Command Palette
Search for a command to run...
MemEye : Un cadre d'évaluation visuo-centré pour la mémoire des agents multimodaux
MemEye : Un cadre d'évaluation visuo-centré pour la mémoire des agents multimodaux
Résumé
La mémoire à long terme des agents devient de plus en plus multimodale, yet les évaluations existantes testent rarement si les agents conservent les preuves visuelles nécessaires au raisonnement ultérieur. Dans les travaux antérieurs, de nombreuses questions ancrées visuellement peuvent être répondues en utilisant uniquement des légendes ou des traces textuelles, permettant d’inférer les réponses sans conserver les preuves visuelles fines. Parallèlement, les cas plus difficiles nécessitant un raisonnement sur des états visuels changeants sont largement absents. Par conséquent, nous introduisons MemEye, un cadre qui évalue les capacités de mémoire selon deux dimensions : l’une mesure la granularité des preuves visuelles décisives (de la preuve de niveau scène à la preuve de niveau pixel), et l’autre mesure comment les preuves récupérées doivent être utilisées (de la preuve unique à la synthèse évolutive). Sous ce cadre, nous construisons un nouveau benchmark sur 8 tâches de scénarios de vie, avec des portes de validation par ablation pour évaluer l’accessibilité des réponses, la résistance aux raccourcis, la nécessité visuelle et la structure du raisonnement. En évaluant 13 méthodes de mémoire sur 4 backbones VLM, nous montrons que les architectures actuelles peinent encore à conserver les détails visuels fins et à raisonner sur les changements d’état au fil du temps. Nos résultats montrent que la mémoire multimodale à long terme dépend du routage des preuves, du suivi temporel et de l’extraction des détails.
One-sentence Summary
MemEye introduces a visual-centric evaluation framework that benchmarks multimodal agent memory across eight life-scenario tasks by measuring evidence granularity and retrieval synthesis, revealing through the evaluation of thirteen memory methods on four VLM backbones that current architectures struggle to preserve fine-grained visual details or reason over temporal state changes, thereby highlighting the necessity for robust evidence routing and tracking.
Key Contributions
- Introduces MemEye, a two-dimensional evaluation framework that assesses long-term multimodal agent memory by measuring visual evidence granularity and the complexity of synthesized reasoning.
- Constructs a benchmark across eight life-scenario tasks validated through ablation-driven gates and caption-substitution diagnostics to enforce visual necessity and prevent textual shortcut exploitation.
- Evaluates thirteen memory methods across four VLM backbones to demonstrate that existing architectures struggle to preserve fine-grained visual details over time, establishing that effective long-term memory relies on evidence routing and temporal tracking.
Introduction
The authors leverage the growing reliance on Vision-Language Models for long-term agent memory, which is essential for enabling AI systems to handle complex real-world tasks that require retaining both dialogue history and visual context. Prior evaluation frameworks, however, largely overlook this visual dimension by relying on text-heavy benchmarks or allowing models to answer questions using captions rather than original images. This design flaw masks critical failures in preserving fine-grained visual details and tracking temporal state changes across sessions. To address these gaps, the authors introduce MemEye, a novel evaluation framework and benchmark that measures multimodal memory along two orthogonal axes: visual evidence granularity and memory reasoning depth. By constructing a rigorously validated dataset of 371 questions across eight life-scenario tasks, they expose fundamental trade-offs in current architectures and demonstrate that reliable long-term visual memory requires precise evidence routing, temporal tracking, and detail extraction.
