HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Granary : Jeu de données de reconnaissance et de traduction vocales dans 25 langues européennes

TransLLM : un cadre fondamental unifié multi-tâches pour le transport urbain par une incitation apprenable






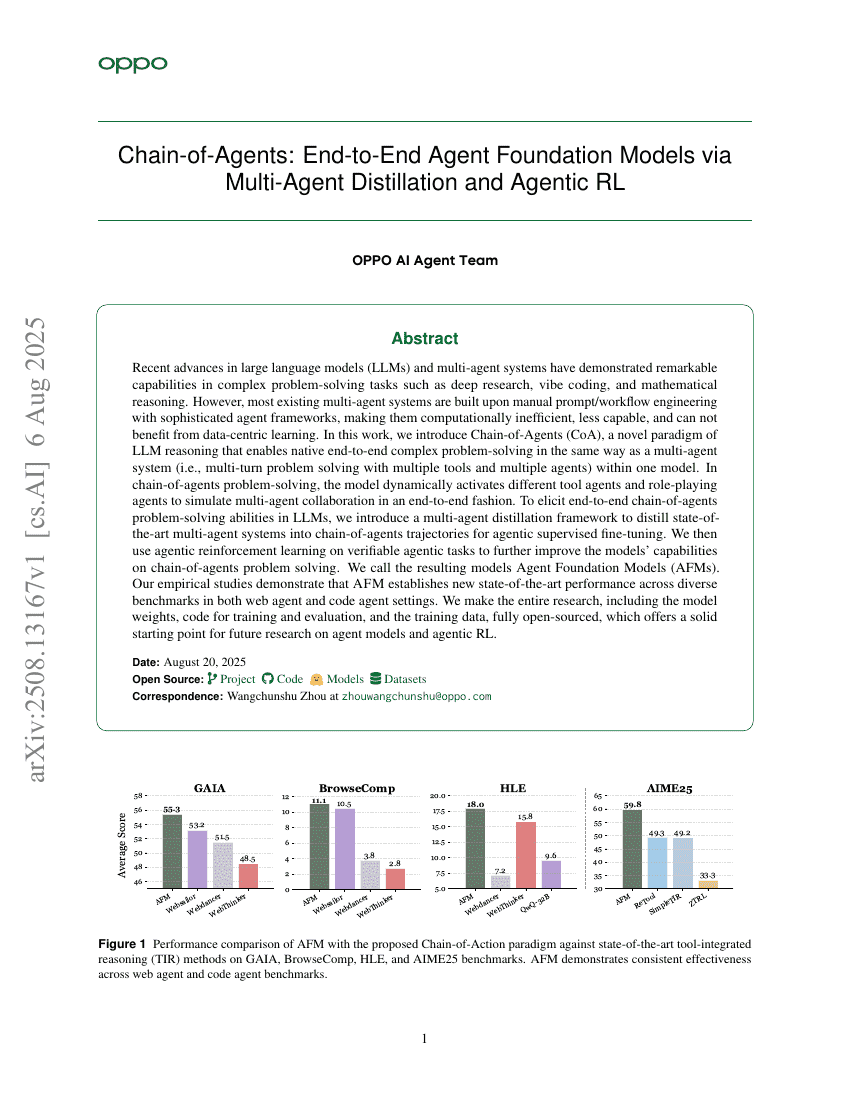

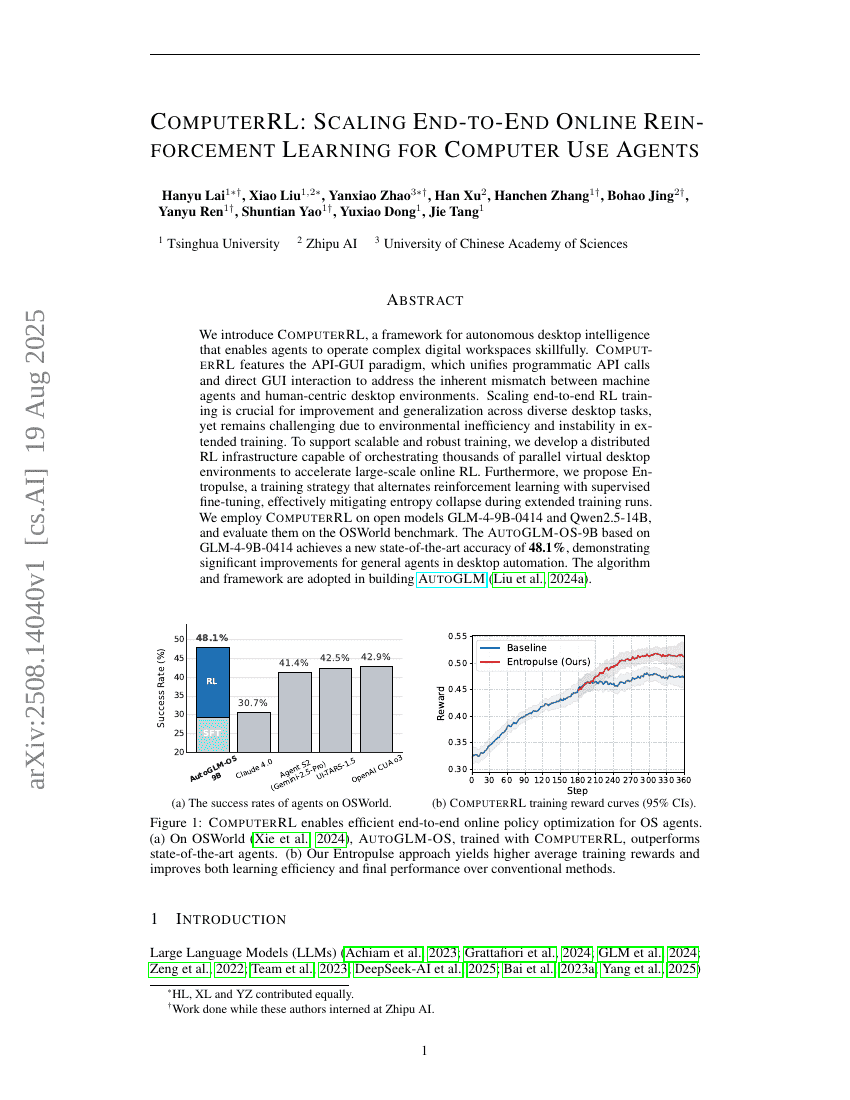








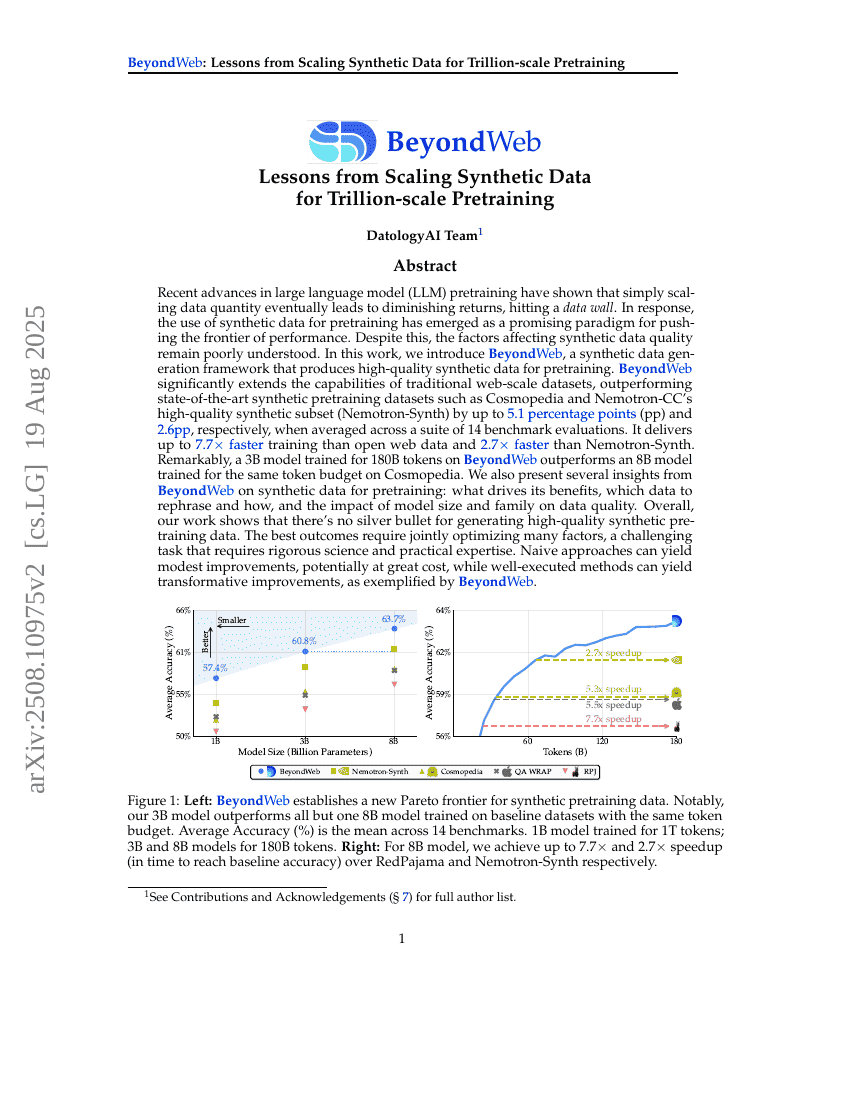



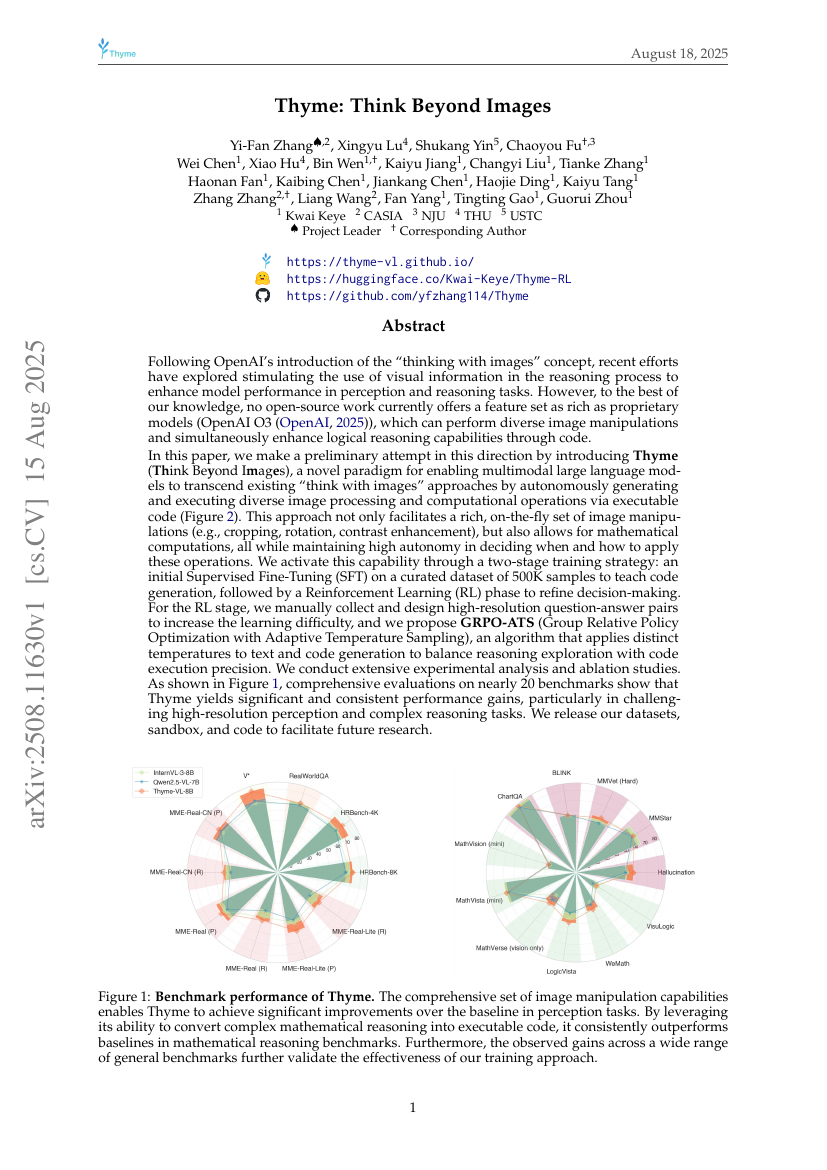






Granary : Jeu de données de reconnaissance et de traduction vocales dans 25 langues européennes
TransLLM : un cadre fondamental unifié multi-tâches pour le transport urbain par une incitation apprenable
La quantification rencontre les dLLMs : une étude systématique de la quantification post-entraînement pour les modèles LLM de diffusion
Édition de couleur guidée par le texte sans entraînement grâce au transformateur de diffusion multimodale
Évaluation des recommandations de podcasts par un jugement de LLM conscient du profil
MultiRef : Génération d'images contrôlable avec plusieurs références visuelles
