HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

SAM 3D : 3Disez n'importe quoi dans les images

Video-as-Answer : Prédire et Générer l'Événement Vidéo Suivant avec Joint-GRPO

























SAM 3D : 3Disez n'importe quoi dans les images
Video-as-Answer : Prédire et Générer l'Événement Vidéo Suivant avec Joint-GRPO
Le premier cadre est la place à aller pour la personnalisation du contenu vidéo
L’extension de l’intelligence spatiale grâce aux modèles fondamentaux multimodaux
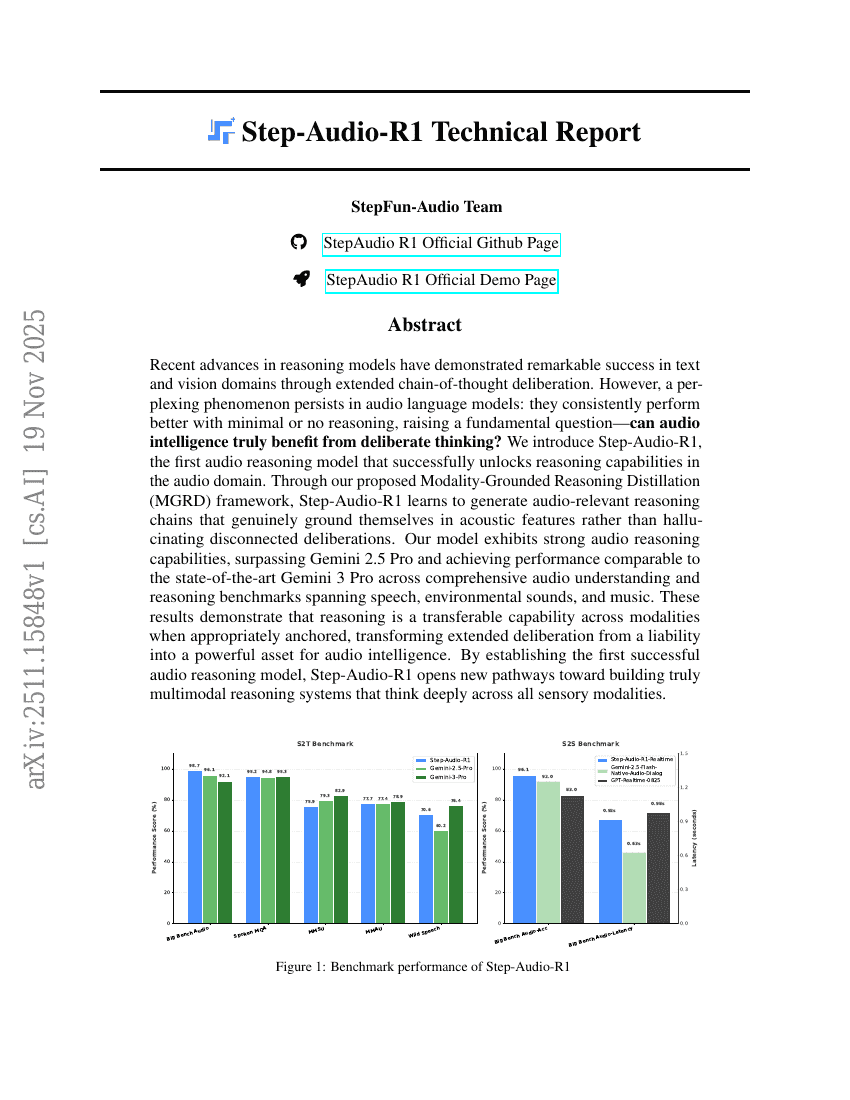
Rapport technique Step-Audio-R1
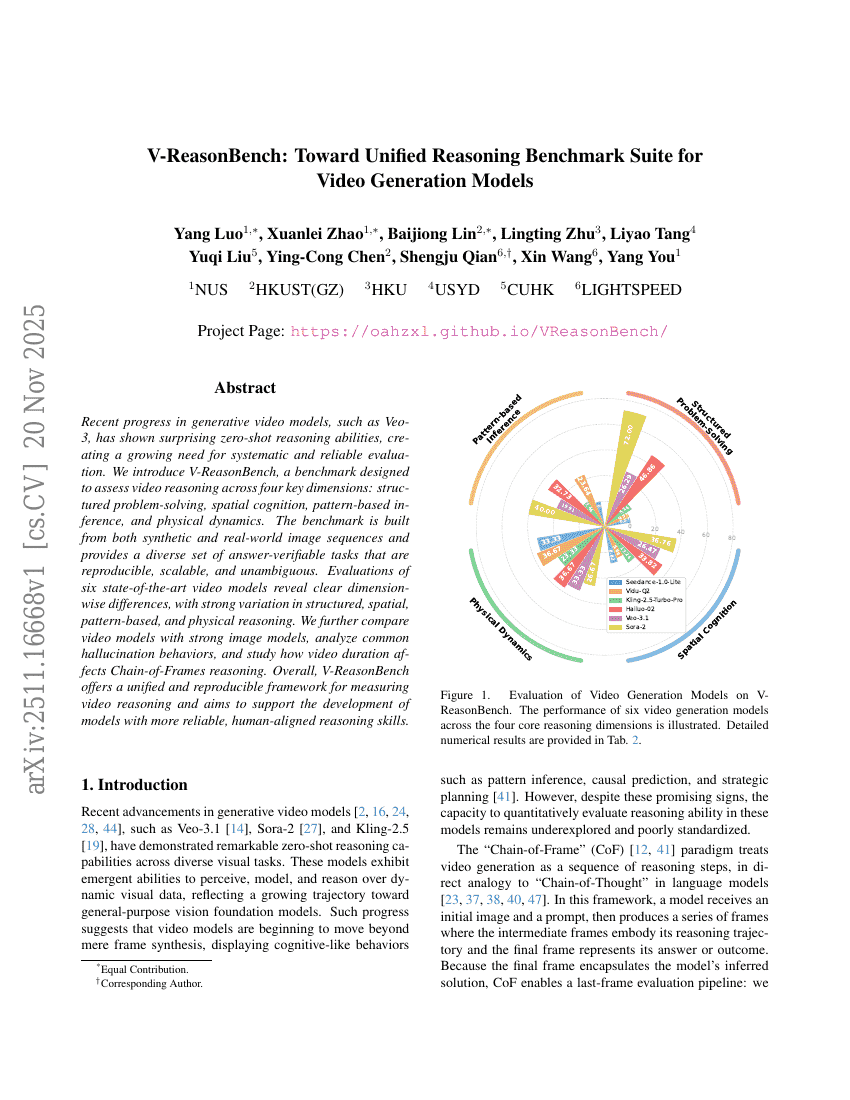
V-ReasonBench : Vers un ensemble unifié de benchmarks pour les modèles de génération vidéo
Olmo 3
Expériences préliminaires d'accélération scientifique avec GPT-5
Vers une évaluation objective et systématique des biais dans l'intelligence artificielle pour l'imagerie médicale
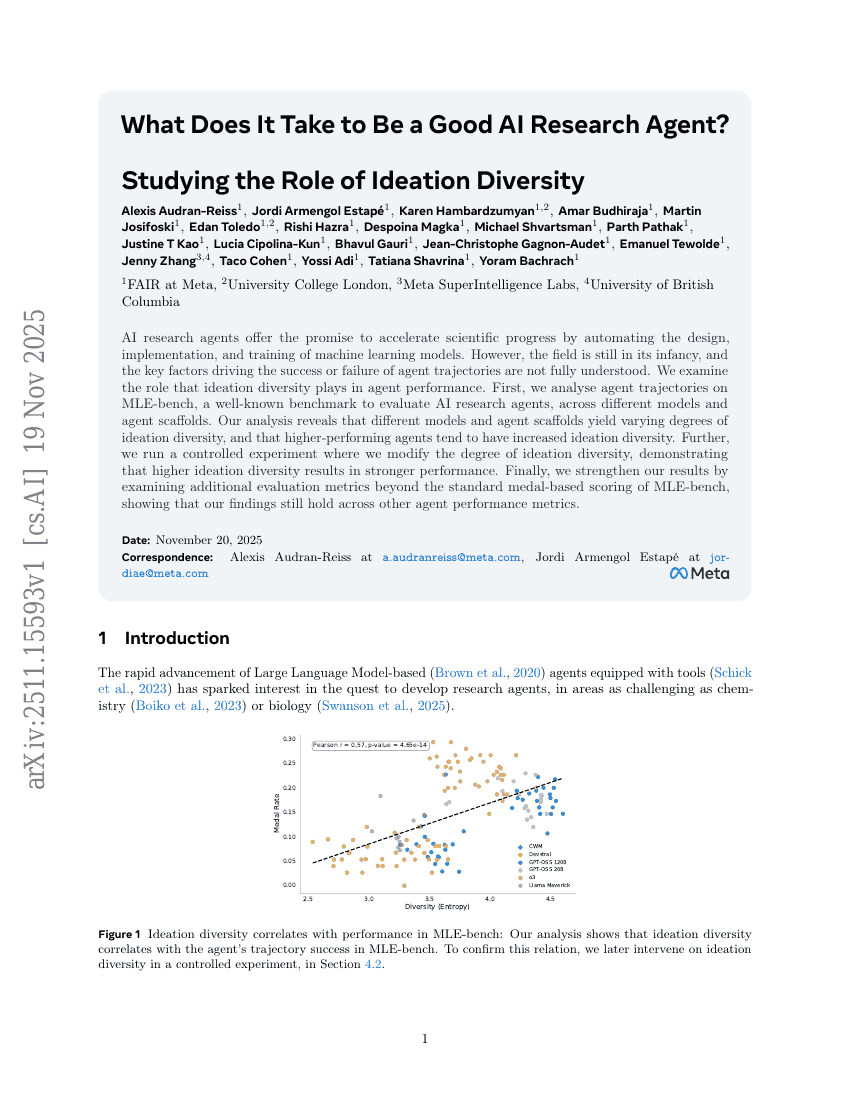
Qu’est-ce qui fait d’un bon agent de recherche en IA ? Une étude sur le rôle de la diversité de l’idéation
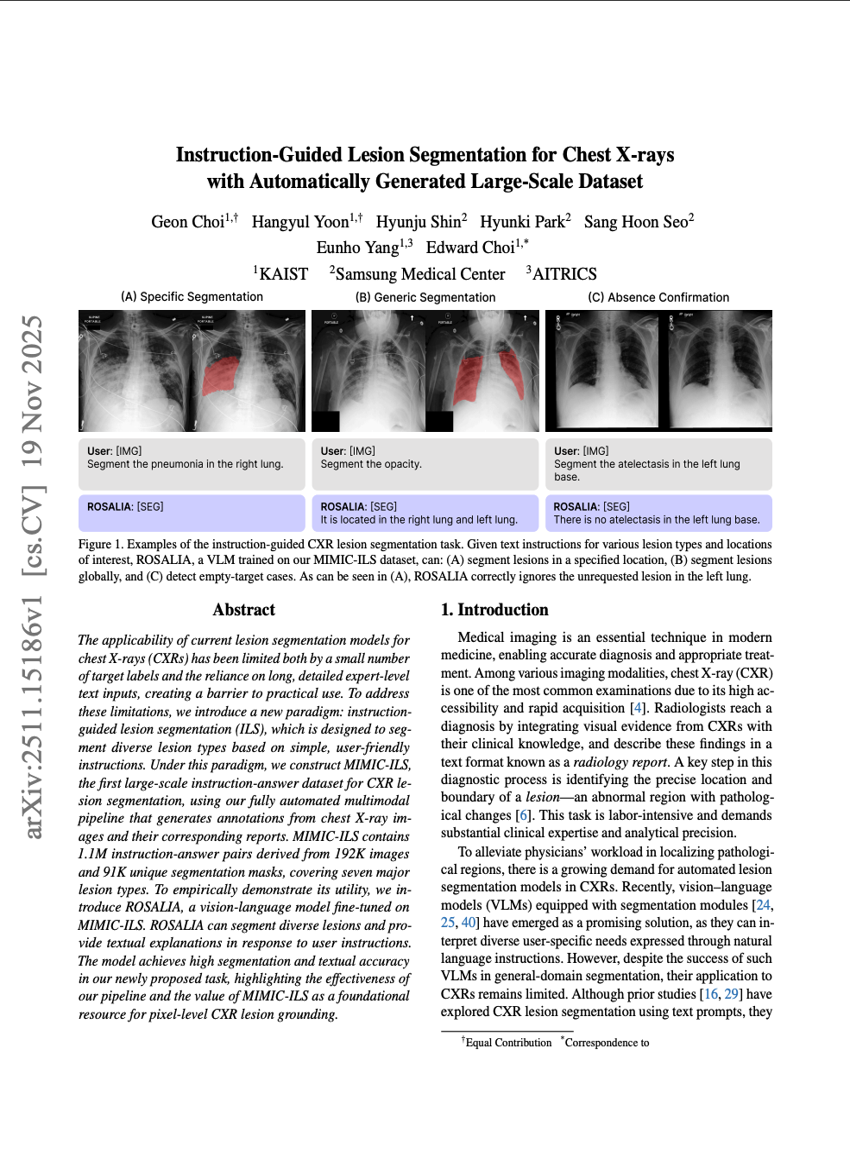
Segmentation de lésions guidée par instruction pour les radiographies thoraciques à l'aide d'un jeu de données à grande échelle généré automatiquement
VisPlay : Modèles Vision-Language auto-évoluant à partir d'images
