Command Palette
Search for a command to run...
La Formation Conjointe Est Possible Sans Partage De Données ! L'équipe De l'UCL Révolutionne l'examen De La Morphologie Sanguine Grâce À l'apprentissage fédéré.

L'examen morphologique du sang est une étape cruciale du diagnostic clinique des maladies hématologiques. L'observation de la morphologie cellulaire sur frottis sanguin périphérique ou par aspiration médullaire permet aux médecins de déterminer le type de leucémie, d'anémie, d'infection ou de maladie hématologique héréditaire. Cependant, ce processus est non seulement laborieux, mais aussi fortement dépendant de professionnels expérimentés. Dans les pays à revenu faible et intermédiaire, en particulier, les spécialistes qualifiés sont rares, ce qui fait du diagnostic hématologique rapide, fiable et accessible à grande échelle un enjeu majeur.
Ces dernières années, le développement de l'intelligence artificielle et de l'apprentissage profond a permis de développer de nouvelles solutions pour l'analyse morphologique du sang. Les modèles d'IA peuvent identifier automatiquement différents types de globules blancs et aider les médecins à établir des diagnostics rapides.Les recherches indiquent que l'apprentissage profond présente un potentiel important dans le diagnostic hématologique automatisé.Cependant, des défis importants persistent lors des applications concrètes : l’entraînement des modèles est fortement dépendant des données, or les données cliniques sont généralement réparties entre différents hôpitaux et présentent des variations dans les méthodes de coloration, les équipements d’imagerie et la présence de quelques types cellulaires rares. Cette hétérogénéité des données peut réduire la capacité de généralisation du modèle dans de nouveaux établissements ou auprès de nouvelles populations de patients.
Plus important encore, les données médicales impliquent la confidentialité des patients, et le partage de données entre institutions est strictement limité. Les méthodes de formation centralisées traditionnelles nécessitent généralement le regroupement de grandes quantités de données médicales sensibles et reposent sur des ressources de calcul haute performance, difficiles à mettre en œuvre dans de nombreuses institutions. Comment parvenir à une formation collaborative multi-institutionnelle tout en protégeant la confidentialité est devenu un enjeu majeur qui doit être traité de toute urgence dans le domaine de l'IA médicale.
Dans ce contexte,Une équipe de recherche du département d'informatique de l'University College London (UCL) a proposé un cadre d'apprentissage fédéré pour l'analyse de la morphologie des globules blancs.Cela permet aux établissements de mener des formations collaboratives sans échanger de données. Utilisant des frottis sanguins provenant de plusieurs sites cliniques, le modèle fédéré apprend des représentations de caractéristiques robustes et indépendantes du domaine, tout en garantissant la confidentialité totale des données. Des évaluations sur des réseaux convolutionnels et des architectures basées sur le Transformer démontrent que la formation fédérée surpasse la formation centralisée en termes de performances inter-sites et de généralisation à des établissements inconnus.
Les résultats de recherche connexes, intitulés « MORPHFED : Apprentissage fédéré pour l'analyse morphologique sanguine interinstitutionnelle », ont été publiés en tant que prépublication sur arXiv.
Points saillants de la recherche :
* Comparée à la formation centralisée, la formation fédérée démontre une performance supérieure sur l'ensemble des sites et sa capacité à se généraliser à des institutions inconnues.
Cette méthode permet la formation collaborative de modèles entre institutions sans partage de données brutes, offrant ainsi une solution viable pour les environnements de soins de santé aux ressources limitées.

Adresse du document :
https://arxiv.org/abs/2601.04121
Suivez notre compte WeChat officiel et répondez « MORPHFED » en arrière-plan pour obtenir le PDF complet.
Ensemble de données : reflétant l'hétérogénéité des contextes cliniques réels
Cette étude a utilisé des données de frottis sanguins provenant de plusieurs institutions médicales afin de garantir que les données d'entraînement couvrent non seulement différents types de cellules, mais reflètent également l'hétérogénéité des situations cliniques réelles.
