Command Palette
Search for a command to run...
Tutoriel En Ligne | L'équipe De l'Université Des Sciences Et Technologies De Hong Kong Publie En Open Source Le Premier Framework Déterministe De Profondeur Vidéo DVD, Atteignant Des Résultats De Pointe Sans Aucun exemple.

L'estimation de profondeur est l'une des tâches les plus fondamentales et critiques en vision 3D. De la conduite autonome à la navigation robotique, en passant par la réalité augmentée/virtuelle, les jumeaux numériques et la génération de contenu vidéo, les systèmes doivent comprendre avec précision les relations spatiales entre les objets et la caméra dans une scène. Cependant, l'estimation de profondeur vidéo se heurte depuis longtemps à une contradiction majeure : les méthodes génératives, représentées par les modèles de diffusion, possèdent de solides capacités de compréhension sémantique et peuvent inférer des structures de scène complexes à partir d'une grande quantité de données pré-entraînées, mais leurs résultats sont souvent affectés par des processus d'échantillonnage aléatoire, ce qui les rend sujettes à des illusions géométriques, à des dérives d'échelle et à une instabilité temporelle ; quant aux méthodes discriminatives traditionnelles, bien que présentant un meilleur déterminisme, elles dépendent fortement de données étiquetées à grande échelle, ce qui entraîne des coûts d'entraînement élevés et une capacité de généralisation limitée dans les scènes complexes.
Pour remédier à ce problème majeur du secteur, l'équipe de l'Université des sciences et technologies de Hong Kong (Guangzhou) a proposé le DVD (estimation déterministe de la profondeur vidéo).Pour la première fois, un modèle de diffusion vidéo pré-entraîné a été transformé de manière déterministe en un estimateur de profondeur vidéo à propagation directe unique.Contrairement aux modèles de diffusion traditionnels qui nécessitent plusieurs itérations pour générer des résultats, le DVD permet de prédire la profondeur en une seule étape. Ceci améliore considérablement l'efficacité de l'inférence et élimine complètement le problème d'illusion géométrique dû à l'échantillonnage aléatoire, garantissant ainsi la cohérence temporelle et la stabilité structurelle des séquences vidéo.
Plus important encore,Le DVD a permis de préserver avec succès une grande quantité de connaissances géométriques et sémantiques préalables contenues dans le modèle vidéo de base.Grâce à des mécanismes d'ancrage structurel innovants et à la technologie de correction de variété latente (LMR), le modèle peut récupérer avec précision les contours des objets, les textures à haute fréquence et les détails de mouvement tout en maintenant la stabilité globale de la scène, améliorant ainsi considérablement la fidélité structurelle des cartes de profondeur.
Dans de nombreux tests de référence accessibles au public, les performances zéro échantillon du DVD atteignent des niveaux de pointe (SOTA).De plus, elle a atteint un niveau de performance exceptionnel avec seulement 367 000 images de données d'entraînement, soit une réduction d'environ 163 fois par rapport aux 60 millions d'images requises par les méthodes discriminatives classiques. Ceci confirme non seulement l'énorme potentiel des modèles génératifs de base pour la compréhension géométrique, mais ouvre également une voie technique entièrement nouvelle pour la perception vidéo 3D de haute précision et à faible coût.
