HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Robix : un modèle unifié pour l'interaction, le raisonnement et la planification robotiques

Test d’intrusion des modèles linguistiques pour réduire les préjudices : méthodes, comportements d’échelle et leçons tirées




























Robix : un modèle unifié pour l'interaction, le raisonnement et la planification robotiques
Test d’intrusion des modèles linguistiques pour réduire les préjudices : méthodes, comportements d’échelle et leçons tirées
FusionProt : Fusionner les informations séquentielles et structurales pour un apprentissage unifié de la représentation des protéines
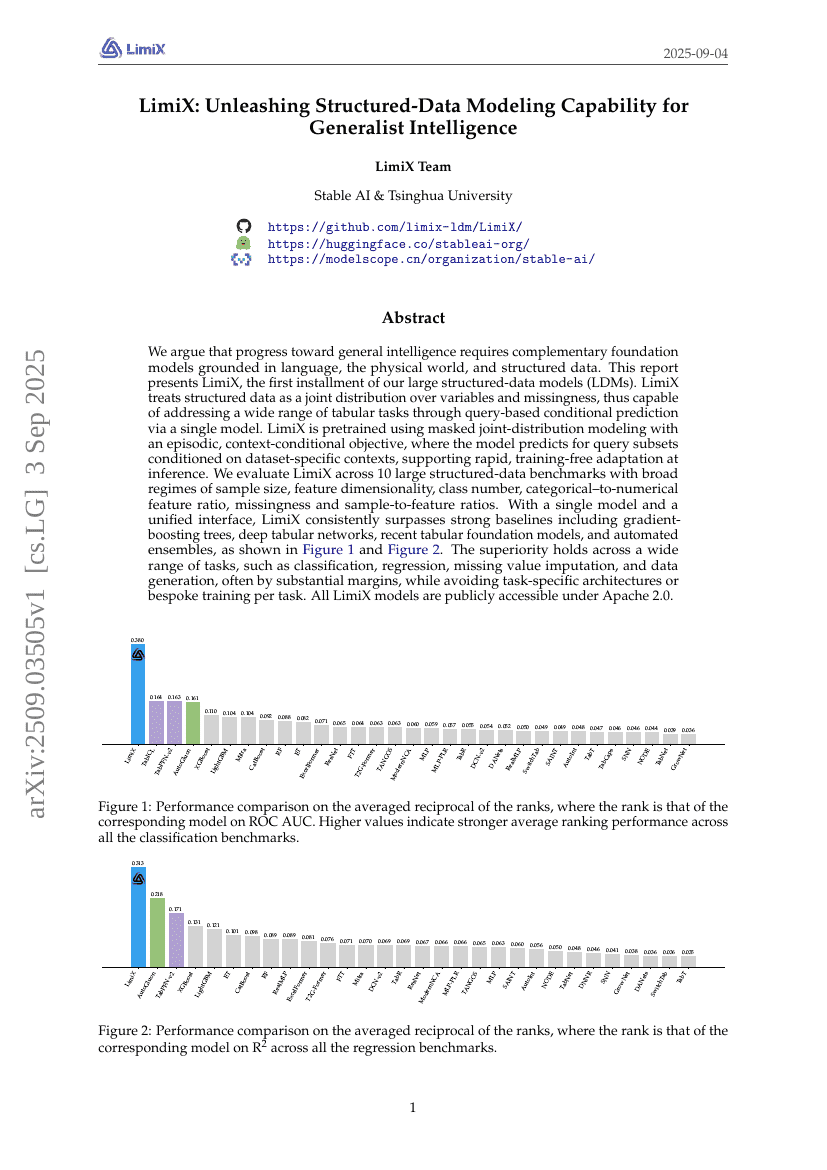
LimiX : Libérer le potentiel de modélisation des données structurées pour une intelligence généraliste
epiGPTope : un générateur et classificateur d’épitopes basé sur l’apprentissage automatique
GenCompositor : composition vidéo générative avec Transformer à diffusion
DCPO : Optimisation dynamique de la politique de découpage
Vecteurs de raisonnement : Transfert de capacités de chaîne de raisonnement par arithmétique de tâches
Baichuan-M2 : Augmenter les capacités médicales grâce à un système de vérification à grande échelle
VerlTool : Vers un apprentissage par renforcement agissant holistique intégrant l'utilisation d'outils
ELV-Halluc : Évaluation des hallucinations d'agrégation sémantique dans la compréhension des vidéos longues
MedChatZH : un meilleur conseiller médical apprend des instructions meilleures
AlphaEarth Foundations : un modèle de champ d'encodage pour une cartographie mondiale précise et efficace à partir de données étiquetées éparses
AetherCode : Évaluation de la capacité des MLN à remporter des compétitions de programmation de premier plan
TileLang : Un modèle de programmation par tuiles composables pour les systèmes d'IA
DeepSeek-R1 Thoughtology : Réfléchissons au raisonnement des LLM
Intégration multi-ontologie avec propagation à deux axes pour la représentation des concepts médicaux
Détection automatisée de problèmes cliniques à partir de notes SOAP à l’aide d’une architecture collaborative à agents multiples basée sur un LLM
SmolDocling : un modèle vision-langage ultra-compact pour la conversion multimodale en bout-en-bout de documents
