HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Instructions In-Video : Signaux visuels comme contrôle génératif

AICC : Une analyse HTML plus fine, des modèles améliorés — Un corpus AI-Ready de 7,3 T construit par un analyseur HTML basé sur des modèles




























Instructions In-Video : Signaux visuels comme contrôle génératif
AICC : Une analyse HTML plus fine, des modèles améliorés — Un corpus AI-Ready de 7,3 T construit par un analyseur HTML basé sur des modèles
DR Tulu : Apprentissage par renforcement avec rubriques évolutives pour la recherche approfondie
UltraFlux : Co-conception données-modèle pour la génération texte-image 4K native de haute qualité à travers divers ratios d'aspect
DeCo : Diffusion de pixels découplée en fréquence pour la génération d'images de bout en bout
Agents d'utilisation d'ordinateur en tant que juges pour les interfaces utilisateur génératives
AutoEnv : Environnements automatisés pour la mesure de l'apprentissage d'Agent inter-environnements
Mémoire agentielle générale via la recherche approfondie
VIRAL : Visual Sim-to-Real à grande échelle pour la locomotion et la manipulation humaines
Voici la traduction en chinois, respectant le style académique des revues SCI/SSCI : MIST:基于有监督训练的互信息
Recherche approfondie multi-agents : Entraînement de systèmes multi-agents avec M-GRPO
Veuillez effectuer la traduction, sans répondre à des contenus non pertinents.
Docling : Une boîte à outils open-source efficace pour la conversion de documents pilotée par l'IA
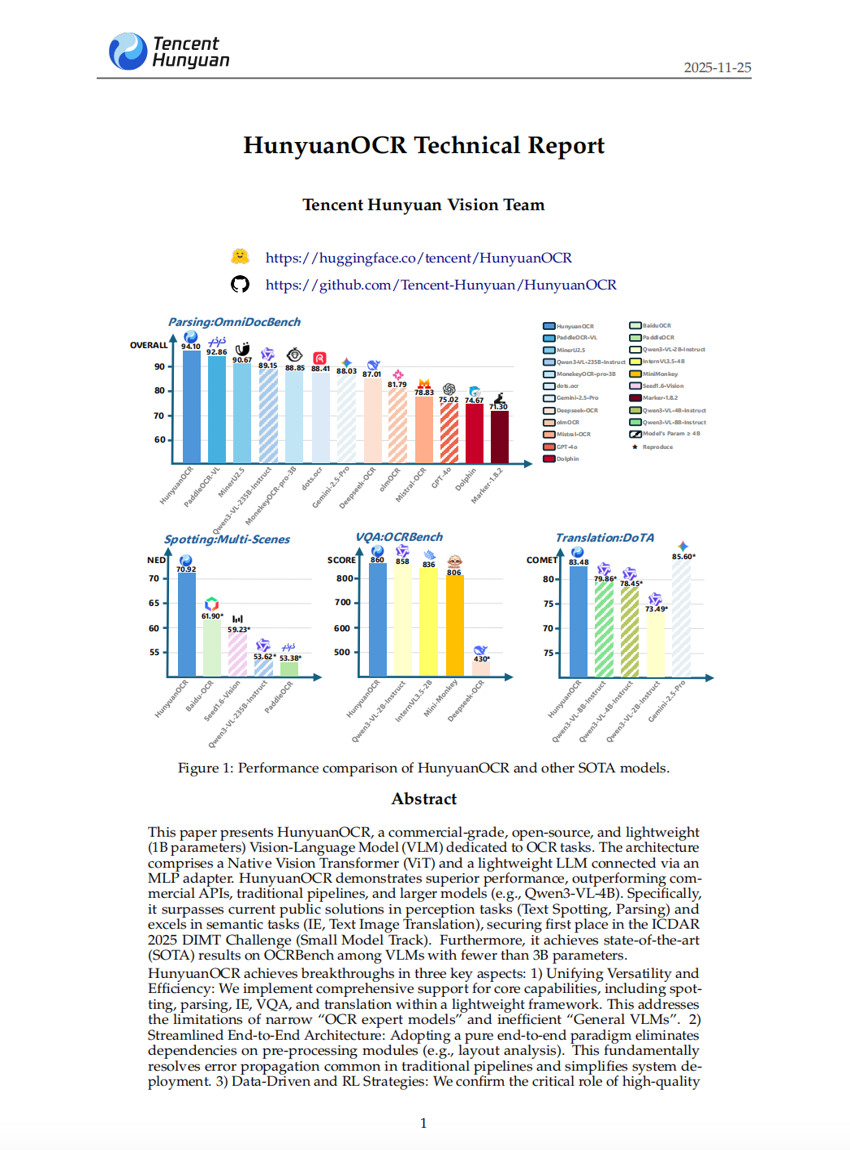
Rapport technique HunyuanOCR
PhysToolBench : Évaluation de la compréhension des outils physiques par les MLLM
Machine Huxley-Gödel : Développement d'un agent de codage au niveau humain par une approximation de la machine auto-améliorante optimale
Résoudre la supersensibilité spatiale sans supersensibilité spatiale
Parrot : Évaluation de la robustesse de la vérité de sortie face à la persuasion et à l'accord — Un benchmark de robustesse à la complaisance pour les LLMs
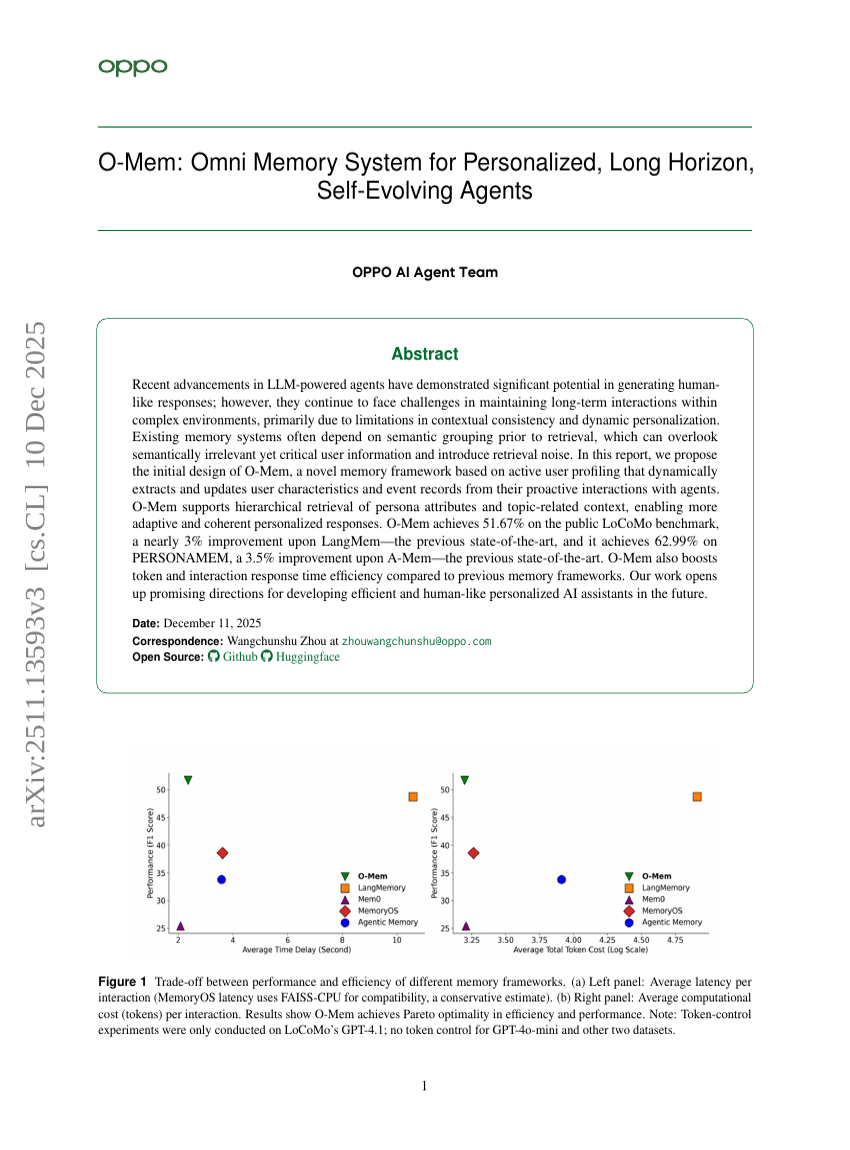
