Command Palette
Search for a command to run...
AlphaFold 2 の背後にある PDB タンパク質構造データセットについて 1 つの記事で学びましょう
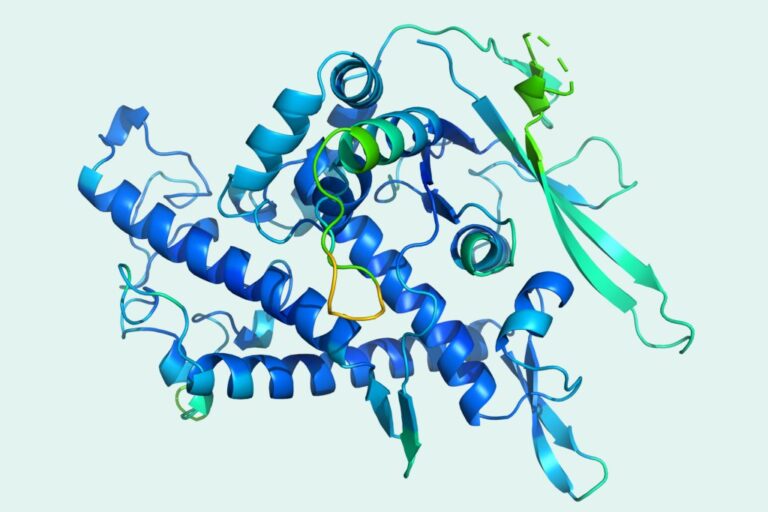
DeepMind の最新世代アルゴリズムである AlphaFold 2 は、最近「タンパク質オリンピック」と呼ばれた CASP で他の対戦相手を完全に破り、驚くべき進歩を遂げ、科学研究界全体に衝撃を与えました。この科学的研究結果に衝撃を受けた後、アルゴリズムの背後にあるデータセットを見てみましょう。
この 2 日間、私たちは DeepMind の新世代人工知能アルゴリズム AlphaFold 2 に圧倒されました。特に生物学の世界では、画期的な進歩の到来を告げたと言えます。
DeepMind は、同社の深層学習アルゴリズム AlphaFold 2 が過去 50 年間にわたって生物学分野の主要な問題の解決に成功したことを正式に発表しました。
このアルゴリズムは、アミノ酸配列に基づいてタンパク質の 3D 構造を正確に予測でき、その精度は、極低温電子顕微鏡 (CryoEM)、核磁気共鳴、X 線結晶構造解析などの実験技術を使用して解析される 3D 構造に匹敵します。

この画期的な出来事は生物学者を興奮させますが、同時に業界の多くの人々を震撼させ、ディープラーニングを学ぶためにキャリアを変えるよう求めています。
しかし、この科学研究の成果に誰もが注目する一方で、その背後にいる英雄の存在も忘れてはなりません――。 PDBタンパク質構造データセットは、タンパク質や核酸の三次元構造データを具体的に収集したデータセットです。
画期的な進歩はこのデータセットと切り離すことができません
DeepMind によると、チームは公開データに基づいてこのシステムをトレーニングしました。これらのデータは、タンパク質構造データ セット PDB と、合計約 170,000 個のタンパク質構造を含む、未知の構造のタンパク質配列を含む大規模なデータベースである UniProt から取得されます。
で、PDB は、タンパク質や核酸の三次元構造データを収集するデータセットであり、その歴史は 1971 年まで遡ります。
