Command Palette
Search for a command to run...
RepoZero : Les LLMs peuvent-ils générer un dépôt de code à partir de zéro ?
RepoZero : Les LLMs peuvent-ils générer un dépôt de code à partir de zéro ?
Zhaoxi Zhang Yiming Xu Jiahui Liang Weikang Li Yunfang Wu
Résumé
Les grands modèles de langage (LLM) ont récemment fait preuve de progrès remarquables dans la génération de code. Pourtant, leur capacité à construire des dépôts logiciels complets à partir de rien reste mal comprise. Un goulot d’étranglement fondamental réside dans l’absence d’évaluation vérifiable et évolutive : les benchmarks existants se concentrent soit sur l’édition par patch, soit s’appuient sur des jugements humains ou basés sur des LLM, introduisant ainsi des biais et limitant la reproductibilité. Dans ce travail, nous présentons RepoZero, le premier benchmark permettant une vérification entièrement automatisée et basée sur l’exécution de la génération de dépôts à partir de zéro. Notre idée centrale est de reformuler la génération comme une reproduction de dépôt : à partir des seules spécifications d’API, un agent doit réimplémenter un dépôt entier de telle sorte que son comportement corresponde à celui de l’implémentation originale. Cette conception permet une validation stricte en boîte noire via l’équivalence des sorties, tout en soutenant naturellement la construction à grande échelle grâce à la réutilisation de dépôts open source existants. Pour atténuer davantage les fuites de données et les solutions de facilité (shortcut solutions), nous introduisons des contraintes inter-langages et un protocole d’évaluation isolé (sandboxed). Sur la base de ce benchmark, nous proposons le cadre ACE (Agentic Code-Test Evolution), qui effectue une génération itérative de tests et un raffinement piloté par les erreurs, permettant ainsi une mise à l’échelle efficace pendant l’inférence (test-time scaling) pour la synthèse à l’échelle du dépôt.
One-sentence Summary
This work presents RepoZero, the first benchmark enabling fully automated, execution-based verification of repository-level generation from scratch by reformulating the task as repository reproduction given only API specifications, and proposes an Agentic Code-Test Evolution (ACE) framework that employs iterative test generation and error-driven refinement to enable effective test-time scaling for repository-level synthesis.
Key Contributions
- This work presents RepoZero, the first benchmark enabling fully automated, execution-based verification of repository-level generation from scratch by reformulating the task as repository reproduction based on API specifications.
- Cross-language constraints and a sandboxed evaluation protocol are introduced to mitigate data leakage and prevent shortcut solutions during the evaluation process.
- An Agentic Code-Test Evolution (ACE) framework is proposed to perform iterative test generation and error-driven refinement, which enables effective test-time scaling for repository-level synthesis.
Introduction
Large Language Models have advanced in code generation but constructing complete software repositories from scratch lacks reliable evaluation methods. Existing benchmarks often rely on patch-based editing or subjective judgments that introduce bias and risk data leakage. To overcome these challenges, the authors present RepoZero, the first benchmark enabling fully automated and execution-based verification of repository-level generation. This approach reformulates generation as repository reproduction where agents re-implement functionality to match original behavior using API specifications. Additionally, they introduce an Agentic Code-Test Evolution framework that leverages iterative test generation and error-driven refinement to improve synthesis capabilities.
Dataset

-
Dataset Composition and Sources
- The authors present RepoZero, a benchmark designed to evaluate end-to-end repository generation capabilities.
- The dataset comprises two cross-language subsets derived from manually curated open-source repositories on GitHub.
- Sources are selected based on strict criteria including determinism, open-source integrity, and architectural complexity to ensure multi-file structures.
-
Subset Details and Statistics
- RepoZero-Py2JS: Contains 400 samples requiring re-implementation of Python repositories in JavaScript.
- RepoZero-C2Rust: Contains 200 samples requiring re-implementation of C/C++ repositories in Rust.
- Difficulty Levels: Samples are partitioned into Easy, Medium, and Hard categories using majority voting from three LLMs to estimate lines of code, API counts, and input/output complexity.
-
Data Processing and Filtering
- Test File Generation: An LLM agent generates test files invoking 1 to 20 API calls per file based on strict prompting.
- Test Case Verification: Each candidate test case executes 20 times to ensure stability.
