Command Palette
Search for a command to run...
Le MIT Propose DRiffusion, Qui Permet d'obtenir Une Accélération De l'inférence De 1,4 À 3,7 Fois, Afin De Surmonter Le Goulot d'étranglement De La Latence d'échantillonnage Dans Les Modèles De diffusion.

Dans le domaine de l'IA générative, les modèles de diffusion, grâce à leur mécanisme itératif unique de débruitage, surmontent efficacement les limitations des modèles traditionnels en termes de qualité et de diversité de génération. Ils sont largement utilisés dans des domaines de pointe tels que le traitement d'images, le traitement vidéo, le traitement audio et la conception moléculaire. Cependant, ce processus d'amélioration, qui privilégie la qualité au détriment du temps, nécessite généralement des dizaines, voire des centaines d'itérations pour produire des résultats de haute fidélité.Il en résulte des vitesses d'échantillonnage extrêmement lentes et des coûts d'inférence élevés.Cela constitue un goulot d'étranglement majeur pour que les modèles de diffusion évoluent vers des applications en temps réel et un déploiement à grande échelle.
Pour pallier le problème de l'échantillonnage lent, les chercheurs ont proposé des méthodes d'accélération telles que le flux rectifié et la distillation : la première réduit les itérations invalides en optimisant le chemin de débruitage, tandis que la seconde utilise la distillation des connaissances pour alléger le modèle. Cependant, lorsque le nombre d'étapes d'échantillonnage est drastiquement réduit afin d'obtenir un gain de vitesse important,Les deux méthodes sacrifient considérablement la qualité du résultat (par exemple, perte de détails et flou des textures), et la distillation peut même réduire fortement la diversité des résultats.
Bien que les techniques de parallélisation offrent une approche complémentaire sans compromettre la qualité, les méthodes système existantes sont limitées par les architectures de modèles (telles que U-Net et Transformer), ce qui engendre une faible polyvalence. Les méthodes mathématiques, qui modélisent le processus de diffusion par des équations différentielles et conçoivent des solveurs efficaces, souffrent souvent d'une faible compatibilité avec les frameworks courants et sont susceptibles de s'écarter de la distribution d'échantillonnage initiale. Aucune de ces solutions ne résout fondamentalement le problème de la dépendance séquentielle inhérente aux modèles de diffusion : chaque étape de débruitage dépend du résultat de l'étape précédente.
Pour relever ce défi, des chercheurs du MIT se sont récemment attaqués au problème fondamental et, grâce à une découverte mathématique concise et à un modèle d'ordonnancement innovant, ont démontré pour la première fois le parallélisme intrinsèque inexploité au sein du cadre de la diffusion. Sur cette base,Des chercheurs ont proposé le modèle de diffusion DRiffusion, basé sur le principe du « draft-and-refine ».En combinant les avantages des méthodes systémiques et des méthodes mathématiques, une accélération significative est obtenue sans sacrifier la qualité de la génération, offrant une solution inédite pour équilibrer haute fidélité et efficacité d'échantillonnage dans les modèles de diffusion.
Les résultats de recherche associés, intitulés « DRiffusion : Draft-and-Refine Process Parallelizes Diffusion Models with Ease », ont été publiés en tant que prépublication sur arXiv.
Points saillants de la recherche :
* Pionnier du cadre parallèle « brouillon-raffinement » DRiffusion, révélant le parallélisme inhérent des modèles de diffusion.
* Propose des modes d'accélération à la fois agressifs et conservateurs, permettant un compromis flexible entre qualité et vitesse.
* Permet d'obtenir une accélération réelle de 1,4 à 3,7 fois lors de tests sur le terrain multi-modèles, avec une qualité de génération quasi sans perte et une supériorité globale par rapport aux méthodes existantes.

Adresse du document :
https://arxiv.org/abs/2603.25872
Suivez notre compte WeChat officiel et répondez « DRiffusion » en arrière-plan pour obtenir le PDF complet.
Ensemble de données MS-COCO : contient 5 000 images et 25 000 descriptions.
