Command Palette
Search for a command to run...
Revue De Presse | Dernières Avancées En Apprentissage Par Renforcement À Grande Échelle : Microsoft, Google, Stanford, L’université Renmin, Xiaohongshu Et D’autres Annoncent Des Avancées Majeures Dans L’allocation De Crédit, Le Raisonnement Complexe Et L’apprentissage Par Renforcement Des Agents

Au vu des développements actuels de l'apprentissage par renforcement, qu'il s'agisse d'améliorer les capacités d'allocation de crédit dans l'inférence à longue chaîne, d'améliorer l'exploration autonome du modèle dans des environnements complexes ou de construire des systèmes d'agents intelligents dotés de capacités de planification à long terme et d'apprentissage par rétroaction, leurs objectifs principaux convergent tous vers la même direction :Dépasser les limites des récompenses rares et de la supervision statique,Il permet au modèle d'apprendre et d'évoluer en permanence grâce à l'interaction.
L'apprentissage par renforcement est une méthode qui permet à un agent intelligent d'optimiser en continu ses stratégies comportementales grâce à une boucle fermée de « perception-décision-exécution-rétroaction ». Contrairement à l'apprentissage supervisé traditionnel, qui repose sur une distribution de données fixe, l'apprentissage par renforcement met l'accent sur la capacité du modèle à apprendre par essais et erreurs lors d'interactions avec l'environnement, lui permettant ainsi de développer progressivement un mécanisme de prise de décision qui maximise les bénéfices à long terme dans des tâches dynamiques.En bref, l'apprentissage par renforcement fait passer l'intelligence artificielle de la simple « capacité à répondre aux questions » à la capacité d'« agir de manière autonome », accomplissant ainsi un bond significatif de la « génération passive » à l'« intelligence active ».
Cette semaine,HyperAI a sélectionné pour vous 6 des articles de recherche les plus récents dans le domaine de l'apprentissage par renforcement de grands modèles.L'équipe à l'origine de ce projet comprend des universités prestigieuses telles que Stanford et l'Université Renmin de Chine, ainsi que des géants de la technologie comme Microsoft, Google, Kuaishou et Xiaohongshu. Leurs articles proposent des solutions novatrices et très inspirantes pour la construction de modèles à grande échelle de nouvelle génération, dotés de puissantes capacités de raisonnement et d'apprentissage automatique. Apprenons ensemble ! ⬇️
De plus, afin de permettre à un plus grand nombre d'utilisateurs de comprendre les derniers développements dans le domaine de l'intelligence artificielle au sein du monde universitaire,Le site web officiel d'HyperAI propose désormais une section « Dernières publications », permettant aux utilisateurs de rester informés des recherches de pointe en IA.
Derniers articles sur l'IA:https://go.hyper.ai/hzChC
Recommandation de papier de cette semaine
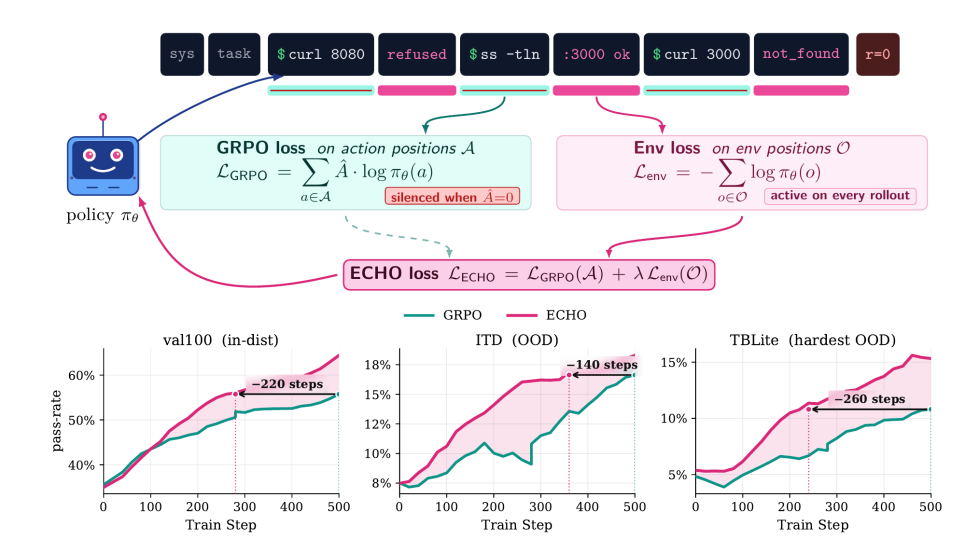
1 ÉCHO
Titre de l'article :
ECHO : Les agents terminaux apprennent gratuitement les modèles du monde
Les interactions entre agents terminaux génèrent une quantité considérable de retours d'information environnementaux. Or, l'apprentissage par renforcement classique n'utilise que des récompenses éparses pour mettre à jour les étiquettes d'action, ce qui entraîne un gaspillage important de données d'observation. Cette recherche propose la méthode ECHO qui, tout en préservant la perte d'action, calcule en outre la perte de prédiction par entropie croisée pour les étiquettes de retour d'information environnementaux. Ce mécanisme n'augmente pas la surcharge de propagation avant, permettant ainsi à la politique de prédire de manière synchrone les réponses du terminal aux instructions pendant l'entraînement, et d'apprendre ainsi le modèle du monde gratuitement.
