Command Palette
Search for a command to run...
拡散モデル×音楽生成、DiffRhythmならわずか数分で楽曲制作が完了! MiniMindデータセットはオープンソース化されており、大きな言語モデルの導入を低い障壁で可能にします。

音楽生成の分野は近年大きな進歩を遂げていますが、既存のモデルでは実際の応用において依然として多くの制限があります。ほとんどのモデルはボーカルまたは伴奏トラックを個別に生成することしかできないため、一貫性のない音楽体験になります。これらの課題に対処するために、西北工科大学の音声音声言語処理研究所と香港中文大学が共同で DiffRhythm と呼ばれるモデルを開発しました。
拡散技術に基づく初のオープンソース完全楽曲生成モデルとしてDiffRhythm は、高レベルの音楽生成と理解可能性を維持するだけでなく、簡潔で効果的なモデル、アーキテクチャ、およびデータ処理パイプラインを通じてスケーラビリティも確保します。ユーザーエクスペリエンスの面では、非自己回帰構造により高速な生成速度が保証されます。わずか 1 分で完全な音楽を生成します。
現在、HyperAI は「DiffRhythm: 1 分で完全な音楽デモを生成する」チュートリアルを公開しています。ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/sHdPu
3月17日から3月21日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 2
* コミュニティ記事の選択: 6 記事
* 人気のある百科事典のエントリ: 5
* 3月に締め切りを迎えるトップカンファレンス: 1
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
このデータセットは現在、コーディング タスクの検証可能なソリューションとテストを提供する、完全に合成された最大のオープン ソース データセットです。このデータセットには 12 の異なるサブセットが含まれており、さまざまな分野 (アルゴリズムからソフトウェア パッケージ固有の知識まで) と難易度 (基本的なコーディング演習から面接や競技プログラミング チャレンジまで) をカバーし、教師あり微調整 (SFT) と RL 調整用に設計されています。
直接使用します:https://go.hyper.ai/CfZCm
このデータセットには 2.7k 枚の画像が含まれており、主に道路上の穴、亀裂、開いたマンホールを検出するために使用されます。
直接使用します:https://go.hyper.ai/XPJNQ

これは、人間のデモンストレーション データのサンプルが 51 個含まれた小さなデータセットです。データと形式を理解し、コードを実行してトレーニング プロセスを体験するのに役立ちます。この研究の背景は、雑然としたシーンでの器用な把握の成功率を高める必要性から生まれたもので、特に、物体、照明、背景のこれまでにない組み合わせで 90% を超える成功率を達成する必要性です。
直接使用します:https://go.hyper.ai/pJ44Y

4. IllusionAnimals 視覚錯視 VQA データセット
IllusionAnimals データセットは、2,000 個のサンプルを含む FiftyOne データセットです。データセットには、10 個の動物カテゴリと 1 つの非錯覚カテゴリが含まれています。画像の解像度は 512×512 ピクセルです。これは、動物ベースの視覚錯覚を識別および説明するマルチモーダル モデルの能力を評価するために使用されます。
直接使用します:https://go.hyper.ai/Ebl40

5. m-WildVision 多言語マルチモーダル大規模モデル評価データセット
このデータセットには、WildVision-Arena プラットフォームから派生した 23 の言語での 500 件の難しいユーザー クエリ例が含まれています。データセットの構造には、質問 ID、言語タイプ、指示テキスト、画像データが含まれており、さまざまな言語でのモデルの一般化と堅牢性を評価することを目的としています。
直接使用します:https://go.hyper.ai/Im6mN