L'expérience a utilisé l'ensemble de validation MS-COCO 2017 comme ensemble de données de référence, qui contient 5 000 images.Chaque image est accompagnée de cinq lignes de texte descriptives. Conformément à la pratique courante, seule la première ligne de description est utilisée pour l'évaluation de l'alignement image-texte afin de garantir une correspondance univoque entre l'image générée et le texte de référence, et ainsi assurer la rigueur de l'évaluation.
Compte tenu de la sensibilité insuffisante des métriques traditionnelles aux préférences visuelles fines, cette étude introduit PickScore et Human Preference Score v2.1 (HPSv2.1) comme évaluations complémentaires. Pour évaluer l'efficacité, jusqu'à quatre GPU NVIDIA V100 ont été utilisés, et la latence d'échantillonnage moyenne a été mesurée sur plusieurs simulations en régime permanent. Le gain de vitesse relatif par rapport au modèle de diffusion mono-GPU de référence est présenté, ainsi que la surcharge mémoire supplémentaire induite par la méthode.
Pour comparer les résultats à la méthode de référence, deux méthodes d'accélération représentatives du modèle de diffusion ont été sélectionnées : le saut direct (réduction du nombre d'étapes d'échantillonnage) et AsyncDiff (parallélisation du débruitage par distribution de sous-réseaux sur différents dispositifs et échantillonnage asynchrone). Afin de garantir la cohérence de l'évaluation, les chercheurs ont reproduit les résultats expérimentaux à partir de l'implémentation officielle d'AsyncDiff, dans les mêmes conditions de mesure.
DRiffusion : Parallélisez facilement les modèles de diffusion grâce à un processus d'ébauche et d'affinage
La conception de DRiffusion repose sur une question fondamentale : un modèle de diffusion peut-il calculer simultanément les prédictions de bruit pour plusieurs pas de temps ? Dans le modèle de diffusion original, cet objectif est difficile à atteindre directement car chaque étape de débruitage dépend de l’état de sortie de l’étape précédente.Les transitions par sauts offrent une nouvelle perspective pour surmonter cette limitation :Si l'opération de saut peut être considérée comme un opérateur local appelable indépendamment, alors les états intermédiaires peuvent être construits directement sans parcourir la trajectoire complète, permettant ainsi un calcul parallèle sur plusieurs étapes temporelles.
Le concept de transitions abruptes n'est pas nouveau. Comme illustré dans la figure ci-dessous, dans une perspective de temps continu, la dynamique du système peut être intégrée sur un intervalle de temps plus long, et le fait de sauter des étapes intermédiaires est une opération naturelle. Cependant, actuellement…Les cadres de modélisation de la diffusion n'utilisent généralement ce degré de liberté qu'au niveau global (par exemple, en resélectionnant la séquence des pas de temps).Il manque un mécanisme étape par étape qui puisse être appelé localement et utilisé à la demande.

à cette fin,DRiffusion convertit d'abord la transition de saut en un opérateur.Plus précisément, pour les modèles de diffusion courants tels que DDPM, DDIM et les solveurs basés sur des équations différentielles ordinaires (EDO), une formule de transition de saut unifiée est dérivée, qui permet une connexion directe entre deux états de diffusion quelconques sans avoir besoin de redéfinir le calendrier global des pas de temps.
Prenons l'exemple de DDPM : la transition abrupte de l'état courant x_t à l'état futur x_t-k admet une solution analytique. DDIM peut également être généralisé en fonction de la cohérence de la distribution marginale. Dans le cadre d'une modélisation par équations différentielles ordinaires, ignorer les étapes intermédiaires revient à utiliser directement un pas d'intégration numérique plus grand. L'introduction de cet opérateur améliore considérablement la flexibilité de la conception des séquences d'échantillonnage et ouvre la voie à une parallélisation ultérieure.
Basé sur l'opérateur de transition de sautLe flux de travail principal de DRiffusion peut être résumé en deux étapes : la génération d’ébauches et l’affinage.Étant donné l'état x_t à l'instant t initial, les états des k instants suivants sont générés en parallèle par des transitions par sauts afin d'obtenir des estimations préliminaires. Du fait de l'augmentation du pas d'intégration, la précision de ces estimations est légèrement inférieure à celle des itérations successives, mais les résultats globaux restent cohérents avec la trajectoire débruitée d'origine.