Dataset
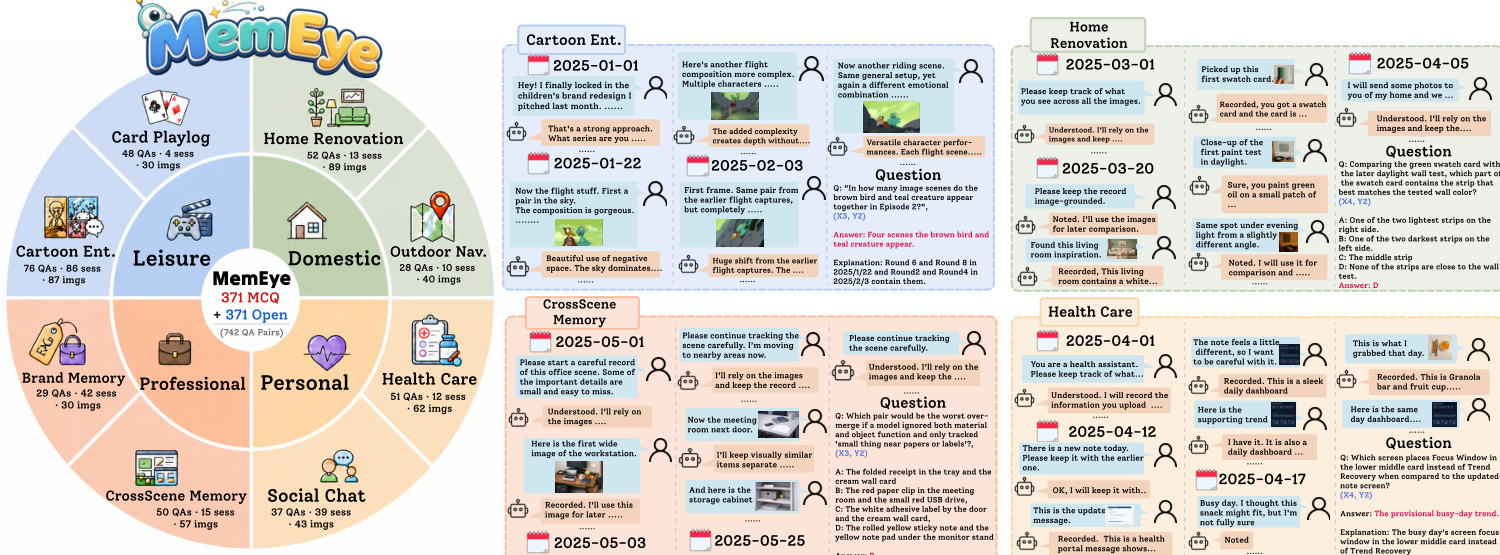
Dataset Overview The authors present MemEye, a vision-centric benchmark designed to evaluate long-horizon multimodal agent memory. The dataset comprises 371 questions distributed across 221 sessions, 848 dialogue rounds, and 438 images. Each question is provided in mirrored multiple-choice and open-ended formats to support diverse evaluation setups.
Composition and Sources The benchmark spans eight tasks grouped into four life-scenario domains: Leisure, Domestic, Professional, and Personal. Image provenance varies by task and includes archival, public, and generated media. Specific sources include the Pitt Image Ads dataset for Brand Memory, public-domain comic strips and Seed-Story for Cartoon Entertainment, stock interior-design photographs for Home Renovation, HTML-rendered screenshots based on Cardiverse for Card Playlog, StyleGAN faces combined with PIL-rendered UI for Social Chat, dashcam frames from the Japan Open Driving Dataset for Outdoor Navigation, and AI-generated images via DALL-E for CrossScene Memory and Health Care. The collection covers diverse image types such as photographs, screenshots, comic panels, and interface renderings.