Plus précisément, l'étude a utilisé des ensembles de données indépendants provenant de deux centres.Ces deux ensembles de données contiennent 11 types cellulaires communs (tels que les neutrophiles, les éosinophiles, les basophiles, les promyélocytes, etc.).Il assure la cohérence des objectifs de classification tout en préservant les différences de coloration et d'imagerie, et est utilisé pour tester la capacité de généralisation de l'apprentissage fédéré dans des environnements hétérogènes réels.
La figure suivante illustre la répartition des différentes catégories de clients.
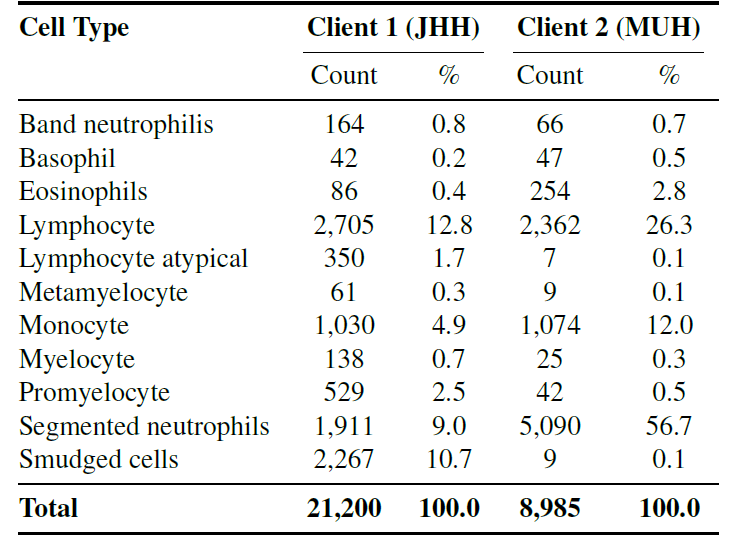
L'image ci-dessous présente des exemples de types cellulaires issus de deux ensembles de données d'entraînement.La différence de style de coloration est clairement observable, ce qui correspond précisément au biais des données que le modèle doit surmonter.
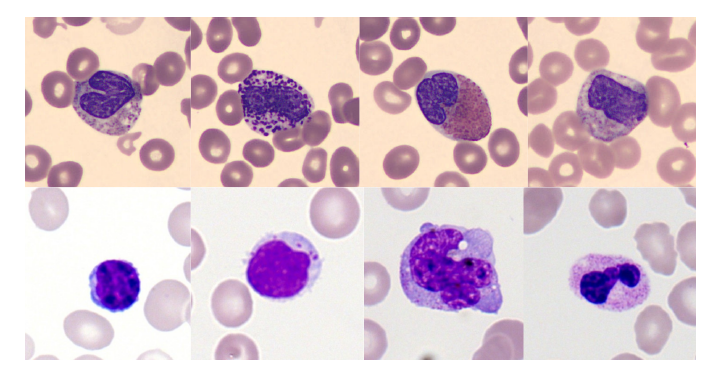
De plus, afin d'évaluer de manière indépendante les performances du modèle sur des données institutionnelles totalement inédites,L’étude a conservé 12 992 images de l’hôpital clinique de Barcelone (Client 3).Cet ensemble de données sert de validation externe. Il comprend divers dispositifs d'imagerie, méthodes de coloration et populations de patients, et est utilisé pour tester la capacité de généralisation du modèle dans des scénarios réels et interinstitutionnels.
Deux types d'architectures d'apprentissage profond et quatre stratégies d'agrégation fédérées
Cette étude utilise deux types d'architectures d'apprentissage profond :
* ResNet-34 : Une architecture classique basée sur des réseaux neuronaux convolutifs (CNN), utilisant des poids pré-entraînés ImageNet.