Ces ébauches sont ensuite traitées en parallèle par le prédicteur de bruit afin d'obtenir les estimations de bruit correspondantes. Puis, des mises à jour de débruitage standard sont effectuées pour affiner chaque ébauche, et enfin, l'état affiné et son bruit correspondant sont obtenus, servant de point d'ancrage pour l'itération suivante.
Cette conception présente un problème potentiel : un grand pas de saut peut entraîner une baisse de la qualité de la génération en raison d’imperfections dans la prédiction du bruit. Des recherches existantes ont effectivement mis en évidence ce risque, mais nos observations expérimentales révèlent deux facteurs atténuants.D'abord,Une légère baisse de la qualité perçue n'équivaut pas à une réduction significative de la capacité de représentation ; les images générées ou les vecteurs latents conservent généralement la majeure partie des informations sémantiques et structurelles sous-jacentes.deuxième,Bien que le prédicteur de bruit ne soit pas parfaitement précis, sa capacité de généralisation est suffisante pour associer des voisinages d'échantillons raisonnables à des résultats acceptables. Grâce à ces deux points, DRiffusion peut produire des images de qualité suffisamment élevée, même avec un grand pas.
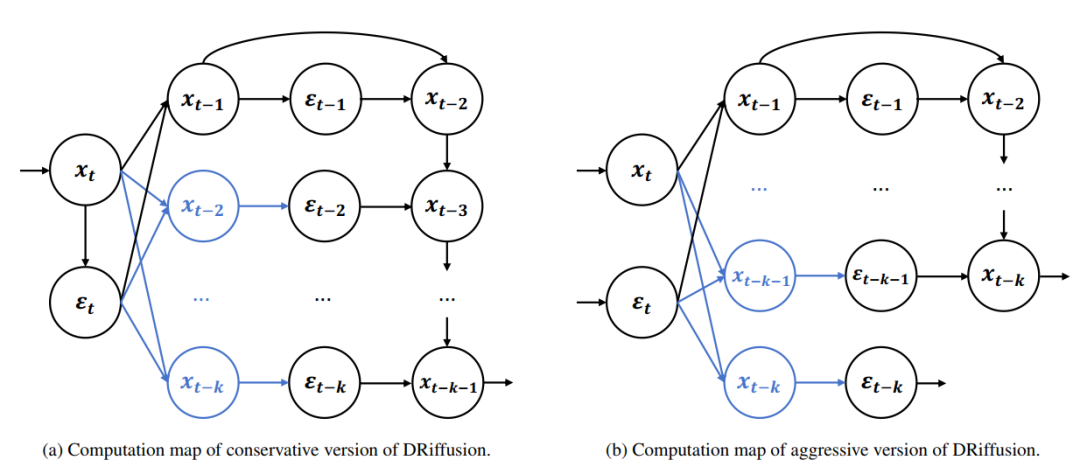
En termes de mise en œuvre, DRiffusion comprend deux versions : radicale et conservatrice.
Comme le montre la figure ci-dessous, la version radicale parallélise entièrement plusieurs prédictions de bruit en une seule itération. En négligeant les surcharges mineures telles que la communication, l'accélération idéale peut atteindre k fois, c'est-à-dire que le temps d'exécution est réduit à 1/k du temps d'exécution initial.
La version conservatrice calcule d'abord indépendamment un bruit de courant de haute précision (généré à partir de l'état affiné), puis l'utilise comme base pour reproduire le processus de la version agressive, en avançant d'un pas de temps supplémentaire, ce qui permet d'obtenir une accélération idéale de 2k+1 fois. L'idée de base des deux versions est la même : privilégier la puissance de calcul parallèle à une ébauche, et affiner le processus pour garantir la qualité du résultat.
Obtention d'une accélération réelle presque triplée sur 3 GPU.