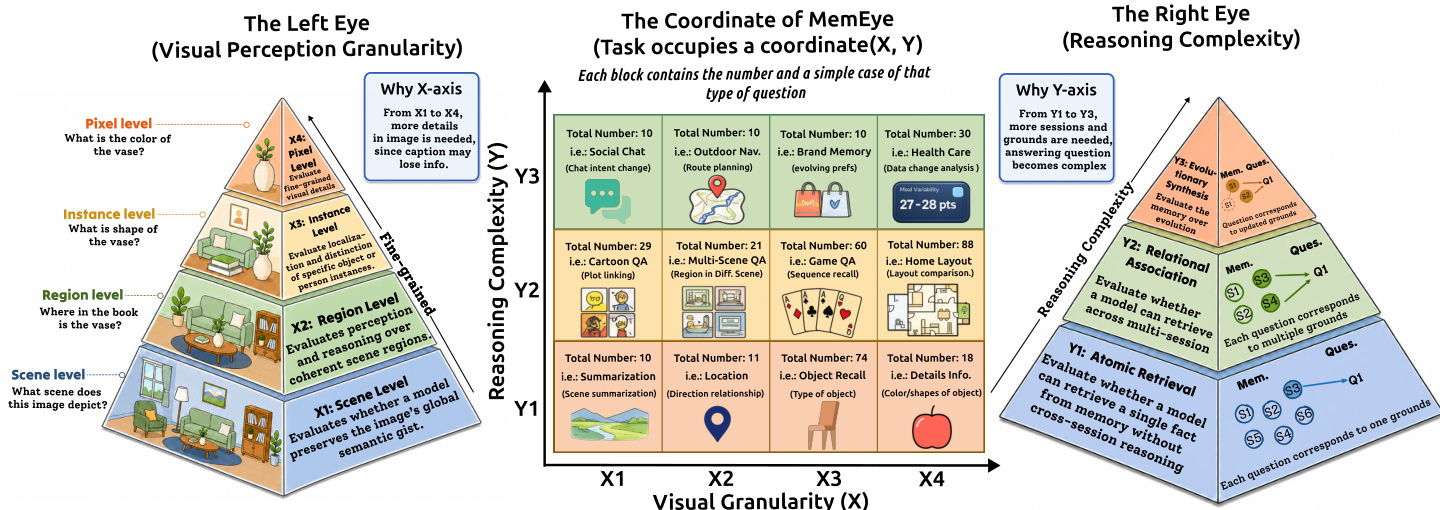
Taxonomy and Metadata Every question is assigned an (X, Y) coordinate using a highest-bottleneck rule that captures the finest required visual evidence and the deepest memory operation. The X-axis measures visual evidence granularity with four levels: X1 for scene-level gist, X2 for region-level spatial details, X3 for instance-level identification, and X4 for pixel-level attributes like exact color, text, or texture. The Y-axis assesses memory reasoning depth with three levels: Y1 for atomic retrieval of a single fact, Y2 for relational association of non-conflicting distributed clues, and Y3 for evolutionary synthesis involving updates, conflicts, or state overrides. The dataset includes metadata on taxonomy distribution and marks each task by whether visual evidence is archival or generated.
Processing and Filtering The authors apply three rigorous filtering mechanisms to ensure the benchmark tests visual memory rather than text solvability or foundation model recognition. First, they eliminate answer leakage by testing questions against dialogue text alone and removing items solvable without visual evidence. Second, they test for visual bypassability by replacing images with minimal captions and discarding questions that remain answerable with text descriptions. Third, they control for inherent difficulty by providing images with answer-relevant context to isolate answerability from memory constraints, removing items that fail due to base model limitations. The authors also mitigate multiple-choice bias by creating four rotated variants for each question where the correct answer cycles through all options.
Usage and Evaluation The dataset is structured for evaluation and includes prompt templates for multimodal multiple-choice answering, text-plus-caption answering, question generation, and taxonomy annotation. Evaluation employs an LLM-as-a-judge framework with a detailed rubric that scores responses on a scale from 0 to 1 based on semantic equivalence, handling of negations, identity matching, and avoidance of hallucinations. The authors provide JSON output formats for question generation and annotation to standardize metadata construction and ensure consistent labeling of visual and reasoning requirements.
Method
The authors leverage a two-dimensional evaluation framework to structure MemEye, organizing tasks along a coordinate system defined by visual perception granularity and reasoning depth. The X-axis, referred to as visual granularity, spans four levels from coarse to fine: scene-level (X1), region-level (X2), instance-level (X3), and pixel-level (X4). These levels correspond to the scale at which visual evidence must be processed, ranging from global scene semantics to fine-grained pixel details such as color and texture. The Y-axis represents reasoning complexity, capturing the depth of cognitive processing required to retrieve and synthesize evidence. It is structured into three levels: Y1 (Atomic Retrieval), where a single evidence unit suffices; Y2 (Relational Association), which requires combining multiple non-redundant evidence units; and Y3 (Evolutionary Synthesis), where temporal ordering and state updates across clues are necessary to resolve the answer.
