングや不純物の検出に最適な Pro iQ シリーズなどの新世代の液体品質検出システムを発売しました。質量範囲は m/z 2~3000 まで拡張され、Agilent Jet Stream (AJS) テクノロジーによって感度が向上しています。低分子および高分子の日常的および微量検出をサポートし、食品安全監督に革新的な技術的手段を提供します。中国企業であるKailaipu Technologyは、液体クロマトグラフィー-タンデム質量分析技術を基盤として、20種類以上の臨床用質量分析キットを独自に開発し、300種類以上の検出項目をカバーしています。中でも、血中および尿中のカテコールアミン代謝物の検出試薬は、中国医師会内分泌学会の専門家コンセンサスに含まれ、臨床におけるゴールドスタンダードとなっています。
総じて、現在、小分子質量分析とメタボロミクス研究の分野は、大学や企業主導による技術革新の真っ只中にあります。これらの革新は、生物学的システムの複雑性に対する人類の理論的理解を深めるだけでなく、がんの早期診断から心血管疾患の予後予測、触媒材料の研究開発から食品安全監視に至るまで、実用化においても大きな可能性を示しています。アルゴリズム革新と実験科学の共鳴によって引き起こされるこの革命は、基礎研究から臨床応用に至るまでのチェーンエコロジー全体を根本的に再構築し、関連分野にさらに広範な影響を及ぼす可能性があります。
最後に、皆さんにイベントをおすすめしたいと思います。HyperAIは7月5日に北京で第7回Meet AI Compiler Technology Salonを開催します。AMD、北京大学、Muxi Integrated Circuitなどから多くの上級専門家を招待できたのは幸運でした。以下のリンクをクリックして登録してください。
https://www.huodongxing.com/event/1810501012111
参考記事:
1.https://mp.weixin.qq.com/s/1QUjLMtj_6ui9T0gbuZtrA
2.https://dicp.cas.cn/xwdt/ttxw/202411/t20241107_7435521.html
3.https://ccms-ucsd.github.io/GNPSDocumentation/
4.https://mp.weixin.qq.com/s/Wgh2w0G76koqc9AY0PBHcg








