Command Palette
Search for a command to run...
L'intelligence Artificielle a Découvert 118 Nouvelles Exoplanètes ! Une Équipe De l'université De Warwick a Proposé RAVEN, Qui Permet Une Comparaison Directe Des Scénarios Planétaires Avec Chaque Faux positif.

Grâce aux progrès constants de la recherche astronomique, la découverte d'exoplanètes connaît un développement rapide. En particulier, les données de courbes de lumière fournies par la mission TESS (Transiting Exoplanet Survey Satellite) de la NASA permettent aux scientifiques d'obtenir chaque jour un grand nombre de candidats au transit.
Cependant, confirmer ou infirmer les propriétés planétaires des candidats est un processus long et complexe. À ce jour, l'Exoplanet Archive recense 7 658 cibles TESS (Teleplanetary Objects of Interest), dont 5 152 sont encore considérées comme candidates.Seules 666 ont été confirmées comme de véritables exoplanètes, et 558 autres ont été détectées par TESS mais avaient déjà été confirmées.Parallèlement, 1 185 candidats TESS ont été identifiés comme des « faux positifs (FP) » et 97 autres ont été classés comme des « fausses alarmes (FA) » — un nombre aussi élevé souligne la difficulté de confirmer les candidats exoplanètes.
L'étape suivante consiste à aller plus loin que la simple sélection des candidats : les « pipelines de validation », qui visent à confirmer, par des méthodes statistiques, que les candidats sont bien des planètes réelles.Les méthodes de vérification traditionnelles reposent principalement sur l'analyse manuelle et les observations ultérieures, notamment les mesures de vitesse radiale (VR) et le suivi par télescope au sol.Bien que ces méthodes soient fiables, elles sont chronophages et coûteuses.
En réponse, une équipe de recherche de l'Université de Warwick, s'appuyant sur le processus Kepler proposé par David J. Armstrong et al.,Un nouveau processus de sélection et de validation des candidats TESS a été développé : RAVEN (RAnking and Validation of ExoplaNets).Le changement le plus important de ce nouveau processus réside dans l'introduction d'ensembles de données d'entraînement synthétiques, qui ne reposent plus uniquement sur les données d'événements de dépassement de seuil (TCE) générées par la tâche elle-même. Cette amélioration élargit et enrichit considérablement l'espace des paramètres des scénarios planétaires et de faux positifs couverts par le modèle d'apprentissage automatique.
Les résultats montrent queLa procédure a atteint un score AUC supérieur à 971 TP3T dans tous les scénarios de faux positifs, à l'exception d'un scénario où il a dépassé 991 TP3T.Sur un ensemble de test externe indépendant contenant 1 361 candidats TESS pré-classés, le flux de travail a atteint une précision globale de 91%, démontrant son efficacité dans le classement automatique des candidats TESS.
Les chercheurs ont également utilisé ce procédé pour confirmer l'existence de 118 nouvelles exoplanètes, tout en identifiant plus de 2 000 candidates planétaires de haute qualité, dont près de 1 000 n'avaient jamais été découvertes auparavant.
Les résultats de recherche associés, intitulés « RAVEN : Rang et validation des ExoplaNets », ont été publiés en tant que prépublication sur arXiv.
Points saillants de la recherche :
* En exploitant des ensembles de données synthétiques, RAVEN permet des comparaisons directes entre les scénarios planétaires et chaque scénario de faux positif — une capacité que l'on ne trouvait auparavant que dans les cadres de validation qui reposent sur l'ajustement de modèles.
Le nouveau processus introduit des ensembles de données d'entraînement synthétiques, ne s'appuyant plus uniquement sur les données TCE générées par la tâche elle-même.
Le nouveau processus maintient une efficacité opérationnelle élevée : le traitement d'un candidat type ne prend qu'une minute environ, et il offre une bonne évolutivité grâce à la prise en charge de plusieurs processus.
Adresse du document :https://arxiv.org/abs/2509.17645*
Suivez notre compte WeChat officiel et répondez « TESS » en arrière-plan pour obtenir le PDF complet.