olmOCR : Déverrouiller des trillions de tokens dans les fichiers PDF à l'aide de modèles vision-langage
VA-MoE : Mélange de Experts Adaptatif aux Variables pour la Prévision Climatique Incrementale
HuatuoGPT-Vision, vers l'intégration à grande échelle de connaissances visuelles médicales dans les modèles linguistiques multimodaux
Comment la reformulation d'entrée peut-elle améliorer la précision de l'utilisation des outils dans un environnement dynamique complexe ? Une étude sur τ-bench
Évaluation au niveau de l'interface utilisateur de ALLaM 34B : Mesure d'un LLM centré sur l'arabe à l'aide de HUMAIN Chat
Du réactif au cognitif : une intelligence spatiale inspirée du cerveau pour les agents incarnés
Aucune étiquette laissée pour compte : un modèle unifié de détection de défauts de surface pour tous les régimes de supervision
T2R-bench : Un benchmark pour la génération de rapports au niveau des articles à partir de tableaux industriels du monde réel
PVPO : Optimisation de politique basée sur la valeur pré-estimée pour le raisonnement agissant
Entraînement d’un assistant utile et sans danger par apprentissage par renforcement à partir de feedback humain
UQ : Évaluation des modèles de langage sur des questions non résolues
CARJAN : Génération et simulation de scénarios de trafic basées sur des agents avec AJAN
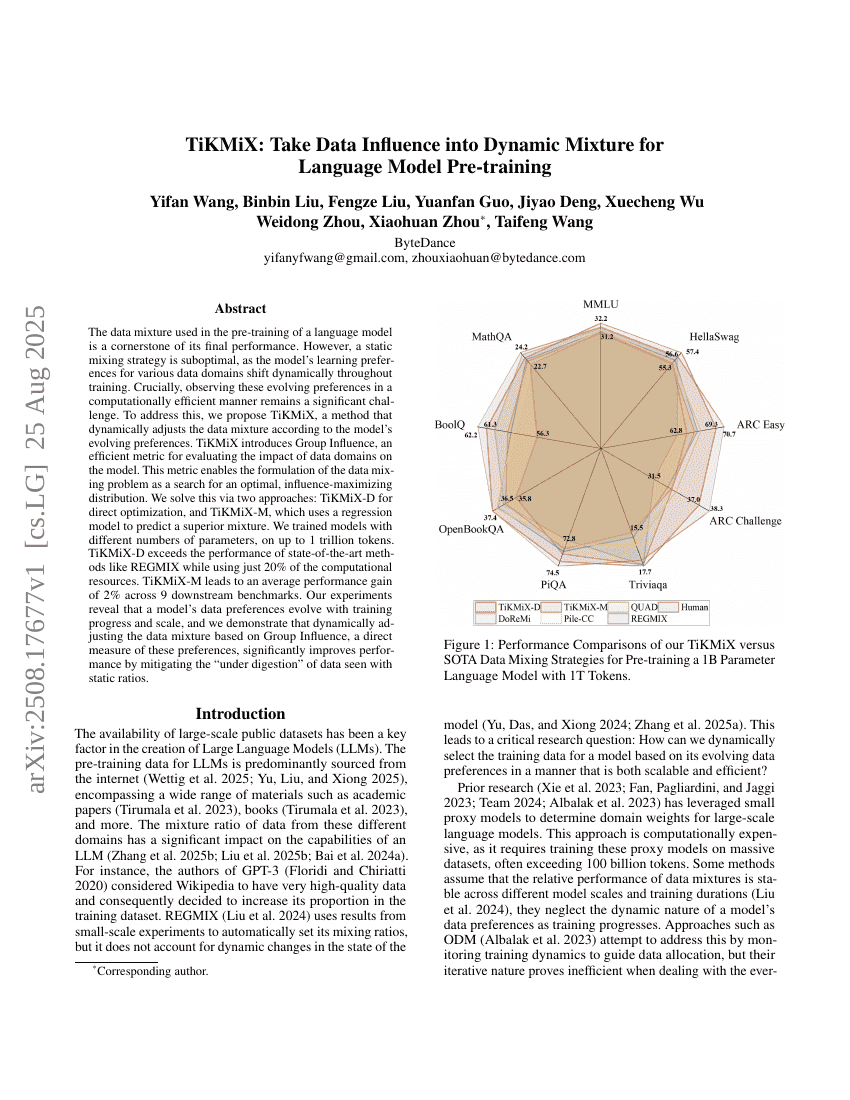
TiKMiX : Intégrer l'influence des données dans un mélange dynamique pour l'entraînement préalable des modèles linguistiques
FusionProt : Fusionner les informations séquentielles et structurales pour un apprentissage unifié de la représentation des protéines
LimiX : Libérer le potentiel de modélisation des données structurées pour une intelligence généraliste
epiGPTope : un générateur et classificateur d’épitopes basé sur l’apprentissage automatique
GenCompositor : composition vidéo générative avec Transformer à diffusion
DCPO : Optimisation dynamique de la politique de découpage
Vecteurs de raisonnement : Transfert de capacités de chaîne de raisonnement par arithmétique de tâches
Baichuan-M2 : Augmenter les capacités médicales grâce à un système de vérification à grande échelle
VerlTool : Vers un apprentissage par renforcement agissant holistique intégrant l'utilisation d'outils
ELV-Halluc : Évaluation des hallucinations d'agrégation sémantique dans la compréhension des vidéos longues