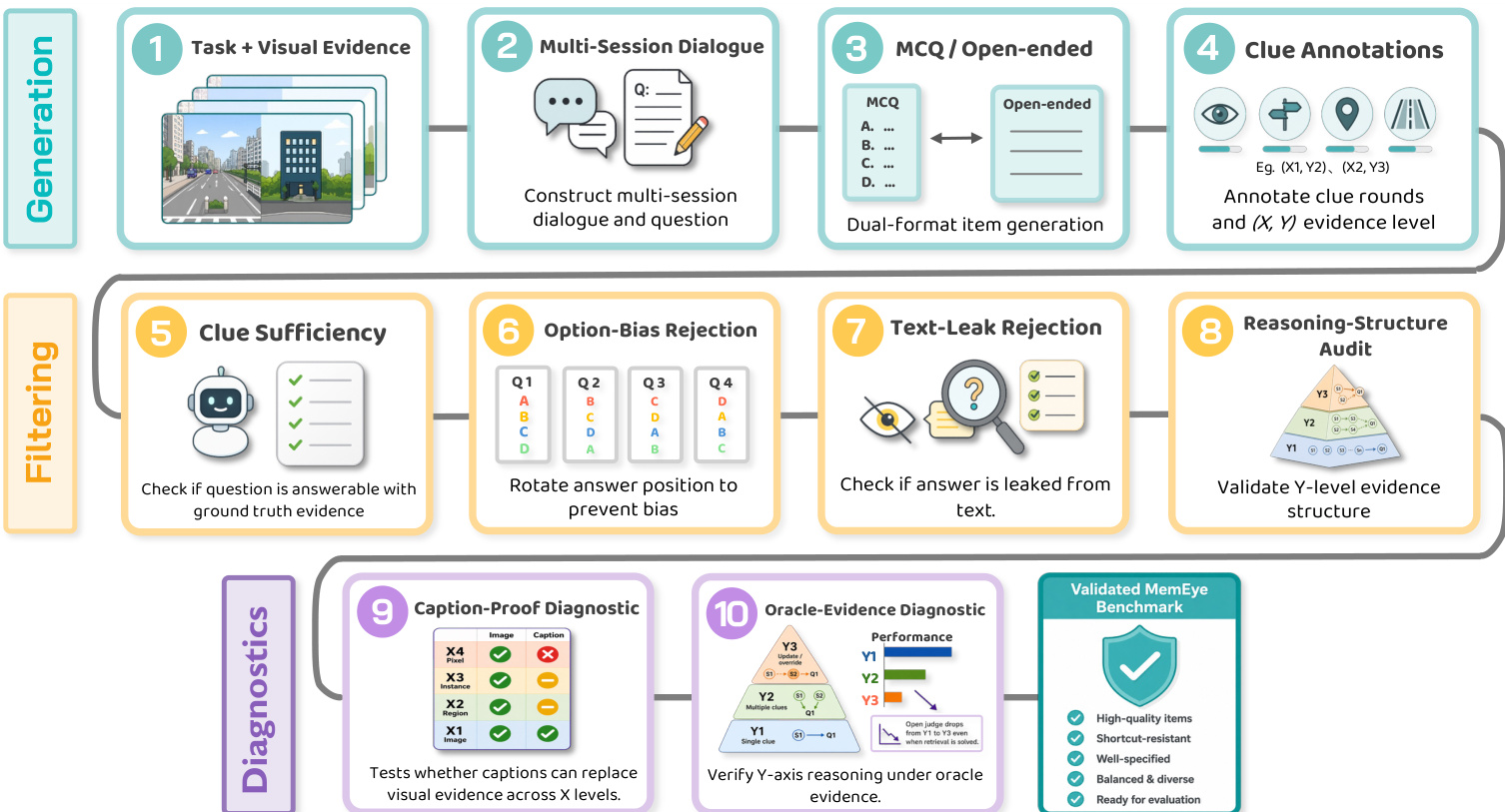
The framework is implemented through a multi-stage pipeline that begins with task and visual evidence generation, followed by the construction of multi-session dialogues and the creation of multiple-choice or open-ended questions. Each question is annotated with its corresponding (X,Y) granularity and complexity levels. The process then enters a rigorous filtering phase, starting with a clue sufficiency check to ensure the question can be answered using ground-truth evidence. This is followed by option-bias rejection, where answer positions are rotated to prevent response bias. A text-leakage filter checks whether the answer can be inferred solely from the text, while a bypass filter evaluates whether a short caption can replace the full image without compromising the question's validity. The difficulty calibration stage ensures that the question maintains appropriate challenge levels across the taxonomy.