Jeu de données : Le chemin de construction complet, des données d’entrée aux échantillons d’entraînement
Données d'entrée : Fusion d'informations multi-sources avec les courbes de lumière comme élément central.
Le flux de travail RAVEN utilise actuellement des profils de lumière générés à partir d'images plein format (FFI) de TESS, publiées par le Centre d'opérations de traitement scientifique de TESS. Ces profils sont extraits des données FFI de chaque secteur d'observation par photométrie d'ouverture, avec une fréquence d'échantillonnage de 30 minutes pour les secteurs 1 à 27 et de 10 minutes pour les secteurs 28 à 55. Les données FFI publiées par la seconde mission d'extension de TESS (à partir du secteur 56) ont une fréquence d'échantillonnage de 200 secondes. Les profils de lumière utilisés dans cette étude s'arrêtent au secteur 55.
Données d'entraînement : Modélisation systématique des planètes et des faux positifs
Le processus RAVEN introduit des données de courbes de lumière synthétiques pour l'entraînement des modèles d'apprentissage automatique, au lieu de s'appuyer sur des données de courbes de lumière candidates classifiées existantes pour cette tâche.
L'ensemble initial d'événements composites utilisait des transits ou des éclipses simulés, intégrés aux courbes de lumière SPOC. Ces événements simulés ont été générés à l'aide d'une version modifiée du logiciel PASTIS des chercheurs et incluaient initialement des scénarios tels que des planètes en transit (Planète), des binaires à éclipses (BE), des binaires à éclipses stratifiées (BEH), des planètes en transit stratifiées (PTS), des binaires à éclipses d'arrière-plan (BEB) et des planètes en transit d'arrière-plan (PTA). Afin de garantir que les données composites correspondent au mieux à la population d'observations réelles de TESS, l'étoile principale de chaque scénario a été sélectionnée aléatoirement à partir d'un échantillon entièrement caractérisé du catalogue d'entrée TESS (TIC). Au final, l'échantillon cible contenait 1 200 520 étoiles SPOC FFI.
Partant de ce constat, la construction de données sur les faux positifs devient plus complexe et cruciale. Concernant les faux positifs proches (FPP), les chercheurs considèrent les scénarios suivants : planète en transit proche (PTP) : la planète transite et dilue l’étoile hôte ; binaire à éclipses proche (BEE) : la source de dilution proche est une binaire à éclipses ; binaire à éclipses stratifiée proche (BEESP) : la source de dilution proche est une binaire à éclipses stratifiée.
Données de test : Scénarios d’application réels centrés sur le TOI
Les performances de ce processus ont finalement été testées sur un ensemble de TOI (c'est-à-dire des cibles TESS d'intérêt) avec des classifications préalables existantes.La liste et les informations de classification des TOI utilisées dans le test proviennent des archives d'exoplanètes de la NASA, datées du 3 février 2025. À cette date, 2 134 TOI étaient pré-classées, dont 548 étaient classées comme planètes connues (KP), 485 comme planètes confirmées par TESS (CP), 1 113 comme planètes confirmées (FP) et 96 comme planètes confirmées (FA). Cependant, seules 1 918 TOI disposaient de courbes de lumière SPOC FFI publiées. Finalement,Après application des contraintes de profondeur et de périodicité aux échantillons restants, le nombre total de TOI à traiter est de 1 589.
Tous les objets d'intérêt (TOI) ont subi l'ensemble des étapes de traitement, à l'exception d'un TOI FP dont l'étoile cible était marquée comme « DOUBLE » dans TIC. Dans les résultats finaux, 68 TOI ont été exclus car le rayon stellaire de l'étoile cible était absent de TIC ; 87 autres ont été exclus car leur magnitude TESS dépassait 13,5 et 22 ont été exclus car leur magnitude Gaia dépassait 14.