Raisonnement par vidéo : Première évaluation des capacités de raisonnement des modèles vidéo à travers des tâches de résolution de labyrinthes
VIDEOP2R : Compréhension vidéo de la perception au raisonnement
Kandinsky 5.0 : Une famille de modèles fondamentaux pour la génération d’images et de vidéos
JAM-2 : conception entièrement computationnelle d'anticorps de type médicament avec un taux de réussite élevé
PathMind : un cadre Retrieve-Prioritize-Reason pour le raisonnement sur les graphes de connaissances avec les modèles de langage à grande échelle
REVISEUR : Au-delà de la réflexion textuelle, vers une raisonnement introspectif multimodal dans la compréhension des vidéos longues
MVI-Bench : Un benchmark complet pour évaluer la robustesse aux entrées visuelles trompeuses dans les LVLM
Les simulateurs mondiaux peuvent-ils raisonner ? Gen-ViRe : Une référence générative pour le raisonnement visuel
Un Style Vaut Un Code : Déverrouiller la Génération d'Images Code-to-Style avec un Espace de Style Discret
AraLingBench : Un benchmark annoté par des humains pour évaluer les capacités linguistiques arabes des grands modèles linguistiques (LLM)
Think-at-Hard : itérations latentes sélectives pour améliorer les modèles de langage rationnels
HumanSense : de la perception multimodale aux réponses empathiques et conscientes du contexte par le biais du raisonnement dans les MLLMs
