HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

AutoResearchClaw : Recherche autonome auto-renforçante avec collaboration humain-IA

Récompenses de processus avec fiabilité apprise

























AutoResearchClaw : Recherche autonome auto-renforçante avec collaboration humain-IA
Récompenses de processus avec fiabilité apprise
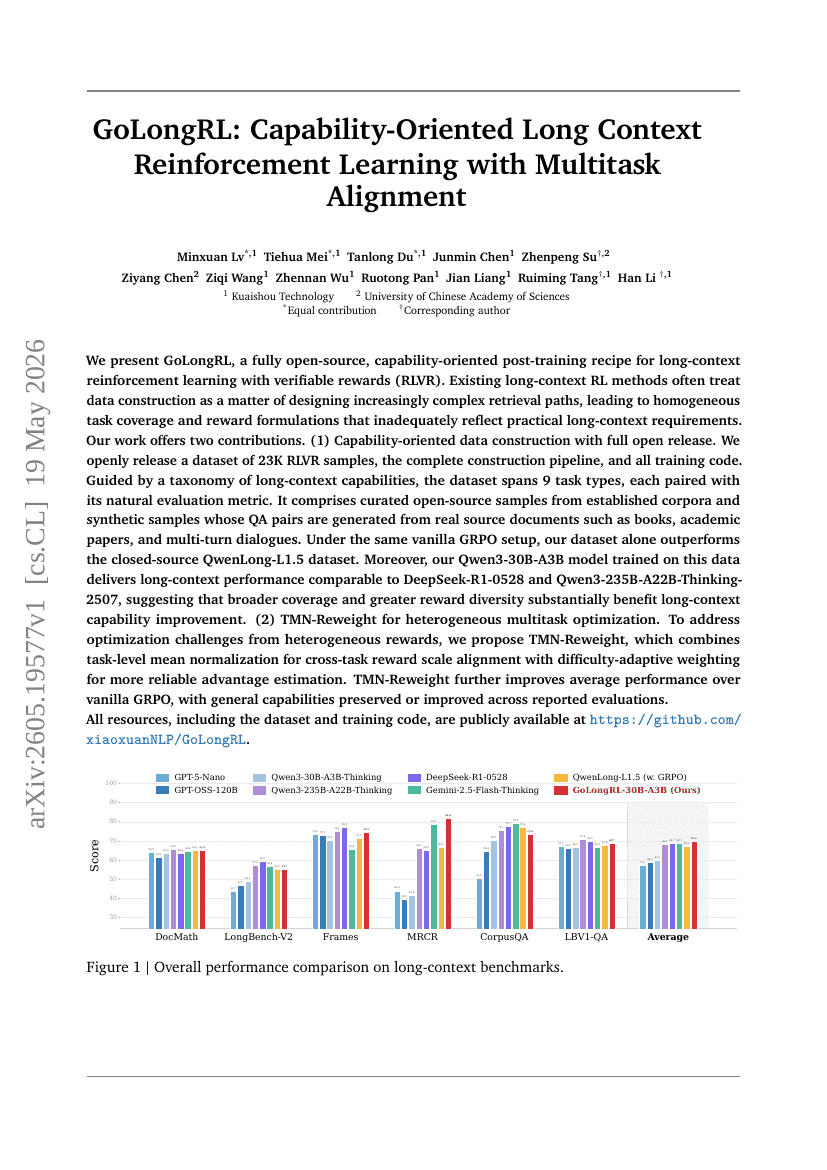
GoLongRL : Apprentissage par renforcement de contexte long orienté vers les capacités avec alignement multitâche
OpenComputer : des mondes logiciels vérifiables pour les agents d'utilisation d'ordinateur
Anti-Auto-Distillation pour le Renforcement par Apprentissage par Renforcement via l'Information Mutuelle Ponctuelle
Modulation ciblée des neurones par recherche de paires contrastives
Continuous Diffusion Scales Compétitivement avec Discrete Diffusion pour Langage
KVPO : GRPO natif pour les EDO pour l'alignement vidéo autoregressif via l'exploration sémantique KV
Code-as-Room : Génération de salles 3D à partir d'images de vue de dessus via la synthèse de code agentic
IA pour l'auto-recherche : feuille de route et guide utilisateur
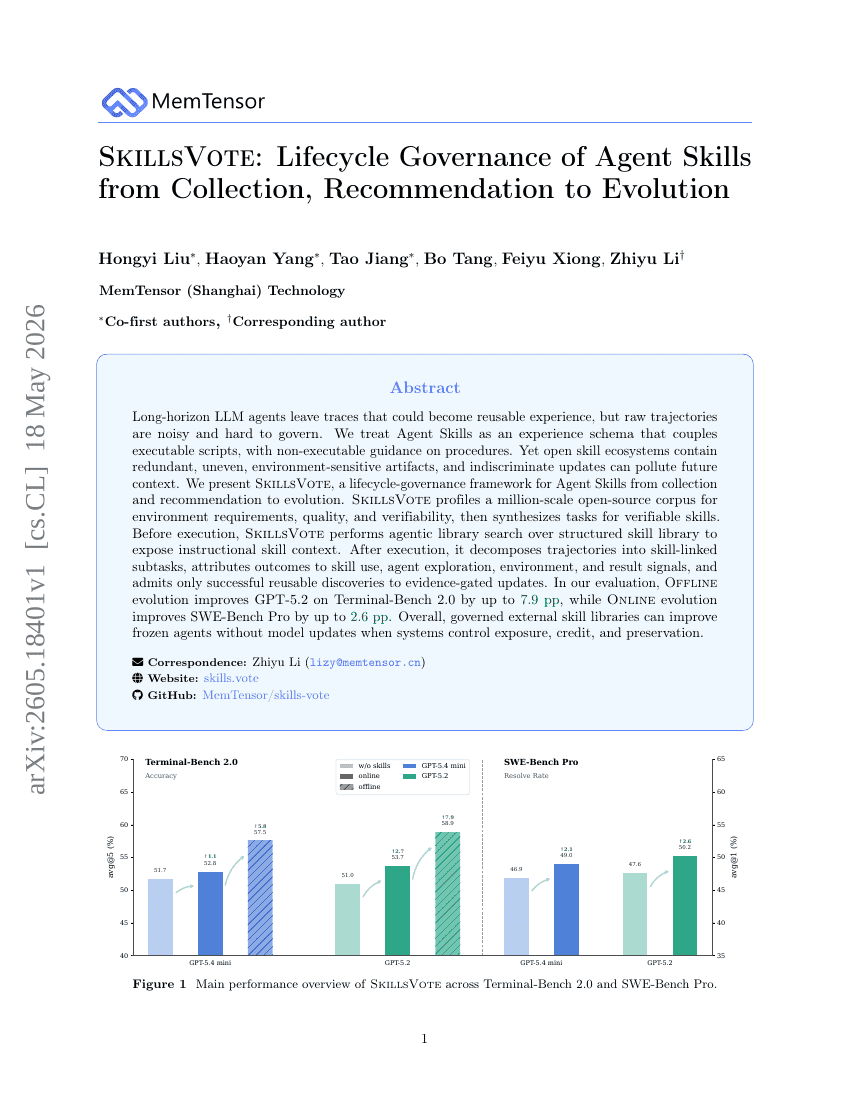