L'ensemble d'entraînement utilisé dans cette étude n'incluait pas d'événements avec des étoiles cibles de magnitude T supérieure à 13,5 ou de magnitude G supérieure à 14. De plus, 28 objets d'intérêt (TOI) ont été exclus car leur MES calculé lors de la génération des caractéristiques était inférieur à 0,8, et 2 TOI ont été écartés en raison d'un échec de la génération des caractéristiques. Enfin, 21 TOI ont été exclus de l'analyse ultérieure car les données de leur centroïde empêchaient le calcul des probabilités de position ; par conséquent, aucune probabilité a posteriori n'a pu être fournie.
donc,Le nombre final de TOI pré-classés dans ce test était de 1 361, dont 705 étaient des planètes connues ou confirmées, 630 étaient des FP et 26 étaient des FA.
Combinaison de deux modèles d'apprentissage automatique : GBDT+GP
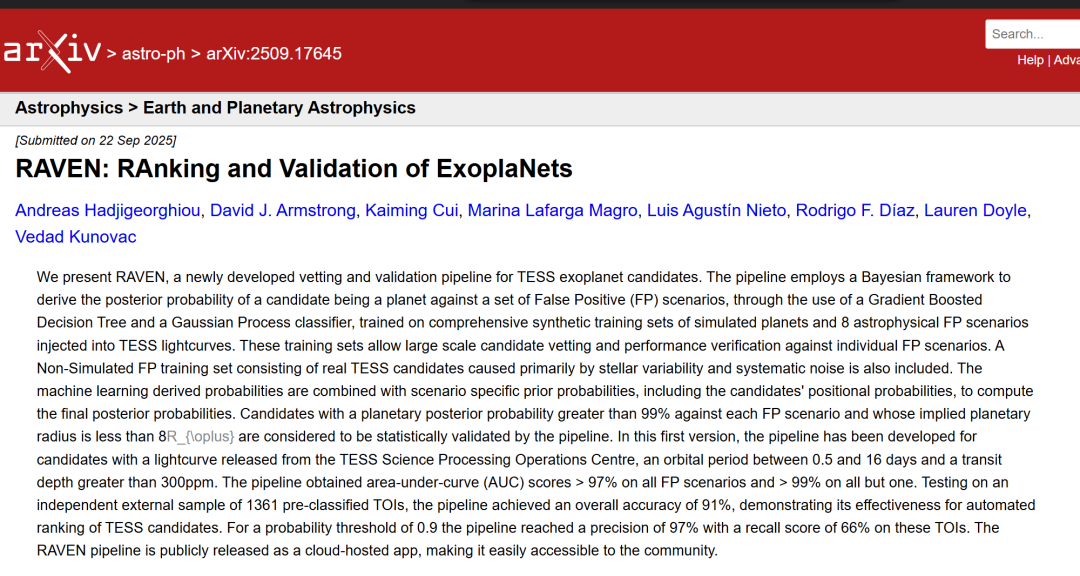
Le flux de travail RAVEN repose sur le cadre de validation statistique (ci-après dénommé A21) proposé par David J. Armstrong et al. en 2021 pour les candidats à la mission Kepler. Ce cadre a été adapté aux données du satellite TES (Transiting Exoplanet Survey Satellite) et a également été étendu et amélioré. La mise en œuvre et le fonctionnement de l'ensemble du flux de travail sont relativement complexes et comportent plusieurs étapes. Un organigramme simplifié est présenté dans la figure ci-dessous :
formation à l'apprentissage automatique
Au cœur de RAVEN se trouvent deux modèles d'apprentissage automatique : l'arbre de décision à gradient boosté (GBDT) et le processus gaussien (GP).Le processus génère des probabilités a posteriori pour 8 scénarios de faux positifs pour chaque planète candidate, et obtient la probabilité RAVEN, qui est la confiance la plus faible dans l'authenticité de la candidate, en prenant la valeur minimale.
① Arbre de décision à gradient boosté (GBDT)
Les arbres de décision constituent un type de modèle d'apprentissage automatique simple mais puissant. Leur grande interprétabilité représente un avantage considérable. Cependant, les arbres de décision individuels présentent des limites en termes de robustesse et sont sujets au surapprentissage lorsque leur profondeur est trop importante. Pour pallier ces problèmes, on utilise généralement des méthodes d'ensemble composées de plusieurs arbres « faibles ». Le Gradient Boosting Decision Trees (GBDT) est l'une de ces méthodes d'ensemble ; elle construit séquentiellement plusieurs arbres de décision pour former un modèle final plus robuste.
