HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Voir, écouter, se souvenir et raisonner : un agent multimodal doté d'une mémoire à long terme

Les LLMs à diffusion peuvent effectuer une inférence plus rapide que l'AR grâce à la contrainte de diffusion discrète


























Voir, écouter, se souvenir et raisonner : un agent multimodal doté d'une mémoire à long terme
Les LLMs à diffusion peuvent effectuer une inférence plus rapide que l'AR grâce à la contrainte de diffusion discrète
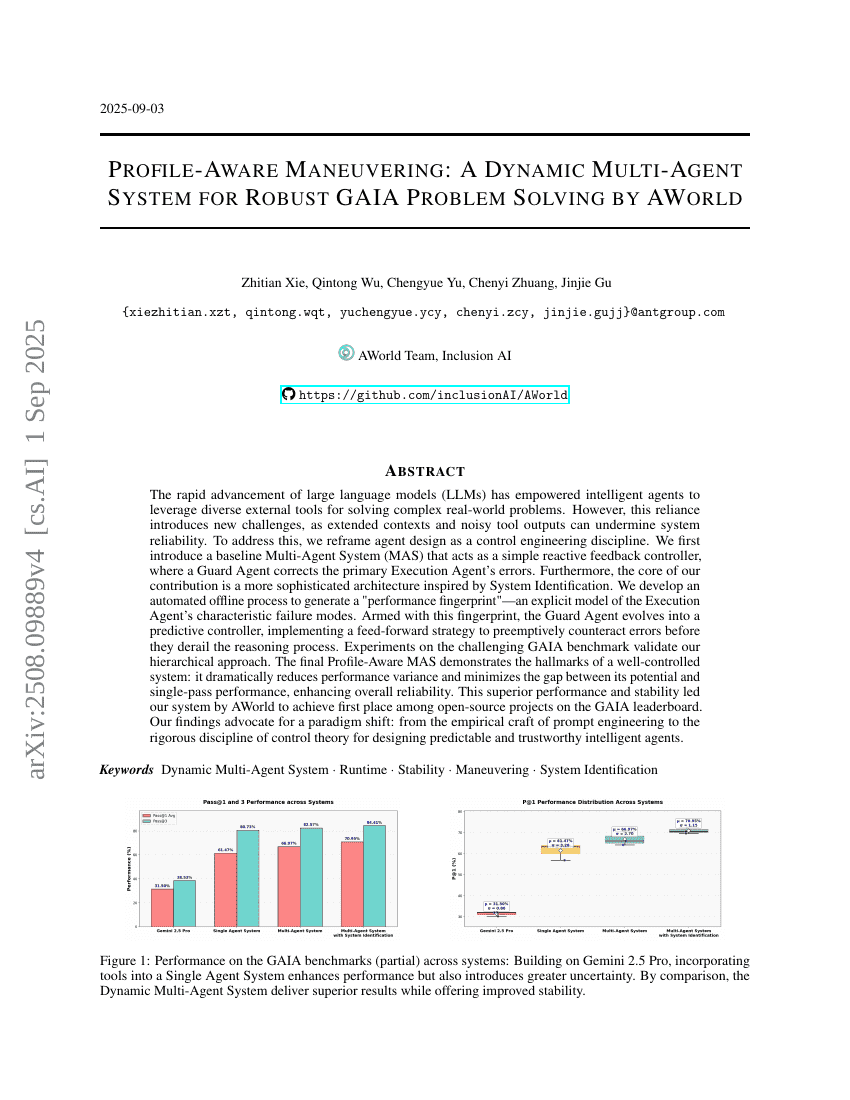
AWorld : Système multi-agents dynamique avec manœuvrabilité stable pour une résolution robuste du problème GAIA
Story2Board : Une approche sans entraînement pour la génération expressive de storyboards
Stand-In : un contrôle d'identité léger et plug-and-play pour la génération vidéo
Mol-R1 : Vers un raisonnement Long-CoT explicite dans la découverte de molécules
Llama-Nemotron : modèles de raisonnement efficaces
Document Haystack : un benchmark vision LLM multimodal pour la compréhension de documents à longue portée
Echo-4o : Exploiter la puissance des images synthétiques GPT-4o pour améliorer la génération d'images
Coloration virtuelle de tissus sans marqueur dans la spectrométrie de masse par imagerie
VisCodex : Génération multimodale de code unifiée par fusion de modèles visuels et de codage
HierSearch : un cadre de recherche profonde hiérarchique pour les entreprises intégrant les recherches locales et web
Le temps est une caractéristique : exploitation des dynamiques temporelles dans les modèles linguistiques à diffusion