米国のブルックヘブン国立研究所のウォルター・ハミルトンは、このデータベースを構築することを決定しました。 1998 年 10 月に、PDB は、RCSB のメンバーでもあるラトガース大学のヘレン M. バーマンの指導の下、構造バイオインフォマティクス研究協力機関 (RCSB) に移管されました。

2003年、PDB は、PDB のリソースを監督する国際組織 wwPDB (Global Protein Data Bank) に発展しました。 PDBe (ヨーロッパ)、RCSB (米国)、PDBj (日本) などの wwPDB の他のメンバーも、PDB のデータ蓄積、処理、リリースのセンターを提供しています。

PDB データは世界中の科学者によって提出されますが、提出された各データは wwPDB スタッフによってレビューおよび注釈が付けられ、データの妥当性がチェックされることは言及する価値があります。 PDB とそれが提供するソフトウェアは現在、一般に無料で入手できます。
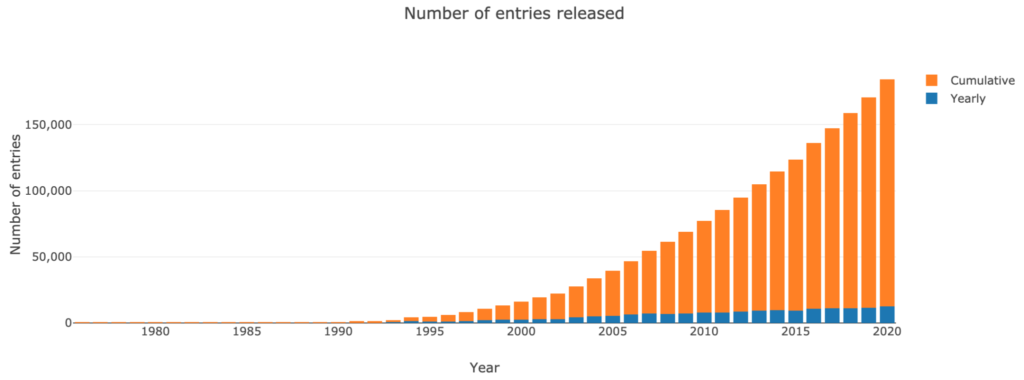
PDB には 140,000 を超える構造があります。
過去数十年にわたり、PDB 構造の数はほぼ指数関数的に増加しました。
- 1982年には100人。
- 1993年には1,000人。
- 1999年には1万人。
- 2014年には10万人。
しかし、新しいタンパク質構造の蓄積速度は 2007 年以降安定しているようです。
世界中の構造生物学者は、X 線結晶構造解析、NMR 分光法、極低温電子顕微鏡などの方法を使用して、分子内の各原子の相対的な位置を決定しています。次に、この構造情報を送信すると、wwPDB によって注釈が付けられ、データベースに公開されます。
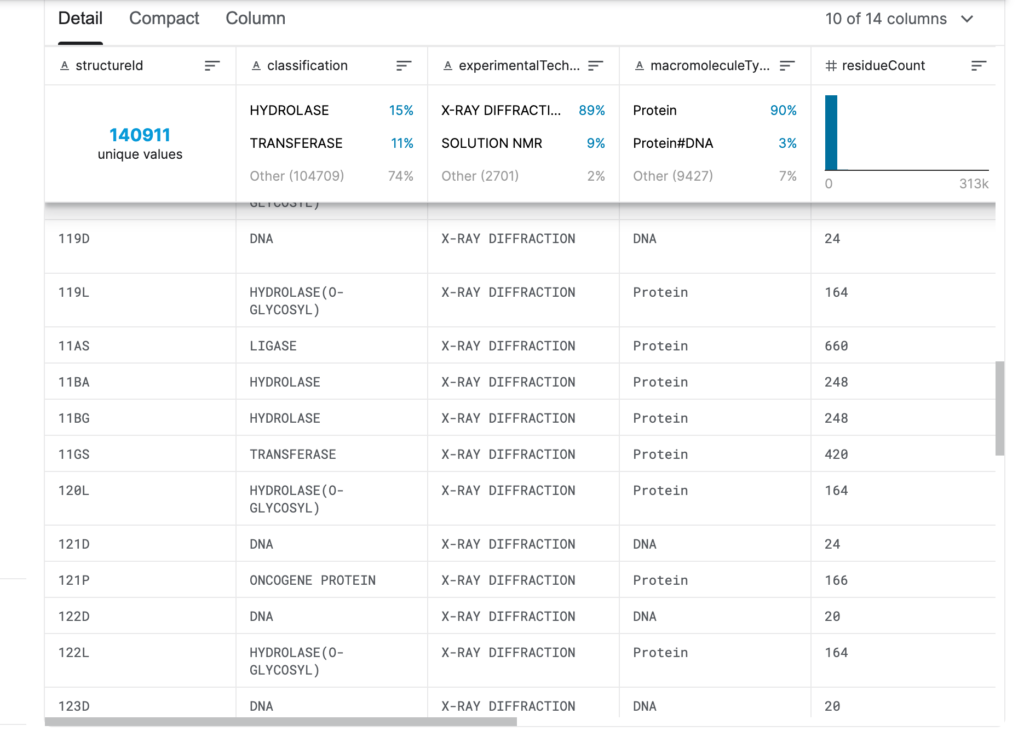
PDB データ セット内のリボソーム、がん遺伝子、薬剤標的、さらにはウイルス全体の構造を検索できます。ただし、PDB にアーカイブされている構造の数は膨大であり、必要な情報を見つけるのは簡単な作業ではありません。
PDB データ セット内の情報には主に次のものが含まれます。タンパク質/核酸の供給源、タンパク質/核酸の分子組成、原子座標、構造を決定するために使用される実験方法、温度因子、構造決定因子、その他のデータと情報。
ダウンロード方法は?