Les principales caractéristiques de GBDT sont :Chaque arbre nouvellement généré n'est pas entraîné directement sur la base des étiquettes originales, mais apprend plutôt à partir de l'erreur résiduelle générée par la prédiction du modèle lors du tour précédent.Autrement dit, chaque nouveau modèle vise à minimiser la fonction de perte du modèle global, un processus similaire à la descente de gradient. Lors du traitement d'ensemble, les sorties de chaque sous-modèle sont pondérées par le taux d'apprentissage, puis additionnées pour obtenir la prédiction finale.
La perte du modèle est calculée à l'aide d'une fonction de perte prédéfinie, et les résidus sont déterminés par le gradient de cette fonction. Dans cette étude, le classificateur GBDT est implémenté avec XGBoost, comme proposé par Chen et Guestrin.
② Classificateur de processus gaussien
Un processus gaussien (PG) est un processus stochastique qui généralise la distribution de probabilité gaussienne, initialement décrite pour les variables aléatoires, à une distribution de fonctions. En classification par PG, l'objectif est de produire des étiquettes de classe discrètes, ou probabilités de classe, comprises entre 0 et 1. Pour ce faire, une fonction de réponse est appliquée à la sortie du PG, transformant le résultat en un intervalle de 0 à 1. Ce résultat est ensuite combiné à une fonction de vraisemblance (telle que la vraisemblance de Bernoulli).
Cette étude utilise la méthode d'approximation variationnelle proposée par James Hensman et al. Cette méthode repose sur un ensemble de « points inducteurs », qui sont des sous-ensembles représentatifs des données, afin d'améliorer l'évolutivité du modèle tout en réduisant la complexité de calcul.
Formation et étalonnage
Pour entraîner et optimiser les deux classificateurs, une approche itérative a été adoptée. L'ensemble d'entraînement synthétique a été utilisé avec différentes combinaisons d'hyperparamètres, et les performances ont été évaluées sur l'ensemble de validation afin de sélectionner les paramètres optimaux. L'optimisation des paramètres s'est principalement concentrée sur trois scénarios clés de faux positifs : EB, NEB et NSFP, car ce sont les événements de faux positifs les plus fréquents. Parallèlement, afin d'éviter la sur-optimisation d'un seul scénario et le surapprentissage qui en découle, la cohérence des paramètres a été maintenue autant que possible entre les scénarios.
Tous les modèles ont activé le mécanisme d'« arrêt précoce » : l'entraînement s'arrête et revient à l'état du modèle au moment de la dernière amélioration de la fonction de perte sur l'ensemble de validation si la fonction de perte sur l'ensemble de validation ne diminue pas d'au moins 0,0001 en 20 itérations consécutives.
Validation statistique
La dernière étape du processus consiste à calculer la probabilité a posteriori de l'hypothèse planétaire en combinant la probabilité de chaque catégorie planète-FP, obtenue par apprentissage automatique, avec sa probabilité a priori correspondante, spécifique au scénario. Cette probabilité a posteriori représente uniquement la probabilité que le candidat soit une planète ou un scénario FP spécifique. Par conséquent, la méthode de validation statistique des chercheurs exige que la probabilité a posteriori du candidat pour chacune des huit catégories planète-FP soit supérieure à 0,99 pour que celui-ci soit considéré comme validé.
RAVEN est performant dans la sélection, le classement et la validation de véritables candidats planétaires.