6. MiniMind大規模モデルトレーニングおよび微調整データセット
MiniMind は、大規模言語モデル (LLM) の使用のハードルを下げ、個々のユーザーが一般的なデバイスで迅速にトレーニングおよび推論できるようにすることを目的とした、オープンソースの軽量大規模言語モデル プロジェクトです。
直接使用します:https://go.hyper.ai/gCz2y
7. Seaclear 海洋ゴミ検出およびセグメンテーションデータセット
このデータセットには、オブジェクト検出およびインスタンスセグメンテーションタスク用に注釈が付けられた 8,610 枚の海洋ゴミ画像が含まれており、ゴミだけでなく、観察された動物、植物、ロボットの部品など 40 のオブジェクトカテゴリをカバーしています。注釈は COCO 形式 (.json) ファイルとして提供され、画像はフォルダーに整理され、各フォルダーは固有のサイトとカメラのペア専用になります。すべての画像の解像度は1920×1080です。
直接使用します:https://go.hyper.ai/JFofd
8. テキストと音声のキャプチャ テキストと音声のキャプチャ データセット
このデータセットには 10 万個の CAPTCHA サンプルが含まれており、それぞれに対応する英数字の文字列がラベル付けされているため、OCR モデル、音声認識、AI ベースの CAPTCHA ソルバーのトレーニングに最適です。
直接使用します:https://go.hyper.ai/vFmTJ
このデータセットには、プラスチック、紙および段ボール、ガラス/金属、有機、廃棄物、繊維、電子機器(電子廃棄物)など、さまざまな種類の廃棄物を分類および検出するための画像と YOLO 形式の注釈が含まれています。
直接使用します:https://go.hyper.ai/NwEF7
10. 火星表面画像(キュリオシティ探査機)火星表面画像データセット
このデータセットは、火星科学研究所 (MSL) の 3 つの機器 (右目用マストカメラ、左目用マストカメラ、MAHLI) によって収集された 6,691 枚の画像で構成され、24 のカテゴリをカバーしています。これらの画像は、各生データ製品の「参照」バージョンであり、フル解像度ではなく、画像あたり約 256×256 ピクセルです。
直接使用します:https://go.hyper.ai/B1T0l
選択された公開チュートリアル
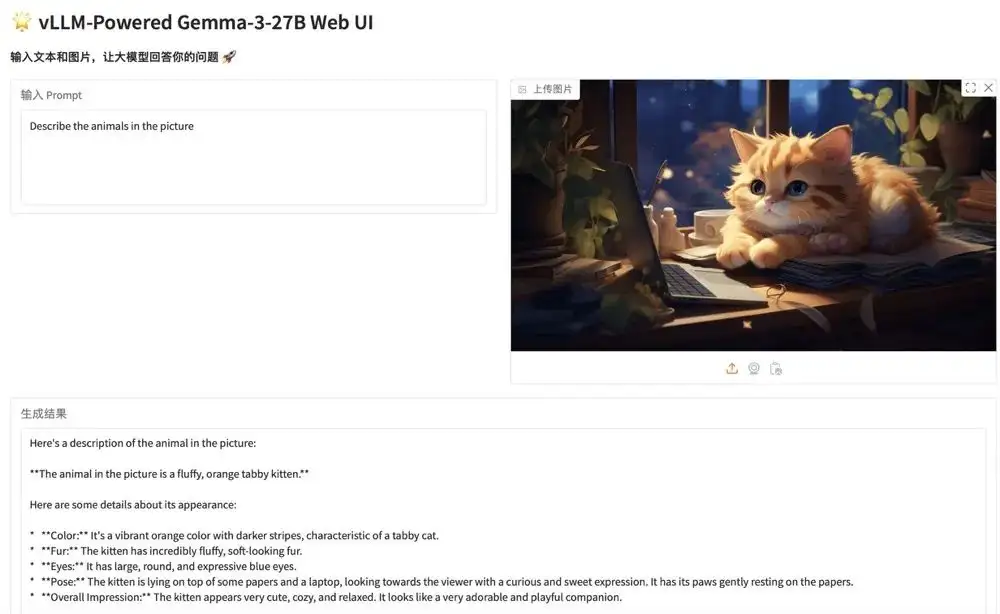
1. vLLMを使用してGemma-3-27B-ITを展開する
Gemma シリーズは、Google がオープンソース化した大規模なモデル シリーズであり、Gemini モデルと同じ研究とテクノロジーに基づいて構築されています。 Gemma 3 は、テキストと画像の入力を処理し、テキスト出力を生成できる大規模なマルチモーダル モデルです。このモデルは、質問への回答、要約、推論など、さまざまなテキスト生成および画像理解タスクに適しています。比較的小型なので、ラップトップ、デスクトップ、クラウド インフラストラクチャなど、リソースが限られた環境に導入できます。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/JxVbA
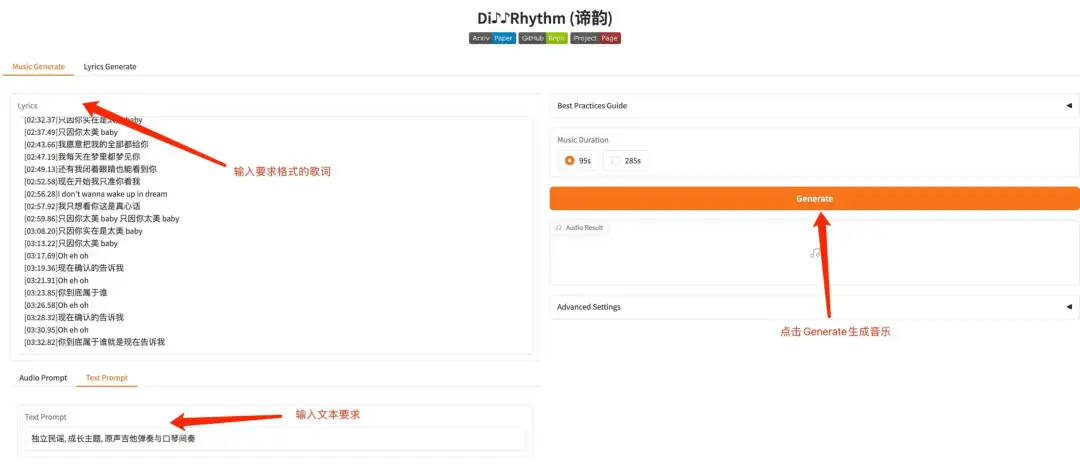
DiffRhythm は、曲全体を作曲できる初めての拡散ベースの曲生成モデルです。ボーカルと伴奏を含めた最長4分45秒の完全な曲を短時間で生成できます。ユーザーは歌詞とスタイルのヒントを提供するだけで、DiffRhythm は歌詞に一致するメロディーと伴奏を自動的に生成し、多言語入力をサポートします。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/sHdPu
注目のコミュニティ記事
1. 計算効率が3000倍に向上!崂山実験室らは、数値海洋予測よりも優れた性能を持つ海洋環境の大規模インテリジェント予測モデル「温海」を提案した。
呉立新院士のチームは、海洋物理学とAIを深く融合し、海洋力学理論を利用してニューラルネットワークアーキテクチャを駆動し、大規模な地球規模の高解像度海洋環境インテリジェント予測モデル「文海」を構築して、実際の海洋の状態をよりよく反映し、計算時間とエネルギー消費を大幅に節約しました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/s7YMj
