Command Palette
Search for a command to run...
CVEvolve, Un Algorithme De Traitement d'images Scientifiques Sans Code Et À Auto-découverte Proposé Par Le Laboratoire National d'Argonne, Possède Des Capacités Complètes Incluant Le Codage, l'auto-vérification Des Résultats Et l'optimisation De La stratégie.

Parvenir à une conclusion scientifique objective et rigoureuse est aussi difficile que de chercher de l'or dans un vaste désert. Cela est d'autant plus vrai aujourd'hui, compte tenu de la large diffusion d'instruments scientifiques de pointe et de technologies de simulation.Les données produites par la recherche scientifique sont massives en volume, peu structurées et très peu structurées.Le traitement des données de recherche scientifique s'apparente à tamiser le sable pour trouver de l'or ; il est devenu l'étape la plus cruciale et fondamentale pour exploiter la valeur des données et révéler la vérité de la recherche scientifique.
Cependant, le dilemme réside précisément là : les scientifiques du domaine manquent souvent des compétences professionnelles requises pour le traitement des données, telles que la vision par ordinateur, le traitement d'images et le génie logiciel ; tandis que les experts techniques qui maîtrisent le traitement des données ne peuvent pas comprendre en profondeur le contexte disciplinaire et ont du mal à concevoir des flux de travail de traitement adaptatifs qui correspondent à des scénarios de recherche scientifique réels.
Combler le déficit de connaissances professionnelles lié au traitement des données scientifiques,Une équipe de recherche du Laboratoire national d'Argonne (ANL) aux États-Unis a développé un cadre d'agent autonome sans code appelé CVEvolve après avoir systématiquement analysé les travaux antérieurs d'automatisation basés sur l'IA.Ce framework est conçu pour extraire les algorithmes nécessaires au traitement des données de recherche scientifique. D'une grande polyvalence, il ne requiert ni architecture de problème prédéfinie ni modèles de processus fixes. Il permet une intégration complète de divers éléments tels que le code, les données, les métriques d'évaluation, les enregistrements de recherche et les résultats de visualisation. Il facilite le développement d'algorithmes exécutables pour la vision par ordinateur, le traitement d'images et d'autres domaines. Non limité à une seule méthode de modélisation, il offre des fonctionnalités complètes incluant l'écriture et l'exécution de code, l'évaluation des performances, le suivi de l'historique, l'autocontrôle des résultats et l'optimisation itérative stratégique.
En résumé, CVEvolve est capable de développer ses propres algorithmes spécialisés, adaptés à divers scénarios de traitement de données scientifiques en situation réelle. Cela permet aux scientifiques, même sans connaissances en programmation ou en traitement d'images, de se familiariser rapidement avec des méthodes d'analyse intelligentes sans écrire une seule ligne de code. Les résultats obtenus sont ainsi plus complets, fiables et efficaces qu'avec les méthodes traditionnelles.
Les résultats correspondants, intitulés « CVEvolve : Découverte autonome d'algorithmes pour le traitement de données scientifiques non structurées », ont été publiés sur la plateforme de prépublication arXiv.
Points saillants de la recherche :CVEvolve propose un cadre de recherche par proxy général pour la découverte d'algorithmes de traitement autonome de données scientifiques, conçu spécifiquement pour les problèmes non structurés. Ce cadre élimine le besoin de cadres de problèmes prédéfinis et de modèles de processus fixes. CVEvolve introduit une architecture de recherche à large champ qui combine des mécanismes de génération, d'optimisation et d'évolution avec une gestion d'état prenant en compte la source et des tests de rétention pilotés par l'agent, garantissant ainsi la flexibilité, l'autonomie, la maturité et la facilité d'utilisation du cadre. CVEvolve a été validé sur diverses tâches, notamment l'alignement d'images de microscopie à fluorescence X, la détection des pics de Bragg et la segmentation d'images de microscopie à diffraction d'énergie à haute énergie, démontrant sa capacité à découvrir des algorithmes pratiques et à accélérer la recherche scientifique.