* DINOv2-Small : Basé sur le Vision Transformer auto-supervisé (ViT), il capture les caractéristiques globales de l'image grâce à un apprentissage auto-supervisé.
L'entraînement suit un protocole unifié : le modèle fédéré effectue 5 cycles de communication globale, chaque client effectuant 5 cycles d'entraînement locaux par cycle, pour un total de 25 cycles d'entraînement ; le modèle de référence centralisé utilise 25 cycles d'entraînement et effectue une validation croisée à 4 plis, comme illustré dans la figure ci-dessous.Les données ont été divisées en un ensemble d'entraînement 60%, un ensemble de validation 13.33%, un ensemble de test local 13.33% et un ensemble de test global 13.33%.Toutes les images ont été redimensionnées à 224×224 pixels et une stratégie d'augmentation de données conservatrice (translation ±10%, rotation ±5°) a été employée pour préserver les informations morphologiques diagnostiques.
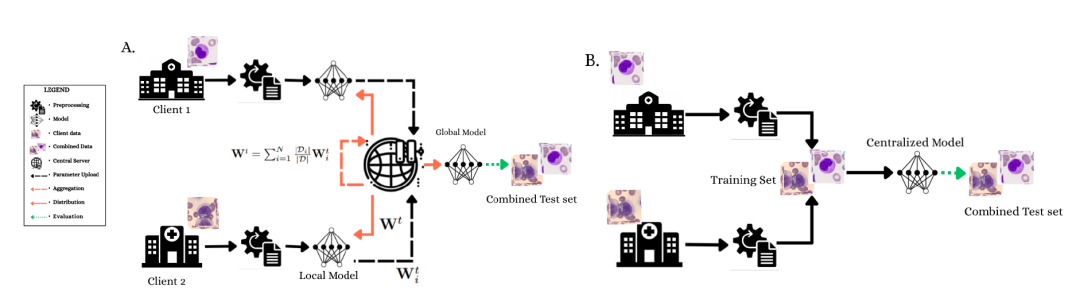
(A) Le cadre d'apprentissage fédéré démontre un processus de formation collaborative préservant la confidentialité dans lequel le Client 1 et le Client 2 entraînent le modèle localement et les paramètres sont agrégés sur un serveur central.
(B) Paradigme d'entraînement centralisé avec accès complet aux ensembles de données fusionnés et validation croisée à 4 plis.
Les deux architectures ont utilisé un réglage fin sélectif : ResNet-34 a figé les premières couches et n'a entraîné que les trois derniers blocs résiduels (environ 11 millions de paramètres) ; DINOv2-Small a figé les huit premiers blocs Transformer (0 à 7) et a entraîné les blocs 8 à 11 (environ 9 millions de paramètres). Les données du client 3 ont été conservées isolées tout au long du processus d'entraînement et utilisées uniquement pour évaluer la capacité de généralisation du modèle final à de nouvelles données institutionnelles.
Dans le cadre de l'apprentissage fédéré, le serveur central est responsable de la coordination de l'entraînement et de la distribution des paramètres globaux, mais n'accède pas aux données originales ; le client s'entraîne localement et ne renvoie que les mises à jour des paramètres.
L'étude a utilisé quatre stratégies d'agrégation fédérée :
* FedAvg : Calcule une moyenne pondérée des paramètres du client, qui est sensible aux distributions de classes extrêmes.
* FedMedian : Calcule la valeur médiane de chaque coordonnée. Cette fonction est robuste aux clients anormaux et aux erreurs byzantines, mais peut atténuer les signaux des classes minoritaires.
* FedProx : Ajoute des contraintes proximales à la fonction objectif locale pour améliorer la stabilité de convergence sur des données non-IID.
* FedOpt : Utilise l'optimisation adaptative (Adam) sur les gradients agrégés pour ajuster dynamiquement le taux d'apprentissage afin de faire face à l'hétérogénéité des clients et d'accélérer la convergence.
