Command Palette
Search for a command to run...
AutoEnv : Environnements automatisés pour la mesure de l'apprentissage d'Agent inter-environnements
AutoEnv : Environnements automatisés pour la mesure de l'apprentissage d'Agent inter-environnements
Résumé
Voici la traduction du texte en français, respectant le style formel et académique requis pour le domaine technologique :Les humains s'adaptent naturellement à divers environnements en apprenant les règles sous-jacentes à travers des mondes présentant des dynamiques, des observations et des structures de récompense différentes. En revanche, les agents existants démontrent généralement des améliorations via une auto-évolution au sein d'un domaine unique, supposant implicitement une distribution d'environnement fixe. L'apprentissage inter-environnements (cross-environment learning) est resté largement non mesuré : il n'existe ni collection standard d'environnements contrôlables et hétérogènes, ni méthode unifiée pour représenter la manière dont les agents apprennent.Nous comblons ces lacunes en deux étapes. Premièrement, nous proposons AutoEnv, un cadre automatisé qui traite les environnements comme des distributions factorisables sur les transitions, les observations et les récompenses, permettant la génération à faible coût (4,12 USD en moyenne) de mondes hétérogènes. À l'aide d'AutoEnv, nous avons construit AutoEnv-36, un jeu de données composé de 36 environnements avec 358 niveaux validés, sur lequel sept modèles de langage obtiennent une récompense normalisée de 12 à 49 %, démontrant ainsi la difficulté que représente AutoEnv-36.Deuxièmement, nous formalisons l'apprentissage des agents comme un processus centré sur les composants, piloté par trois étapes : Sélection, Optimisation et Évaluation, appliquées à un composant d'agent améliorable. En utilisant cette formulation, nous avons conçu huit méthodes d'apprentissage et les avons évaluées sur AutoEnv-36. Empiriquement, le gain de toute méthode d'apprentissage unique diminue rapidement à mesure que le nombre d'environnements augmente, révélant que les méthodes d'apprentissage fixes ne passent pas à l'échelle (scale) à travers des environnements hétérogènes. La sélection de méthodes d'apprentissage adaptative à l'environnement améliore considérablement les performances, mais présente des rendements décroissants à mesure que l'espace des méthodes s'étend. Ces résultats soulignent à la fois la nécessité et les limites actuelles de l'apprentissage des agents pour une généralisation inter-environnements évolutive, et positionnent AutoEnv et AutoEnv-36 comme un banc d'essai pour l'étude de l'apprentissage des agents inter-environnements. Le code est disponible sur https://github.com/FoundationAgents/AutoEnv.
Summarization
Researchers from HKUST (Guangzhou), DeepWisdom, et al. propose AutoEnv, an automated framework that treats environments as factorizable distributions to efficiently generate the heterogeneous AutoEnv-36 dataset, thereby establishing a unified testbed for measuring and formalizing agent learning scalability across diverse domains.
Introduction
Developing intelligent agents that can adapt across diverse environments, much like humans transition from board games to real-world tasks, remains a critical challenge in AI. While recent language agents perform well in specific domains like coding or web search, their success relies heavily on human-designed training data and narrow rule sets. Progress is currently stalled by two infrastructure gaps: the lack of an extensible collection of environments with heterogeneous rules, and the absence of a unified framework to represent how agents learn. Existing benchmarks rely on small, manually crafted sets that fail to test cross-environment generalization, while learning methods remain siloed as ad-hoc scripts that are difficult to compare systematically.
To bridge this gap, the authors introduce AutoEnv, an automated framework that generates diverse executable environments, alongside a formal component-centric definition of agentic learning.
The key innovations include:
- Automated Environment Generation: The system uses a multi-layer abstraction process to create AutoEnv-36, a dataset of 36 distinct environments and 358 validated levels at a low average cost of $4.12 per environment.