- Filtering Rules: Samples are discarded if they trigger runtime exceptions or produce non-deterministic outputs like memory addresses or time-dependent variables.
- Minimum Threshold: A sample is only retained if it contains at least 10 valid test cases.
-
Usage and Maintenance
- The benchmark serves as an evaluation framework rather than training data to mitigate data leakage.
- The pipeline remains automated after initial repository selection to allow continuous updates and expansion.
- Ground truth is established via stable output verification from the executed test cases.
Method
The proposed framework operates through a two-stage pipeline comprising dataset construction and model evaluation. The authors leverage an automated agent-based workflow to generate high-quality benchmarks and subsequently evaluate model performance on migration tasks.
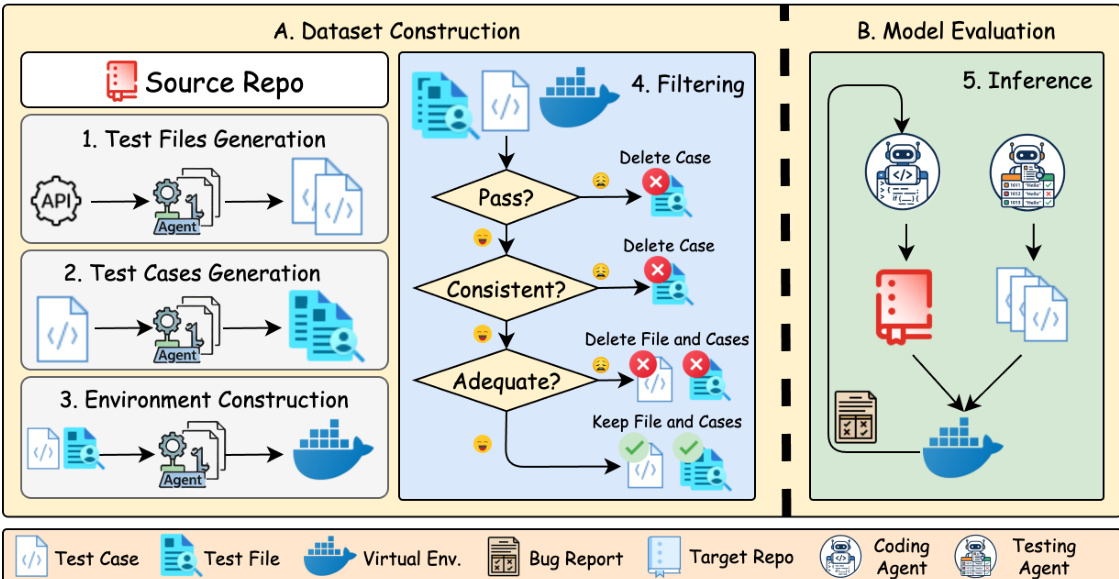
The process begins with Dataset Construction, illustrated in the left panel. Starting from a source repository, the system employs an agent to perform three sequential generation tasks. First, test files are generated to establish the necessary structure. Second, specific test cases are synthesized to validate functionality. Third, a virtual environment is constructed to ensure the code can be executed in an isolated context. Following generation, a rigorous filtering mechanism is applied. This stage evaluates the generated artifacts based on three criteria: whether the tests pass, if the behavior is consistent with the source, and if the coverage is adequate. Items failing any of these checks are discarded, ensuring only high-quality data proceeds.
In the Model Evaluation phase, shown in the right panel, the system enters an inference loop. This stage utilizes two specialized agents: a Coding Agent and a Testing Agent. The Coding Agent is tasked with generating the target implementation based on a bug report and the target repository, while the Testing Agent validates the output. The agents operate under strict prompting guidelines designed to ensure fidelity during cross-language migration. For instance, in Python to Node.js migration tasks, the prompt enforces the use of pure JavaScript with ES Modules, requiring that all library and entry files use the .mjs suffix.
Furthermore, the generation process mandates that command-line arguments be parsed identically to the source language using process.argv, ensuring that node test.mjs --arg val behaves identically to python test.py --arg val. The logic, numeric precision, and string formatting must match exactly, with console.log output required to be byte-for-byte identical to Python print statements. The agents are also restricted to using only Node.js built-in modules, prohibiting external npm packages to maintain a zero-dependency environment. Finally, the project structure is enforced to split code into modules with explicit exports, and the agents must implement logic as black boxes, inferring behavior from interfaces rather than reading source code directly.