Pour évaluer les performances de RAVEN, les chercheurs ont effectué les validations suivantes sur les ensembles d'entraînement et de test :
Les chercheurs ont d'abord testé les performances du modèle sur des sous-ensembles inédits de l'ensemble d'entraînement, composés de 101 événements TP3T sélectionnés aléatoirement dans chaque scène et isolés indépendamment avant l'entraînement. Les performances du modèle ont été évaluées à l'aide de quatre indicateurs clés : l'exactitude, l'aire sous la courbe ROC (AUC), la précision et le rappel. Les résultats des tests de performance sont présentés dans le tableau ci-dessous :
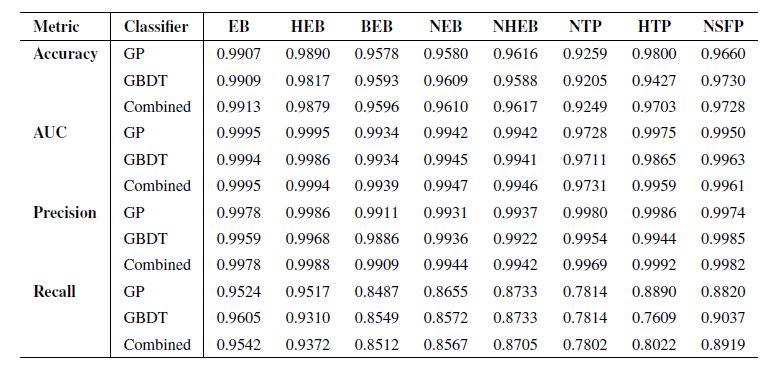
Les résultats montrent que les deux classificateurs sont performants dans tous les scénarios de faux positifs, notamment en termes de précision. L'objectif principal du pipeline RAVEN étant de sélectionner et de valider de véritables candidats planétaires, la précision est le critère le plus important, car elle reflète la capacité du pipeline à identifier correctement les faux positifs sans erreur de classification.En combinant les résultats des deux classificateurs, la précision atteint presque 99% dans tous les scénarios.
Les performances du processus RAVEN ont finalement été testées sur un ensemble de TOI ayant fait l'objet d'une classification préalable. Les probabilités RAVEN pour l'ensemble des 1 361 TOI de l'échantillon sont présentées dans la figure suivante :
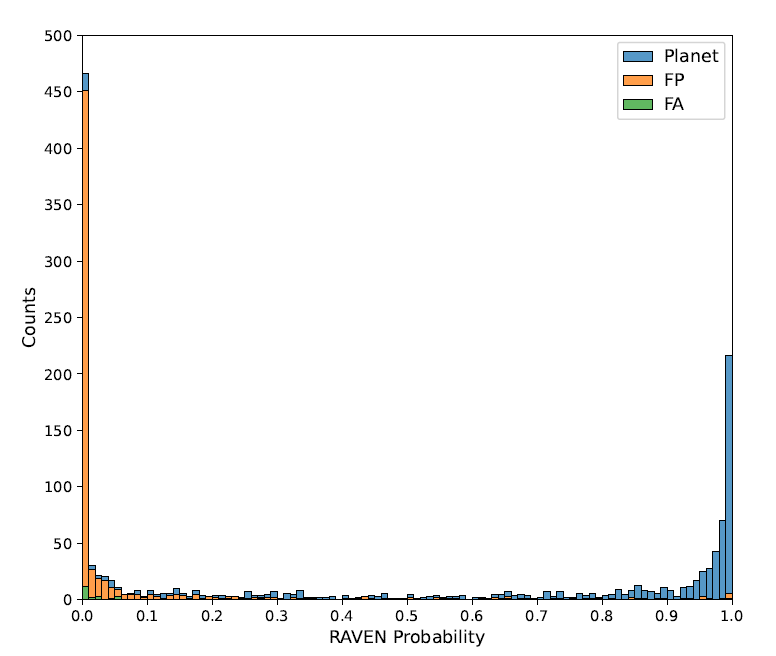
L'histogramme montre que les différences de probabilité entre les trois classes sont significatives, la distribution est bonne et les valeurs extrêmes sont évidentes.Ceci démontre l'efficacité de RAVEN pour identifier les événements FP et leur attribuer de faibles probabilités a posteriori planétaires.Plus précisément, la probabilité a posteriori minimale d'événements FP est inférieure à 0,5 pour 93,8% et inférieure à 0,01 pour 69,7%. La probabilité moyenne d'événements FP est de 0,076 et la médiane de 0,00022.