MedChatZH : un meilleur conseiller médical apprend des instructions meilleures
AlphaEarth Foundations : un modèle de champ d'encodage pour une cartographie mondiale précise et efficace à partir de données étiquetées éparses
AetherCode : Évaluation de la capacité des MLN à remporter des compétitions de programmation de premier plan
TileLang : Un modèle de programmation par tuiles composables pour les systèmes d'IA
DeepSeek-R1 Thoughtology : Réfléchissons au raisonnement des LLM
Intégration multi-ontologie avec propagation à deux axes pour la représentation des concepts médicaux
Détection automatisée de problèmes cliniques à partir de notes SOAP à l’aide d’une architecture collaborative à agents multiples basée sur un LLM
SmolDocling : un modèle vision-langage ultra-compact pour la conversion multimodale en bout-en-bout de documents
olmOCR : Déverrouiller des trillions de tokens dans les fichiers PDF à l'aide de modèles vision-langage
VA-MoE : Mélange de Experts Adaptatif aux Variables pour la Prévision Climatique Incrementale
HuatuoGPT-Vision, vers l'intégration à grande échelle de connaissances visuelles médicales dans les modèles linguistiques multimodaux
Comment la reformulation d'entrée peut-elle améliorer la précision de l'utilisation des outils dans un environnement dynamique complexe ? Une étude sur τ-bench
Évaluation au niveau de l'interface utilisateur de ALLaM 34B : Mesure d'un LLM centré sur l'arabe à l'aide de HUMAIN Chat
Du réactif au cognitif : une intelligence spatiale inspirée du cerveau pour les agents incarnés
Aucune étiquette laissée pour compte : un modèle unifié de détection de défauts de surface pour tous les régimes de supervision
T2R-bench : Un benchmark pour la génération de rapports au niveau des articles à partir de tableaux industriels du monde réel
PVPO : Optimisation de politique basée sur la valeur pré-estimée pour le raisonnement agissant
Entraînement d’un assistant utile et sans danger par apprentissage par renforcement à partir de feedback humain
UQ : Évaluation des modèles de langage sur des questions non résolues
CARJAN : Génération et simulation de scénarios de trafic basées sur des agents avec AJAN
TiKMiX : Intégrer l'influence des données dans un mélange dynamique pour l'entraînement préalable des modèles linguistiques