Voir le document :
https://hyper.ai/papers/2605.11359
Des ensembles de données de validation spécifiques ont été créés pour les trois types de tâches.
Dans cette étude, tous les ensembles de données ont été conçus sur mesure spécifiquement pour l'expérience de contrôle.
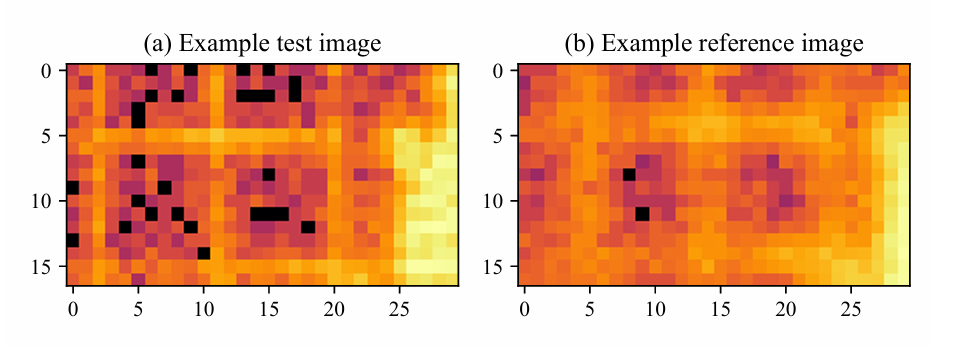
Ensemble de données d'enregistrement d'images de microscopie à fluorescence
À partir d'images XRF réelles, des décalages de translation, du bruit de Poisson, des fluctuations de balayage et un flou ont été appliqués artificiellement afin de simuler les différences d'image dues à une dérive de mise au point réelle. Les images, dessinées sur une échelle logarithmique, ne mesuraient que 10 à 30 pixels. L'ensemble de données comprenait 809 paires d'images test/référence, dont 101 (TP3T) ont été sélectionnées aléatoirement comme ensemble de validation, les 901 restantes servant à l'itération et au développement de l'algorithme.
ensemble de données de détection des pics de Bragg
Les images de diffraction ont été obtenues à partir de tous les points de balayage, puis divisées en deux groupes. Les images de chaque groupe ont été superposées pixel par pixel pour créer deux images. L'une a servi à l'évaluation des performances lors de la phase de développement de l'algorithme, et l'autre a été utilisée comme ensemble de validation. Les pics de Bragg ont été identifiés manuellement sur les deux images.
Ensemble de données de segmentation d'images de microscopie à diffraction à haute énergie : L'ensemble de données de développement contient 5 images et leurs étiquettes créées manuellement, avec 2 échantillons réservés à l'ensemble de test.
Trois processus majeurs et cinq outils clés pour la construction d'un agent intelligent basé sur LLM.
En termes d'architecture globale,CVEvolve est un contrôleur de recherche autonome articulé autour d'un agent basé sur un modèle de langage étendu. Cet agent peut utiliser des outils pour générer, exécuter et évaluer des solutions candidates, tandis que le contrôleur détermine la direction de l'exploration ultérieure en fonction des données historiques.La stratégie d'itération s'inspire du framework Pty-Chi-Evolve et comprend trois types d'étapes : génération, réglage et évolution. Elle est adaptée à un plus grand nombre de tâches grâce à un ensemble d'outils étendu et une gestion d'état améliorée.
Pour limiter la durée du contexte et réduire les coûts de calcul, un contexte entièrement nouveau est utilisé à chaque itération. Seules les invites système et les invites de tâche correspondant aux actions effectuées lors de cette itération sont conservées, et l'historique des dialogues n'est pas accumulé. Au cours d'une même itération, les opérations de génération et d'ajustement peuvent être exécutées simultanément par plusieurs processus parallèles, permettant ainsi au système d'explorer plusieurs solutions nouvelles ou d'effectuer plusieurs cycles d'optimisation et d'ajustement pour différents contenus originaux avant la mise à jour de l'historique des dialogues.
