Command Palette
Search for a command to run...
サイエンスのサブマガジンに参加してください!上海交通大学、上海AI研究所などが最先端の手法を上回るタンパク質変異体設計モデルを発表

タンパク質は人間の生命活動の担い手であるだけでなく、生物医学、食品加工、醸造業、化学工業などの分野でも重要な役割を果たしています。したがって、ニーズを満たし、産業応用シナリオに適した安定性の高いタンパク質を選択するために、タンパク質の構造と機能に関する研究が絶えることはありません。
しかし、生物から抽出された「野生型」タンパク質が工業環境で機能するために必要な物理的および化学的条件(温度、pHなど)は、ほとんどの場合、本来の生物学的環境とはかけ離れています。言い換えれば、このタイプのタンパク質の安定性は、過酷な産業環境に適応することが困難です。したがって、さまざまなアプリケーションシナリオのニーズを満たすために、タンパク質の物理的および化学的特性を改善して、極端な温度/pH 条件下での安定性を向上させたり、酵素の活性と特異性を高めたりするために、突然変異が必要になることがよくあります。
タンパク質の生物学的活性を変化させるには、その作用メカニズムに関する数年間の実験研究が必要であり、これには時間と労力がかかるだけでなく、急速に変化する修飾のニーズを満たすことがますます困難になることに注意する必要があります。近年、タンパク質言語モデルの出現により、タンパク質のフィットネス予測の精度は大幅に向上しましたが、安定性の予測精度はまだ不十分です。
本当に意味のあるタンパク質の変異は、生物学的活性を維持しながら安定性を向上させる必要があり、その逆も同様です。これに応えて、上海交通大学自然科学研究所/物理天文学部のホン・リャン教授の研究グループは、上海人工知能研究所の若手研究者タン・パン氏や上海科学大学の共同研究者らと協力した。とテクノロジーと中国科学院杭州医科大学。新しいタンパク質配列大規模言語モデル事前トレーニング手法 PRIME を共同開発しました。同時に、タンパク質の突然変異活性と突然変異安定性の予測、およびその他の温度関連表現学習において最高の予測結果を達成しました。
関連する研究のタイトルは「安定性と活性が強化されたタンパク質を設計するための一般的な温度ガイド言語モデル」で、有名な雑誌 Science の子会社である Science Advances に掲載されました。
研究のハイライト:
* PRIME は、事前の実験データに依存せずに、特定のタンパク質変異体のパフォーマンス向上を予測できます
* PRIME はタンパク質の複数の特性を効果的に予測できるため、研究者はなじみのないタンパク質分野でも首尾よく設計できるようになります。
* PRIME は、タンパク質配列の温度特性をより適切に捕捉できる「温度認識」言語モデルに基づいてトレーニングされています。

用紙のアドレス:
https://www.science.org/doi/10.1126/sciadv.adr2641
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データセット: タンパク質配列と温度の関係を調査する 9,600 万のデータポイント
Uniprot (Universal Protein Resource) の公開データと、メタゲノム研究を通じて環境サンプルから得られたタンパク質配列を統合することで、研究者らは、47 億の天然タンパク質配列を含む大規模なデータベースである ProteomeAtlas を編集しました。
* UniProt は、タンパク質配列と関連する詳細な注釈を提供する大規模なデータベースです。
配列スクリーニングプロセス中、研究者らは完全長配列のみを保持し、生物学的配列アラインメントツールMMseqs2を使用してこれらの配列を処理し、配列同一性閾値を50%に設定して冗長性を減らし、それらに関連する配列に関連する細菌株を特定して注釈を付けた。最適成長温度 (OGT) まで。