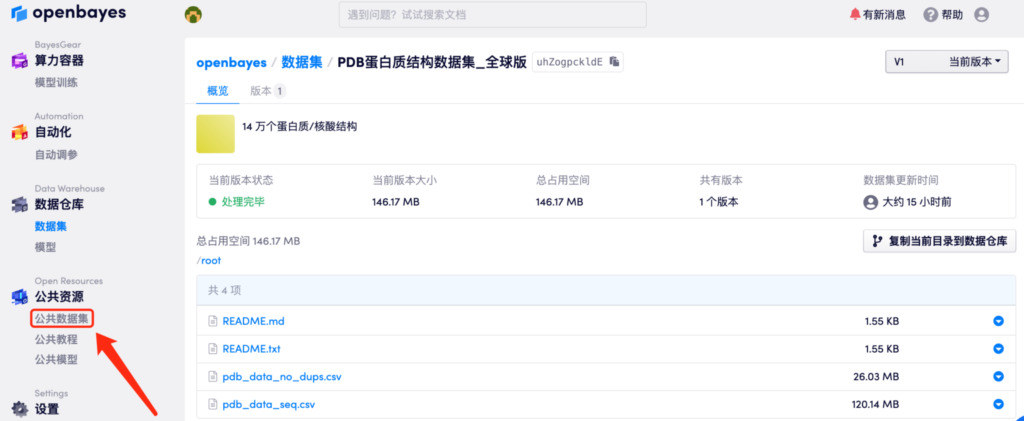
現在、データセットは Super Neural および openbayes.com の公式 Web サイトにオンラインで公開されています。次のサイトにアクセスしてください。https://orion.hyper.ai/datasets/13906 または、「原文を読む」をクリックするとワンクリックでデータセットを取得できます。
■ PDB タンパク質構造データセットの詳細
発売時期:1971年から収集
発行機関:wwPDB
含まれる数量:140,000以上のタンパク質/核酸構造
データ形式:csvファイル
データサイズ:27MB(解凍後は146MB)
ダウンロードアドレス:https://orion.hyper.ai/datasets/13906
あなたも DeepMind から同じデータセットを受け取る価値があります~
使い方は?
私たちのパートナーは、機械学習のためのクラウド コンピューティング能力を提供するクラウド サービスである OpenBayes です。大規模なスーパーコンピューティング クラスターを備えており、GPU クラスター アーキテクチャはマトリックス コンピューティング用に特別に設計されており、AI アプリケーションにコンピューティング パワー コンテナーを提供します。これは開始するのが非常に簡単で、すぐに使用できます。
現在、OpenBayes のコンピューティング パワー コンテナ製品はすでにサポートされています。 TensorFlow、PyTorch、MXNet などの CPU および GPU 環境で。、標準的な機械学習フレームワークのさまざまなバージョンとタイプ、およびさまざまな共通の依存関係。
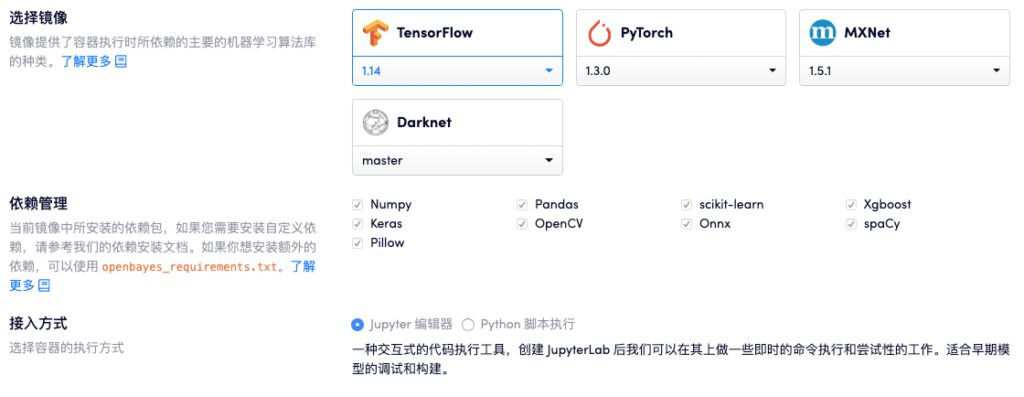