Après chaque itération, les algorithmes candidats soumis par l'agent sont regroupés selon leur lignée évolutive, ce qui permet de conserver les relations d'héritage parent-enfant et de préserver les modèles de conception performants. L'architecture d'échantillonnage des candidats est empruntée à l'algorithme MAP-Elites et est réalisée de manière aléatoire. Pour les étapes d'optimisation et d'évolution, CVEvolve utilise un échantillonnage aléatoire des candidats au lieu de sélectionner systématiquement le meilleur candidat actuel.
Flux de travail en trois étapes
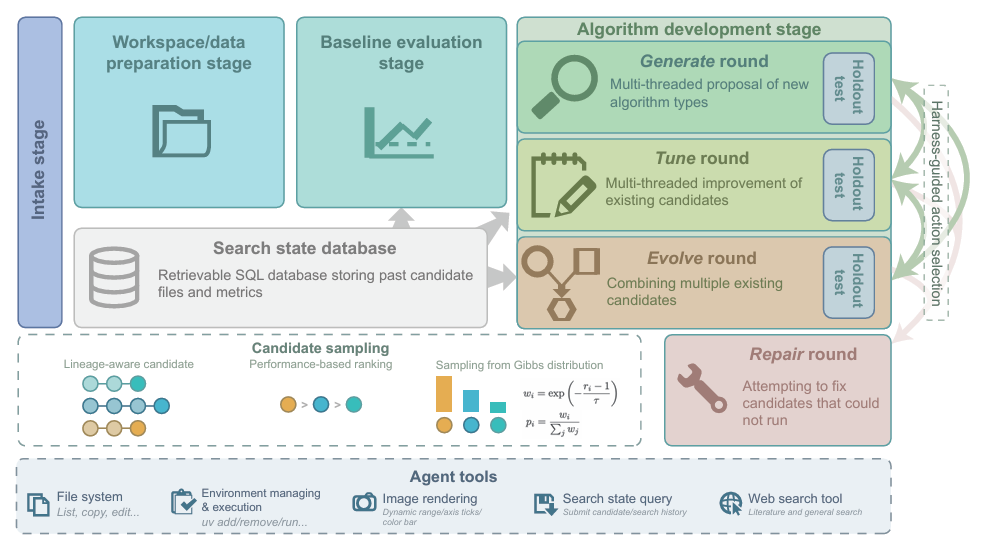
* Phase de préparation de l'espace de travail :Dès la préparation de l'espace de travail, l'environnement d'exécution est configuré et les indicateurs d'évaluation issus des descriptions de tâches ou des invites de l'utilisateur sont automatiquement intégrés au code d'évaluation exécutable.
* Phase d'évaluation initiale :Exécuter et évaluer les algorithmes de référence existants afin de fournir une base de comparaison pour les travaux ultérieurs.
* Phase d'itération et de développement de l'algorithme :L'algorithme suit les stratégies de génération, d'optimisation et d'évolution pour effectuer plusieurs itérations de recherche. La stratégie de génération permet une exploration approfondie et la conception de nouveaux algorithmes à l'aide de plusieurs threads. La stratégie d'optimisation consiste à sélectionner aléatoirement les algorithmes candidats les plus prometteurs et à optimiser leurs paramètres. La stratégie d'évolution permet une évolution itérative, en combinant les avantages de plusieurs algorithmes pour générer un nouvel algorithme.
En outre, afin de garantir la rigueur et la rationalité de la recherche, le processus global comprend également des cycles de réparation optionnels pour corriger les algorithmes candidats qui ne peuvent pas s'exécuter, des tests indépendants après chaque cycle, une recherche SQL dans la base de données d'état et l'enregistrement des candidats, des indicateurs, des cycles d'itération et des lignées évolutives tout au long du processus.