Pour permettre aux développeurs de découvrir rapidement les DVD, HyperAI a lancé un Notebook facile à déployer, simplifiant ainsi l'accès à des modèles de pointe en un clic. ⬇️
Exécutez en ligne :https://go.hyper.ai/w8kUO
Adresse open source :https://github.com/EnVision-Research/DVD
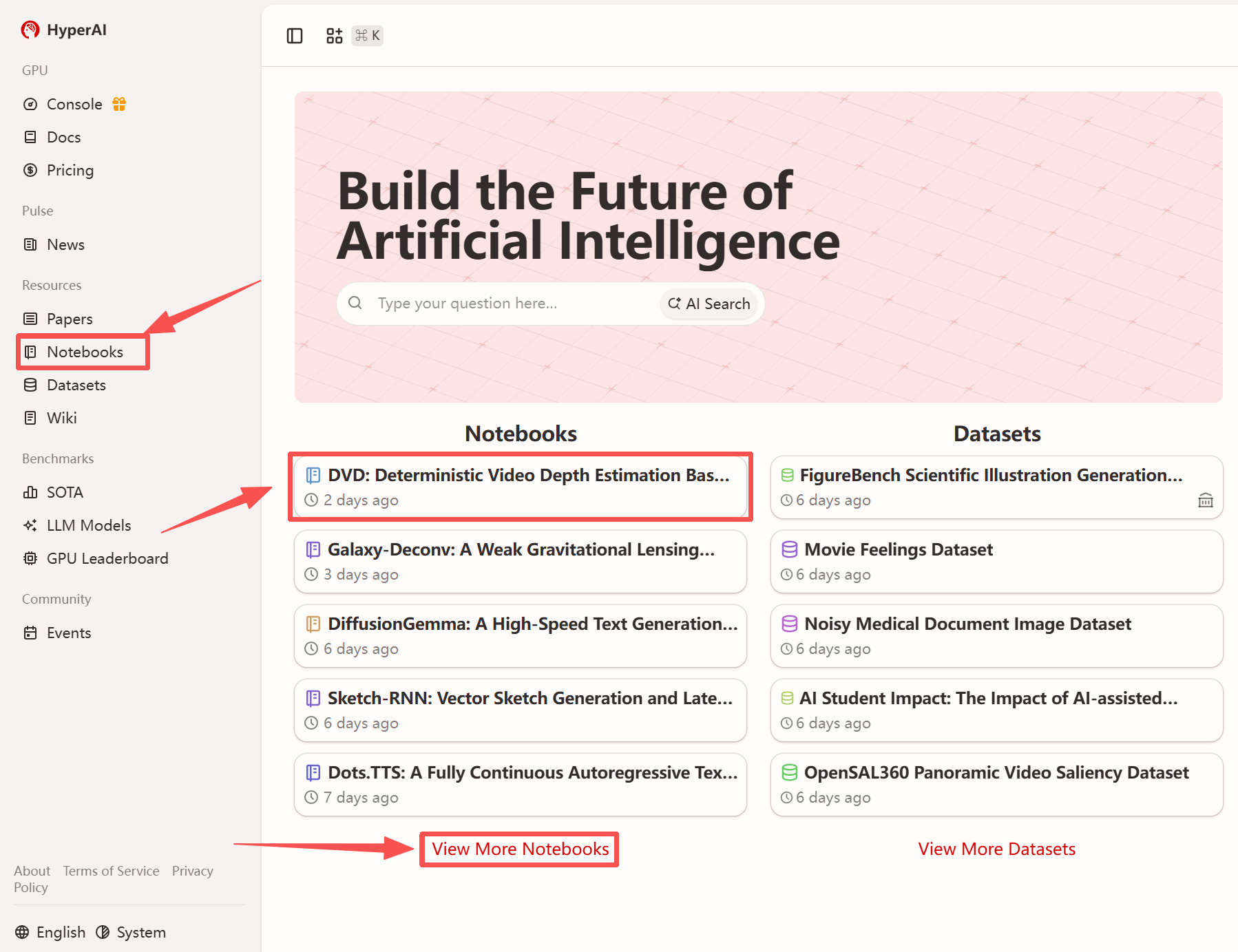
Plus de tutoriels en ligne :
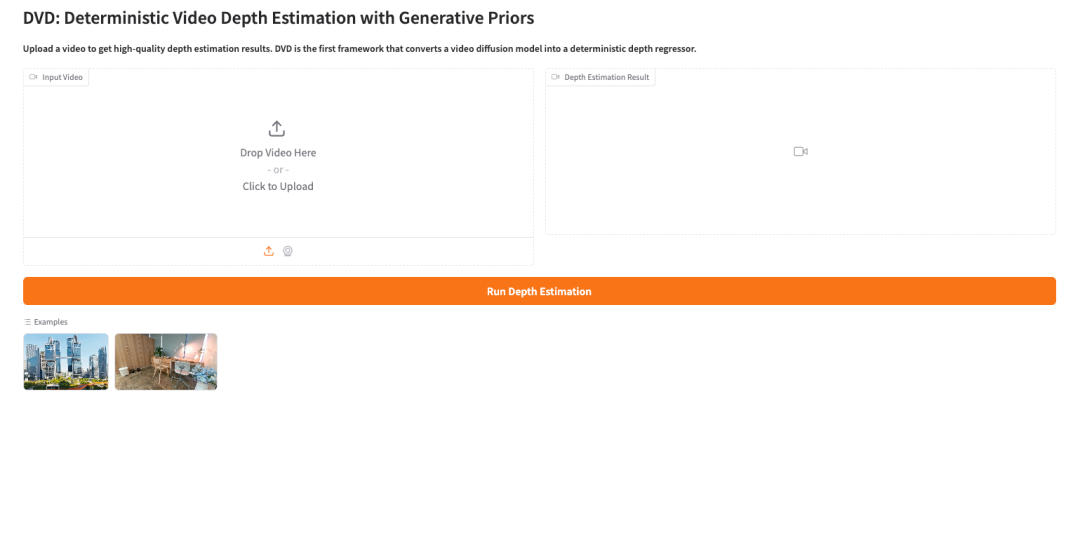
Essai de démonstration
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels » ou cliquez sur « Voir plus de tutoriels », sélectionnez « DVD : Estimation déterministe de la profondeur vidéo basée sur des a priori génératifs », puis cliquez sur « Exécuter ce tutoriel ».