Langage de balisage d'orchestration de prompt
LongSplat : Éclaboussures 3D gaussiennes robustes non orientées pour des vidéos longues informelles
Chaîne d'agents : Modèles fondamentaux d'agents bout-en-bout par distillation multi-agents et apprentissage par renforcement agissant
HPSv3 : Vers un score de préférence humaine à large spectre
ComputerRL : Piloter l'apprentissage par renforcement en ligne end-to-end à grande échelle pour les agents d'utilisation informatique
Évaluation de la fuite d'identité dans les systèmes de désidentification vocale
Génération suivante de granularité visuelle
4DNeX : Modélisation générative 4D en boucle avant simplifiée
ComoRAG : Un modèle RAG inspiré par le cognition et organisé par la mémoire pour le raisonnement narratif long et étatique
Réseau de neurones micro-ondes intégré pour le calcul et la communication à large bande
GTool : Planification d'outils améliorée par graphe avec un grand modèle linguistique
Observation de la formation de dendrites à l'interface électrode de lithium-électrolyte par un cadre à potentiel constant amélioré par apprentissage automatique
XQuant : franchir le mur de la mémoire pour l'inférence des grands modèles linguistiques grâce à la rématérialisation du cache KV
BeyondWeb : Leçons tirées de l'exploitation de données synthétiques pour l'entraînement préalable à l'échelle du trillion
PaperRegister : Accroître la recherche flexible à granularité fine de documents grâce à l'indexation hiérarchique par registre
DINOv3
SSRL : apprentissage par renforcement par recherche auto-contrôlée
Thym : Pensez au-delà des images
Ancrage des modèles linguistiques multimodaux multilingues par des connaissances culturelles
HiFiTTS-2 : Un ensemble de données vocal large échelle à large bande
CryptoScope : Utilisation de modèles linguistiques à grande échelle pour la détection automatisée des vulnérabilités logiques en cryptographie
Medical Graph RAG : Vers un modèle linguistique massif médical sûr grâce à la génération augmentée par récupération graphique
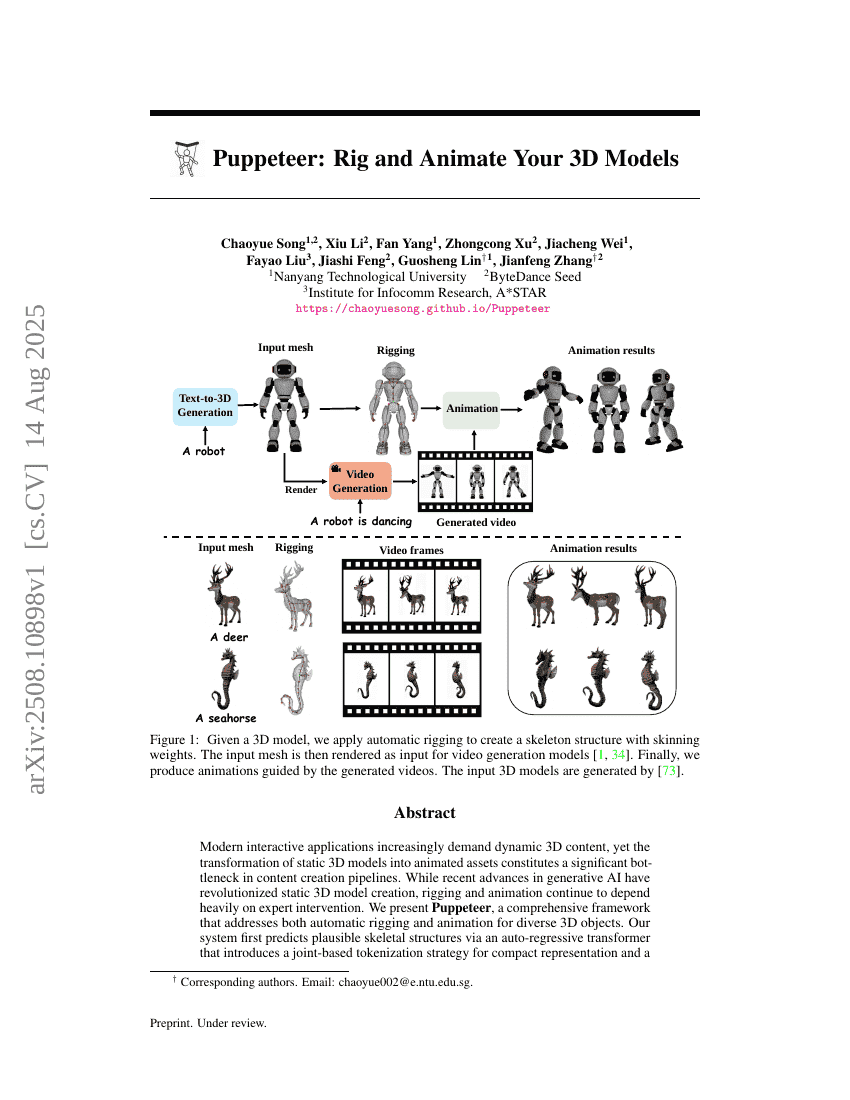
Puppeteer : Animer et contrôler vos modèles 3D