A reasoning-structure audit validates that the question adheres to the intended Y-level evidence structure, ensuring that Y1 items require only atomic retrieval, Y2 items involve relational association across multiple clues, and Y3 items necessitate evolutionary synthesis over time. The pipeline concludes with diagnostic evaluations: a caption-proof diagnostic tests whether captions can substitute visual evidence across X levels, and an oracle-evidence diagnostic verifies that the Y-axis reasoning is dependent on multimodal evidence by testing performance under oracle conditions. The final output is a validated MemEye benchmark characterized by high-quality, shortcut-resistant, well-specified, and diverse items ready for evaluation.
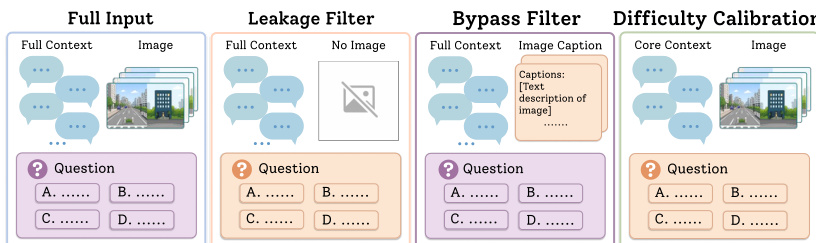
Experiment
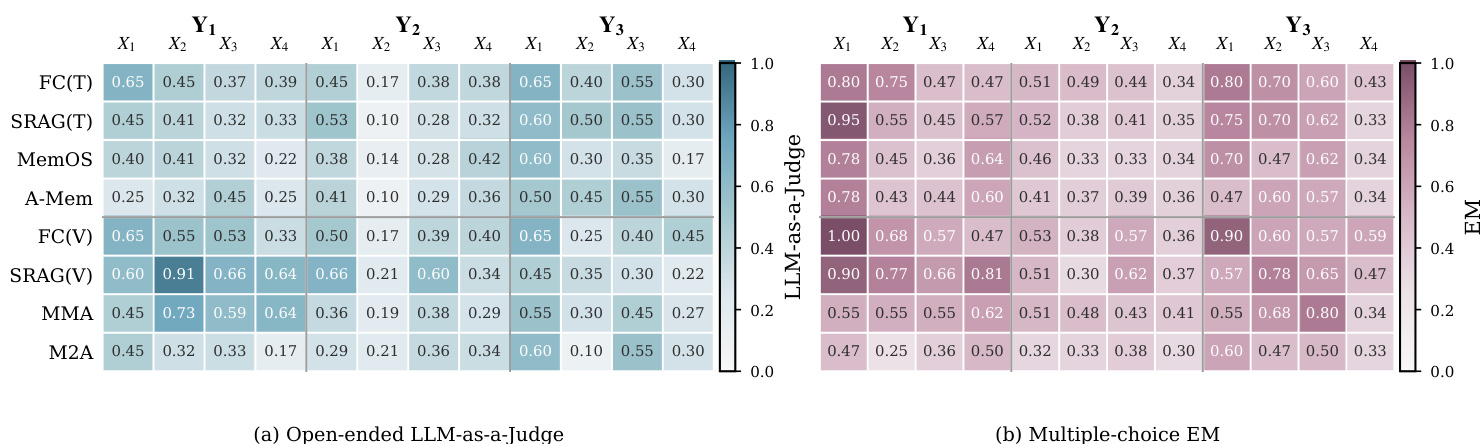
The study evaluates thirteen memory architectures across four vision-language models using the MemEye benchmark, which organizes tasks along a visual granularity axis and a reasoning depth axis, validated through caption-proof and oracle-evidence diagnostics. Results reveal that current systems struggle with two primary bottlenecks: converting images to text causes significant loss of fine-grained visual details, while retrieval-based approaches frequently select temporally stale evidence when tracking evolving visual states. Consequently, effective long-term multimodal memory requires a hybrid approach that preserves native visual evidence alongside structured textual state records, supplemented by filtering mechanisms that prioritize temporally valid information over semantic similarity.