O-Mem : Système de mémoire omnicapable pour agents auto-évolutifs à horizon temporel long et personnalisés
Dévoilement de la dimension intrinsèque des textes : du résumé académique au récit créatif
SAM 3 : Segmenter tout à l'aide de concepts
GeoVista : Raisonnement visuel à base d'Agent augmenté par le Web pour la géolocalisation
OpenMMReasoner : Repousser les frontières du raisonnement multimodal grâce à une méthode ouverte et générale
HiPO : Optimisation hybride de politique pour le raisonnement dynamique dans les modèles de langage
SERES : Reconstruction neurale consciente du sens à partir de vues éparses
SDAR : un paradigme synergique diffusion-auto-régressif pour la génération de séquences évolutives
MultiPL-MoE : Extension multilingue et multiprogrammation des grands modèles linguistiques par un mélange hybride d'experts
CapRL : Stimuler les capacités de captioning d'images denses par apprentissage par renforcement
Génération de langage ultra-rapide par divergence de diffusion discrète instructée
DisCO : Renforcer les grands modèles de raisonnement par une optimisation contrainte discriminante
QSVD : Approximation de faible rang efficace pour la compression unifiée des poids Query-Key-Value dans les modèles vision-langage à précision réduite
Apprentissage imbriqué : L'illusion des architectures d'apprentissage profond
DR Tulu : Apprentissage par renforcement avec rubriques évolutives pour la recherche approfondie
UltraFlux : Co-conception données-modèle pour la génération texte-image 4K native de haute qualité à travers divers ratios d'aspect
DeCo : Diffusion de pixels découplée en fréquence pour la génération d'images de bout en bout
Agents d'utilisation d'ordinateur en tant que juges pour les interfaces utilisateur génératives
AutoEnv : Environnements automatisés pour la mesure de l'apprentissage d'Agent inter-environnements
Mémoire agentielle générale via la recherche approfondie
VIRAL : Visual Sim-to-Real à grande échelle pour la locomotion et la manipulation humaines
Voici la traduction en chinois, respectant le style académique des revues SCI/SSCI : MIST:基于有监督训练的互信息