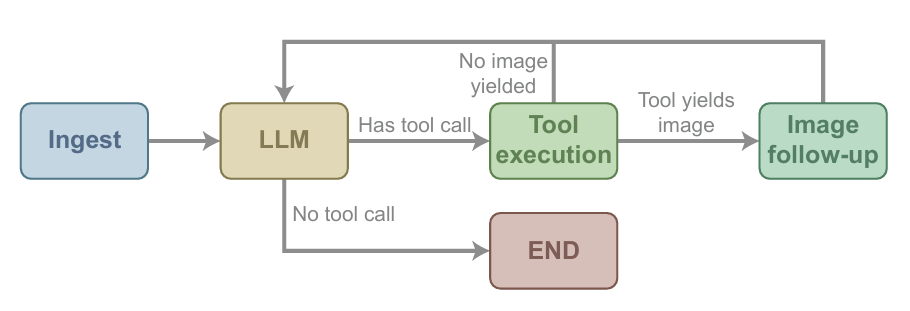
Cinq outils de soutien essentiels
* Outils du système de fichiers :Permet de lister, lire, écrire, modifier, copier, déplacer et supprimer des fichiers dans l'espace de travail, permettant aux agents d'écrire des codes candidats, des scripts d'assistance et des outils d'évaluation dans un environnement de test.
* Outils de gestion de l'environnement et d'exécution du code :Installation ou suppression des dépendances dans l'espace de travail de support et exécution de scripts Python.
* Outils de visualisation d'images :Il prend en charge le traitement d'images à virgule flottante, la mise à l'échelle logarithmique d'images à grande gamme dynamique, la conversion du format TIFF au format PNG et d'autres fonctions d'ajustement, permettant à l'agent d'identifier des structures subtiles, des variations de luminosité et des anomalies difficiles à détecter avec un rendu linéaire ordinaire.
* Outil de recherche d'état :Il aide les agents à définir des indicateurs clés, à enregistrer les résultats d'évaluation, à vérifier les données historiques, à analyser les résultats des candidats et à soumettre de nouveaux candidats aux enregistrements de recherche dans le langage de requête structuré.
* Outils de recherche Web :L'accès à arXiv, Semantic Scholar et Tavily facilite le développement d'algorithmes itératifs en tirant parti d'informations techniques de référence externes.
De plus, un intergiciel de suivi d'images multimodal a été intégré afin de pallier l'impossibilité pour les interfaces de modèles de langage volumineux de transmettre directement des images. Concrètement, lorsque l'outil renvoie le chemin d'accès à l'image, il réinjecte automatiquement l'image rendue comme message de suivi dans la boîte de dialogue.
Architecture d'exécution sous-jacente de base
CVEvolve est une application agent basée sur LangGraph. Elle utilise un graphe de nœuds simplifié lors de l'exécution et traite les données via quatre processus principaux : réception des messages, inférence du modèle, appel de l'outil et post-traitement des images. Une fois que l'outil a renvoyé le chemin d'accès à l'image, le nœud de traitement d'images le convertit en données d'observation multimodales et les renvoie au modèle pour la prochaine inférence, comme illustré dans le schéma ci-dessous.
Vérification de la praticabilité de CVEvolve dans trois types de scénarios de traitement d'images scientifiques
Pour démontrer l'efficacité pratique et la capacité de généralisation de CVEvolve, l'équipe de recherche a spécifiquement conçu trois séries d'expériences de traitement d'images scientifiques réelles pour le valider.Toutes les expériences ont été réalisées à l'aide de Claude Opus 4.6.
Enregistrement d'images de microscopie à fluorescence
Les chercheurs ont d'abord démontré la capacité de CVEvolve à trouver un algorithme robuste pour l'enregistrement translationnel d'images de microscopie à fluorescence X (XRF), qui résout le problème de l'étalonnage du décalage d'image après la mise au point du microscope.
Les algorithmes de base comprennent deux types : la corrélation de phase avec un préprocesseur à fenêtre de Hanning et la minimisation des erreurs par force brute ; la métrique de comparaison des performances est la distance euclidienne moyenne entre les décalages calculés et les décalages de vérité terrain.