CamCloneMaster : Permettre le contrôle de la caméra basé sur une référence pour la génération vidéo
EditScore : Déverrouiller le renforcement par apprentissage en ligne pour l'édition d'images grâce à une modélisation de récompense à haute fidélité
InteractMove : Génération d'interactions homme-objet contrôlée par texte dans des scènes 3D comprenant des objets déplaçables
WebCoach : Agents web auto-évoluant avec une orientation mémoire trans-session
Apprendre à faire confiance : adaptation bayésienne à la fiabilité variable du suggesteur dans la prise de décision séquentielle
GroupRank : un paradigme de reranking groupwise piloté par apprentissage par renforcement
MMaDA-Parallel : Modèles Multimodaux de Diffusion de Langage de Grande Taille pour l'Édition et la Génération Conscientes de la Pensée
TiViBench : Évaluation du raisonnement « think-in-video » pour les modèles génératifs vidéo
Le premier cadre est la place à aller pour la personnalisation du contenu vidéo
L’extension de l’intelligence spatiale grâce aux modèles fondamentaux multimodaux
Rapport technique Step-Audio-R1
V-ReasonBench : Vers un ensemble unifié de benchmarks pour les modèles de génération vidéo
Olmo 3
Expériences préliminaires d'accélération scientifique avec GPT-5
Vers une évaluation objective et systématique des biais dans l'intelligence artificielle pour l'imagerie médicale