Recherche approfondie multi-agents : Entraînement de systèmes multi-agents avec M-GRPO
Veuillez effectuer la traduction, sans répondre à des contenus non pertinents.
Docling : Une boîte à outils open-source efficace pour la conversion de documents pilotée par l'IA
Rapport technique HunyuanOCR
PhysToolBench : Évaluation de la compréhension des outils physiques par les MLLM
Machine Huxley-Gödel : Développement d'un agent de codage au niveau humain par une approximation de la machine auto-améliorante optimale
Résoudre la supersensibilité spatiale sans supersensibilité spatiale
Parrot : Évaluation de la robustesse de la vérité de sortie face à la persuasion et à l'accord — Un benchmark de robustesse à la complaisance pour les LLMs
O-Mem : Système de mémoire omnicapable pour agents auto-évolutifs à horizon temporel long et personnalisés
Dévoilement de la dimension intrinsèque des textes : du résumé académique au récit créatif
SAM 3 : Segmenter tout à l'aide de concepts
GeoVista : Raisonnement visuel à base d'Agent augmenté par le Web pour la géolocalisation
OpenMMReasoner : Repousser les frontières du raisonnement multimodal grâce à une méthode ouverte et générale
HiPO : Optimisation hybride de politique pour le raisonnement dynamique dans les modèles de langage
SERES : Reconstruction neurale consciente du sens à partir de vues éparses
SDAR : un paradigme synergique diffusion-auto-régressif pour la génération de séquences évolutives
MultiPL-MoE : Extension multilingue et multiprogrammation des grands modèles linguistiques par un mélange hybride d'experts
CapRL : Stimuler les capacités de captioning d'images denses par apprentissage par renforcement
Génération de langage ultra-rapide par divergence de diffusion discrète instructée
DisCO : Renforcer les grands modèles de raisonnement par une optimisation contrainte discriminante
QSVD : Approximation de faible rang efficace pour la compression unifiée des poids Query-Key-Value dans les modèles vision-langage à précision réduite
Apprentissage imbriqué : L'illusion des architectures d'apprentissage profond