- Unified Learning Formalism: The researchers define agentic learning as a structured process involving Selection, Optimization, and Evaluation, allowing distinct strategies (such as prompt optimization or code updates) to be compared within a single configuration space.
- Cross-Environment Analysis: Empirical results demonstrate that fixed learning strategies yield diminishing returns as environment diversity increases, highlighting the necessity for adaptive methods that tailor learning components to specific rule distributions.
Dataset
Dataset Composition and Sources
- The authors introduce AutoEnv-36, a benchmark dataset consisting of 36 distinct reinforcement learning environments.
- The environments originate from an initial pool of 100 themes generated using the AutoEnv framework, primarily utilizing text-only SkinEnv rendering.
- While the main dataset focuses on text-based interactions, the authors also explore multi-modal generation by integrating coding agents with image generation models.
Subset Details and Filtering
- Verification Process: The initial 100 environments underwent a three-stage verification pipeline, resulting in 65 viable candidates.
- Selection Criteria: The final 36 environments were selected to maximize diversity in rule types and difficulty, filtering out tasks that were either too trivial or too hard for meaningful evaluation.
- Reward Distribution: The dataset is split evenly (50/50) between binary rewards (success/failure at the end) and accumulative rewards (scores collected over time).
- Observability: The environments favor partial observability (58.3%) over full observability (41.7%) to reflect realistic information constraints.
- Semantic Alignment: Most environments (78.8%) use aligned semantics where descriptions match rules, while a subset (22.2%) uses inverse semantics (e.g., "poison restores health") to test robustness against misleading instructions.
Usage in Evaluation
- The paper utilizes the dataset to evaluate agent performance across specific capability dimensions, including navigation, memory, resource control, pattern matching, and planning.
- The authors use the inverse semantic subset specifically to force agents to rely on interaction rather than surface wording.
- The environments present moderate structural complexity, featuring an average of 6.10 available actions and approximately 471 lines of implementation code per task.
Processing and Metadata
- File Structure: Each environment is organized with specific metadata files, including YAML configurations, Python implementation scripts, reward computation logic, and natural language agent instructions.
- Standardization: The dataset employs a unified interface for action spaces and observations, supporting both procedural generation and fixed level loading.
- Feature Tagging: The authors explicitly tag each environment with the primary skills required (such as "Multi-agent" or "Long-horizon Planning") to facilitate detailed performance analysis.
Method
The authors leverage a component-centric framework for agent learning, formalized through four basic objects—candidate, component, trajectory, and metric—and three iterative stages: Selection, Optimization, and Evaluation. A candidate represents a version of the agent, encapsulating its internal components and associated metadata such as recent trajectories and performance metrics. Components are modifiable parts of the agent, including prompts, agent code, tools, or the underlying model. During interaction with an environment, a candidate produces a trajectory, which is then used to compute one or more metrics, such as success rate or reward. The learning process proceeds through the three stages: Selection chooses candidates from the current pool based on a specified rule (e.g., best-performing or Pareto-optimal); Optimization modifies the selected candidates' target components using an optimization model that analyzes the candidate's structure, past trajectories, and metrics to propose edits; and Evaluation executes the updated candidates in the environment to obtain new trajectories and compute updated metrics. This framework enables the expression of various existing learning methods, such as SPO for prompt optimization and AFlow for workflow optimization, by specifying different combinations of selection rules, optimization schemes, and target components.