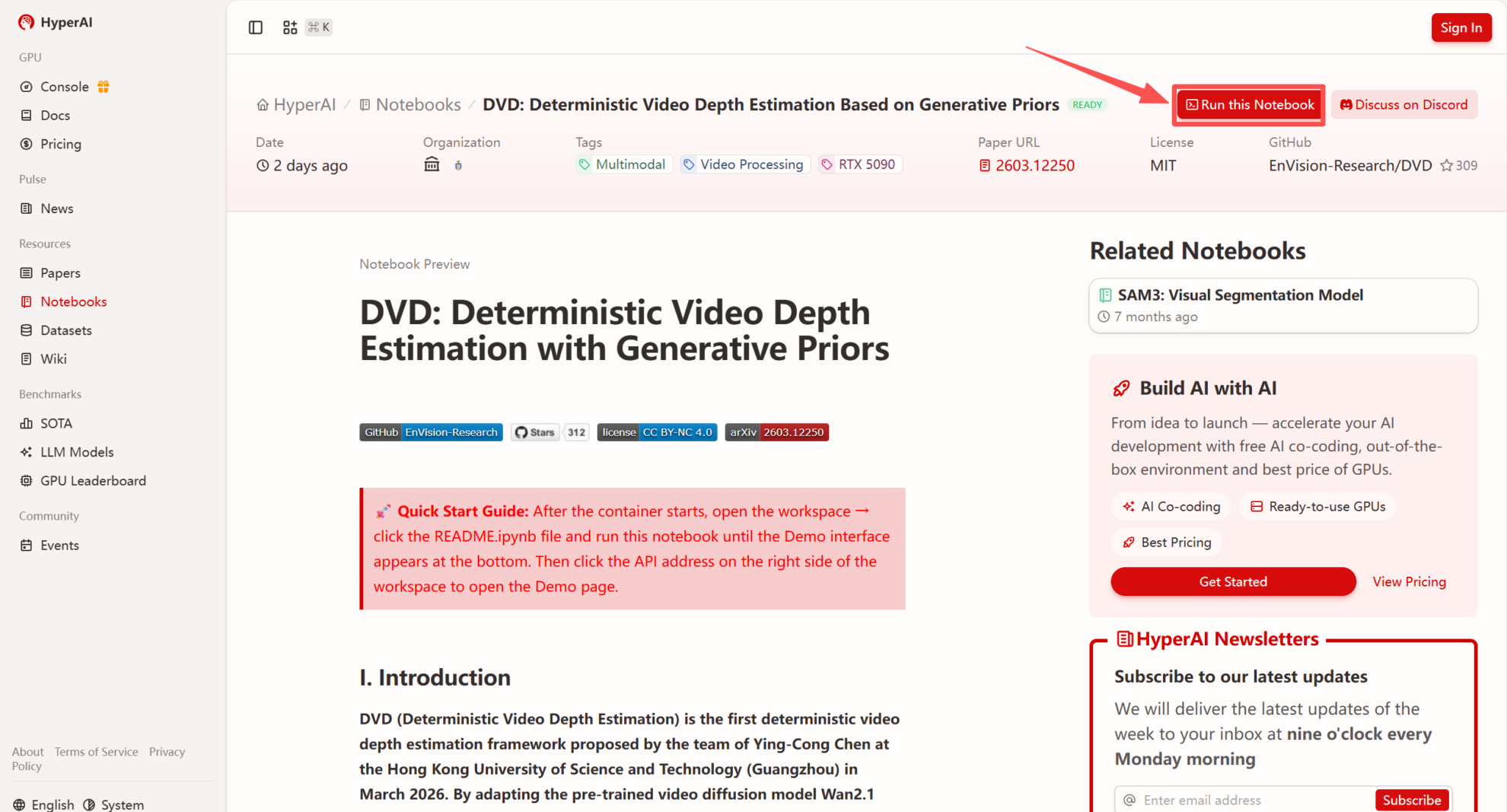
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
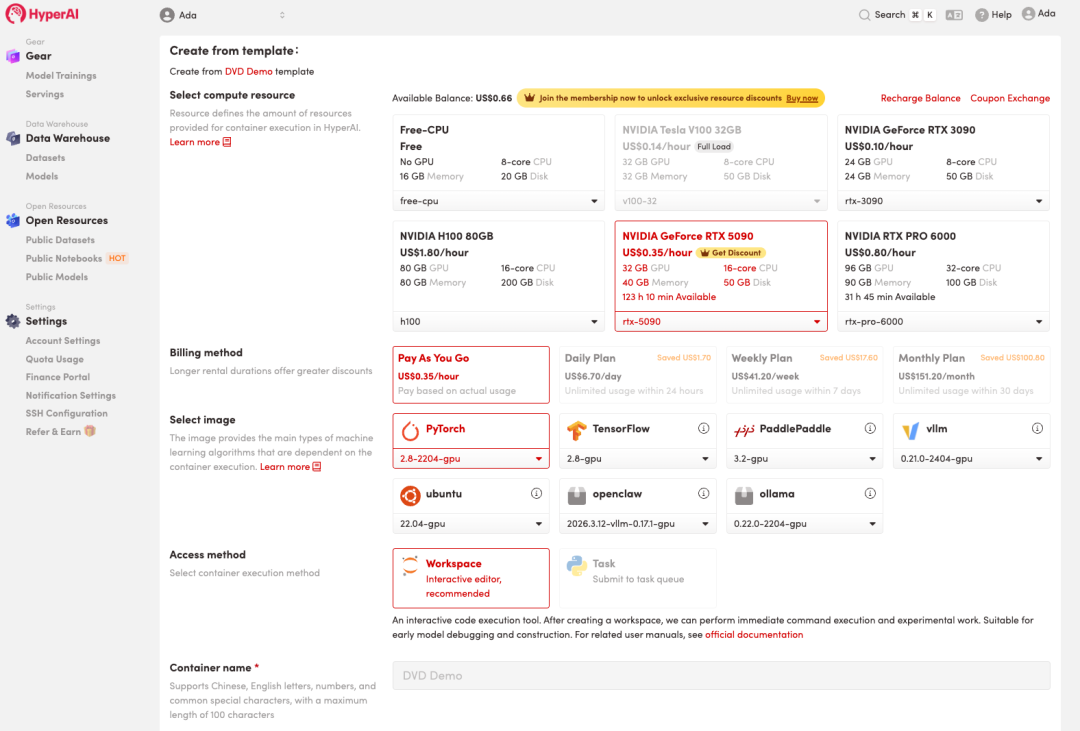