Pour vérifier les performances de DRiffusion, des expériences ont été menées sur des modèles de diffusion d'architectures et d'échelles variées, notamment Stable Diffusion 2.1 (SD2.1) et Stable Diffusion XL (SDXL) basés sur U-Net, ainsi que Stable Diffusion 3 (SD3) basé sur Transformer pour l'adaptation des flux. Cette couverture multi-modèles permet non seulement des comparaisons équitables avec les méthodes existantes, mais aussi de tester pleinement la généralité de la méthode.
Les résultats qualitatifs sont présentés dans la figure ci-dessous. Sous des taux d'accélération élevés,Bien que DRiffusion peine à reproduire intégralement le rendu pixel par pixel de la référence, il maintient une cohérence sémantique constante et préserve efficacement les détails fins (tels que la texture du bois et les reflets sur la poitrine d'un chat).En omettant légèrement certaines étapes d'échantillonnage du bruit, la version accélérée peut parfois générer des images au contraste plus marqué et aux détails plus nets (comme les reflets en œil de chat). Une accélération plus poussée (proche de 4x) peut entraîner une légère perte de qualité, comme une saturation excessive des couleurs ou de petits artefacts, mais globalement, la qualité reste très proche de l'image de référence.

Les résultats quantitatifs sont présentés dans le tableau ci-dessous.Dans toutes les configurations, la valeur FID est très proche de la valeur de référence et la diminution maximale du score CLIP ne dépasse pas 0,16.Dans certains cas, le FID s'est légèrement amélioré, principalement en raison de la variance statistique plutôt que d'améliorations méthodologiques. Les évaluations complémentaires PickScore et HPSv2.1 montrent des