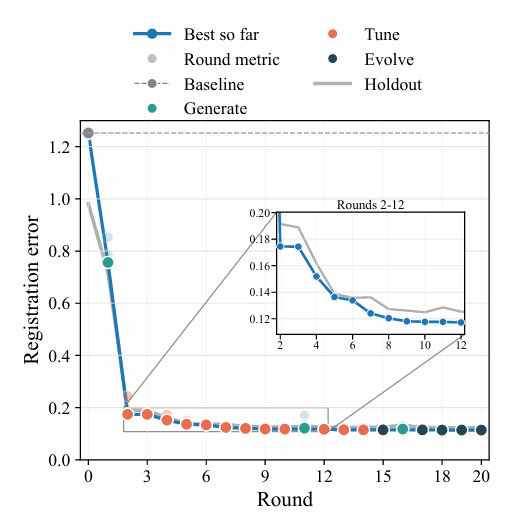
L'étude, après 20 itérations de recherche, met en évidence l'évolution des erreurs et les caractéristiques de performance. Lors des itérations initiales de référence, l'erreur euclidienne moyenne de la minimisation par force brute était de 1,25, tandis que l'erreur de la méthode de corrélation de phase après prétraitement par fenêtre de Hanning atteignait 5,8. Après les itérations de génération et d'évolution suivantes, l'erreur d'enregistrement a diminué continuellement, atteignant respectivement 0,8 et 0,43, et les performances se sont stabilisées après la 9e itération. Ce phénomène est illustré dans la figure ci-dessous.
Pour sélectionner l'algorithme d'enregistrement optimal, cet algorithme adopte une approche d'enregistrement d'images progressive, du grossier au fin. La première étape consiste à réaliser un alignement et un positionnement au niveau du pixel entier par corrélation croisée normalisée multi-échelle. La deuxième étape combine diverses méthodes de prétraitement, notamment des fonctions splines et des algorithmes d'optimisation, afin d'améliorer la précision jusqu'au niveau sub-pixel. La troisième étape consiste à pondérer et à intégrer de manière adaptative plusieurs ensembles de résultats d'estimation en fonction des coordonnées pour obtenir un décalage final stable et fiable.
Les tests effectués sur l'ensemble de test et les comparaisons avec divers algorithmes de référence ont montré que l'algorithme d'enregistrement optimal présentait une erreur de 0,12, soit près de 8 fois inférieure à celle de l'algorithme de minimisation d'erreur par force brute, pourtant plus performant. Par ailleurs,Les chercheurs ont ensuite comparé les candidats découverts par CVEvolve avec ceux découverts par OpenEvolve. Après 500 itérations, l'erreur s'est stabilisée à 0,23, soit une valeur nettement supérieure à celle de l'algorithme candidat découvert par CVEvolve.Comme le montre le tableau suivant :

Détection des pics de Bragg
L'objectif de cette expérience est de trouver un algorithme pour la détection des pics de Bragg dans les images de diffraction des rayons X. Il s'agit de développer une méthode permettant d'identifier et de localiser les pics de Bragg à l'intérieur et autour des régions annulaires correspondantes d'un plan réticulaire donné. Les métriques d'évaluation comprennent le score F1, la précision et le rappel.
Comme l'ensemble de développement ne contient qu'une seule image, l'algorithme est très sensible au surapprentissage ; il est donc nécessaire d'utiliser un ensemble de validation croisée pour surveiller ses performances de généralisation. Les résultats sont présentés dans la figure ci-dessous. Le score F1 pour l'image de l'ensemble de développement continue d'augmenter, tendant finalement vers la valeur maximale de 1, tandis que le score F1 pour l'ensemble de test réservé atteint son maximum autour du 5e passage, puis chute brutalement après le 9e passage.