ファイナル、研究者たちはこの方法で9,600万のタンパク質配列に注釈を付けました。タンパク質の配列と温度の関係を調べるための豊富なリソースを提供します。
さらに、モデルの熱安定性のゼロショット予測能力の分析では、融解温度変化 (ΔTm) の研究に使用されたデータセットは MPTherm、FireProtDB、および ProThermDB から取得され、すべての実験が以下の条件の下で実行されることを保証しました。同じpH条件。
その中で、MPTherm にはタンパク質の熱安定性に関する実験データが含まれており、FireProtDB はタンパク質の熱安定性と機能に関する突然変異実験データの保存に特に使用され、ProThermDB はタンパク質の熱力学特性に関するデータの収集に特化しています。同時に、研究者らは、主にタンパク質変異解析データベース ProteinGym からのディープミューテーション スキャン (DMS) データも組み合わせました。
* ProteinGym タンパク質変異データセット
https://go.hyper.ai/YlMT5
モデルアーキテクチャ:「温度認識」に基づく深層学習モデル
本研究で提案した新しい深層学習モデルPRIME(Protein language model for Intelligent Masked pretraining andEnvironment Prediction)は、事前の実験データに依存せずに、特定のタンパク質変異体のパフォーマンス向上を予測する機能。
このモデルは、トークン レベルでのマスク言語モデリング (MLM) タスクと最適成長温度 (OGT) 予測ターゲットと組み合わせた、9,600 万個のタンパク質配列のデータセットに依存する「温度認識」言語モデルに基づいてトレーニングされます。配列レベルで、マルチタスク学習を通じて相関損失項を導入します。これにより、高温耐性を持つタンパク質配列を選別して、その安定性と生物学的活性を最適化できます。
具体的には、PRIME は 3 つの主要な部分で構成されます。以下に示すように。 1 つ目は Encoder モジュールで、シーケンスの潜在的な特徴を抽出するために使用される Transformer エンコーダーです。 2 つ目は MLM モジュールで、エンコーダーがアミノ酸の文脈上の表現を学習できるように設計されています。同時に、MLM モジュールは変異体のスコアリングにも使用できます。 3 番目のコンポーネントは OGT 予測モジュールで、基礎となる表現に基づいてタンパク質が存在する生物の OGT を予測します。
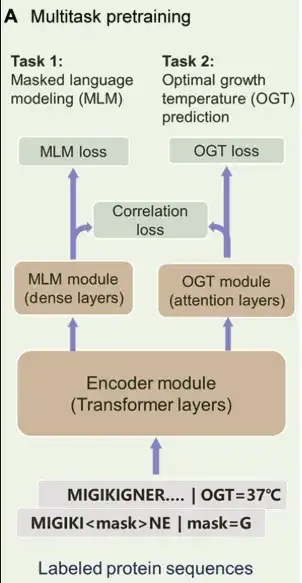
PRIME の事前トレーニング段階でのマルチタスク学習には、MLM、OGT 予測、相関損失が含まれます。
で、MLM は、シーケンス データ表現の事前トレーニング方法としてよく使用されます。この研究では、ノイズのあるタンパク質配列が入力として取得され、部分マーカーがマスクされるか代理マーカーで表され、トレーニングの目標はこれらのノイズのあるマーカーを再構築することです。このアプローチは、モデルがアミノ酸間の依存関係や配列のコンテキスト情報を捕捉するのに役立ち、同時にこの再構成プロセスを使用して変異をスコアリングします。
2 番目のトレーニング タスクである教師あり最適化では、研究者らは OGT で注釈が付けられた 9,600 万個のタンパク質配列のデータセットを使用して PRIME モデルをトレーニングしました。このタスクへの入力はタンパク質シーケンスであり、OGT モジュールによって生成される温度値の範囲は 0° ~ 100°C です。 OGT モジュールと MLM モジュールは共有エンコーダを使用して実行されることに注意してください。この構造により、モデルはアミノ酸のコンテキスト情報とその中の温度に関連した配列の特徴を同時に捕捉することができます。
