Command Palette
Search for a command to run...
ICLR 2025に選出されたMIT/UCバークレー/ハーバード/スタンフォードなどが、生物学的配列設計のボトルネックを打破するDRAKESアルゴリズムを提案した。
長い間、タンパク質設計の分野における中核的なボトルネックは打破されていませんでした。アミノ酸配列の組み合わせ空間は飛躍的に拡大しており、従来の計算方法では、配列の自然さと安定性を最適化する際に、そのボトルネックを見失ってしまうことがよくあります。遺伝子治療の分野では、科学者は遺伝子発現を効率的に制御する DNA 要素を設計するという課題にも直面しています。 mRNAワクチンの開発においては、配列最適化と翻訳効率向上の間に矛盾が常に存在します。自然言語生成タスクにおいても、エンジニアは文法の正確さとコンテンツのセキュリティのバランスを取る必要があります。一見ばらばらの課題のように見えるこれらの課題は、実際には同じ技術的なボトルネックを指しています。統計分布に準拠する離散シーケンスを生成しながら、特定のタスク目標を最適化するにはどうすればよいでしょうか?
この重要な課題に対処するため、マサチューセッツ工科大学、ハーバード大学、スタンフォード大学、カリフォルニア大学バークレー校、および米国の遺伝子工学技術企業ジェネンテックの研究者が共同で革新的なアルゴリズム「DRAKES」を提案しました。強化学習フレームワークを導入することにより、このアルゴリズムは離散拡散モデルで生成された完全な軌跡に対する微分可能な報酬バックプロパゲーションを初めて実現します。実験により、DRAKES はシーケンスの自然さを維持しながら、下流タスクのパフォーマンスを大幅に向上できることが示されました。さらに、その理論分析により、分布の忠実度とタスクの最適化のバランスをとるこの方法の最適な解決パスが明らかになります。
関連研究成果は、「報酬最適化による離散拡散モデルの微調整とDNAおよびタンパク質設計への応用」というタイトルでICLR 2025に選出されました。長い間、タンパク質設計の分野における中核的なボトルネックは打破されていませんでした。アミノ酸配列の組み合わせ空間は飛躍的に拡大しており、従来の計算方法では、配列の自然さと安定性を最適化する際に、そのボトルネックを見失ってしまうことがよくあります。遺伝子治療の分野では、科学者は遺伝子発現を効率的に制御する DNA 要素を設計するという課題にも直面しています。 mRNAワクチンの開発においては、配列最適化と翻訳効率向上の間に矛盾が常に存在します。自然言語生成タスクにおいても、エンジニアは文法の正確さとコンテンツのセキュリティのバランスを取る必要があります。一見ばらばらの課題のように見えるこれらの課題は、実際には同じ技術的なボトルネックを指しています。統計分布に準拠する離散シーケンスを生成しながら、特定のタスク目標を最適化するにはどうすればよいでしょうか?
この重要な課題に対処するため、マサチューセッツ工科大学、ハーバード大学、スタンフォード大学、カリフォルニア大学バークレー校、および米国の遺伝子工学技術企業ジェネンテックの研究者が共同で革新的なアルゴリズム「DRAKES」を提案しました。強化学習フレームワークを導入することにより、このアルゴリズムは離散拡散モデルで生成された完全な軌跡に対する微分可能な報酬バックプロパゲーションを初めて実現します。実験により、DRAKES はシーケンスの自然さを維持しながら、下流タスクのパフォーマンスを大幅に向上できることが示されました。さらに、その理論分析により、分布の忠実度とタスクの最適化のバランスをとるこの方法の最適な解決パスが明らかになります。
関連研究成果は、「報酬最適化による離散拡散モデルの微調整とDNAおよびタンパク質設計への応用」というタイトルでICLR 2025に選出されました。
用紙のアドレス:
https://doi.org/10.48550/arXiv.2410.13643
「HyperAI Super Neural」の公開アカウントをフォローし、「DRAKES」と返信すると、完全なPDFを入手できます。
オープンソースプロジェクト「awesome-ai4s」100 以上の AI4S 論文解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データセット: DRAKESの多次元的なパフォーマンス評価を実現するために、複数のデータセットを組み合わせて使用します。
この研究は、実験検証をサポートするために複数の公開データセットを使用し、調節 DNA 配列とタンパク質配列の設計を中心に行われました。この研究では、調節 DNA 配列の設計に、長さ 200 bp の DNA 配列約 700,000 個を含む大規模なエンハンサー データセットを使用しました。超並列レポーターアッセイ (MPRA) を通じて、ヒト細胞株におけるエンハンサー活性を測定し、モデルの事前トレーニングと報酬オラクル構築のための基礎データを提供しました。
この実験では、HepG2 細胞株のクロマチンアクセシビリティデータも導入されました。予測されるアクティビティの信頼性を検証するために、合成配列のクロマチンアクセシビリティを独立して評価するために使用されます。さらに、JASPAR 転写因子結合プロファイルを使用して、生成された配列をスキャンし、潜在的な転写因子結合モチーフを探し、エンハンサー活性の主要な特徴の分析を支援しました。
タンパク質配列設計タスクでは、事前トレーニング済みの逆フォールディング モデルは、天然タンパク質の構造と配列データをカバーする PDB トレーニング セットに基づいています。報酬オラクルのトレーニングは、Megascale データセットに依存します。このデータセットには、983 の自然ドメインと設計されたドメインからの約 180 万の配列バリアントが含まれています。生成されたシーケンスの機能特性を評価するために、安定性の尺度が提供されます。標準的なプロセスを使用してデータが選別および分割された後、333 のドメインの約 500,000 のシーケンスが形成され、微調整と評価のための報酬モデルの構築に使用されました。これらのデータセットを組み合わせて使用することで、さまざまなバイオ分子設計タスクにおけるモデル生成シーケンスの機能性、自然な類似性、安定性を効果的に検証できるようになり、DRAKES メソッドのパフォーマンス評価に多次元の経験的サポートが提供されます。
DRAKESアルゴリズム:2段階のアーキテクチャと二重の実験を採用し、生物医学シナリオへの応用の可能性を検証します。
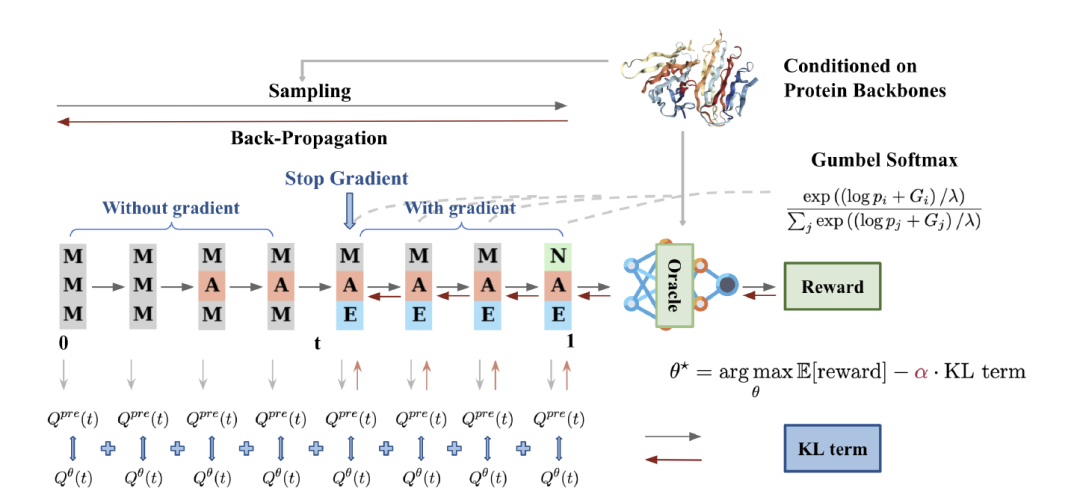
研究者らは、離散拡散モデルを微調整して特定のタスク目標に対する報酬関数を最適化するための DRAKES と呼ばれるアルゴリズムを提案しました。このアルゴリズムは、強化学習 (RL) フレームワークと Gumbel-Softmax を組み合わせたものです。離散拡散モデルにおける報酬の最大化と自然性の維持との間のバランスが解決されます。 DRAKES の中心的なアイデアは、KL ダイバージェンス制約を導入することで報酬を最適化しながら、生成されたシーケンスが事前トレーニング済みモデルの分布に類似していることを保証することです。
具体的には、DRAKES は、サンプリング プロセスと最適化プロセス用にそれぞれ設計された 2 段階のアーキテクチャを採用しています。データ サンプリング ステージでは、アルゴリズムは連続時間マルコフ連鎖 (CTMC) を通じて軌跡を生成し、Gumbel-Softmax 手法を使用して離散サンプリング プロセスを微分可能な操作に変換します。この手法は、ソフトマックスを通じて分類分布を近似し、サンプリングの信頼性を維持し、低温パラメータでの勾配情報を保持します。この設計は、従来の離散拡散モデルにおける微分不可能性の制限を打ち破ります。これは、その後の最適化のための理論的根拠を提供します。