Qu’est-ce qui fait d’un bon agent de recherche en IA ? Une étude sur le rôle de la diversité de l’idéation
Segmentation de lésions guidée par instruction pour les radiographies thoraciques à l'aide d'un jeu de données à grande échelle généré automatiquement
VisPlay : Modèles Vision-Language auto-évoluant à partir d'images
Raisonnement par vidéo : Première évaluation des capacités de raisonnement des modèles vidéo à travers des tâches de résolution de labyrinthes
VIDEOP2R : Compréhension vidéo de la perception au raisonnement
Kandinsky 5.0 : Une famille de modèles fondamentaux pour la génération d’images et de vidéos
JAM-2 : conception entièrement computationnelle d'anticorps de type médicament avec un taux de réussite élevé
PathMind : un cadre Retrieve-Prioritize-Reason pour le raisonnement sur les graphes de connaissances avec les modèles de langage à grande échelle
REVISEUR : Au-delà de la réflexion textuelle, vers une raisonnement introspectif multimodal dans la compréhension des vidéos longues
MVI-Bench : Un benchmark complet pour évaluer la robustesse aux entrées visuelles trompeuses dans les LVLM
Les simulateurs mondiaux peuvent-ils raisonner ? Gen-ViRe : Une référence générative pour le raisonnement visuel