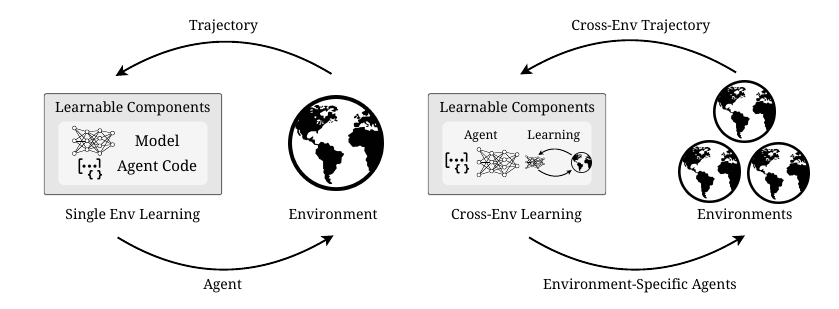
The environment generation process, referred to as \textscAutoEnv, follows a pipeline that leverages a three-layer abstraction to systematically create and validate environments. The process begins with an environment theme, which is translated into a detailed language description. This description is then converted into a YAML-based domain-specific language (DSL) that specifies the core dynamics for the BaseEnv, the observation policy for the ObsEnv, the rendering rules for the SkinEnv, and the configuration of a level generator. Coding agents then read this DSL to implement the three-layer classes, the level generator, and concise agent-facing documentation. The initial code is subjected to a self-repair loop, where the agents run syntax and execution tests, collect error messages, and iteratively edit the code until the tests pass or a repair budget is exhausted. The final outputs are executable environment code for all three layers, a level generator, and a validator. The generated environments undergo a three-stage verification pipeline: Execution testing ensures runtime stability by running a simple ReAct-style agent; Level Generation checks that the generator can produce valid levels with properties like goal reachability; and Reliability testing uses differential model testing with two ReAct agents to ensure the reward structure is skill-based and not random. This pipeline ensures that the final environments are executable, can generate valid levels, and provide reliable, non-random rewards.
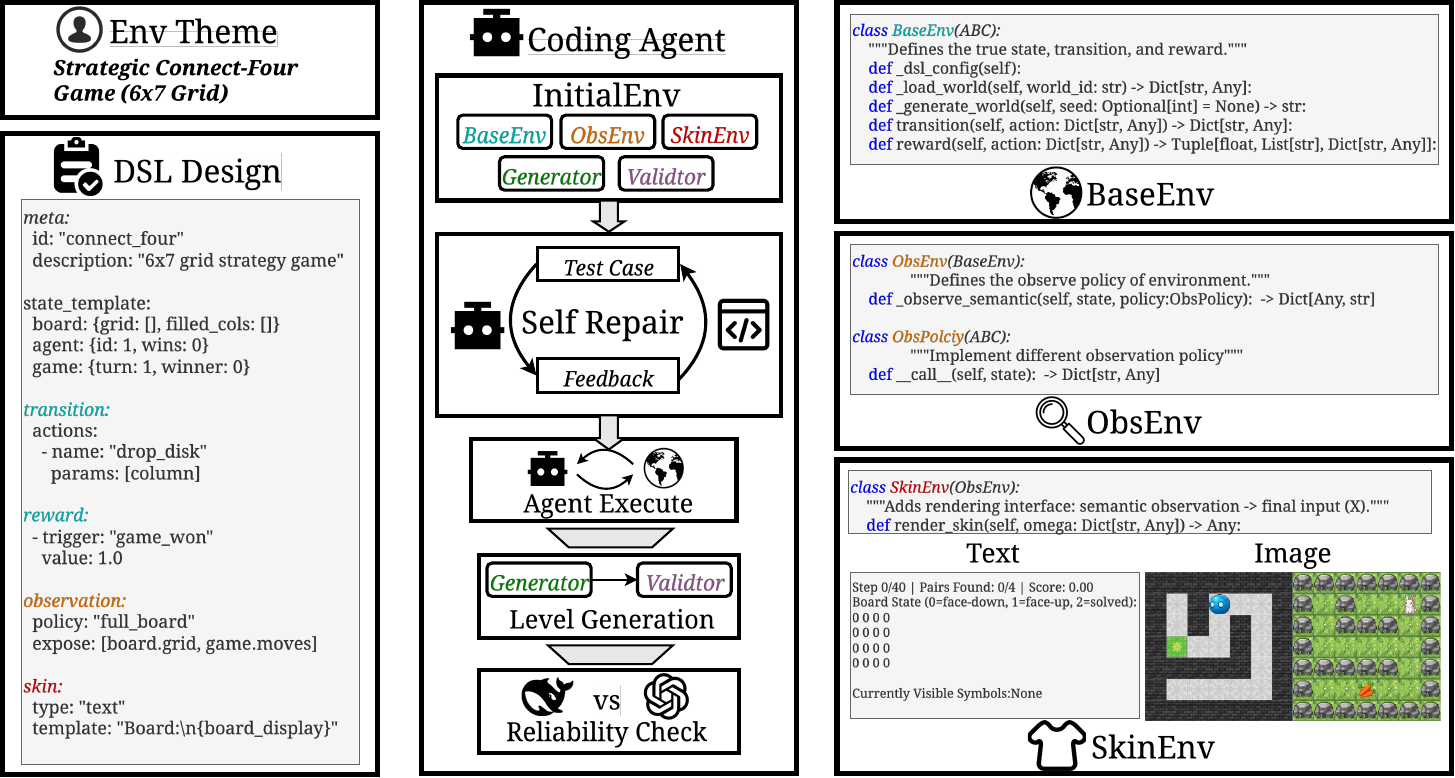
