Command Palette
Search for a command to run...
Tutoriels En Ligne | Déployez Facilement Les Derniers Modèles d'IA Physique De NVIDIA, Couvrant Les Robots Humanoïdes, La Génération De Mouvements Humains, Le Réglage Fin Des Modèles De Diffusion, etc.
Lors de la GTC 2026 qui s'est récemment conclue, outre les nouveaux GPU très attendus, NVIDIA a également accordé une attention considérable à une orientation plus concrète et pratique :IA physique.
Ce concept, maintes fois évoqué par Jensen Huang, révèle une conclusion essentielle : l’IA ne devient véritablement l’infrastructure de la transformation industrielle que lorsqu’elle cesse de se limiter à un écran, mais qu’elle est capable de percevoir l’environnement physique, de comprendre les tâches et d’agir. Ce concept recoupe largement celui d’« IA incarnée », soulignant le lien profond qui unit l’IA au monde réel – non pas une simple capacité à « se déplacer », mais une capacité à agir de manière fiable dans des environnements complexes.
Par conséquent, nous pouvons constater lors de la GTC 2026, une conférence technologique de premier plan, que tous les sujets, des modèles de robots humanoïdes de base à la génération de mouvements haute fidélité et à un système unifié de modélisation du corps humain, ont été abordés.La série de modèles proposés par NVIDIA ne se concentre plus seulement sur les capacités du modèle lui-même, mais s'articule autour de « l'action » et de « l'exécution ».
dans,Les trois projets open source sont NVIDIA Isaac GR00T, Kimodo et SOMA-X.Ils abordent le même problème à trois niveaux : la prise de décision, la génération et la représentation – comment permettre aux machines d’effectuer des actions complexes de manière plus naturelle et efficace.
L'un est chargé de comprendre les tâches et de les traduire en comportements exécutables ; un autre se concentre sur la génération de trajectoires de mouvement détaillées et réalistes ; et le troisième s'attaque au problème persistant de la fragmentation des modèles humains, permettant une collaboration plus fluide entre différents systèmes. Chacune de ces capacités a sa propre valeur, mais surtout, elles convergent toutes vers un objectif plus pratique : faire passer les robots d'une fonction « active » à une fonction « conviviale ».
en plus,NVIDIA a également publié FDFO, une méthode d'entraînement pour les modèles de diffusion, qui fournit un support sous-jacent aux capacités ci-dessus du point de vue de l'optimisation des modèles génératifs.
Pour permettre aux développeurs du monde entier de découvrir rapidement les avancées open source de la GTC 2026 dans un environnement plus accessible et stable, le site web HyperAI (hyper.ai) a mis en ligne les tutoriels suivants dans sa section tutoriels :
NVIDIA Isaac GR00T : Un modèle de base pour les robots humanoïdes à usage général
Exécutez en ligne :https://go.hyper.ai/2Cjvr
SOMA-X : Un cadre paramétrique unifié pour les modèles du corps humain
Exécutez en ligne :https://go.hyper.ai/UcEI7
Kimodo : Modèles de génération de mouvements humains et robotiques
Exécutez en ligne :https://go.hyper.ai/p99vI
FDFO : Optimisation des flux par différences finies
Exécutez en ligne :https://go.hyper.ai/ikihN
HyperAI offre des avantages à l'inscription pour les nouveaux utilisateurs.Pour seulement $1, vous pouvez obtenir 20 heures de puissance de calcul RTX 5090 (prix d'origine $7).La ressource est valide en permanence.
NVIDIA Isaac GR00T
Modèle de base général de robot humanoïde
Le modèle NVIDIA Isaac GR00T N1.6 est un modèle Vision-Langage-Action (VLA) open source, publié en mars 2026 et conçu spécifiquement pour l'apprentissage de compétences chez les robots humanoïdes polyvalents. Ce modèle utilise une conception multimodale, lui permettant de recevoir des entrées multimodales, notamment du langage et des images, et d'effectuer des tâches de manipulation dans des environnements variés.