CharacterShot : Animation 4D contrôlable et cohérente de personnages
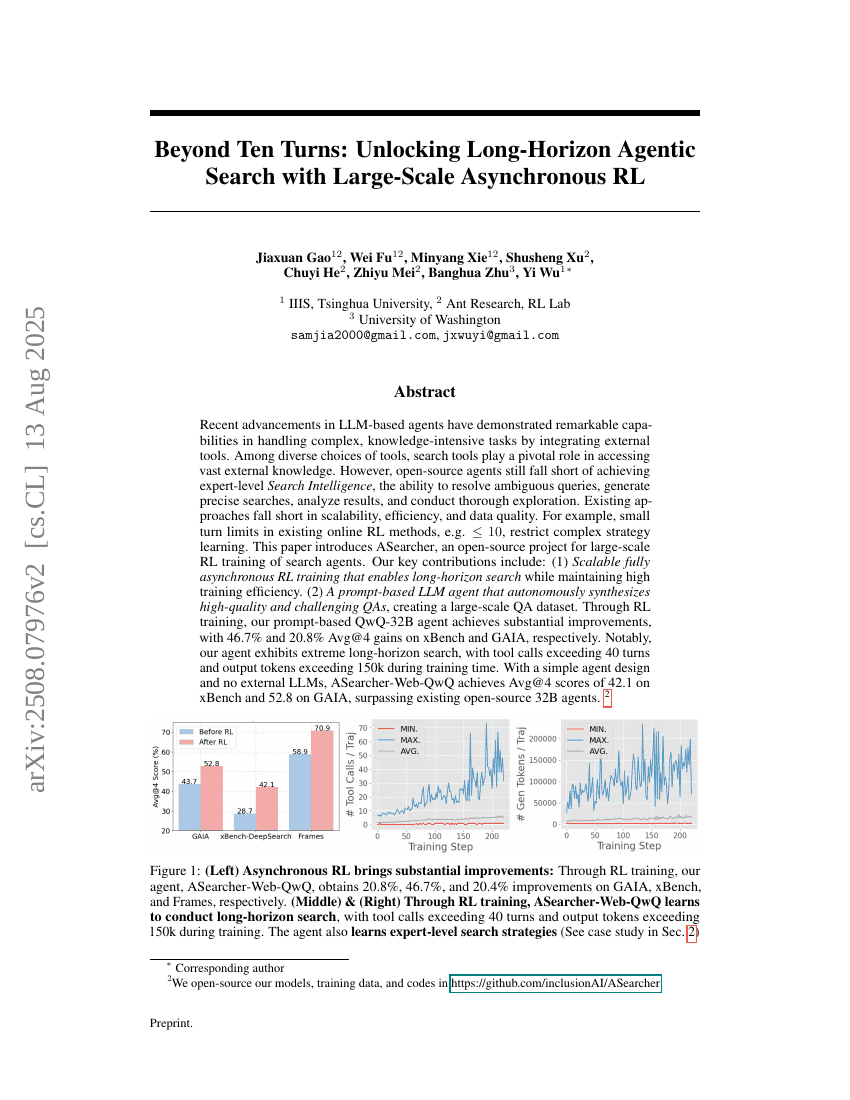
Au-delà de dix tours : déverrouiller la recherche agente à long terme grâce à un apprentissage par renforcement asynchrone à grande échelle
Matrix-3D : Génération de mondes 3D omnidirectionnels explorables
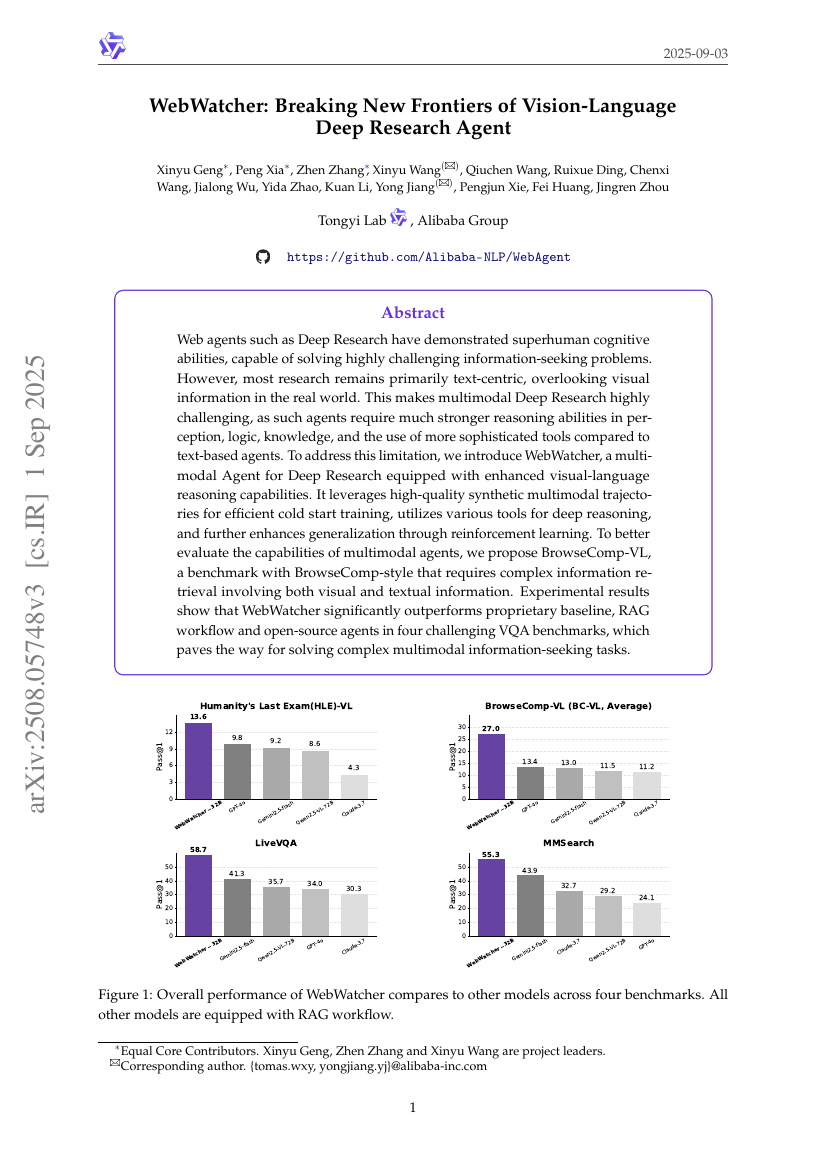
WebWatcher : Ouvrir de nouveaux horizons pour l'agent de recherche profonde vision-langage
Rapport technique Marco-Voice
Aperçu de Kimina-Prover : Vers de grands modèles de raisonnement formel par apprentissage par renforcement
PyVeritas : Vérification de Python par transpilation basée sur les LLM et vérification bornée de modèles pour C
Agents de mémoire intrinsèque : systèmes multi-agents LLM hétérogènes par le biais d'une mémoire contextuelle structurée
Conception d’éditeurs génomiques hautement fonctionnels par modélisation des séquences CRISPR-Cas
UserBench : un environnement d'entraînement interactif pour des agents centrés sur l'utilisateur
SONAR-LLM : Transformer autoregressive qui pense en embeddings de phrases et parle en tokens
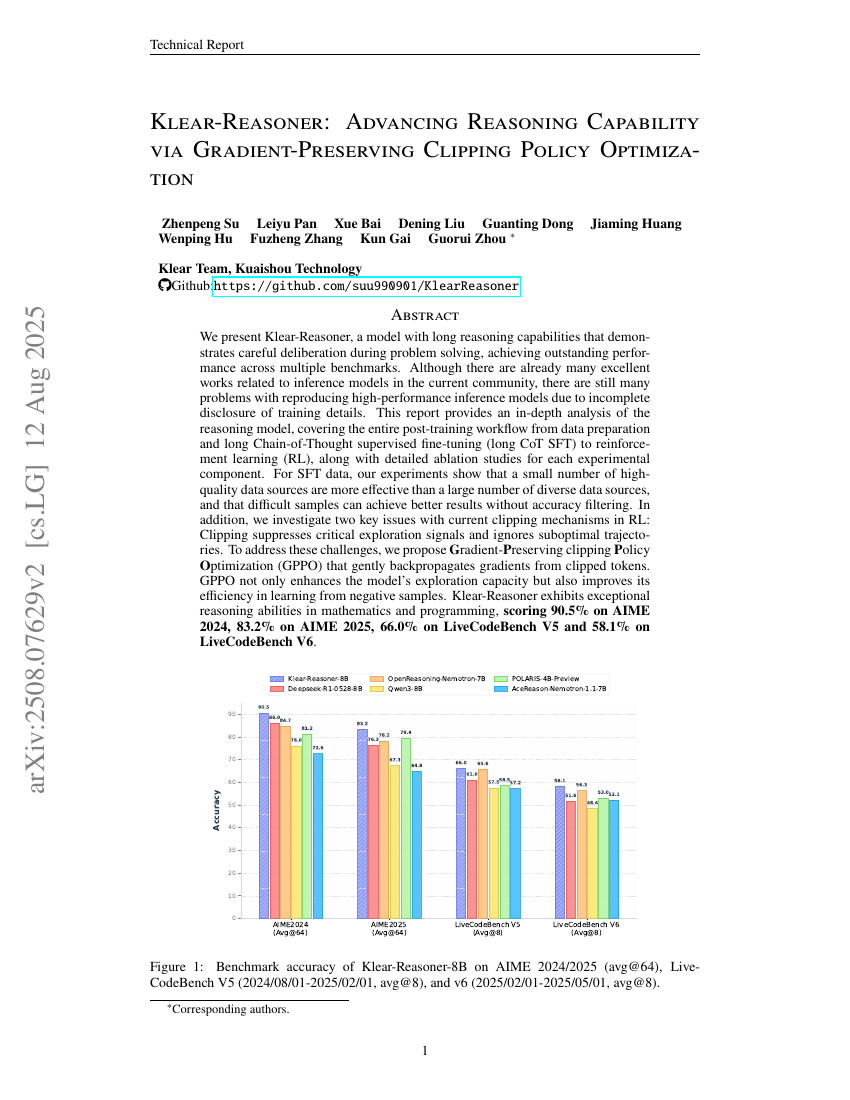
Klear-Reasoner : Progresser dans la capacité de raisonnement grâce à l'optimisation de la politique de découpage préserver le gradient
Omni-Effects : Génération unifiée et contrôlable spatialement d'effets visuels
WideSearch : Benchmarking de l'information large et agente
ReasonRank : Renforcer le classement des passages grâce à une forte capacité de raisonnement