Les résultats expérimentaux montrent que la méthode double la précision de la première réponse sur le banc d'essai de contrôle terminal, améliore considérablement la capacité à prédire la dynamique terminale non observée, réduit considérablement la dépendance aux démonstrations d'experts et peut même parvenir à une auto-évolution sans vérification externe.
Document et interprétation détaillée :https://go.hyper.ai/qma4O
2 Delta
Titre de l'article :
DelTA : Attribution discriminative de crédits par jetons pour l’apprentissage par renforcement à partir de récompenses vérifiables
L'apprentissage par renforcement basé sur des récompenses vérifiables se heurte souvent au problème d'une granularité trop grossière dans l'allocation des crédits. Les mises à jour régulières sont facilement dominées par des motifs partagés à haute fréquence, tels que la mise en page, et ne parviennent pas à identifier efficacement les marqueurs d'inférence clés qui génèrent réellement des rendements élevés. Pour résoudre ce problème, cette recherche propose DelTA, qui pondère la fonction objectif auto-normalisée en calculant des coefficients uniques. Ce mécanisme amplifie avec précision les directions de gradient des marqueurs spécifiques aux côtés des récompenses positives et négatives, en supprimant fortement les directions partagées et faiblement discriminantes, et en améliorant significativement le contraste des mises à jour de gradient. Lors d'évaluations en inférence mathématique et en génération de code, cette méthode surpasse largement les meilleures méthodes de référence de son échelle et démontre une excellente capacité de généralisation sur différentes architectures.
Document et interprétation détaillée :https://go.hyper.ai/IdI42
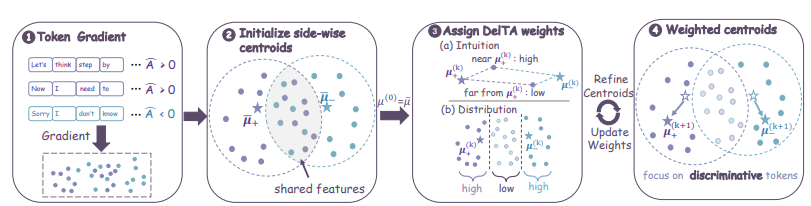
3 GoLongRL
Titre de l'article :
GoLongRL : Apprentissage par renforcement à long contexte orienté capacités avec alignement multitâche
L'apprentissage par renforcement en contexte long est souvent limité par l'homogénéité des données d'entraînement, et les algorithmes conventionnels sont sujets à une estimation biaisée des avantages en raison des différences d'échelle et de difficulté lors du traitement de récompenses mixtes entre plusieurs tâches. Cette recherche propose le schéma GoLongRL, orienté capacités, et s'appuie sur un jeu de données open source couvrant neuf capacités fondamentales et des récompenses personnalisées. Pour relever les défis d'optimisation, un mécanisme de repondération TMN est conçu, utilisant une normalisation au niveau de la tâche pour aligner les différentes échelles de récompense et combinant des pondérations adaptatives à la difficulté afin de se concentrer sur les exemples difficiles et à forte valeur ajoutée. Les évaluations montrent que ce schéma surpasse largement les modèles de pointe existants sur plusieurs jeux de données de textes longs et évite efficacement la baisse des capacités de raisonnement général et de mémorisation.
Document et interprétation détaillée :https://go.hyper.ai/omy5E
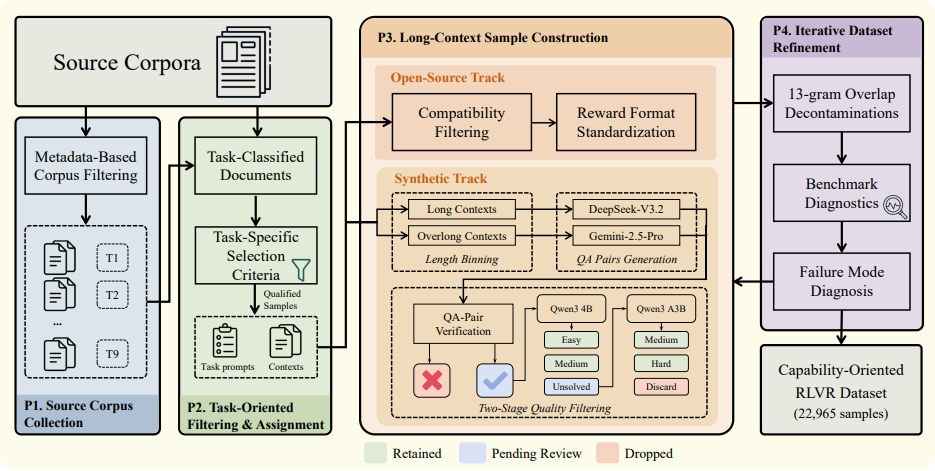
Les auteurs ont construit un ensemble de données contenant 22 965 échantillons, couvrant neuf tâches orientées vers les capacités, avec des longueurs de contexte allant de 0,1 K à 256 K jetons.