Experiment
This study evaluates coding agents using OpenHands-bash and Mini-SWE-Agent within isolated Docker containers to enforce rigorous black-box testing and prevent evaluation cheating. Experimental results show that while overall performance is suboptimal, Mini-SWE-Agent outperforms OpenHands-bash due to superior context engineering, with Claude-4.6-Sonnet achieving the highest pass rates across benchmarks. Additionally, the ACE framework demonstrates that integrating dynamic test generation during inference significantly enhances success by resolving corner cases and prioritizing semantic correctness over simple code runnability.
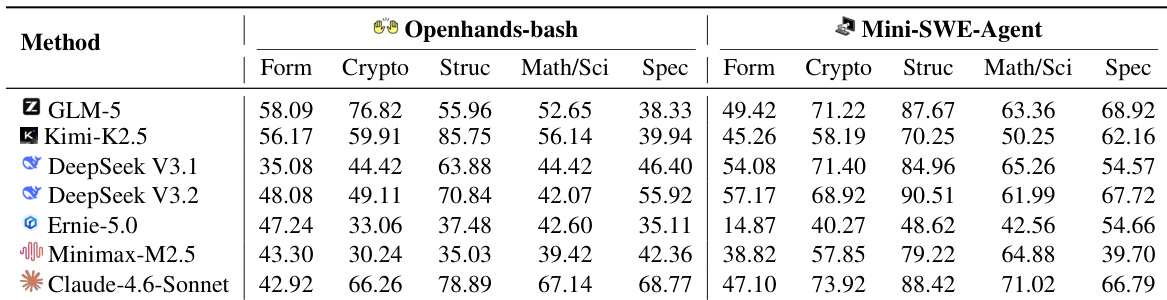
The authors assess multiple large language models using OpenHands-bash and Mini-SWE-Agent scaffolds across five functional domains including cryptography and data structures. The evaluation reveals that Mini-SWE-Agent generally outperforms OpenHands-bash, while Claude-4.6-Sonnet achieves top-tier results across most categories. Mini-SWE-Agent generally yields higher performance scores than OpenHands-bash across the tested models. Claude-4.6-Sonnet demonstrates superior capabilities in mathematical and specialized domains compared to other models. Newer model iterations such as DeepSeek V3.2 show performance improvements over earlier versions like V3.1 in several categories.
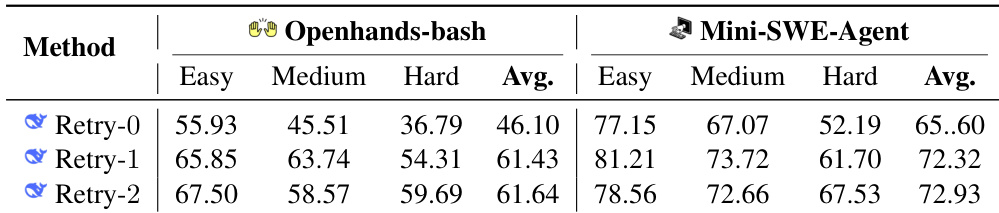
The experiment evaluates the DeepSeek V3.1 backbone model on a Py2JS benchmark using Openhands-bash and Mini-SWE-Agent scaffolds. It assesses performance across varying task difficulties and test-time scaling strategies defined by the number of retry iterations. Mini-SWE-Agent consistently outperforms Openhands-bash across all difficulty levels and retry configurations. Performance improves significantly when moving from zero retries to one retry, with diminishing returns for a second retry. Task difficulty inversely correlates with success rates, as performance drops from Easy to Hard categories.