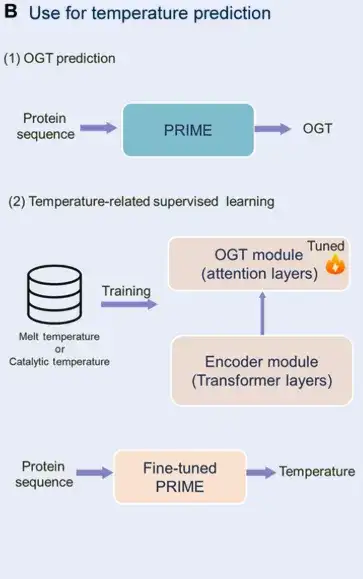
最後に、研究者らは相関損失を導入して、予測された OGT から MLM 分類へのフィードバックを促進し、トークンとシーケンスレベルのタスク情報を調整しました。これにより、大規模なモデルでタンパク質配列の温度特性をより適切に捕捉できるようになります。
実験の結論: 変異タンパク質配列の適応性の予測において最先端の方法を上回る性能を発揮
研究者らは、PRIME のゼロショット予測機能を、深層学習モデル ESM-1v、ESM-2、MSA-transformer、Tranception-EVE、CARP、MIF などの熱安定性に関する現在の最先端モデルと実験的に比較しました。 - ST、SaProt、Stability Oracle、および従来の計算方法 GEMME および Rosetta。
研究者らは、同じ pH 環境で収集された融解温度変化 (ΔTm) を含む MPTherm、FireProtDB、ProThermDB のデータセットを使用し、合計 66 のアッセイでタンパク質ごとに少なくとも 10 のデータ ポイントを確保しました。同時に、この研究には、ProteinGym をテストベンチマークとして使用する、ディープミューテーションスキャン (DMS) の検出方法も含まれています。
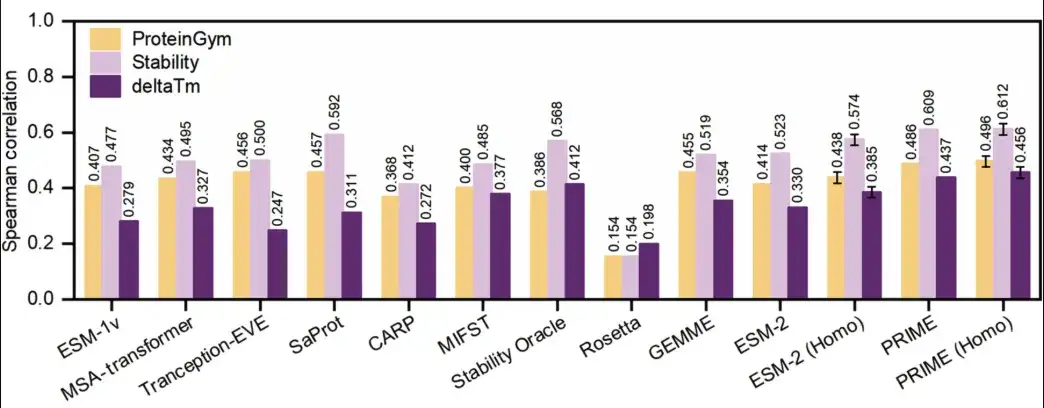
結果は下の図に示されています。PRIME は、タンパク質の利用可能性と安定性の予測において、他のすべての方法よりも優れた性能を発揮しました。
ProteinGym ベンチマーク (下の画像の黄色) では、PRIME のスコアは 0.486、2 位の SaProt のスコアは 0.457 でした。 ΔTm データセット (下図の濃い紫色) では、PRIME は依然として 0.437 のスコアで 1 位、0.412 のスコアで 2 位にランクされています。さらに、研究者らは PRIME を ProteinGym のサブデータセット ProteinGym-stability (以下の薄紫色) の他の手法と比較しましたが、それでも PRIME は他のすべての手法を上回っていました。
注目に値するのは、タンパク質工学の実用化におけるPRIMEの有効性と効果をテストするために、研究者らは湿式実験も実施し、検証のために5つのタンパク質を選択した。LbCas12a、T7 RNA ポリメラーゼ、クレアチナーゼ、人工核酸ポリメラーゼ、および特定のナノボディの重鎖可変領域が含まれます。
上位 30 ~ 45 の単一点変異の実験的検査では、30% を超える AI は、熱安定性、酵素活性、抗原抗体結合親和性、非天然核酸の重合能力などの重要な特性のパフォーマンスが低い単一点変異を推奨しました。性的条件下での耐性は野生型タンパク質よりも大幅に優れており、個々のタンパク質の陽性率は 50% を超えています。
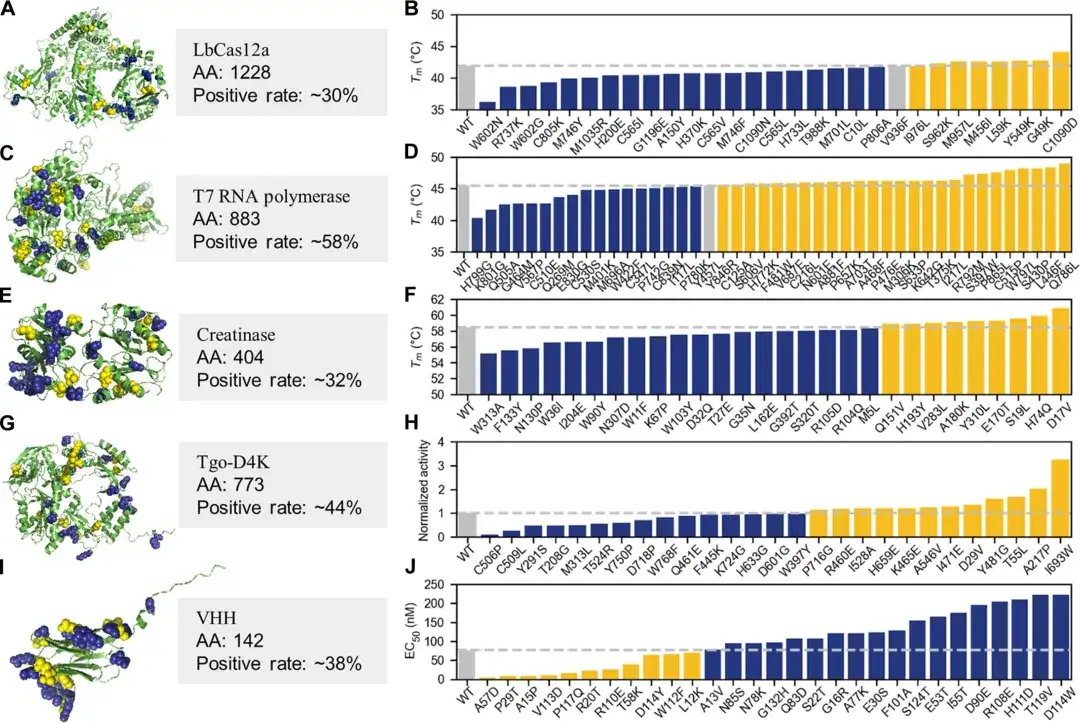
チームが PRIME に基づいた効率的な方法も実証したことは注目に値します。活性と安定性が向上した多部位変異体を迅速に取得できます。この少量サンプルの微調整方法により、100 未満の湿潤実験サンプルを使用して 2 ~ 4 ラウンドの進化で非常に優れたタンパク質変異体を生成できます。
たとえば、T7 RNA ポリメラーゼを乾式および湿式で 4 回繰り返した後、高い活性と安定性を備えた多点変異体の取得に成功しました。最も高い多点変異体の Tm は野生型よりも 12.8℃高かったです。その活性は野生型のほぼ 4 倍であり、一部の製品の性能は、10 年間市場を独占してきた大手国際バイオテクノロジー企業である New England Biolabs の同様の製品を上回っています。さらに、LbCas12a および T7 RNA ポリメラーゼを使用した実験では、Pro-PRIME は負の単一点変異を重ね合わせて、正の複数点変異を取得できます。