De plus, afin de remédier au problème important de déséquilibre des classes, l'étude combine la fonction de perte focale, l'échantillonnage aléatoire pondéré et l'accumulation de gradients pour garantir que les signaux d'entraînement des classes minoritaires ne soient pas négligés. L'écrêtage du gradient (norme maximale de 1,0) assure une convergence stable pendant l'entraînement.
Les performances du modèle ont été évaluées à l’aide d’une précision équilibrée, en mettant l’accent sur la capacité de généralisation interinstitutionnelle afin de tester la robustesse du modèle face à des données provenant de différents protocoles d’imagerie et populations de patients.
La formation fédérée démontre d'excellentes performances sur différents sites et sa capacité à se généraliser à des institutions inconnues.
Pour vérifier l'efficacité du cadre d'apprentissage fédéré, les chercheurs ont mené une évaluation conjointe de l'ensemble de tests et une évaluation de la généralisation des données distribuées externes.
① Évaluation conjointe de l'ensemble de tests
Le modèle a été évalué sur un jeu de données commun contenant des données provenant de deux clients, et les résultats sont présentés dans le tableau ci-dessous. Différentes méthodes d'agrégation présentent des différences significatives de performance selon les architectures.
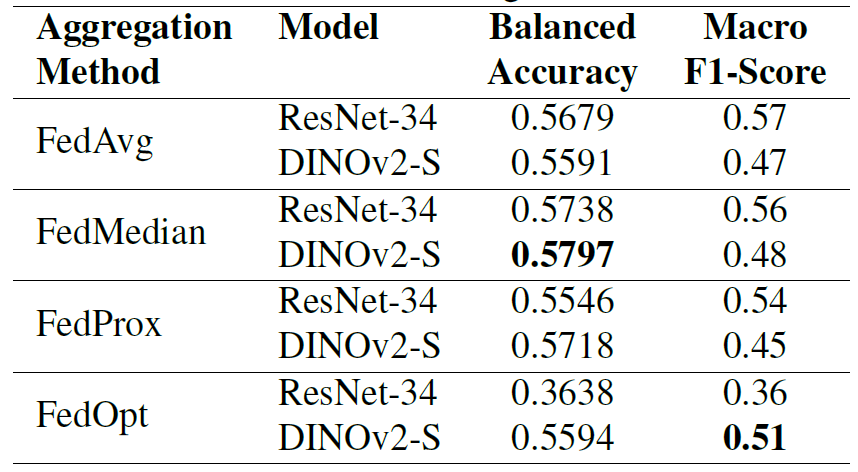
Il convient de noter que FedOpt présente une volatilité extrême : ses performances sont très mauvaises sur ResNet-34 (précision équilibrée de 0,3638), tandis qu'il conserve des performances compétitives sur DINOv2-S (précision équilibrée de 0,5594).En comparaison, FedAvg et FedProx ont affiché des performances relativement stables sur les deux modèles ;FedMedian a obtenu les résultats les plus constants sur les deux architectures, atteignant une précision équilibrée de 0,5738 pour ResNet-34 et de 0,5797 pour DINOv2-S.
Les résultats montrent que l'apprentissage fédéré améliore significativement les performances, démontrant les avantages de l'entraînement collaboratif sans partage de données par rapport aux modèles entraînés uniquement à partir des données d'un seul établissement (58% vs 52%, précision équilibrée). Bien que les modèles fédérés soient légèrement moins performants que ceux entraînés de manière centralisée sur l'ensemble des données, ils atteignent une précision comparable tout en garantissant la confidentialité totale des données.