OpenBayes コンピューティング パワー コンテナーで現在サポートされている標準ライブラリそして提供します CPU、NVIDIA T4、NVIDIA Tesla V100、その他のコンピューティング リソース、大規模なデータの集中トレーニングでも、低電力モデルの常駐操作でも、ユーザーのニーズに簡単に対応できます。

CPUからT4、V100まで、豊富なコンピューティングパワーコンテナ構成 オープンベイズのサポートスクリプトのアップロードと JupyterLab エディターオンライン プログラミングとその後のモデル トレーニング。
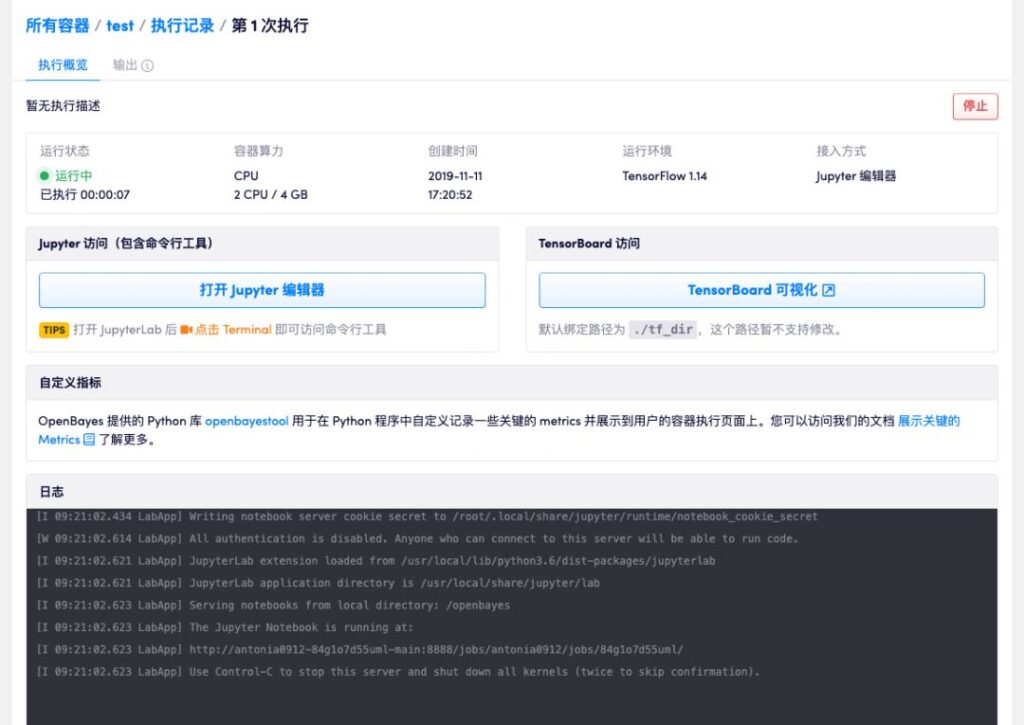
明確かつ簡潔な実行プロセス完全なチュートリアル: https://openbayes.com/docs/quickstart/
新規ユーザーとして登録して、GPU コンピューティングパワーを活用してください
openbayes.com にアクセスしてください、公式ウェブサイトのホームページをクリックしてすぐに登録すると、内部テスト期間中は毎週無料のギフトが提供されるため、クラスメートや同僚とコンピューティング能力を競う必要はもうありません~
活動の説明 openbayes.com にアクセスしてください 招待コード【HyperAI】で新規ユーザー登録楽しむ準備はできています
空きCPU割り当て:300分/週
無料の vGPU クォータ:180分/週
PDB 完全なデータセットの取得:
https://www.rcsb.org/#Category-download
PDB データ セット内のファイルはテキスト エディタで直接表示できますが、公式に推奨されている表示プログラムは Swiss PDB viewer です。
https://spdbv.vital-it.ch/disclaim.html#
その他の参考文献:
https://www.novopro.cn/articles/201912021193.html
- 以上 -