Un Style Vaut Un Code : Déverrouiller la Génération d'Images Code-to-Style avec un Espace de Style Discret
AraLingBench : Un benchmark annoté par des humains pour évaluer les capacités linguistiques arabes des grands modèles linguistiques (LLM)
Think-at-Hard : itérations latentes sélectives pour améliorer les modèles de langage rationnels
HumanSense : de la perception multimodale aux réponses empathiques et conscientes du contexte par le biais du raisonnement dans les MLLMs
CamCloneMaster : Permettre le contrôle de la caméra basé sur une référence pour la génération vidéo
EditScore : Déverrouiller le renforcement par apprentissage en ligne pour l'édition d'images grâce à une modélisation de récompense à haute fidélité
InteractMove : Génération d'interactions homme-objet contrôlée par texte dans des scènes 3D comprenant des objets déplaçables
WebCoach : Agents web auto-évoluant avec une orientation mémoire trans-session
Apprendre à faire confiance : adaptation bayésienne à la fiabilité variable du suggesteur dans la prise de décision séquentielle
GroupRank : un paradigme de reranking groupwise piloté par apprentissage par renforcement
MMaDA-Parallel : Modèles Multimodaux de Diffusion de Langage de Grande Taille pour l'Édition et la Génération Conscientes de la Pensée
TiViBench : Évaluation du raisonnement « think-in-video » pour les modèles génératifs vidéo