Command Palette
Search for a command to run...
À Partir De Données Cliniques Issues De 11 647 Cas, Une Équipe Française a Réussi, Pour La Première Fois, À Prédire Avec Précision Le Double Risque De Mortalité Lors D’une Transplantation Hépatique Pour Carcinome Hépatocellulaire Grâce À L’apprentissage automatique.
Le cancer du foie, en raison de ses stades précoces insidieux et de sa progression rapide, est depuis longtemps considéré comme le « roi des cancers ». Parmi les différents types de cancers du foie, le carcinome hépatocellulaire (CHC) est le plus fréquent, représentant entre 70 et 90 millions de cas de cancers primitifs du foie. Aux stades précoces, la transplantation hépatique est souvent le traitement radical le plus nécessaire et constitue le dernier espoir de survie pour de nombreux patients atteints de CHC.
Cependant, la pénurie extrême d'organes rend cet espoir de vie d'autant plus précieux. Plus difficile encore est le fait que les candidats à la transplantation hépatique pour un carcinome hépatocellulaire sont constamment confrontés à la double menace de décès par insuffisance hépatique et progression tumorale ; ces deux facteurs sont étroitement liés et s'influencent mutuellement, augmentant considérablement le risque de décès pendant la période d'attente. Par conséquent,L’évaluation précise du risque de décès pendant la période d’attente pour les candidats à une transplantation hépatique pour un carcinome hépatocellulaire est non seulement essentielle pour optimiser la priorité de la liste d’attente et parvenir à une répartition équitable des donneurs rares, mais aussi un enjeu fondamental pour sauver efficacement chaque patient et préserver l’espoir de vie durement acquis.
Auparavant, les méthodes traditionnelles d'évaluation du risque, telles que les scores de Child-Pugh, d'albumine-bilirubine (ALBI) et de MELD (Model for End-Stage Liver Disease), étaient largement utilisées pour évaluer le risque de maladie hépatique. Cependant, elles présentaient des lacunes importantes face à la complexité de la situation des patients atteints de carcinome hépatocellulaire (CHC) : ces méthodes se concentraient soit sur l'évaluation de la fonction hépatique et du degré de cirrhose, soit uniquement sur la prédiction de la progression tumorale, sans prendre en compte simultanément les deux risques. Même avec le développement ultérieur de systèmes de score complets tels que HALT-HCC et le modèle de Mehta, qui peuvent considérer les deux risques simultanément,De plus, en raison des limitations des modèles linéaires, des pondérations variables fixes et des mesures statiques à un seul moment donné, il est impossible de saisir les interactions entre les facteurs d'influence et les changements de risque dans la progression dynamique de la maladie, ce qui rend difficile la réalisation d'une évaluation individualisée précise du risque.
En réponse à ce point douloureux sur le plan clinique,Une équipe de recherche de Telecom Sud-Paris et de l'Université Paris-Saclay en France a proposé un cadre d'apprentissage automatique qui intègre l'apprentissage d'ensemble (EL) avec l'analyse Schapel Additive exPlanations (SHAP).Cette étude propose une nouvelle approche pour évaluer le risque de mortalité chez les candidats à la transplantation hépatique pour un carcinome hépatocellulaire (CHC). À partir des données cliniques de 11 647 patients, elle compare trois modèles d'ensemble : Random Forest (RF), XGBoost et LightGBM. De plus, en intégrant les valeurs SHAP dans l'espace de faible dimension UMAP (Uniform Manifold Approximation and Projection) et en les combinant à l'algorithme K-medoids pour le clustering supervisé, l'étude a mis en évidence que le dysfonctionnement hépatique et la progression tumorale constituent les deux principaux facteurs de risque de décès chez les patients atteints de CHC.
Cette étude comble précisément une lacune des modèles d'apprentissage automatique précédents pour l'évaluation précise des candidats à la transplantation hépatique pour le CHC, en particulier dans les études impliquant des risques doubles.Cette étude permet une prédiction précise et une interprétation clinique de la mortalité pendant la période d'attente de 3 mois pour les candidats à une transplantation hépatique pour un carcinome hépatocellulaire, fournissant un nouvel outil pour la prise de décision clinique et la stratification des risques chez les patients atteints de carcinome hépatocellulaire subissant une transplantation hépatique.