2. ICLR 2025に選出されました!ケンブリッジ大学が提案したセルコメンモデルは、空間トランスクリプトミクス解析における因果推論の識別可能性を初めて達成した。
ケンブリッジ大学の研究チームは、環境が個々の細胞に与える影響を推定できるだけでなく、個々の細胞が周囲の環境や組織全体に与える影響を推測できる仮想組織モデル「セルコメン」を提案した。研究者らは、自己矛盾のない合成データと実世界のデータ実験を通じて、因果構造学習と因果関係の解明におけるセルコメンモデルの識別可能性、および現実と自己シミュレーションの空間トランスクリプトミクスデータにおける遺伝子間相互作用の解明と回復能力を検証した。関連する結果が ICLR 2025 に選ばれました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/ylKOr
3. HUST/上海AIラボ/上海交通大学の研究の先駆者による詳細な情報共有:最新の成果、トップカンファレンスへの論文投稿の経験、学際的なコラボレーションの課題など...
第7回Meet AI4Sライブ放送では、HyperAIが華中科技大学の黄紅准教授、上海AIラボの周東展博士、上海交通大学研究所の周秉馨博士を招き、社会科学、物理化学、生命科学などの分野におけるAIの最先端の開発について3人の学者と議論しました。また、研究の方向性を選択する際の洞察や、トップクラスのAIカンファレンスに論文を提出した経験も共有しました。この記事は3人の先生方のシェアをまとめたものです。
レポート全体を表示します。https://go.hyper.ai/klU6m
4. GTC 2025: チップだけではなく、ジェンセン・フアンは30分で物理AIにおけるいくつかの新しい成果を発表しました。すべてオープンソースです。
NVIDIA CEO のジェンスン フアンは、毎年開催される世界的な AI イベントである GTC 2025 カンファレンスで基調講演を行い、最先端 AI 分野の最新動向に焦点を当てました。ブラックウェルの新世代核グレードAIチップが披露されただけでなく、物理AIデータセット、GR00T N1モデル、ニュートン物理エンジン、コスモス世界モデルなど、一連の新たな成果も発表されました。この記事は黄仁訓氏の講演内容と新たな成果をまとめたものです。
レポート全体を表示します。https://go.hyper.ai/Q6wdO
NVIDIA は、MIT などと共同で、新しいタイプの大規模フロー タンパク質バックボーン ジェネレーターである Proteina を開発しました。 Proteina は RFdiffusion モデルの 5 倍のパラメータ数を持ち、トレーニング データを 2,100 万の合成タンパク質構造に拡張しました。de novo タンパク質バックボーン設計で SOTA パフォーマンスを達成し、最大 800 残基という前例のない長さの多様で設計可能なタンパク質を生成しました。その成果は ICLR 2025 Oral に選出されました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/w7jlU
6. 医師研修にDeepSeekプラグインを導入!上海体育学院、上海交通大学、清華大学の共同研究により、大型モデルがプライマリケア医師のトレーニングの「黄金のパートナー」になり得ることが証明された。
上海交通大学は、ChatGPTやDeepSeekを含む国内外の10の主流法学修士課程を対象に、権威ある評価システムを構築し、体系的なテストを実施するために、いくつかのトップ機関と提携しました。これは、AI支援によるプライマリケア医師のトレーニングに関する初の実世界証拠を提供し、AI対応のプライマリヘルスケアに重要なサポートを提供します。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/DH8hf
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1700 を超える公開データ セットに対して国内の高速ダウンロード ノードを提供
* 500 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








