HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Élagage des prévisibles : raisonnement efficace sur le code via la surprise du premier jeton

Voost : un transformateur de diffusion unifié et évolutif pour l’essayage virtuel bidirectionnel et le retrait virtuel




























Élagage des prévisibles : raisonnement efficace sur le code via la surprise du premier jeton
Voost : un transformateur de diffusion unifié et évolutif pour l’essayage virtuel bidirectionnel et le retrait virtuel
InfiGUI-G1 : Progresser dans l'annotation des interfaces graphiques utilisateur grâce à l'optimisation d'une politique d'exploration adaptative
Memp : Exploration de la mémoire procédurale des agents
Perch 2.0 : La leçon du bécassine pour la bioacoustique
Sommes-nous sur la bonne voie pour évaluer la génération de documents augmentée par récupération ?
Hi3DEval : Progresser dans l’évaluation de la génération 3D grâce à une validité hiérarchique
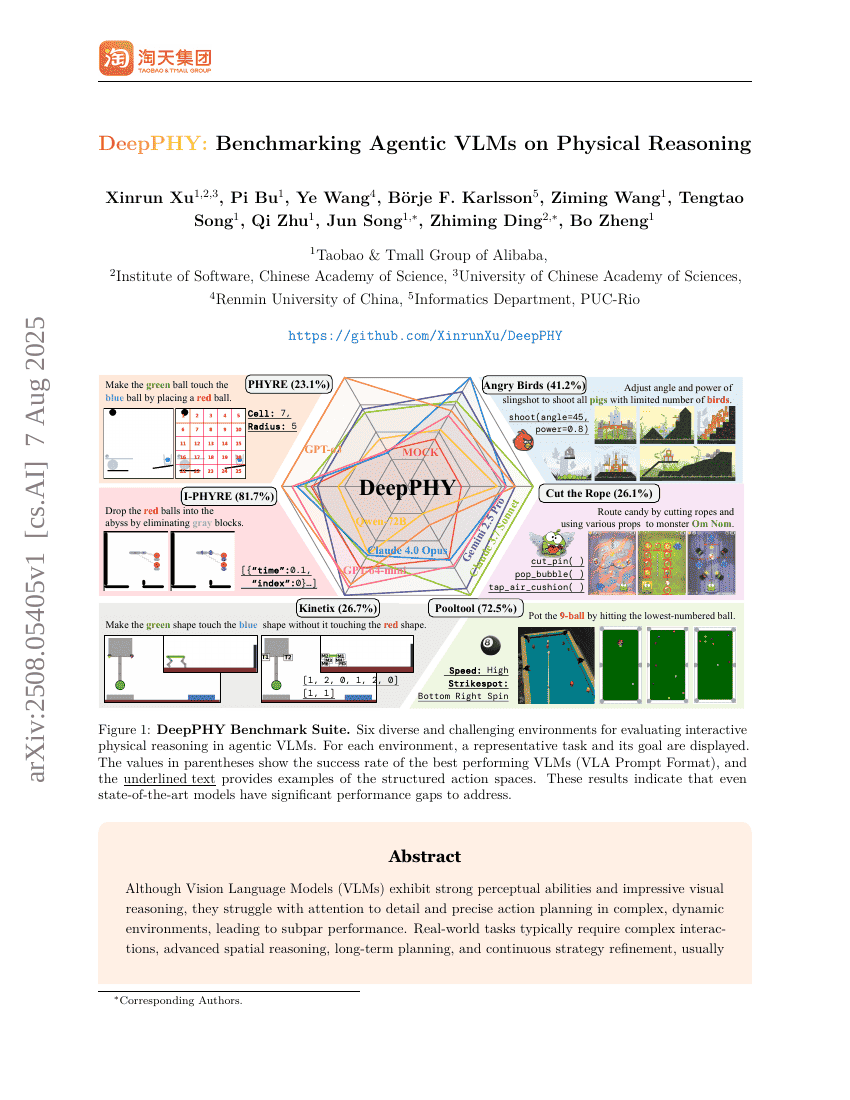
DeepPHY : Évaluation des VLM agents sur le raisonnement physique
Genie Envisioner : une plateforme fondamentale unifiée du monde pour la manipulation robotique
R-Zéro : un modèle LLM de raisonnement auto-évoluant à partir de zéro donnée
Sur la généralisation de SFT : une perspective d'apprentissage par renforcement avec rectification de récompense
Simuler des dynamiques d'apprentissage humain avec des agents autonomes alimentés par des grands modèles linguistiques
GRAIL : Apprendre à interagir avec de grands graphes de connaissances pour un raisonnement augmenté par la récupération
CoTox : Raisonnement et prédiction de la toxicité moléculaire fondés sur la chaîne de raisonnement
Agents efficaces : Construire des agents performants tout en réduisant les coûts
Le raisonnement en chaîne des LLM est-il une illusion ? Une perspective fondée sur la distribution des données