De même, parmi les 26 FA TOI, 23 présentaient une probabilité inférieure à 0,5, avec une médiane de 0,016 pour l'ensemble de la catégorie. Globalement, les résultats concernant les faux positifs et les FA TOI confirment l'efficacité du processus de sélection des candidats TESS et permettent d'éliminer la plupart des faux positifs.
Ensuite, les chercheurs ont validé la capacité de RAVEN à identifier les faux positifs (FP), et le tableau ci-dessous répertorie 12 événements FP avec une probabilité supérieure à 0,9 :
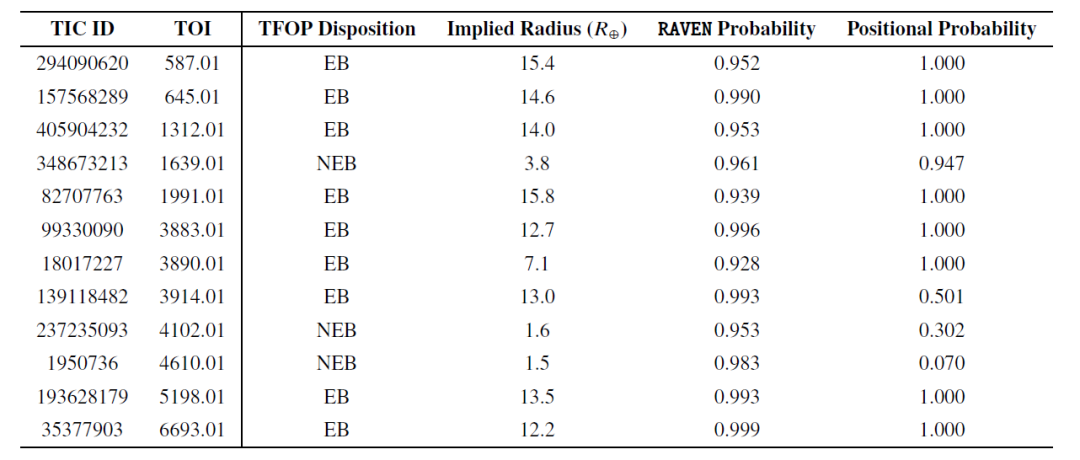
Parmi ces événements de faux positifs (FP) à forte probabilité, la plupart étaient des binaires à éclipses (EB), et seulement trois étaient des binaires à éclipses proches (NEB). Bien que les NEB soient le type de FP le plus fréquent dans l'échantillon, cela suggère que RAVEN a été performant pour identifier les NEB. En effet, pour deux événements NEB (TOI-4102.01 et TOI-4610.01), la procédure RAVEN a déterminé que la probabilité de leur information de localisation était faible et a correctement attribué la probabilité la plus élevée à l'étoile hôte réelle, confirmée par des observations de suivi.
De plus, l'événement TOI-4102.01 a également été signalé comme problématique. Ces deux événements TOI indiquent que lors de l'évaluation des candidats, notamment pendant la validation, il convient de considérer l'ensemble des résultats du processus RAVEN conjointement aux probabilités des informations de localisation afin d'identifier les situations où les probabilités a posteriori pourraient être invalides.