STream3R : Reconstruction 3D séquentielle évolutif avec transformateur causal
PRÉLUDE : Un benchmark conçu pour exiger une compréhension et un raisonnement globaux sur des contextes longs
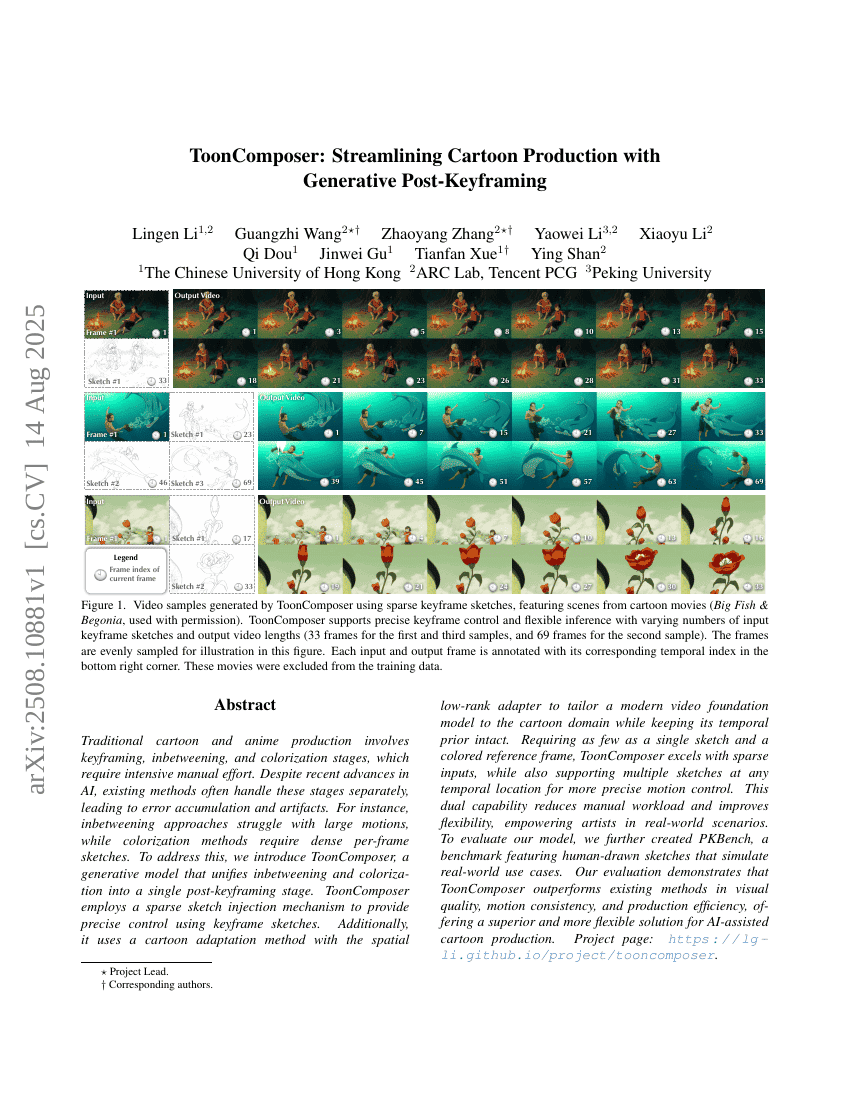
ToonComposer : Simplification de la production de bandes dessinées grâce à la post-création générative de cadrages
La quantification rencontre les dLLMs : une étude systématique de la quantification post-entraînement pour les modèles LLM de diffusion
Édition de couleur guidée par le texte sans entraînement grâce au transformateur de diffusion multimodale
Évaluation des recommandations de podcasts par un jugement de LLM conscient du profil
MultiRef : Génération d'images contrôlable avec plusieurs références visuelles
Langage de balisage d'orchestration de prompt
LongSplat : Éclaboussures 3D gaussiennes robustes non orientées pour des vidéos longues informelles
Chaîne d'agents : Modèles fondamentaux d'agents bout-en-bout par distillation multi-agents et apprentissage par renforcement agissant