VeriGUI : Jeu de données Verifiable Long-Chain GUI
Rapport technique Qwen2.5-VL
Le GAN est mort ; vive le GAN ! Une base moderne pour les GAN
MegaPairs : synthèse de données massives pour la recherche multimodale universelle
Lyra : Un cadre efficace et centré sur la parole pour l'omnicognition
Élargir les limites de performance des modèles multimodaux open source par une mise à l'échelle du modèle, des données et du test
NVILA : Modèles linguistiques visuels pour les frontières efficaces
VisionZip : Plus long est meilleur, mais pas nécessaire dans les modèles vision-langage
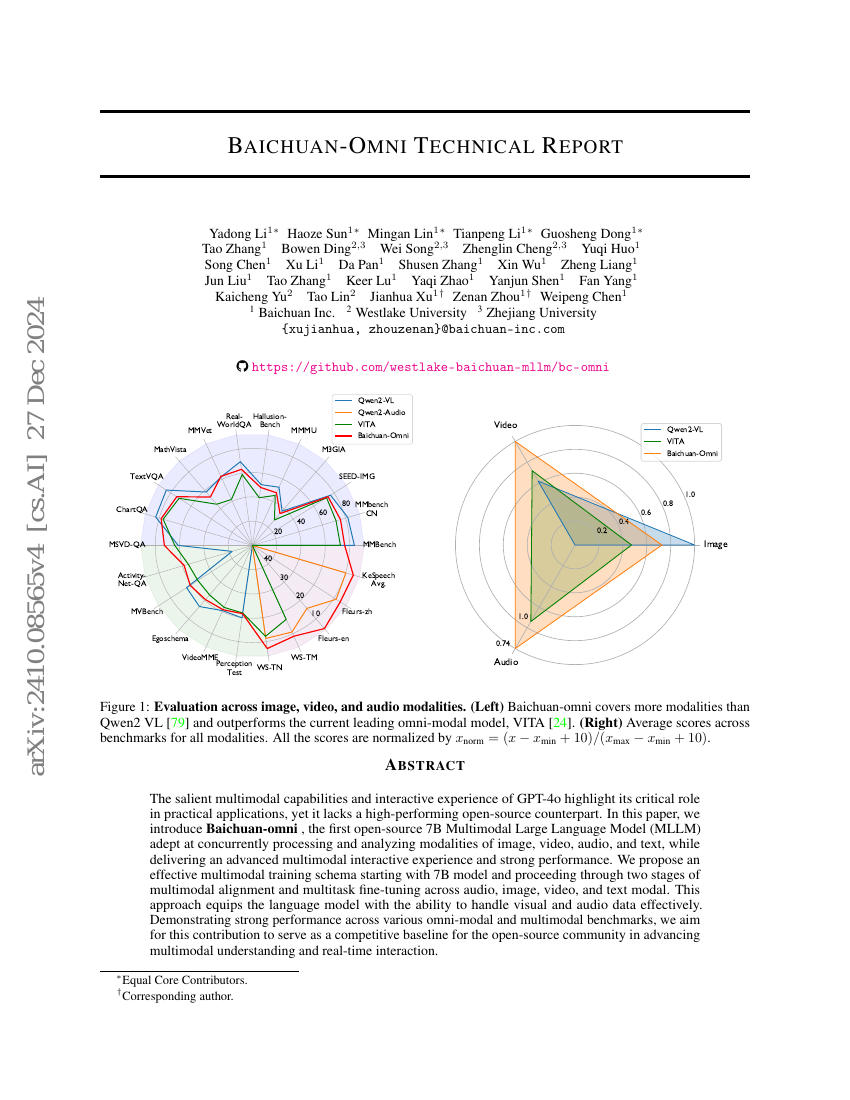
Rapport technique Baichuan-Omni
MM1.5 : Méthodes, analyse et enseignements tirés de l'ajustement fin des modèles linguistiques multimodaux
Emu3 : Prédire le prochain jeton, c'est tout ce dont vous avez besoin
CogVLM2 : Modèles de langage visuel pour la compréhension d'images et de vidéos
Rapport technique Qwen2
Une image vaut 32 jetons pour la reconstruction et la génération
Modèle autorégressif bat la diffusion : Llama pour une génération d’images évolutif
Meteor : Exploration basée sur Mamba des justifications pour les grands modèles linguistiques et visuels
InfiGUI-G1 : Progresser dans l'annotation des interfaces graphiques utilisateur grâce à l'optimisation d'une politique d'exploration adaptative
Memp : Exploration de la mémoire procédurale des agents
Perch 2.0 : La leçon du bécassine pour la bioacoustique
Sommes-nous sur la bonne voie pour évaluer la génération de documents augmentée par récupération ?
Hi3DEval : Progresser dans l’évaluation de la génération 3D grâce à une validité hiérarchique
DeepPHY : Évaluation des VLM agents sur le raisonnement physique
Genie Envisioner : une plateforme fondamentale unifiée du monde pour la manipulation robotique