The environment abstraction is structured into three distinct layers to support systematic generation and agent interaction. The BaseEnv layer implements the core dynamics of the environment, including the state space, action space, transition function, reward function, and termination predicate, capturing the fundamental rules and maintaining the full world state. The ObsEnv layer specializes the observation function by applying configurable observation policies to the underlying state and transitions from the BaseEnv, determining what information is exposed to the agent. This allows for controlled variation in information availability, from full observability to strong partial observability. The SkinEnv layer applies rendering on top of the ObsEnv, converting observations into agent-facing modalities such as natural language text or images. This layered design enables the same observation policy to be paired with different skins, creating environments that appear semantically different to the agent while sharing the same underlying rules. The code implementation of these layers is provided in the appendix, with the BaseEnv defining the true state, transition, and reward, the ObsEnv adding an observation interface, and the SkinEnv adding a rendering interface that transforms semantic observations into final inputs.

Experiment
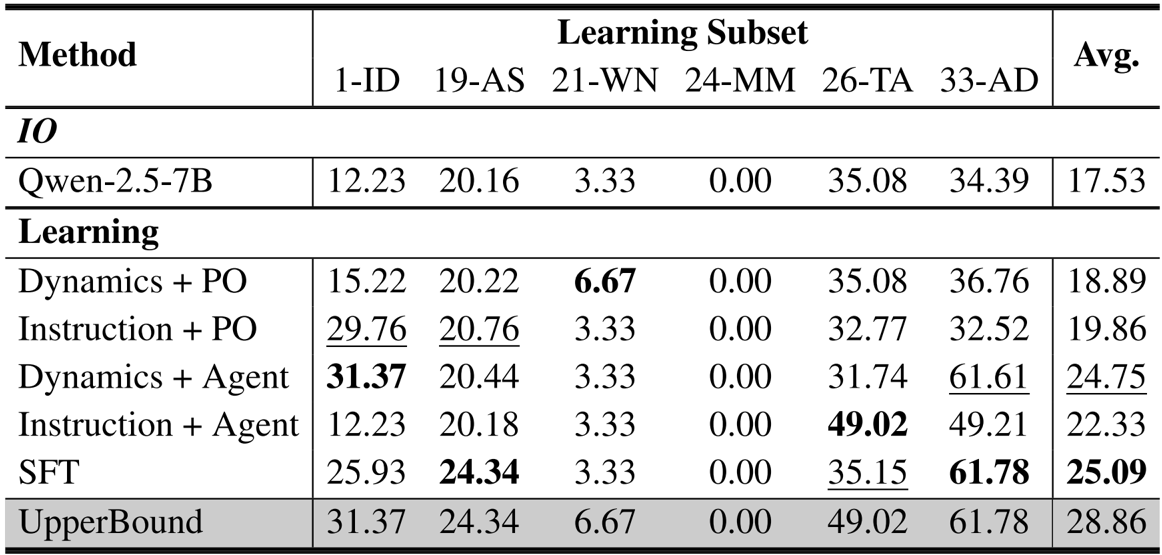
- Environment Generation Analysis: Evaluated AutoEnv across 100 themes, achieving 90.0% execution success and 96.7% level generation success with an average cost of $4.12 per environment. Human review of themes improved overall success rates from 60.0% to 80.0% by reducing rule inconsistencies.