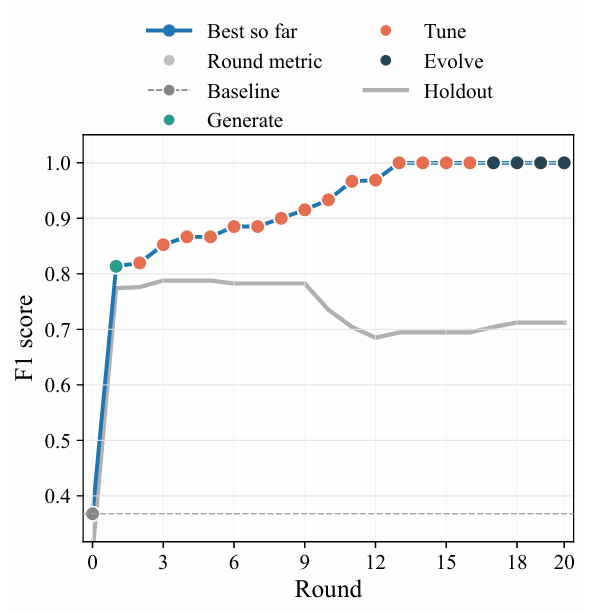
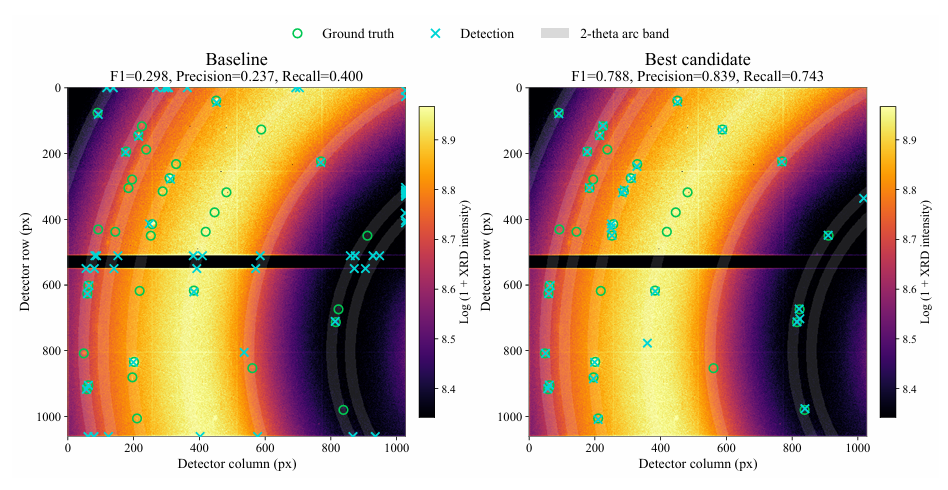
Ensuite, nous sélectionnons le candidat optimal au 5e tour. Nous masquons d'abord la région invalide, puis générons une carte de rapport signal/bruit en soustrayant le bruit de fond à l'aide de coordonnées polaires en forme d'arc et en normalisant le bruit local. Puis, nous utilisons un algorithme complémentaire multi-itérations pour trouver la valeur maximale. Enfin, nous fusionnons, vérifions et optimisons le point central pour obtenir les coordonnées finales du pic.
Les résultats montrent queLa solution candidate optimale permet d'atténuer efficacement les fausses détections, tout en réduisant le nombre de détections manquées et en identifiant davantage de pics étiquetés.Le meilleur candidat a obtenu des performances supérieures à la référence pour tous les indicateurs : le score F1 est passé de 0,298 à 0,788, le score de précision de 0,237 à 0,839 et le score de rappel de 0,400 à 0,743 (correspondant aux détections manquées). Voir la figure ci-dessous.
Segmentation d'images de diffraction
L'objectif de cette étude était la segmentation d'images de diffraction polycristalline, dont la difficulté résidait dans la distinction précise entre les anneaux de diffraction et les pics de Bragg. L'expérience a utilisé l'indice d'intersection à union (IoU) pondéré et a consisté en 40 cycles d'observation. Les résultats ont montré…Les candidats de référence initiaux créés par l'agent, par soustraction d'arrière-plan et segmentation par seuillage pour identifier les caractéristiques, avaient finalement un rapport intersection-union de seulement 0,37, ce qui est faible en précision.Comme le montre la figure ci-dessous.