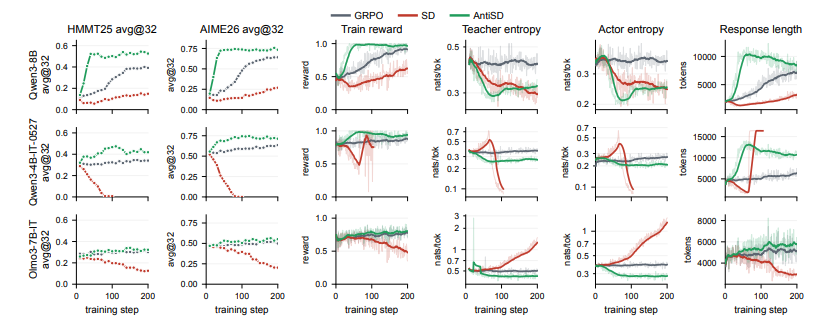
4 AntiSD
Titre de l'article :
Anti-auto-distillation pour le raisonnement par renforcement via l'information mutuelle ponctuelle
L'auto-distillation conventionnelle dans les tâches de raisonnement mathématique conduit facilement les modèles à « prendre des raccourcis », en s'appuyant excessivement sur les réponses connues et en occultant le processus de réflexion qui sous-tend véritablement les recherches en plusieurs étapes. Pour remédier à ce problème, cette recherche propose la méthode Anti-Auto-Distillation (AntiSD). Au lieu de réduire passivement l'écart entre les modèles enseignant et élève, elle maximise la divergence JS pour inverser le signal de gradient, en valorisant spécifiquement les marqueurs de pensée exploratoire, et la complète par un mécanisme de contrôle basé sur l'entropie afin de maintenir la stabilité de l'entraînement. Lors de tests menés sur plusieurs grands modèles avec des échelles de paramètres variables, cette méthode ne nécessite qu'un cinquième à la moitié des étapes d'entraînement de référence pour atteindre l'objectif, tout en améliorant la précision finale jusqu'à 11,5 points de pourcentage sur plusieurs benchmarks de raisonnement mathématique.
Document et interprétation détaillée :https://go.hyper.ai/Vax3f
5 RubriqueEM
Titre de l'article :
RubricEM : Méta-apprentissage par renforcement avec décomposition de politiques guidée par une grille d’évaluation au-delà des récompenses vérifiables
Les tâches de recherche approfondies et de longue durée manquent souvent de récompenses objectives, et l'apprentissage par renforcement conventionnel fournit un retour d'information grossier qui ne permet pas d'accumuler une expérience efficace. Cette recherche propose le cadre RubricEM, qui utilise de manière novatrice une « échelle d'évaluation » comme interface principale. Le modèle décompose les trajectoires longues en étapes de planification, de récupération, de révision et de réponse, en s'appuyant sur une échelle conçue spécifiquement pour cette étude, ce qui permet une attribution fine des crédits. Simultanément, le cadre entraîne de manière asynchrone des métapolitiques, extrayant les interactions historiques pour créer des mémoires réflexives réutilisables. Lors de multiples évaluations de recherches de longue durée, ce modèle 8B surpasse de nombreuses solutions open source et se rapproche des meilleurs systèmes propriétaires, en réalisant un apprentissage efficace sur de longs contextes et une excellente généralisation inter-tâches avec un minimum d'étapes d'entraînement.