- Model Performance Benchmarking: Validated AutoEnv-36 as a capability benchmark by testing 7 models; O3 achieved the highest normalized accuracy (48.73%), surpassing GPT-5 (46.80%) and significantly outperforming GPT-4o-mini (11.96%).
- Semantic Inversion Control: Conducted a "Skin Inverse" experiment which showed that inverting only semantic displays caused an 80% performance drop, clarifying that inverse semantics inherently increase difficulty and that higher scores in original inverse environments stemmed from simpler structural generation.
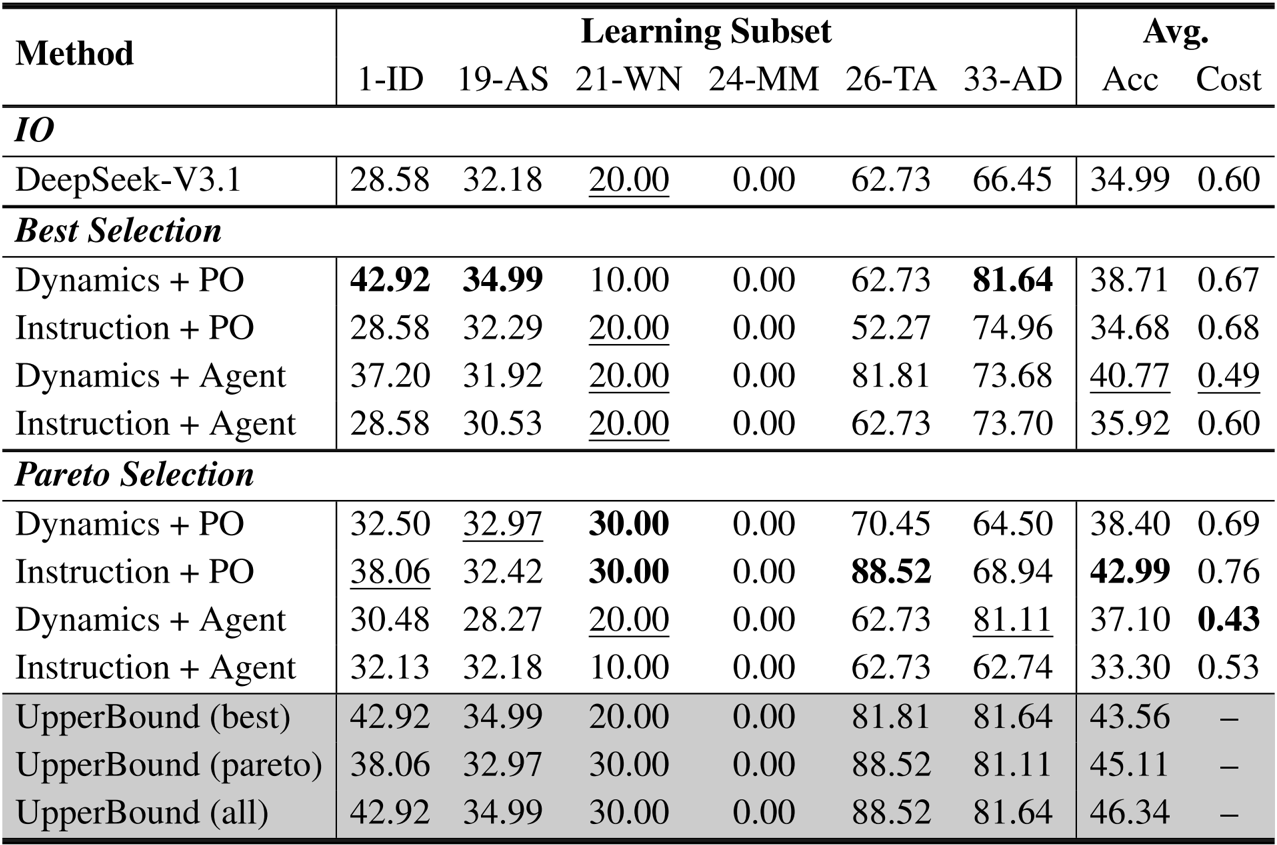
- Learning Method Diversity: Experiments on a 6-environment subset using Qwen-2.5-7B and DeepSeek-V3.1 revealed strong environment-method interactions. On DeepSeek-V3.1, the upper bound using 8 methods reached 46.34%, exceeding the best single method performance of 42.99%.
- Adaptive Learning Potential: Scaling to 36 environments demonstrated that single learning methods yield marginal gains over baselines (42.40% vs. 39.41%), whereas the adaptive upper bound achieved 47.75%, highlighting the necessity of environment-specific strategy selection.