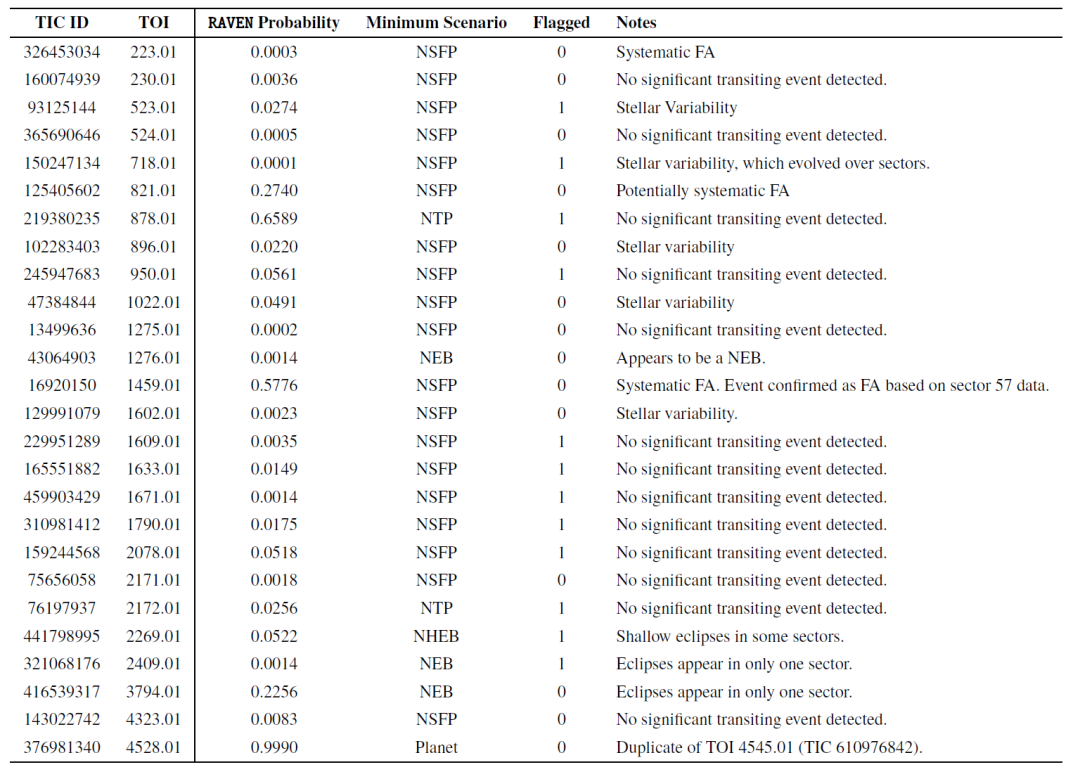
Les chercheurs ont également évalué les performances du processus RAVEN sur les fausses alertes (FA) de type TOI. Le tableau ci-dessous présente les probabilités a posteriori les plus faibles pour 26 FA de type TOI de l'échantillon, ainsi que les scénarios de faux positifs correspondants. Les probabilités de la quasi-totalité des FA de type TOI étaient incohérentes avec les scénarios planétaires, ce qui démontre que RAVEN les a identifiées efficacement.
Finalement, après avoir examiné l'échantillon initial de TOI, les chercheurs ont retenu 397 planètes connues et 308 planètes confirmées, soit un total de 705 planètes. Les résultats montrent que…La plupart des TOI planétaires ont des probabilités planétaires postérieures élevées, 81% dépassant le seuil de 0,5.
Plus précisément, 420 planètes présentent une probabilité supérieure à 0,9 et sont donc considérées comme des planètes probables. Par ailleurs, 210 planètes ont un TOI supérieur au seuil de validation statistique de 0,99, ce qui représente environ 301 planètes sur l'ensemble de l'échantillon.Ces résultats démontrent que RAVEN est performant pour la sélection, le classement et la validation de candidats planétaires réels.
L'IA devient progressivement une infrastructure importante pour la recherche astronomique.
Dans une perspective plus large d'évolution technologique, l'intelligence artificielle devient progressivement une infrastructure cruciale pour la recherche astronomique. Son importance dépasse la simple « amélioration de l'efficacité du traitement des données » ; elle commence à redéfinir le paradigme global de la découverte scientifique. Longtemps, l'astronomie s'est appuyée sur des méthodes analytiques fondées sur des modèles physiques et des règles artificielles. Cependant, avec l'amélioration des capacités d'observation, l'échelle et la complexité des données n'ont cessé de croître. Des courbes de lumière aux images à haute résolution, puis aux spectres multidimensionnels et aux informations des catalogues d'étoiles, les méthodes traditionnelles atteignent progressivement leurs limites face au traitement de données multidimensionnelles, non linéaires et fortement bruitées. Dans ce contexte,Les technologies d'IA, avec l'apprentissage automatique et l'apprentissage profond en leur cœur, deviennent un pont essentiel reliant les « données d'observation massives » à une « compréhension scientifique efficace ».