Document et interprétation détaillée :https://go.hyper.ai/xSVTh
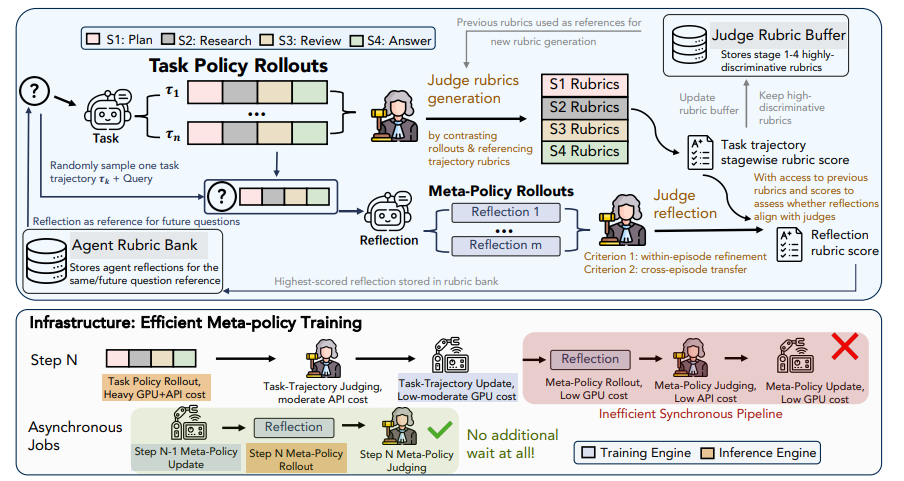
Composition et source du jeu de données : L’équipe de recherche a constitué un jeu de données d’apprentissage supervisé contenant environ 11 000 échantillons. La source des données est constituée des trajectoires d’agents générées par le modèle enseignant Gemini et adaptées à Qwen3.

6 Poly-EPO
Titre de l'article :
Poly-EPO : Entraînement des modèles de raisonnement exploratoire
Le post-entraînement de modèles d'apprentissage par renforcement à grande échelle conduit souvent à une diminution de la diversité générative, ce qui entrave l'exploration de nouvelles voies d'inférence et l'expansion des capacités de calcul lors des tests. Pour favoriser l'exploration et l'utilisation collaboratives, cette étude propose l'algorithme Poly-EPO, basé sur l'apprentissage par renforcement d'ensemble. Cette méthode rompt avec l'approche traditionnelle qui consiste à évaluer les réponses individuelles isolément. Elle multiplie la récompense moyenne d'un ensemble de réponses par le score de diversité de la politique d'inférence, utilisé comme objectif d'optimisation conjointe, intégrant ainsi nativement des signaux encourageant l'exploration diversifiée dans la fonction d'avantage. Lors d'évaluations de raisonnement mathématique, cet algorithme évite efficacement l'homogénéisation des politiques, améliorant la couverture pass@k jusqu'à 20% et démontrant un potentiel d'expansion plus important sous des mécanismes de vote majoritaire.
Document et interprétation détaillée :https://go.hyper.ai/j9Z3C
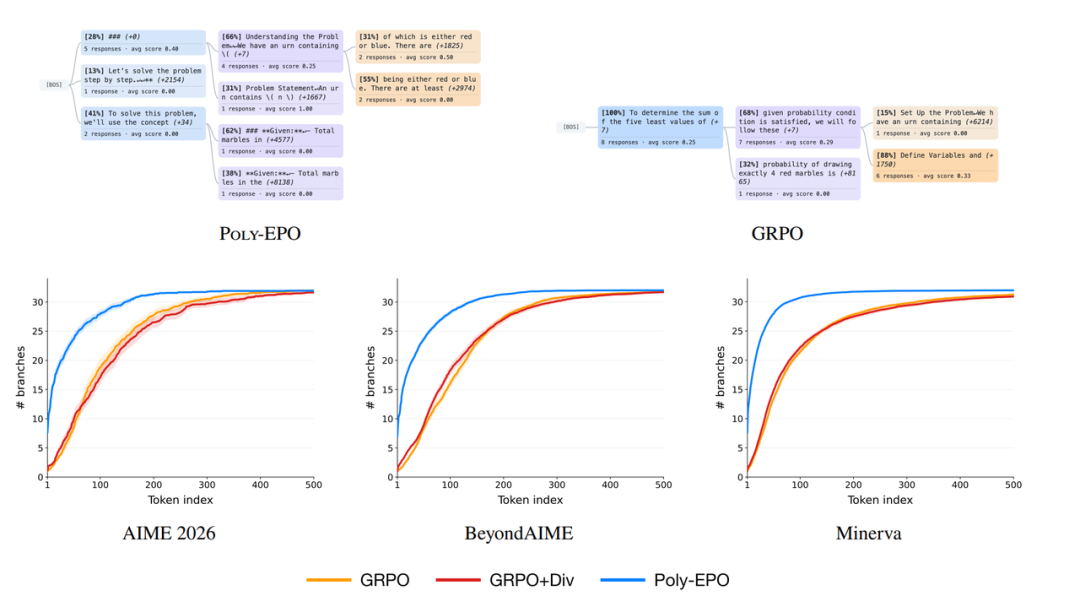
Voici l'intégralité du contenu de la recommandation d'article de cette semaine. Pour découvrir d'autres articles de recherche de pointe en IA, veuillez consulter la section « Derniers articles » du site officiel d'hyper.ai.
À la semaine prochaine !