最適化フェーズでは、アルゴリズムは経験的目的関数を最大化することによってパラメータを更新します。Truncated Back-Propagation と Straight-Through Gumbel Softmax テクノロジーを組み合わせることで、トレーニング効率を効果的に向上させることができます。このアーキテクチャは、生成されたシーケンスの自然さを保証するだけでなく、KL ダイバージェンス制約を通じて過剰最適化のリスクを回避し、報酬の最大化と分布の忠実度との間の動的なバランスを実現します。
DRAKES アルゴリズムの有効性を検証するために、研究者らは、調節 DNA 配列設計とタンパク質配列設計という 2 つの主要タスクで包括的な実験評価を実施しました。実験結果は、配列の自然さを維持しながらターゲット特性を大幅に最適化する DRAKES の能力を体系的に実証しています。
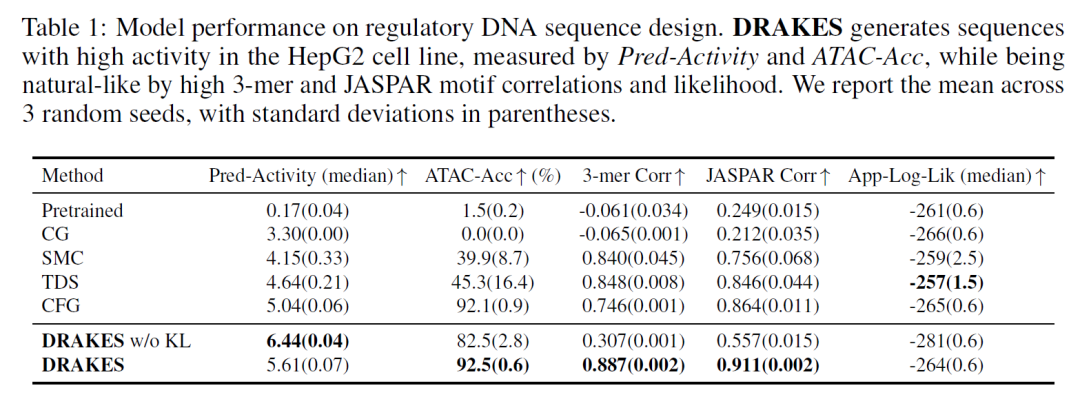
調節性 DNA 配列最適化タスクでは、DRAKES によって生成されたエンハンサー配列は、HepG2 細胞株において予測アクティビティ (Pred-Activity=0.78) とクロマチン アクセシビリティ (ATAC-Acc=0.81) の相乗的な改善を示し、トリプレット ヌクレオチド相関 (0.92) と JASPAR モチーフ相関 (0.88) を自然配列に近い値に維持しました。注目すべきは、KL 正則化なしのバージョンでは予測アクティビティが高かったものの (Pred-Activity=0.85)、独立検証指標 ATAC-Acc (0.72) のパフォーマンスが低下し、過剰最適化によって生成されたシーケンスが自然な分布から逸脱するリスクが明らかになったことです。
タンパク質安定性最適化タスクでは、DRAKES によって生成された配列が、予測される安定性 (Pred-ddG = -1.23 kcal/mol) と構造の一貫性 (scRMSD の成功率 <2 83%) の間で最適なバランスを達成しました。比較実験では、KL 正則化なしのバージョンの方が予測安定性 (Pred-ddG=-1.45 kcal/mol) では優れているものの、構造の自己一貫性は大幅に低下していることが示されています (scRMSD < 2 の成功率はわずか 61%)。 PyRosetta 物理シミュレーションによって検証された結果、ターゲット主鎖構造下で DRAKES によって生成されたシーケンスのギブス自由エネルギー (ΔG = -15.2 kcal/mol) はベースライン メソッドよりも 21% 低く、最適化結果の物理的な合理性がさらに確認されました。
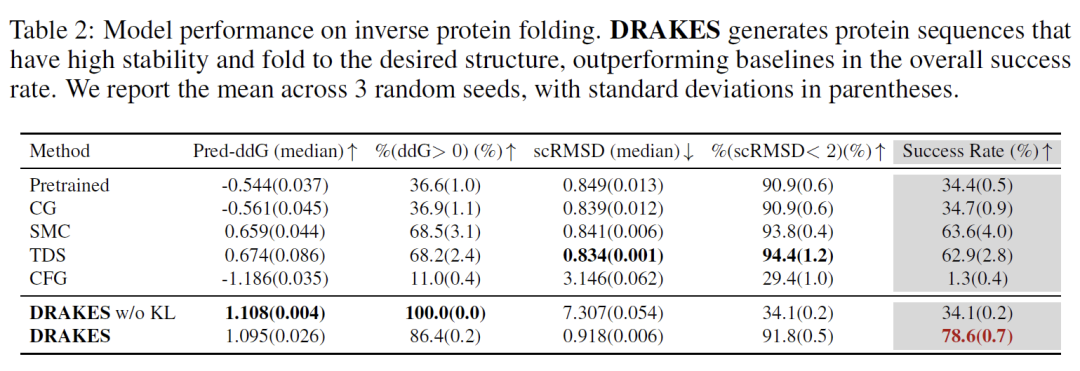
実験結果では、DRAKES アルゴリズムがシーケンスの自然さを維持することが示されています (対数尤度 App-Log-Lik = -1.05)。ターゲット属性の最適化機能が大幅に改善されました。遺伝子調節要素の設計において、35% によってエンハンサー活性が向上します。タンパク質医薬品の設計において、28% によって安定性が向上します。これらの結果は、主要な生物医学的シナリオにおける DRAKES の応用可能性を検証するだけでなく、離散拡散モデルに基づくシーケンス最適化タスクの新しい技術的パラダイムを確立します。
離散拡散モデルと生物学的配列設計における中国の革新的な進歩