Avec le développement des méthodes d'observation, les données astronomiques ne se limitent plus à une seule modalité. De multiples sources de données, telles que les images, les spectres, les courbes de lumière temporelles et les paramètres des catalogues d'étoiles, coexistent, et les modèles d'apprentissage profond traditionnels commencent à montrer de nouvelles limites à ce stade. En effet, certaines études ont tenté de construire des modèles astronomiques multimodaux, mais ces tentatives présentent encore des limitations importantes.La plupart des études se concentrent sur des phénomènes isolés, comme les explosions de supernovae, et reposent sur des « objectifs contrastifs » comme technologie de base. De ce fait, les modèles peinent à gérer avec souplesse des combinaisons modales arbitraires et à saisir les informations scientifiques essentielles entre les modalités, au-delà des simples corrélations superficielles.
Pour surmonter ce goulot d'étranglement,Des équipes de plus de dix institutions de recherche du monde entier, dont l'Université de Californie à Berkeley, l'Université de Cambridge et l'Université d'Oxford, ont collaboré pour lancer AION-1 (Astronomical Omni-modal Network), la première famille de modèles de base multimodaux à grande échelle pour l'astronomie.En intégrant et en modélisant des informations observationnelles hétérogènes telles que des images, des spectres et des données de catalogue d'étoiles via un réseau dorsal de fusion précoce unifié, il fonctionne non seulement bien dans les scénarios sans exemple, mais sa précision de détection linéaire est également comparable à celle des modèles spécifiquement entraînés pour des tâches spécifiques.
Titre de l'article : AION-1 : Modèle fondamental omnimodal pour les sciences astronomiques
Adresse du document :https://openreview.net/forum?id=6gJ2ZykQ5W
Parallèlement, au niveau de questions scientifiques spécifiques, l'IA repousse également les limites des méthodes d'observation traditionnelles. Par exemple, en astronomie moderne, la lentille gravitationnelle forte est un outil important pour étudier la structure à grande échelle de l'Univers et la coévolution des trous noirs et des galaxies. Les quasars, qui agissent comme des lentilles gravitationnelles fortes, offrent des opportunités d'observation extrêmement rares pour étudier l'évolution de la relation d'échelle (en particulier la relation masse du trou noir supermassif – masse de la galaxie hôte) entre les trous noirs supermassifs et leurs galaxies hôtes en fonction du décalage vers le rouge.
Cependant, les quasars sont extrêmement rares et leur identification a toujours constitué un énorme défi pour les astronomes : parmi les près de 300 000 quasars catalogués dans le Sloan Digital Sky Survey (SDSS), seuls 12 candidats ont été trouvés et seulement 3 ont finalement été confirmés.Dans ce contexte, une équipe composée de nombreux instituts de recherche, dont l'Université de Stanford, le SLAC National Accelerator Laboratory, l'Université de Pékin, l'Observatoire de Brera de l'Institut national italien d'astrophysique, l'University College London et l'Université de Californie à Berkeley, a mis au point une méthode d'analyse de données permettant d'identifier les quasars agissant comme de puissantes lentilles gravitationnelles dans les données spectrales de DESI DR1. Grâce à cette méthode, les chercheurs ont identifié sept quasars candidats de haute qualité (classe A) susceptibles de jouer ce rôle.
Titre de l'article : Découverte de quasars agissant comme des lentilles puissantes dans DESI DR1
Adresse du document :https://arxiv.org/abs/2511.02009
Il est prévisible qu'avec le développement des futures missions d'observation (telles que les relevés du ciel à grande échelle), l'astronomie entrera dans une phase d'explosion de données encore plus importante, et le rôle de l'IA s'en trouvera renforcé. De l'aide à l'analyse à la découverte fondamentale, des modèles dédiés à une tâche spécifique aux modèles fondamentaux généraux, l'IA redéfinit notre compréhension de l'univers : elle change non seulement notre façon de voir, mais aussi ce que nous sommes capables de découvrir.
Références :
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W