これは、PRIME が配列データからタンパク質変異のエピスタティック効果を学習できることを示しており、これは従来のタンパク質工学にとって非常に重要です。
タンパク質工学を深く探究し、サンプルが少ないという問題を克服します
タンパク質工学の分野では、タンパク質の発現、精製、機能試験には通常、高価な試薬や機器が必要であり、実験には時間がかかるため、生成できるサンプルの数が大幅に制限されます。タンパク質の機能研究において、機能(触媒活性、熱安定性、結合親和性など)に対するタンパク質の変異の影響をテストするには、より正確で複雑な実験が必要であり、すべての考えられる変異のパフォーマンスを 1 つの方法で測定することは困難です。時間の高いスループット。
これにより、機械学習モデルが限られたサンプルで十分なトレーニングを行うことが困難になり、新しい突然変異を予測する際にモデルのパフォーマンスが低下する可能性があります。また、サンプル データが小さい場合、実験エラーやノイズがモデル トレーニングに大きな干渉を引き起こす可能性があります。言えることは、サンプルデータが少ないという課題により、タンパク質工学分野における研究の効率と精度がある程度制限されます。このことは、長所と短所に加えて、機械学習、実験技術、マルチモーダルデータ分析を組み合わせて、少量のサンプルの限界を突破する革新的な技術を研究者が探求することを大いに促進しました。
この記事で説明した研究チームは、上記の PRIME に加えて、Hong Liang 教授のチームと Tan Pan 博士も、小規模サンプル学習に関する多くの結果を発表しています。
以前、チームはメタ転移学習 (MTL)、ランク付け学習 (LTR)、およびパラメーター効率の良い微調整 (PEFT) を使用して、データが極度に不足している場合にタンパク質言語モデルを効果的に最適化できるトレーニング戦略 FSFP を開発しました。これは、タンパク質の適合性の小規模サンプル学習に使用でき、非常に少ないウェット実験データを使用して突然変異特性を予測する従来のタンパク質事前トレーニング大規模モデルの効果を大幅に改善し、実用的なアプリケーションでも大きな可能性を示します。
関連する研究のタイトルは「少数ショット学習による最小限のウェットラボデータによるタンパク質言語モデルの効率の向上」で、Nature の子会社である Nature Communications に掲載されました。
さらに、ホン・リアン教授は、「今後 3 年間で、専門分野における一般的な人工知能が明確なパラダイム変化をもたらし、人間による散発的な試行錯誤に依存していた科学的発見モデルを変革するだろう」と信じています。過去の脳は、大規模な AI モデルの自動化された標準設計モデルに組み込まれていました。」
具体的な変更には、ゼロサンプルまたは小規模サンプルの学習方法の構築と、事前トレーニング技術モデルの構築が含まれます。データがない場合は、物理シミュレーターを使用して精度が若干低い偽データを大量に生成して事前学習し、実際の貴重なデータを使用して微調整して強化学習を完成させます。
ホン教授は、「フェイクデータとは、現実世界ではないが、AIによって生成されたデータや、最終的には実際の湿式実験によって強化されたデータを指します。データは最も貴重であり、モデルの最終的な微調整に使用できます。」
データ不足という課題がタンパク質工学の分野にだけ存在するわけではないのは事実です。少量のサンプルまたはゼロサンプルの学習方法も非常に重要です。私たちは、Hong Liang 教授のチームと Tan Pan 博士がより高品質なデータを提供することを期待しています。この問題点に関する結果が得られます。