② Évaluation de la généralisation des données distribuées en externe
Les évaluations réalisées sur l'ensemble de données de validation externe Client 3 de Barcelone montrent que les deux méthodes fédérées (FedMedian et FedOpt) surpassent l'entraînement centralisé sur des données institutionnelles totalement inédites (précision équilibrée : 67% contre 64%), comme indiqué dans le tableau ci-dessous. Cela indique que…L'exposition à des caractéristiques institutionnelles hétérogènes (telles que l'équipement d'imagerie, les populations de patients et les méthodes de coloration) pendant l'entraînement fédéré aide le modèle à apprendre des caractéristiques morphologiques plus généralisables.
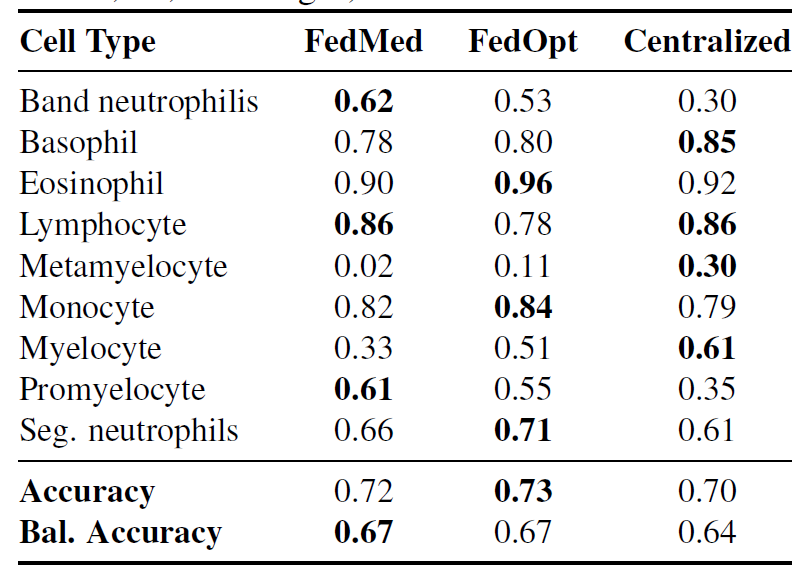
FedMedian a montré des améliorations particulièrement significatives dans une minorité de types cellulaires : neutrophiles en bande F1 : 0,62 contre neutrophiles centraux 0,30 (une augmentation de 1071 TP3T), et promyélocytes F1 : 0,61 contre neutrophiles centraux 0,35 (une augmentation de 741 TP3T).Les résultats montrent que les caractéristiques diagnostiques ont été efficacement préservées dans le cadre de différents protocoles institutionnels.Cependant, l’identification des métamyélocytes reste difficile pour toutes les méthodes (F1 : 0,02–0,30), reflétant la difficulté fondamentale d’apprendre des représentations robustes à partir de classes extrêmement rares.
③ La loi d'interaction entre l'architecture et la stratégie d'agrégation
Les chercheurs ont également identifié des interactions clés entre l'architecture et la stratégie d'agrégation : FedMedian offre une robustesse inter-architectures, mais est préjudiciable aux classes rares ; FedOpt préserve mieux la fidélité du signal cellulaire dans les classes minoritaires, mais est sensible à l'architecture. L'architecture Transformer pré-entraînée de DINOv2-S présente une plus grande robustesse face aux distributions de données non i.i.d., tandis que ResNet-34 est plus sensible aux conflits de gradients.
Globalement, ces résultats positionnent l'apprentissage fédéré comme un cadre robuste, respectueux de la vie privée et généralisable pour l'analyse d'images hématologiques.
L'apprentissage fédéré devient essentiel pour briser les « silos de données » du secteur de la santé.
L'apprentissage fédéré est un paradigme d'apprentissage automatique collaboratif pour les environnements de données distribués. Son concept fondamental est d'entraîner conjointement des modèles sans centraliser les données d'origine. Dans un cadre d'apprentissage fédéré, les institutions participantes (telles que les hôpitaux, les laboratoires ou les centres de recherche) entraînent leurs modèles localement, en téléchargeant uniquement les paramètres du modèle ou les mises à jour des gradients sur un serveur central. Ce serveur agrège ensuite ces mises à jour, génère un modèle global et le distribue à chaque nœud pour un entraînement itératif. Grâce à ce mécanisme où les données restent dans leur domaine et les modèles collaborent,L’apprentissage fédéré permet le partage des connaissances entre institutions tout en protégeant efficacement la confidentialité des données et en répondant aux exigences strictes de conformité en matière de données.