SkillsVote : Gouvernance du cycle de vie des compétences des agents, de la collecte et de la recommandation à l'évolution
Lance : Modélisation multimodale unifiée par synergie multi-tâches
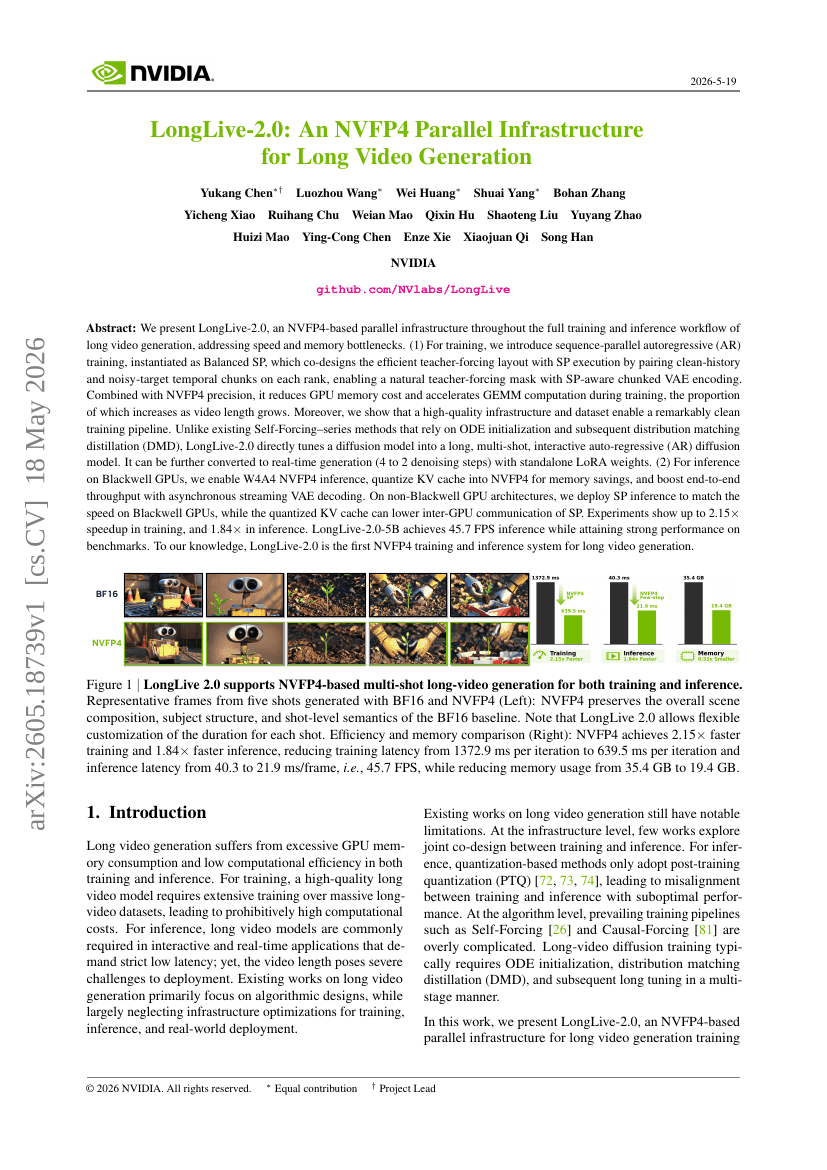
LongLive-2.0 : Une infrastructure parallèle NVFP4 pour la génération de vidéos longues
Découpage et Analyse Fine : Configuration de Mélanges Optimaux d'Experts
Découverte Agentique des Architectures Neurales : AIRA-Compose et AIRA-Design
Apprendre à prévoir : Révéler l'efficacité de déverrouillage de la distillation sur politique
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo
FashionChameleon : Vers une personnalisation vidéo en temps réel et interactive des vêtements humains
CiteVQA : Évaluation de l'attribution des preuves pour une intelligence documentaire fiable
MMSkills : Vers des compétences multimodales pour des agents visuels généraux
PhysBrain 1.0 Rapport technique
Ramenation des modèles de valeur : critiques génératives pour la modélisation de la valeur dans l’apprentissage par renforcement des LLM
NEXUS : Un cadre agentic pour la prévision des séries temporelles
MemEye : Un cadre d'évaluation visuo-centré pour la mémoire des agents multimodaux