L'architecture de réseau neuronal du GR00T N1.6 combine un modèle de base de traitement du langage visuel avec une tête Diffusion Transformer pour le débruitage continu des mouvements. Ce modèle est entraîné sur des données robotiques variées, incluant des robots à deux bras, des robots semi-humanoïdes et des robots humanoïdes de grande taille, et peut être affiné pour s'adapter à différentes formes de robots, tâches et environnements.
Exécutez en ligne :https://go.hyper.ai/2Cjvr

SOMA-X : Un cadre paramétrique unifié pour les modèles du corps humain
Les modèles paramétriques du corps humain, notamment Skinned Multi-Person Linear (SMPL), SMPL-X, Multi-Task Human Representation (MHR), Anny et GarmentMeasurements, sont largement utilisés dans des domaines tels que la reconstruction du corps humain, l'animation et la simulation.
Cependant, ces modèles souffrent d'une incompatibilité fondamentale au niveau de leur architecture sous-jacente : chaque modèle définit sa propre topologie de maillage, sa hiérarchie articulaire et sa méthode de paramétrage, ce qui rend toute intégration transparente impossible. Par conséquent, lorsqu'il est nécessaire de combiner les avantages de différents modèles (par exemple, associer les capacités de contrôle de l'âge d'un modèle aux données de mouvement d'un autre), il faut souvent développer un adaptateur distinct pour chaque paire de modèles. Ceci augmente non seulement les coûts de développement, mais limite aussi considérablement l'interopérabilité et les applications pratiques du système.
Dans ce contexte, NVIDIA Labs a lancé SOMA-X pour résoudre les problèmes de compatibilité entre les modèles humains paramétriques. Ce système offre une topologie humaine standardisée et un système d'armature squelettique commun à tous les modèles humains paramétriques pris en charge. Au lieu de remplacer les modèles existants, il assure leur unification en mappant les formes statiques de chaque modèle sur une représentation partagée. Cette approche permet à tout modèle d'identité compatible d'être utilisé dans un pipeline d'animation unifié, sans nécessiter d'adaptateurs personnalisés ni de redirection spécifique au modèle, ce qui améliore considérablement la polyvalence et l'évolutivité du système.
Exécutez en ligne :https://go.hyper.ai/UcEI7
Kimodo : Modèles de génération de mouvements humains et robotiques
Kimodo est un modèle de diffusion de mouvement cinématique publié par NVIDIA Research en mars 2026. Entraîné sur un ensemble de données de capture de mouvement optique à grande échelle (700 heures) et disponible dans le commerce, ce modèle génère des mouvements humains et de robots humanoïdes de haute qualité et peut être contrôlé via des invites textuelles et des contraintes cinématiques riches telles que des images clés de pose du corps entier, la position/rotation de l'effecteur final, des chemins 2D et des points de passage 2D.
Kimodo prend en charge plusieurs types d'os, notamment :
SOMA : Squelette humain, 30 articulations
* Unitree G1 : Squelette de robot humanoïde à 34 articulations
* SMPL-X : Un modèle paramétrique du corps humain avec 22 articulations.
Ce modèle utilise une architecture de diffusion, combinant un encodeur de texte avec un mécanisme de contrainte de mouvement, ce qui lui permet de générer des séquences de mouvement fluides et naturelles basées sur des descriptions en langage naturel et des contraintes d'images clés.