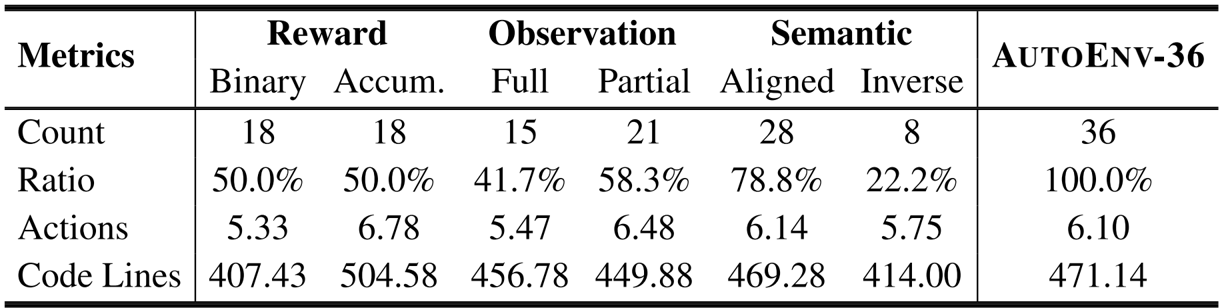
The authors use the table to summarize the characteristics of the 36 environments in the AutoEnv-36 benchmark, showing the number of environments and their distribution across different reward, observation, and semantic types. Results show that the benchmark includes a diverse set of environments, with binary and accumulative rewards each covering 50.0% of the total, full observation environments making up 41.7%, and aligned semantic environments being the most common at 78.8%.
The authors use the table to evaluate the performance of their AutoEnv generation pipeline across 100 environment themes, distinguishing between purely LLM-generated (Automated) and human-reviewed (Supervised) themes. Results show that human review significantly improves overall success rates from 60.0% to 80.0%, primarily by reducing rule inconsistencies, while also lowering generation costs. The overall success rate across all themes is 65.0%, with 90.0% execution success, 96.7% level generation success, and 74.7% reliability verification rate.