baisses moyennes de 0,17 et 0,43, respectivement. La seule exception concerne SD3 en mode agressif à 4 dispositifs, où le HPSv2.1 a diminué de 1,50. Ceci s'explique par le fait que le nombre d'étapes d'échantillonnage par défaut de SD3 n'est que de 28, et cette taille d'étape extrême amplifie l'erreur d'approximation. Compte tenu de la stabilité des quatre métriques et des gains de vitesse significatifs, cette dégradation de la qualité est acceptable.
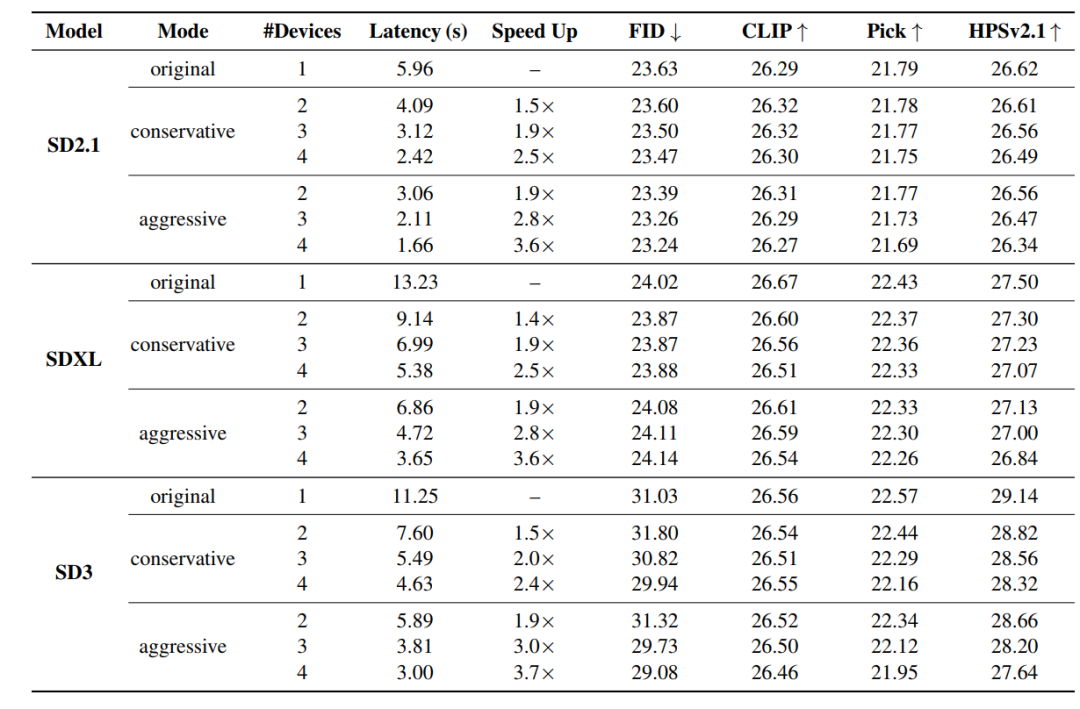
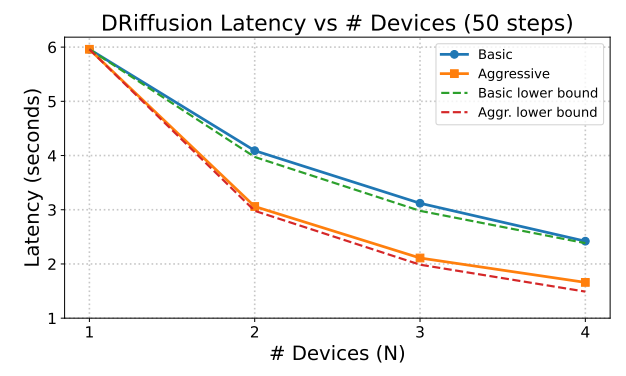
En termes de performances d'accélération,L'accélération réelle se situe entre 1,4 et 3,7 fois, et le coût de calcul total par échantillon est presque identique à celui du modèle original.Les données expérimentales montrent que la mise à l'échelle du délai du mode agressif est proche de la limite inférieure théorique O(1/N), tandis que le mode conservateur est très cohérent avec O(2/(N+1)), prouvant que DRiffusion réalise une parallélisation efficace et évolutive.
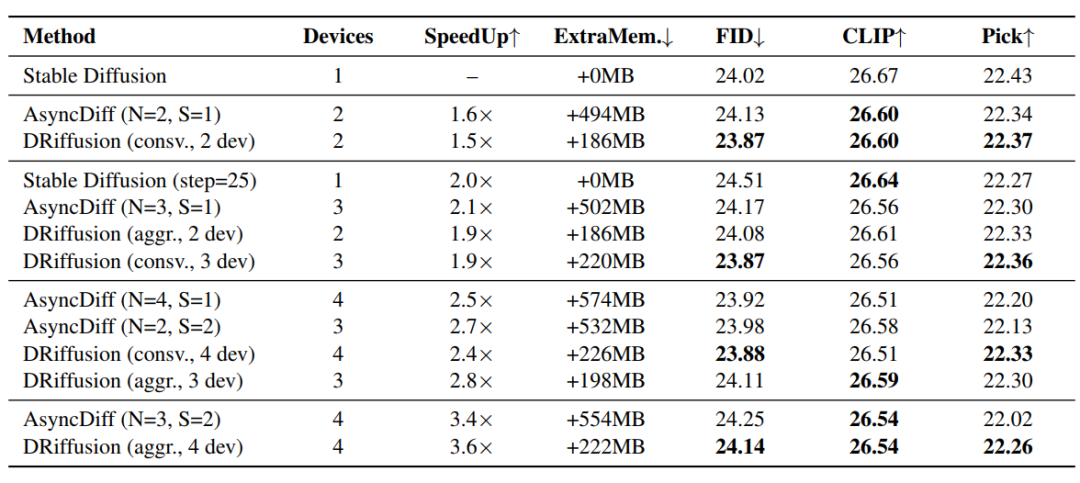
Les résultats de la comparaison des méthodes sont présentés dans le tableau ci-dessous.Dans tous les groupes d'accélération, DRiffusion a surpassé AsyncDiff et la méthode de référence par saut simple en termes de qualité de génération.En utilisant PickScore, plus sensible à l'accélération, comme principal indicateur, DRiffusion a réduit l'écart de dégradation des performances de 48,61 TP3T en moyenne, avec une réduction maximale de 58,51 TP3T pour 4 appareils. L'effet de l'accélération est quasi linéaire par rapport au nombre d'appareils, et le taux d'accélération est équivalent, voire légèrement supérieur, à celui d'AsyncDiff pour un nombre d'appareils similaire.