Exécutez en ligne :https://go.hyper.ai/p99vI
FDFO : Optimisation des flux par différences finies
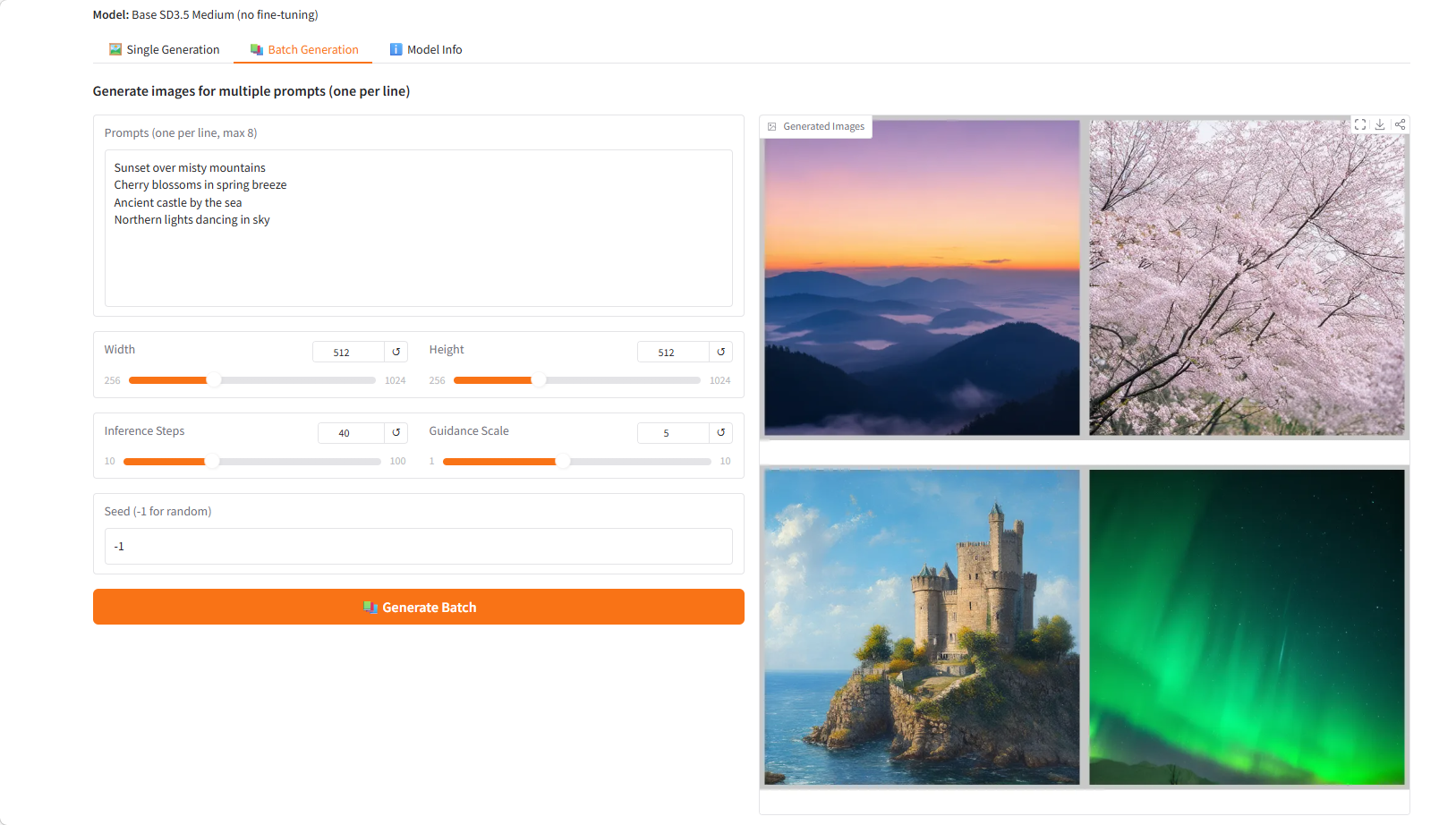
FDFO (Finite Difference Flow Optimization) est une méthode d'optimisation fine des modèles de diffusion en flux continu, publiée par NVIDIA en mars 2026 et basée sur l'estimation du gradient par différences finies. Cette méthode optimise la qualité générative du modèle en l'entraînant sur Stable Diffusion 3.5 Medium à l'aide de signaux de récompense provenant des scores du Visual Language Model (VLM) et/ou de PickScores après un apprentissage par renforcement.
FDFO résout le problème d'estimation du gradient lors du réglage fin des modèles de diffusion traditionnels en assurant un calcul de gradient efficace et stable grâce à la méthode des différences finies. Tout en préservant les capacités initiales du modèle, cette méthode améliore considérablement l'alignement, la qualité esthétique et le réalisme entre l'image générée et le texte affiché.
Exécutez en ligne :https://go.hyper.ai/ikihN