近年、中国は離散拡散モデルと生物配列設計の分野で理論革新から産業応用までの完全な技術システムを構築し、離散拡散モデルの理論的枠組み内で多くの独創的な方法を提案した。たとえば、上海元馬智能製薬が開発した3次元RNA双曲型離散拡散モデルは、RNAの幾何学的特徴を双曲型空間に埋め込み、双曲型幾何学の指数関数的成長特性を利用して、有限サンプル条件下で正確な構造配列マッピングを実現します。実験データによれば生成された配列とターゲット構造の類似性は、従来の方法よりも 23% 高くなります。これは、特に複雑な擬似結び目構造の予測において大きな利点を示します。微分幾何学と生成モデルを統合するこの革新的なアプローチは、中国がバイオ分子コンピューティングの分野で「自己定義パラダイム」の新しい段階に入ったことを示しています。
遺伝子治療の分野では、復旦大学の李華氏のチームが開発した遺伝性難聴の治療薬。DNA配列の機能発現を精密に制御することで、臨床試験において68%の聴力改善率が達成されました。その技術の核心は、「配列編集-エピジェネティック制御-機能検証」の3段階の最適化システムの構築にあります。これは、方法論レベルで離散拡散モデルの方向性最適化の概念と深く適合します。この躍進は「中国(北京)自由貿易試験区昌平グループ医薬・健康産業支援措置」(2023年)の政策支援によるもので、細胞・遺伝子治療が重要な方向性として明確に挙げられ、「アルゴリズム設計、実験検証、臨床変革」のフルチェーンの協働イノベーションが求められている。
記事リンク:
https://doi.org/10.1016/S0140-6736(23)02874-X
中国国家生物情報科学センター (CNCB) が導入した専用のコンピューティング プラットフォームは、大規模な生物学的配列設計のための戦略的なインフラストラクチャを提供し、従来の研究室では数か月かかるタンパク質折り畳みシミュレーションを迅速に完了できます。復旦大学、西安交通大学、中国医学科学院など26の機関が共同で発表した中国汎ゲノムコンソーシアム(CPC)の研究進捗の第一段階は、まず中国人に限定した初の汎ゲノム参照地図を構築し、中国人の遺伝子コードを解読するための基礎を築いた。この「コンピューティングパワー + データ」の二輪駆動モデルは、生物学的配列設計における 2 つの大きな問題点、すなわち集団特異性の問題とロングテール効果の突破を効果的に解決します。
AIが生成した生物学的配列の潜在的なリスクに直面して、全国人民代表大会は2024年に「中華人民共和国バイオセーフティ法」を改正し、「人工知能技術の乱用によって引き起こされるバイオセーフティリスクの防止」を強調した。遺伝子編集や合成生物学などの技術に対してフルチェーン監視を実施することが求められています。技術開発の安全な境界を設定します。
現在、中国は離散拡散モデルと生物配列設計の分野で「理論-応用-設備-標準」の完全なイノベーションチェーンを形成しています。これらの進歩は、バイオメディカル研究開発の根本的な論理を再構築するだけでなく、バイオテクノロジー産業の新たな世代の革命をもたらす可能性も秘めています。サウジアラビアのメディア「メッカ」紙は次のように報じている。「中国は西側諸国に追いついているだけでなく、独自の革新的な特徴を確立しつつある。若い世代のイノベーターたちは先端技術に注力しており、それが中国を世界をリードするバイオテクノロジー大国へと押し上げ、世界的なバイオテクノロジー大国となることが期待されている。」
参考文献:
1.https://export.shobserver.com/baijiahao/html/709277.html
2.https://www.ncsti.gov.cn/kjdt/yqdy/cpy2/zchj/202410/t20241012_181850.html
3.https://sghexport.shobserver.com/html/baijiahao/2023/06/15/1051928.html
4.http://news.china.com.cn/2025-01/03/content_117643069.shtml