HPSv3 : Vers un score de préférence humaine à large spectre
ComputerRL : Piloter l'apprentissage par renforcement en ligne end-to-end à grande échelle pour les agents d'utilisation informatique
Évaluation de la fuite d'identité dans les systèmes de désidentification vocale
Génération suivante de granularité visuelle
4DNeX : Modélisation générative 4D en boucle avant simplifiée
ComoRAG : Un modèle RAG inspiré par le cognition et organisé par la mémoire pour le raisonnement narratif long et étatique
Réseau de neurones micro-ondes intégré pour le calcul et la communication à large bande
GTool : Planification d'outils améliorée par graphe avec un grand modèle linguistique
Observation de la formation de dendrites à l'interface électrode de lithium-électrolyte par un cadre à potentiel constant amélioré par apprentissage automatique
XQuant : franchir le mur de la mémoire pour l'inférence des grands modèles linguistiques grâce à la rématérialisation du cache KV
BeyondWeb : Leçons tirées de l'exploitation de données synthétiques pour l'entraînement préalable à l'échelle du trillion
PaperRegister : Accroître la recherche flexible à granularité fine de documents grâce à l'indexation hiérarchique par registre
DINOv3
SSRL : apprentissage par renforcement par recherche auto-contrôlée
Thym : Pensez au-delà des images
Ancrage des modèles linguistiques multimodaux multilingues par des connaissances culturelles
HiFiTTS-2 : Un ensemble de données vocal large échelle à large bande
CryptoScope : Utilisation de modèles linguistiques à grande échelle pour la détection automatisée des vulnérabilités logiques en cryptographie
Medical Graph RAG : Vers un modèle linguistique massif médical sûr grâce à la génération augmentée par récupération graphique
Puppeteer : Animer et contrôler vos modèles 3D
STream3R : Reconstruction 3D séquentielle évolutif avec transformateur causal
PRÉLUDE : Un benchmark conçu pour exiger une compréhension et un raisonnement globaux sur des contextes longs
ToonComposer : Simplification de la production de bandes dessinées grâce à la post-création générative de cadrages