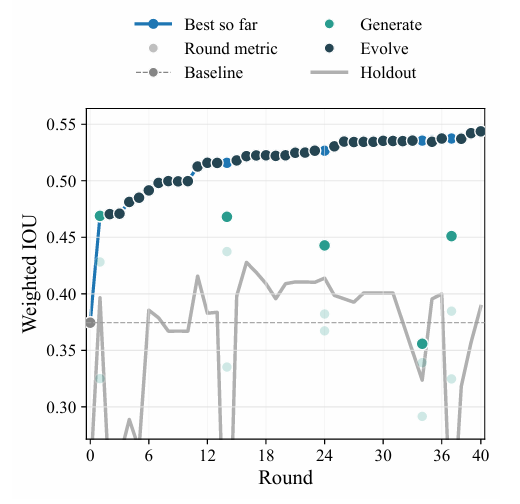
Ensuite, grâce au suivi des indicateurs de rétention, l'algorithme candidat optimal a été sélectionné au 16e tour. Cet algorithme a été transformé en une image de diffraction logarithmique, les paramètres du centre du faisceau et du fond radial ont été calculés, puis les résultats annulaires ont été identifiés et vérifiés par des contrôles de cohérence radiale et azimutale. Les pixels ont été segmentés en fonction du seuil de fond, et enfin les pics de diffraction ont été purifiés et un masque de segmentation a été généré.
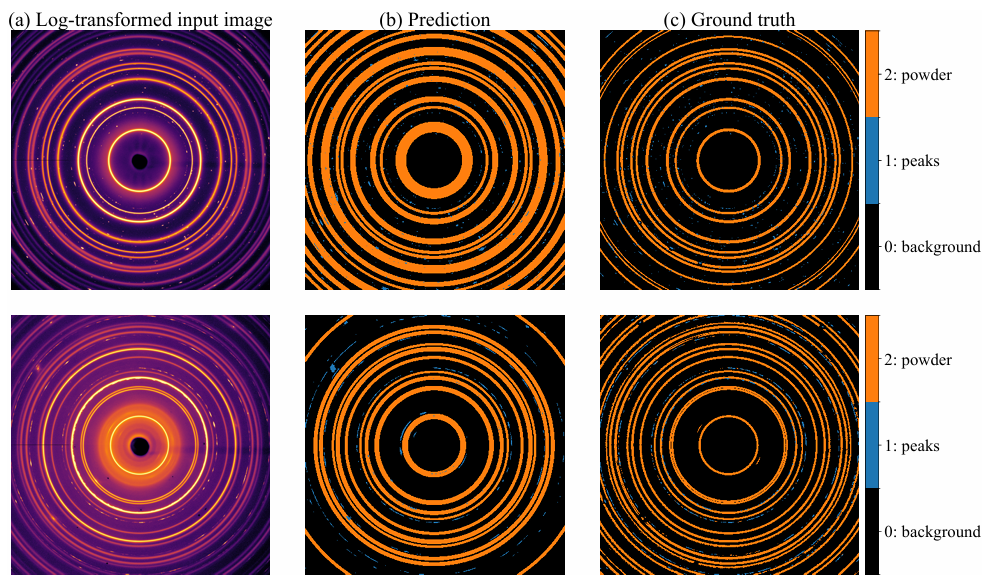
Les résultats ont montré que lors de la première démonstration, le masque annulaire prédit était plus large et plus épais que le contour de base réel. Cependant, après une vérification minutieuse, il a été confirmé que la plupart des structures annulaires avaient été détectées avec succès et que plusieurs pics de Bragg avaient été correctement segmentés. Le masque prédit correspondait parfaitement au contour de base réel. Lors de la seconde démonstration, quelques structures annulaires situées dans la région externe n'ont pas pu être identifiées ni détectées.
Derniers mots
En résumé, le développement sans code de CVEvolve abaisse considérablement les barrières à l'entrée pour les technologies d'imagerie computationnelle, offrant ainsi aux scientifiques un moyen rapide d'effectuer un traitement personnalisé des données scientifiques. À l'avenir, CVEvolve devrait encore améliorer ses capacités, comme décrit dans l'article, en intégrant le traitement de données de haut niveau et l'optimisation des flux de travail en temps réel. Ceci propulsera les flux de travail de découverte scientifique autonomes dans une ère où intelligence et technologie seront à la fois mises en œuvre.