{"summary": "The authors analyze the performance of various memory systems on a benchmark that evaluates both reasoning depth and visual granularity. The results show that systems perform differently across the two dimensions, with multimodal methods generally outperforming text-based ones in fine-grained visual tasks, while text-based methods show advantages in reasoning over evolving states. The analysis highlights a trade-off between preserving visual evidence and selecting valid states in dynamic memory environments.", "highlights": ["Multimodal methods outperform text-based methods in fine-grained visual tasks but struggle with evolving state selection.", "Text-based methods are more competitive in reasoning over evolving states, where the ability to track updates and conflicts is crucial.", "The benchmark reveals a trade-off between visual evidence preservation and state selection, indicating that no single method excels across both dimensions."]
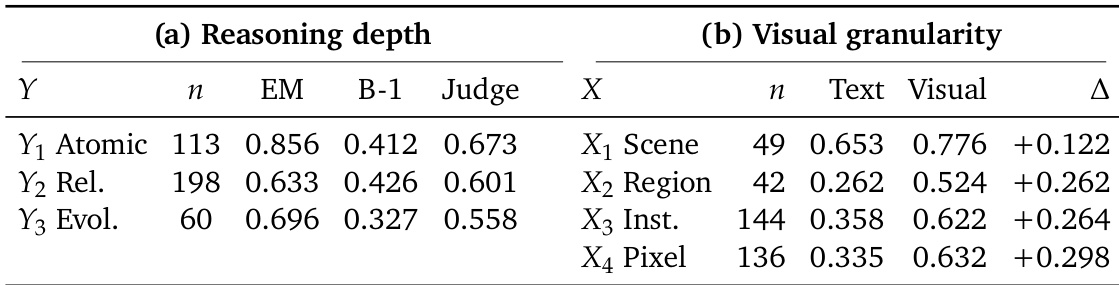
The authors analyze memory system performance across different levels of visual evidence granularity and reasoning depth, identifying that current systems struggle with fine-grained visual information and evolving visual states. Multimodal methods generally outperform text-based ones in preserving visual details, but retrieval-based systems often fail to select the most recent valid state when evidence changes over time. Multimodal memory systems outperform text-based systems in preserving fine-grained visual evidence, especially at higher visual granularity levels. Retrieval-based methods often fail to select the most recent valid visual state, even when relevant evidence is retrieved. Text-based memory systems can better handle evolving visual states by maintaining structured state records, but they lose fine-grained visual details.
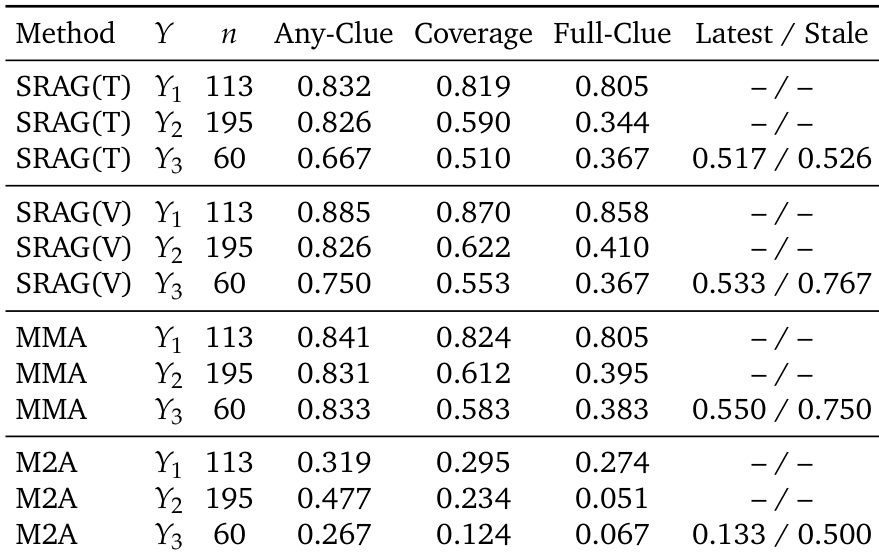
The authors analyze the performance of various memory systems on a benchmark that evaluates both visual evidence granularity and reasoning depth. The results show that multimodal methods generally outperform text-based methods, especially in tasks requiring fine-grained visual details. However, the performance of all systems declines in tasks that require tracking evolving visual states over time, indicating a bottleneck in selecting valid evidence from a dynamic memory history. Multimodal memory methods outperform text-based methods in tasks requiring fine-grained visual evidence. Performance drops across all systems in tasks that require tracking evolving visual states over time. No method fully addresses both visual evidence preservation and evolving state selection simultaneously.