AdaptFlow : Optimisation adaptative des flux de travail par méta-apprentissage
Collaboration multi-agents guidée par un médiateur entre modèles open-source pour la prise de décision médicale
Adaptation des modèles vision-langage sans étiquettes : une revue complète
GENIE : Encodage Gaussien pour l'Édition Interactive des Champs de Radiance Neuronaux
AWorld : Système multi-agents dynamique avec manœuvrabilité stable pour une résolution robuste du problème GAIA
Story2Board : Une approche sans entraînement pour la génération expressive de storyboards
Stand-In : un contrôle d'identité léger et plug-and-play pour la génération vidéo
Mol-R1 : Vers un raisonnement Long-CoT explicite dans la découverte de molécules
Llama-Nemotron : modèles de raisonnement efficaces
Document Haystack : un benchmark vision LLM multimodal pour la compréhension de documents à longue portée
Echo-4o : Exploiter la puissance des images synthétiques GPT-4o pour améliorer la génération d'images
Coloration virtuelle de tissus sans marqueur dans la spectrométrie de masse par imagerie
VisCodex : Génération multimodale de code unifiée par fusion de modèles visuels et de codage
HierSearch : un cadre de recherche profonde hiérarchique pour les entreprises intégrant les recherches locales et web
Le temps est une caractéristique : exploitation des dynamiques temporelles dans les modèles linguistiques à diffusion
CharacterShot : Animation 4D contrôlable et cohérente de personnages
Au-delà de dix tours : déverrouiller la recherche agente à long terme grâce à un apprentissage par renforcement asynchrone à grande échelle