3. Sélectionnez les images « NVIDIA RTX 5090 » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
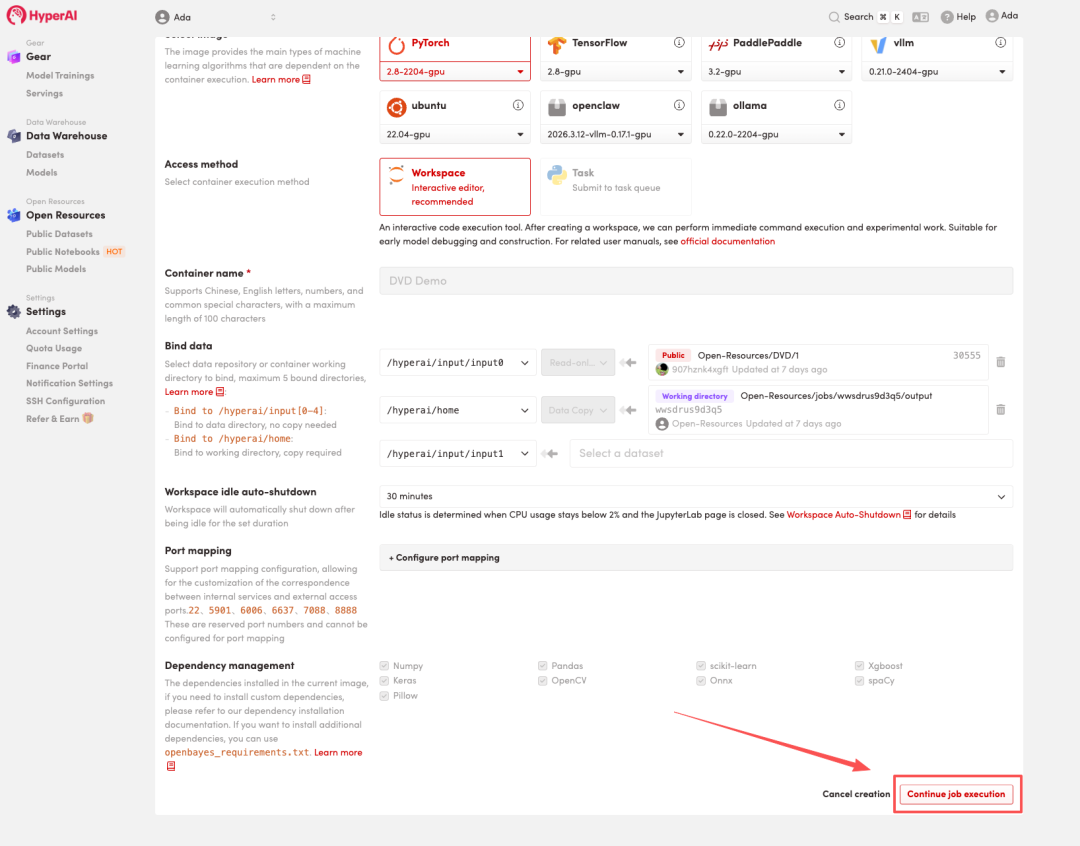
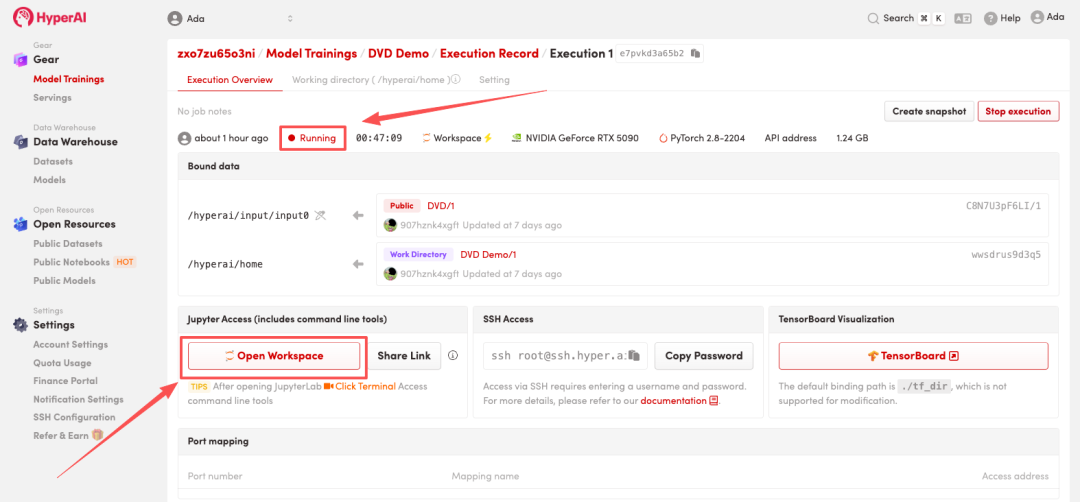