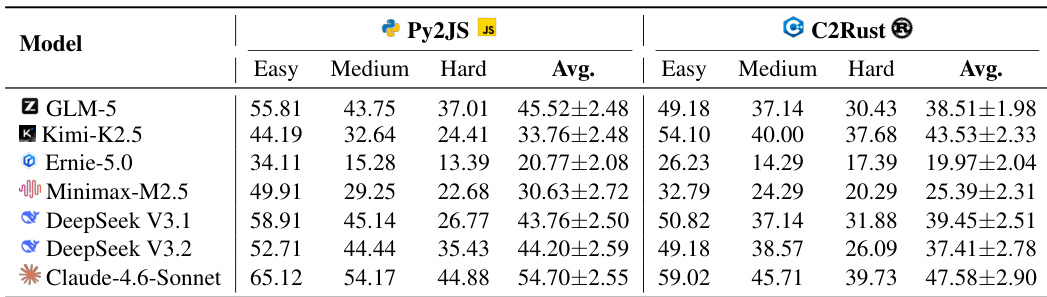
The authors evaluate various large language models using the Mini-SWE-Agent scaffold on the RepoZero benchmark, focusing on Python-to-JavaScript and C-to-Rust translation tasks. The results are categorized by difficulty levels, demonstrating that while newer models generally achieve higher pass rates, performance consistently declines as task complexity increases. Claude-4.6-Sonnet achieves the highest pass rates across both translation benchmarks compared to other models. Performance generally degrades as task difficulty moves from easy to hard categories for all evaluated models. Newer iterations of model families, such as DeepSeek V4 and Kimi-K2.6, show performance improvements over their previous versions.
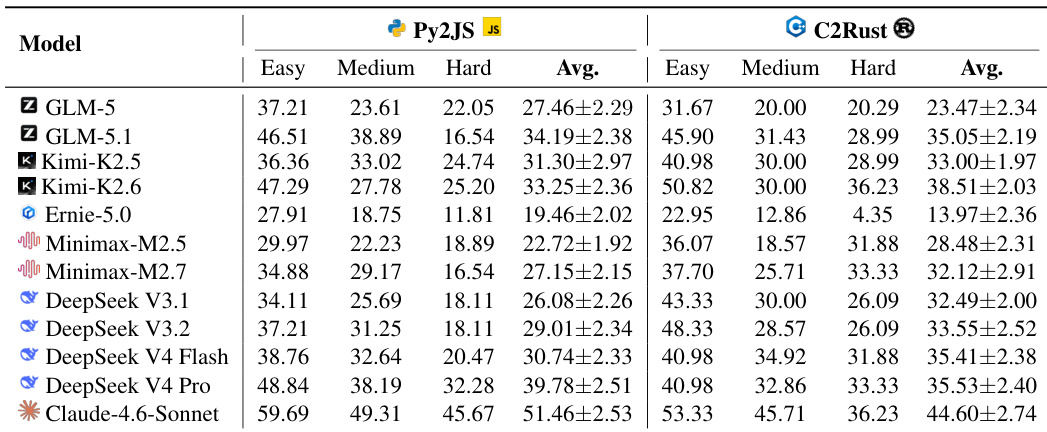
The authors evaluate various large language models on the RepoZero benchmark using the Mini-SWE-Agent scaffold to assess their ability to port code between Python and JavaScript as well as C and Rust. The results demonstrate that Claude-4.6-Sonnet consistently achieves the highest pass rates across all difficulty levels and translation tasks, while Ernie-5.0 records the lowest performance. Generally, models exhibit higher success rates on Python-to-JavaScript tasks compared to C-to-Rust tasks, and performance degrades as task difficulty increases. Claude-4.6-Sonnet achieves the highest average pass rates in both Py2JS and C2Rust tasks compared to other models. Performance consistently declines as task difficulty increases from Easy to Hard across all models. Python-to-JavaScript porting tasks yield higher success rates than C-to-Rust porting for the majority of evaluated models.
The experiment evaluates the impact of iterative refinement on coding agents using the DeepSeek V3.1 backbone, comparing OpenHands-bash and Mini-SWE-Agent. Results indicate that increasing the number of retry cycles significantly improves performance for both frameworks. Additionally, Mini-SWE-Agent consistently achieves higher success rates than OpenHands-bash across all difficulty levels. Increasing retry iterations from 0 to 2 leads to consistent performance improvements for both agents Mini-SWE-Agent consistently outperforms OpenHands-bash across easy, medium, and hard difficulty levels Performance declines as task difficulty increases, with hard tasks yielding the lowest success rates

The authors evaluate multiple large language models using OpenHands-bash and Mini-SWE-Agent scaffolds across code translation and functional benchmarks. Mini-SWE-Agent consistently outperforms OpenHands-bash, and Claude-4.6-Sonnet demonstrates superior capabilities compared to other models across varying difficulty levels. Performance trends show that success rates decline with increased task difficulty but improve with additional retry cycles, while newer model iterations generally surpass earlier versions.