SANA-WM : Modélisation du monde efficace à l'échelle de la minute avec un Transformateur de Diffusion Linéaire Hybride
MemLens : Évaluation des modèles de vision-langage à grande échelle pour la mémoire multimodale à long terme
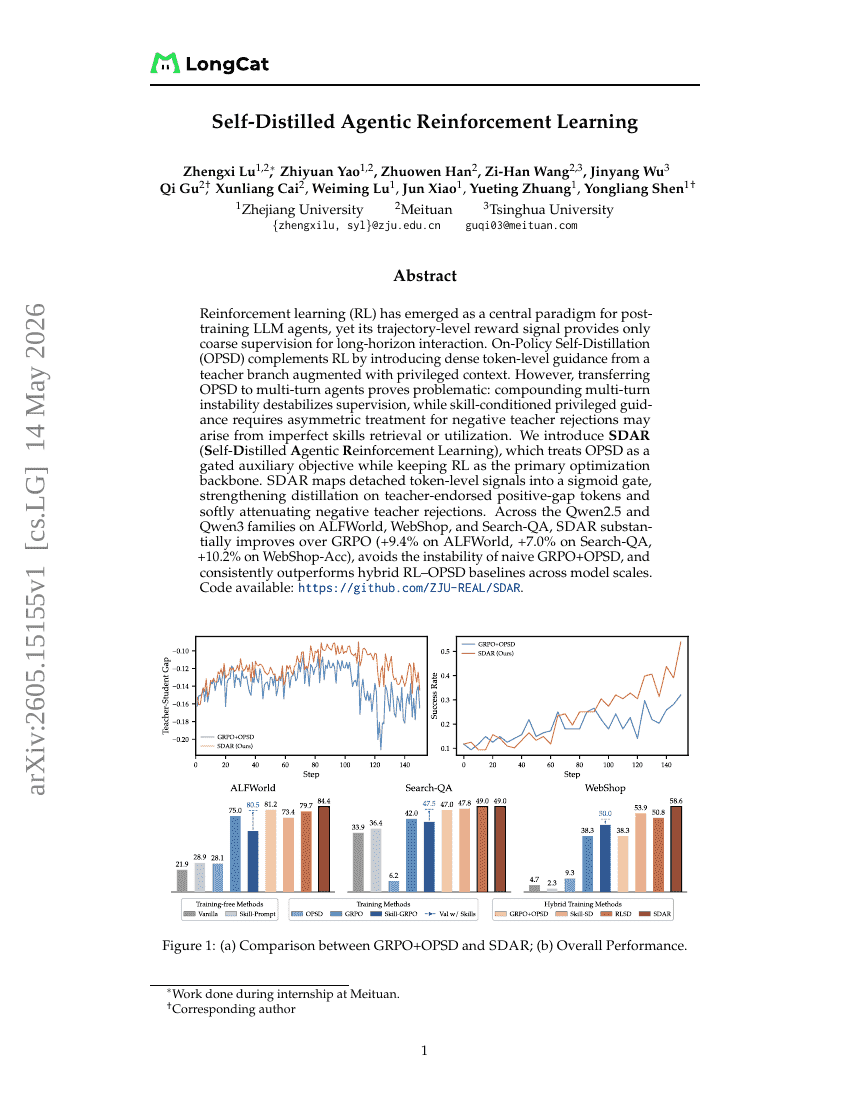
Apprentissage par renforcement agentique auto-distillé
Forçage causal++ : distillation de diffusion autoregressive à quelques étapes évolutive pour la génération vidéo interactive en temps réel
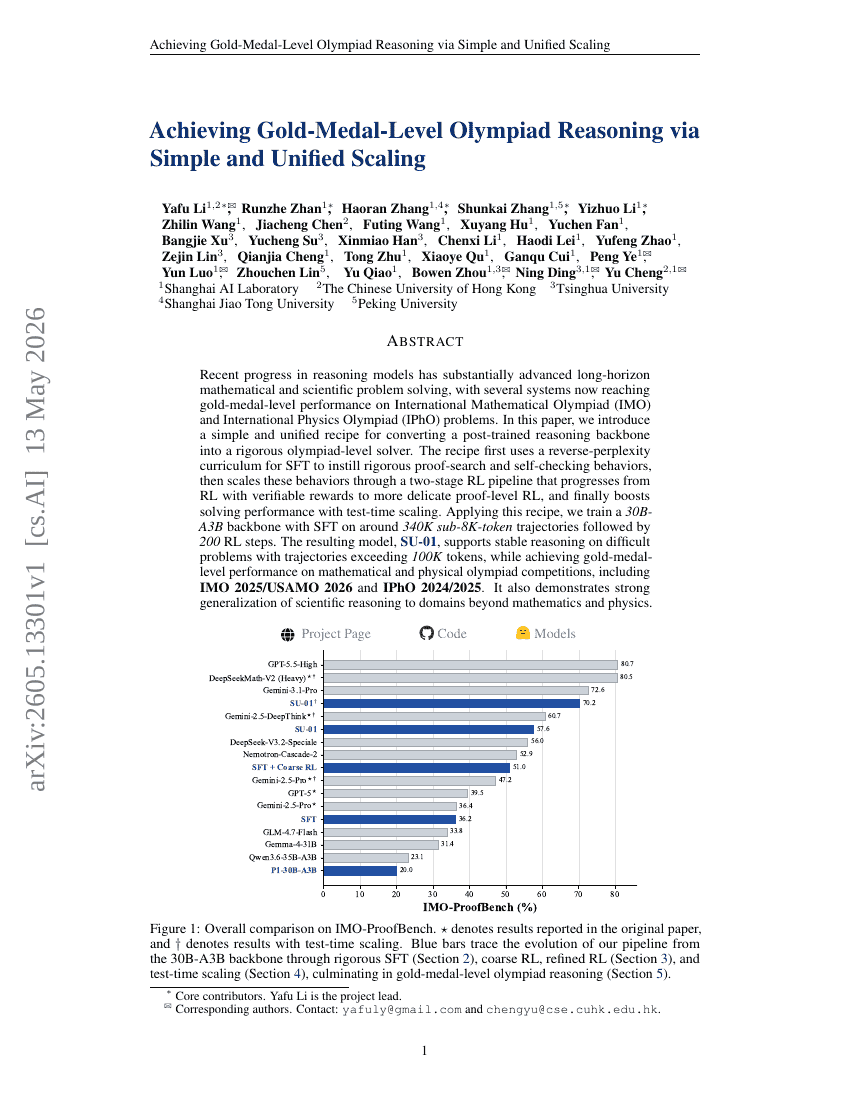
Obtenir un niveau de raisonnement olympique de médaille d'or via une mise à l'échelle simple et unifiée
RepoZero : Les LLMs peuvent-ils générer un dépôt de code à partir de zéro ?
Rapport technique Qwen-Image-VAE-2.0
Prédire les décisions des agents d'IA à partir d'interactions limitées par la modélisation textuelle et tabulaire
GoLongRL : Apprentissage par renforcement de contexte long orienté vers les capacités avec alignement multitâche
OpenComputer : des mondes logiciels vérifiables pour les agents d'utilisation d'ordinateur
Anti-Auto-Distillation pour le Renforcement par Apprentissage par Renforcement via l'Information Mutuelle Ponctuelle