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
Affichage des effets
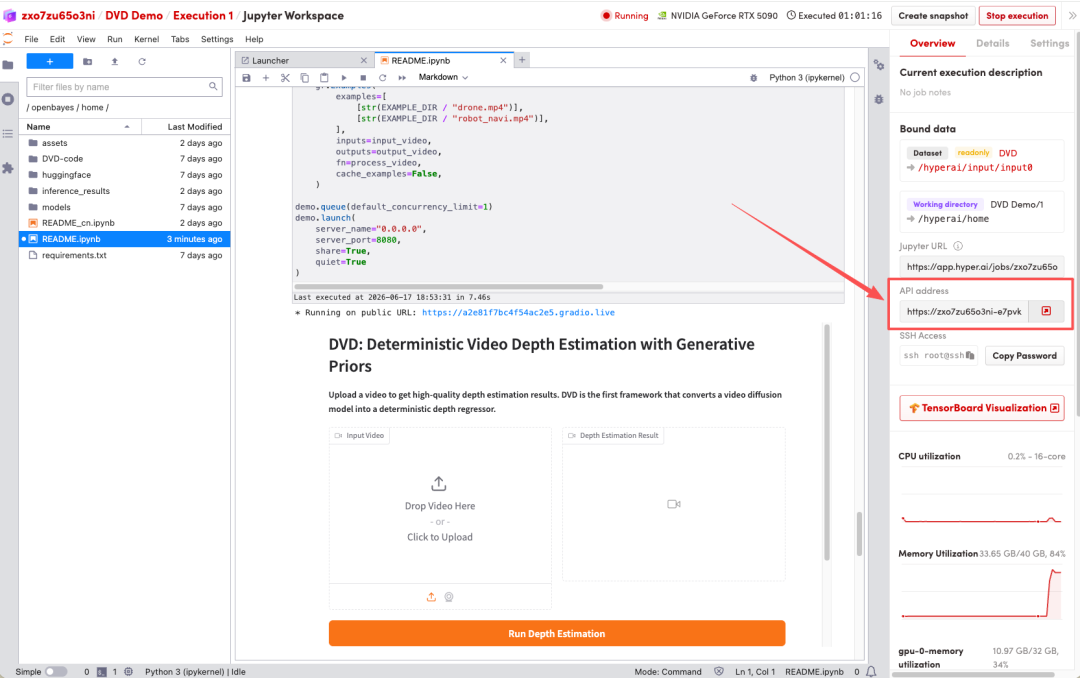
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