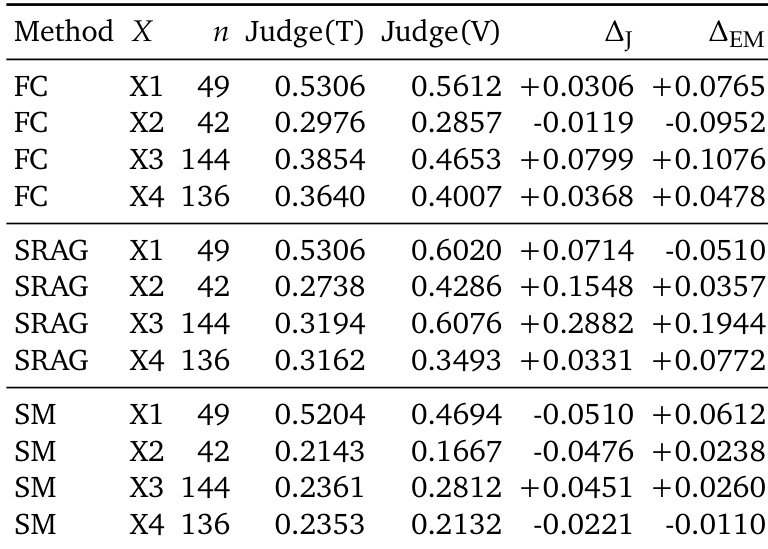
The experiment evaluates multiple memory systems across a two-axis framework that measures visual evidence granularity and reasoning depth over memory. Results show that current systems struggle to handle both fine-grained visual details and evolving visual states simultaneously, with performance varying significantly between text-based and multimodal approaches depending on the task complexity. The analysis reveals distinct failure modes related to visual information loss and state selection, indicating that effective memory systems must combine both visual and textual evidence with mechanisms for selecting valid evidence over time. Current memory systems fail to handle both fine-grained visual evidence and evolving visual states simultaneously, showing distinct failure modes in different parts of the evaluation matrix. Multimodal methods outperform text-based methods on fine-grained visual tasks, while text-based methods show better performance on evolving-state reasoning, indicating a trade-off between visual fidelity and state tracking. The results suggest that future memory systems need to combine image-based and text-based memory with mechanisms for filtering and selecting valid evidence from long, diverse histories.
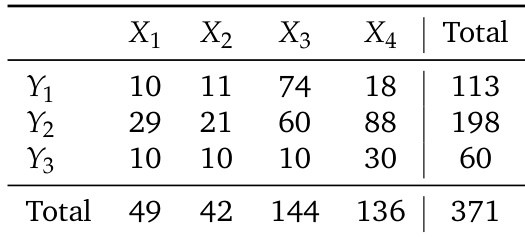
The authors evaluate multiple memory systems across a two-dimensional benchmark that assesses visual evidence granularity and reasoning depth over memory. Results show that no single method performs well across all conditions, with multimodal methods excelling in fine-grained visual tasks and text-based methods showing better performance in evolving state reasoning. The analysis reveals that current systems struggle with both preserving detailed visual information and selecting the most relevant updated evidence from long histories. Multimodal methods outperform text-based methods in fine-grained visual tasks but struggle with evolving state reasoning. Text-based methods are more effective in reasoning over evolving visual states but lose fine-grained visual details. Current memory systems fail to simultaneously handle both visual evidence preservation and temporal state selection, indicating a need for combined memory architectures.
The experiments evaluate multiple memory systems using a two-dimensional benchmark that validates performance across visual evidence granularity and reasoning depth over dynamic memory. The analysis reveals a distinct qualitative trade-off, with multimodal architectures excelling at preserving fine-grained visual details while text-based methods prove more effective at tracking evolving states. Ultimately, no single approach successfully balances both requirements, indicating that future systems must integrate visual and textual memory with dedicated mechanisms for filtering valid evidence across temporal histories.