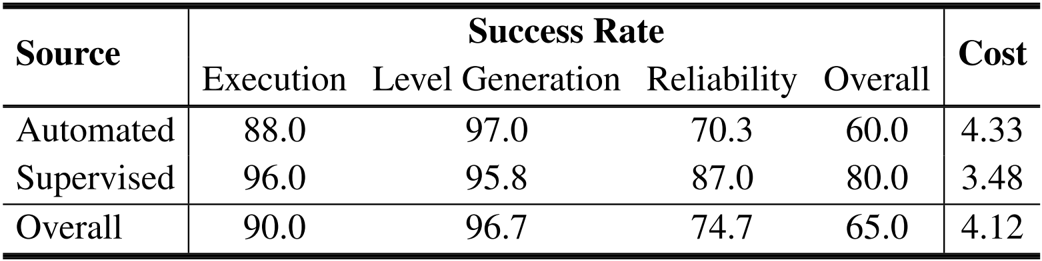
Results show that O3 achieves the highest performance at 48.73% normalized accuracy, followed by GPT-5 at 46.80%, while GPT-4o-mini obtains the lowest at 11.96%. The performance gap across models validates the benchmark's ability to differentiate agent capabilities, with binary reward environments outperforming accumulative ones and full observation environments outperforming partial ones.
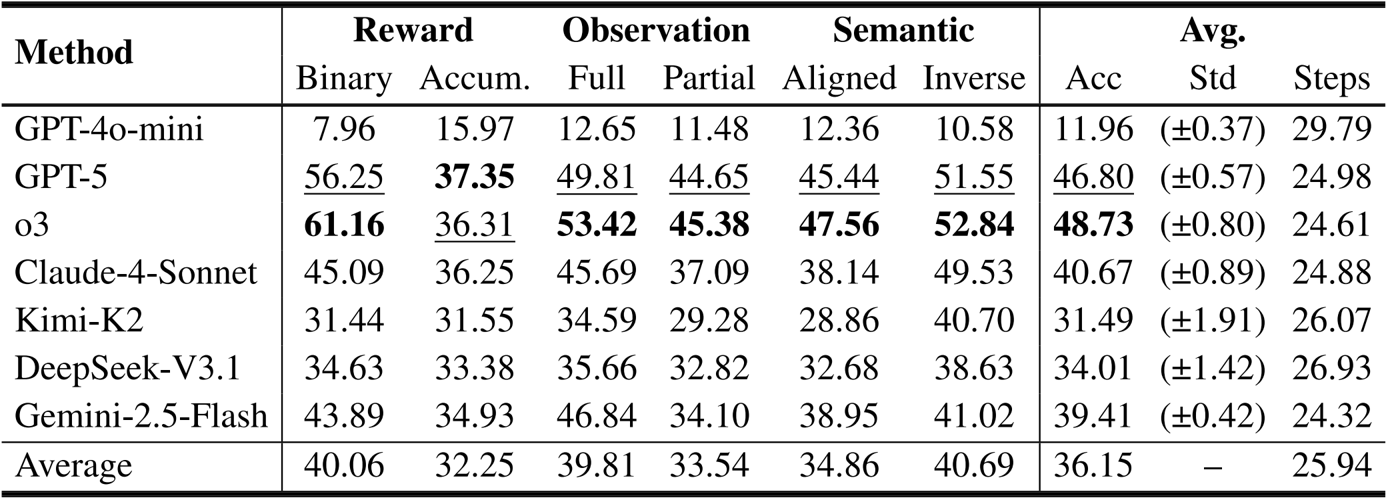
The authors use a subset of six environments to evaluate different learning methods, including training-free approaches and supervised fine-tuning (SFT), on the Qwen-2.5-7B model. Results show that the upper bound performance, achieved by selecting the best method per environment, is 28.86%, significantly higher than the best single method (SFT at 25.09%), indicating that optimal learning strategies are environment-specific and that combining diverse methods improves overall performance.
The authors use DeepSeek-V3.1 to evaluate five learning methods across six environments, comparing performance under Best Selection and Pareto Selection. Results show that the upper bound performance increases with more methods, but gains diminish after four methods, with the best single method achieving 38.71% accuracy and the upper bound reaching 46.34% when all methods are combined.