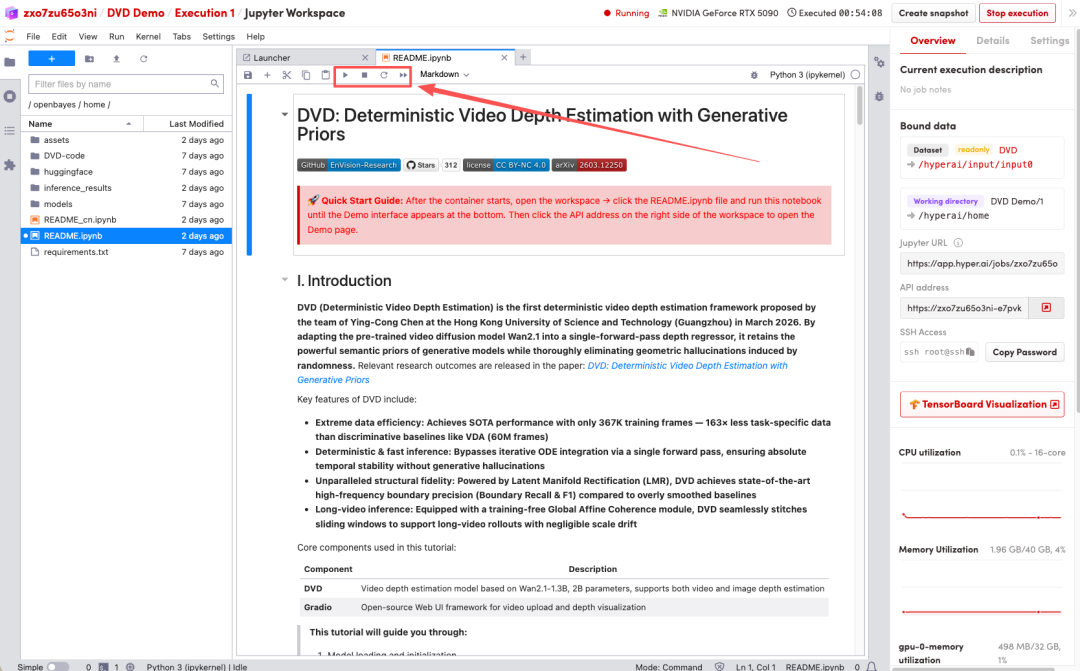
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour ouvrir l'interface de démonstration.