R-Zéro : un modèle LLM de raisonnement auto-évoluant à partir de zéro donnée
Sur la généralisation de SFT : une perspective d'apprentissage par renforcement avec rectification de récompense
Simuler des dynamiques d'apprentissage humain avec des agents autonomes alimentés par des grands modèles linguistiques
GRAIL : Apprendre à interagir avec de grands graphes de connaissances pour un raisonnement augmenté par la récupération
CoTox : Raisonnement et prédiction de la toxicité moléculaire fondés sur la chaîne de raisonnement
Agents efficaces : Construire des agents performants tout en réduisant les coûts
Le raisonnement en chaîne des LLM est-il une illusion ? Une perspective fondée sur la distribution des données
VeriGUI : Jeu de données Verifiable Long-Chain GUI
Rapport technique Qwen2.5-VL
Le GAN est mort ; vive le GAN ! Une base moderne pour les GAN
MegaPairs : synthèse de données massives pour la recherche multimodale universelle
Lyra : Un cadre efficace et centré sur la parole pour l'omnicognition
Élargir les limites de performance des modèles multimodaux open source par une mise à l'échelle du modèle, des données et du test
NVILA : Modèles linguistiques visuels pour les frontières efficaces
VisionZip : Plus long est meilleur, mais pas nécessaire dans les modèles vision-langage
Rapport technique Baichuan-Omni
MM1.5 : Méthodes, analyse et enseignements tirés de l'ajustement fin des modèles linguistiques multimodaux
Emu3 : Prédire le prochain jeton, c'est tout ce dont vous avez besoin
CogVLM2 : Modèles de langage visuel pour la compréhension d'images et de vidéos
Rapport technique Qwen2
Une image vaut 32 jetons pour la reconstruction et la génération
Modèle autorégressif bat la diffusion : Llama pour une génération d’images évolutif
Meteor : Exploration basée sur Mamba des justifications pour les grands modèles linguistiques et visuels