Matrix-3D : Génération de mondes 3D omnidirectionnels explorables
WebWatcher : Ouvrir de nouveaux horizons pour l'agent de recherche profonde vision-langage
Rapport technique Marco-Voice
Aperçu de Kimina-Prover : Vers de grands modèles de raisonnement formel par apprentissage par renforcement
PyVeritas : Vérification de Python par transpilation basée sur les LLM et vérification bornée de modèles pour C
Agents de mémoire intrinsèque : systèmes multi-agents LLM hétérogènes par le biais d'une mémoire contextuelle structurée
Conception d’éditeurs génomiques hautement fonctionnels par modélisation des séquences CRISPR-Cas
UserBench : un environnement d'entraînement interactif pour des agents centrés sur l'utilisateur
SONAR-LLM : Transformer autoregressive qui pense en embeddings de phrases et parle en tokens
Klear-Reasoner : Progresser dans la capacité de raisonnement grâce à l'optimisation de la politique de découpage préserver le gradient
Omni-Effects : Génération unifiée et contrôlable spatialement d'effets visuels
WideSearch : Benchmarking de l'information large et agente
ReasonRank : Renforcer le classement des passages grâce à une forte capacité de raisonnement
AdaptFlow : Optimisation adaptative des flux de travail par méta-apprentissage
Collaboration multi-agents guidée par un médiateur entre modèles open-source pour la prise de décision médicale
Adaptation des modèles vision-langage sans étiquettes : une revue complète
GENIE : Encodage Gaussien pour l'Édition Interactive des Champs de Radiance Neuronaux