L'avantage en termes d'efficacité mémoire est plus marqué : AsyncDiff nécessite jusqu'à 574 Mo de mémoire supplémentaire, une quantité qui augmente avec le nombre de périphériques, tandis que DRiffusion n'induit qu'une surcharge stable de 186 à 226 Mo. Comparée à la mémoire requise de base de SDXL, d'environ 13 Go, cette surcharge est négligeable. Avec une taille de lot de 5, AsyncDiff a rencontré une anomalie de mémoire insuffisante sur un nœud de 32 Go, tandis que DRiffusion a fonctionné normalement.La raison est que DRiffusion modifie uniquement le processus d'itération d'échantillonnage, le découplant de la structure du modèle et du calcul principal.
En résumé,DRiffusion atteint une vitesse presque 3 fois supérieure sur 3 GPU tout en maintenant la qualité de génération et les détails fins, améliorant considérablement la vitesse d'inférence.En combinant des caractéristiques théoriques concises avec une implémentation parallèle pratique, des résultats expérimentaux stables et de haute qualité ont été obtenus.
La parallélisation des modèles de diffusion accélère le processus
La parallélisation des modèles de diffusion est devenue un axe de recherche majeur, exploré par les milieux universitaires et industriels du monde entier. Dans le milieu universitaire, de nombreuses institutions de pointe ont réalisé des avancées significatives dans ce domaine. Le modèle Fast-dLLM, développé conjointement par le MIT et l'Université de Hong Kong, permet d'obtenir une accélération globale de 27,6x pour les modèles de diffusion de langage à grande échelle (tâches de génération de textes longs) sans réentraînement, tout en maintenant la perte de précision sous la barre des 2%.
Titre de l'article : FAST-DLLM V2 : LLM à diffusion par blocs efficace
Lien vers l'article :https://arxiv.org/pdf/2509.26328
Le système de streaming StreamDiffusionV2 développé par l'UC Berkeley intègre un planificateur de traitement par lots prenant en compte les SLO et un contrôleur de bruit sensible au mouvement pour les modèles de diffusion vidéo, augmentant ainsi la fréquence d'images de génération vidéo à 58 FPS dans un environnement multi-GPU, surmontant le goulot d'étranglement de la puissance de calcul de la génération en temps réel.
Titre de l'article : StreamDiffusionV2 : un système de streaming pour la génération vidéo dynamique et interactive
Lien vers l'article :https://arxiv.org/abs/2511.07399
Dans le secteur des entreprises, NVIDIA a profondément intégré la technologie de parallélisation à son écosystème matériel et logiciel. En optimisant les chemins de calcul et la collaboration multi-appareils, elle améliore considérablement la vitesse d'inférence des modèles de diffusion et réduit les coûts de calcul lors de la génération d'images et de vidéos. De son côté, Stability AI explore des stratégies d'échantillonnage parallèle dans sa série de modèles Stable Diffusion. En optimisant les paramètres de traitement par lots et en activant des échantillonneurs compatibles avec le traitement parallèle, tels que DDIM et PLMS, elle améliore l'efficacité de la génération d'images d'un facteur 3 à 5 tout en préservant la qualité.
En résumé, la collaboration entre le monde académique et l'industrie a fait de la parallélisation des modèles de diffusion un sujet de prédilection pour les avancées technologiques. DRiffusion, solution typique, a démontré la faisabilité et l'efficacité de l'exploitation du parallélisme inhérent. À l'avenir, grâce à une collaboration étroite entre le matériel et les algorithmes, les modèles de diffusion devraient permettre une génération en temps réel tout en conservant une haute fidélité, levant ainsi les obstacles à l'efficacité et favorisant une application plus large de l'IA.
Liens de référence :
1.https://mp.weixin.qq.com/s/70OiIuuNP2PWgIV_hiRZBQ