Modulation ciblée des neurones par recherche de paires contrastives
Continuous Diffusion Scales Compétitivement avec Discrete Diffusion pour Langage
KVPO : GRPO natif pour les EDO pour l'alignement vidéo autoregressif via l'exploration sémantique KV
Code-as-Room : Génération de salles 3D à partir d'images de vue de dessus via la synthèse de code agentic
IA pour l'auto-recherche : feuille de route et guide utilisateur
SkillsVote : Gouvernance du cycle de vie des compétences des agents, de la collecte et de la recommandation à l'évolution
Lance : Modélisation multimodale unifiée par synergie multi-tâches
LongLive-2.0 : Une infrastructure parallèle NVFP4 pour la génération de vidéos longues
Découpage et Analyse Fine : Configuration de Mélanges Optimaux d'Experts
Découverte Agentique des Architectures Neurales : AIRA-Compose et AIRA-Design
Apprendre à prévoir : Révéler l'efficacité de déverrouillage de la distillation sur politique
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo
FashionChameleon : Vers une personnalisation vidéo en temps réel et interactive des vêtements humains
CiteVQA : Évaluation de l'attribution des preuves pour une intelligence documentaire fiable
MMSkills : Vers des compétences multimodales pour des agents visuels généraux
PhysBrain 1.0 Rapport technique
Ramenation des modèles de valeur : critiques génératives pour la modélisation de la valeur dans l’apprentissage par renforcement des LLM
NEXUS : Un cadre agentic pour la prévision des séries temporelles
MemEye : Un cadre d'évaluation visuo-centré pour la mémoire des agents multimodaux
SANA-WM : Modélisation du monde efficace à l'échelle de la minute avec un Transformateur de Diffusion Linéaire Hybride
MemLens : Évaluation des modèles de vision-langage à grande échelle pour la mémoire multimodale à long terme
Apprentissage par renforcement agentique auto-distillé
Forçage causal++ : distillation de diffusion autoregressive à quelques étapes évolutive pour la génération vidéo interactive en temps réel
Obtenir un niveau de raisonnement olympique de médaille d'or via une mise à l'échelle simple et unifiée
RepoZero : Les LLMs peuvent-ils générer un dépôt de code à partir de zéro ?
Rapport technique Qwen-Image-VAE-2.0
Prédire les décisions des agents d'IA à partir d'interactions limitées par la modélisation textuelle et tabulaire