Ces dernières années, de nombreuses organisations se sont efforcées de renforcer le secteur de la santé grâce à l'apprentissage fédéré. Owkin, une entreprise de biotechnologie spécialisée dans l'IA de bout en bout, en est un exemple typique. Elle a été reconnue comme l'une des 20 startups IA les plus prometteuses de France, l'une des startups médicales et technologiques les plus remarquables de 2023, lauréate du prix de la meilleure technologie médicale et figurant parmi les 50 entreprises IA les plus influentes de Forbes.
Owkin travaille à permettre à la technologie d'IA d'identifier différents biomarqueurs dans les données multimodales des patients, de classer les patients en sous-groupes, d'associer chaque patient à la meilleure cible de traitement, de promouvoir le développement ciblé de médicaments, d'optimiser les outils de diagnostic des maladies et de parvenir à une médecine véritablement personnalisée.La clé pour atteindre les objectifs ci-dessus réside dans la manière de partager les données tout en garantissant la confidentialité des données des patients ?Pour remédier à ce problème, Owkin utilise l'apprentissage fédéré. Afin de promouvoir l'adoption de cette technologie, Owkin a rendu open source son logiciel d'apprentissage fédéré, Substra, qui peut être utilisé dans la recherche clinique, le développement de médicaments et d'autres applications.
Adresse open source :
En imagerie médicale, l'apprentissage fédéré est considéré comme une approche technologique clé pour surmonter les problèmes liés aux silos de données et au respect de la vie privée. Les données d'imagerie médicale sont extrêmement sensibles et impliquent la confidentialité des données des patients et des réglementations strictes (telles que le RGPD et la loi HIPAA). La formation centralisée traditionnelle se heurte souvent à des obstacles pratiques comme les approbations éthiques, les risques juridiques et les restrictions sur les transferts de données transfrontaliers. L'apprentissage fédéré permet à différents hôpitaux d'entraîner conjointement des modèles sans partager les données d'imagerie brutes, améliorant ainsi la capacité de généralisation du modèle à différents appareils, protocoles de coloration et populations de patients.Les recherches existantes ont montré que l'apprentissage fédéré peut atteindre des performances de généralisation interinstitutionnelles proches, voire supérieures, à celles de la formation centralisée dans des domaines tels que l'imagerie radiologique, la pathologie numérique et l'imagerie par ultrasons.Elle fait preuve d'une plus grande robustesse, notamment lors des tests sur des données externes.
D'un point de vue plus large, le modèle d'« intelligence collaborative distribuée », représenté par l'apprentissage fédéré, devient une infrastructure essentielle au déploiement à grande échelle de l'IA médicale. Il offre non seulement une voie viable pour l'entraînement de modèles médicaux à grande échelle respectueux de la vie privée, mais pose également les fondements technologiques des systèmes d'aide à la décision clinique interinstitutionnels et des plateformes mondiales de recherche médicale collaborative. Dans des domaines spécifiques tels que l'analyse de la morphologie sanguine, l'apprentissage fédéré devrait permettre à l'IA de passer d'applications de laboratoire mono-institutionnelles à des services de diagnostic intelligents de niveau clinique, déployés à l'échelle interrégionale et intersystème, apportant ainsi un soutien crucial à la médecine de précision et à la santé numérique.
Références :
1.https://arxiv.org/abs/2601.04121
2.https://mp.weixin.qq.com/s/Lf6N7EUHlhibLNc9YXWjTQ