Les résultats, intitulés « Prédiction explicable de la mortalité chez les candidats à la transplantation hépatique atteints de carcinome hépatocellulaire : une approche de regroupement supervisé », ont été publiés dans la revue Health Data Science.
Points saillants de la recherche :
* Cette étude est la première étude exhaustive à utiliser des modèles d'apprentissage automatique pour analyser en profondeur le risque de mortalité des candidats à la transplantation hépatique pour un carcinome hépatocellulaire inscrits sur la liste d'attente.
* En utilisant SHAP + UMAP + K-medoids, sept sous-groupes de risque cliniquement explicables ont été stratifiés pour identifier les principaux facteurs du double risque.
* Le nouveau score de risque ELM-HCC, construit sur la base du dépistage SHAP de 8 variables clés, démontre une précision prédictive significativement supérieure à celle des scores traditionnels.
* Cette étude est la première à intégrer des variables dynamiques clés (telles que l'AFP_DIFF) dans l'évaluation des risques des candidats à la transplantation hépatique pour un CHC, clarifiant leur rôle en tant que prédicteur clé de la mortalité pendant la période d'attente pour les patients atteints de CHC.
Adresse du document :
https://spj.science.org/doi/10.34133/hds.0295
Suivez notre compte WeChat officiel et répondez « transplantation hépatique » en arrière-plan pour obtenir le PDF complet.
Consultez d'autres articles de pointe sur l'IA :
Jeu de données : Stratégie d’échantillonnage large + Introduction de variables dynamiques
Afin de réduire les facteurs de confusion,L'étude a utilisé une stratégie d'échantillonnage à grande échelle basée sur des données de bases de données publiques.
Plus précisément, les données de l'étude proviennent des fichiers Standard Transplant Analysis and Research (STAR) de l'Organ Procurement and Transplantation Network (OPTN) et de l'United Network for Organ Sharing (UNOS), couvrant les patients adultes atteints de CHC qui n'ont pas subi de transplantation d'organes multiples et qui ont été enregistrés entre le 27 février 2002 et le 30 septembre 2023.
Cette étude visait à prédire la mortalité durant la période d'attente de trois mois avant une transplantation hépatique chez les patients atteints de carcinome hépatocellulaire. L'équipe de recherche a donc divisé la population étudiée en deux groupes pour l'analyse.Les patients inscrits sur la liste d'attente depuis plus de trois mois sont appelés « patients sur la liste d'attente » ; les patients qui décèdent sur la liste d'attente dans les trois mois ou dont l'état s'aggrave et les empêche de recevoir une greffe sont appelés « patients sur la liste d'attente pour cause de mortalité ».final,La cohorte totale de l'étude comprenait 11 647 patients.Parmi ces patients, 11 199 étaient sur liste d’attente et 448 sur liste d’attente pour cause de décès. Les données incluaient des variables cliniques, biologiques et multidimensionnelles liées à la maladie.
Lors de l'étape de prétraitement des données, afin de saisir les caractéristiques dynamiques de l'état de santé des patients, l'équipe de recherche a calculé la différence de mesure continue (DIFF) de six variables clés de laboratoire impliquées dans le score traditionnel, notamment le sodium sérique, la créatinine, l'albumine, la bilirubine, l'alpha-fœtoprotéine (AFP) et le rapport international normalisé (INR), afin de saisir la trajectoire dynamique des changements dans l'état de santé des patients.Cela porte le nombre total de caractéristiques à 31 (25 variables statiques d'origine + 6 variables dynamiques nouvellement ajoutées).
Pour la gestion des valeurs manquantes, les variables numériques (taux de valeurs manquantes < 7%) ont été imputées à l'aide de la moyenne de la classe ; les enregistrements d'observation contenant des valeurs manquantes ont été directement supprimés pour les variables catégorielles (taux de valeurs manquantes < 0,1%).
Architecture du modèle : Processus intégré de bout en bout + Comparaison de plusieurs modèles d’apprentissage d’ensemble
Afin de garantir la fiabilité, l'exactitude et l'interprétabilité des prédictions de mortalité pendant la période d'attente de 3 mois pour les candidats à une transplantation hépatique pour un carcinome hépatocellulaire,L'équipe de recherche a construit un processus intégré de bout en bout qui combine l'apprentissage d'ensemble, l'analyse d'interprétabilité SHAP, la réduction de dimensionnalité UMAP et le clustering supervisé K-Medoids.Comme le montre la figure suivante :
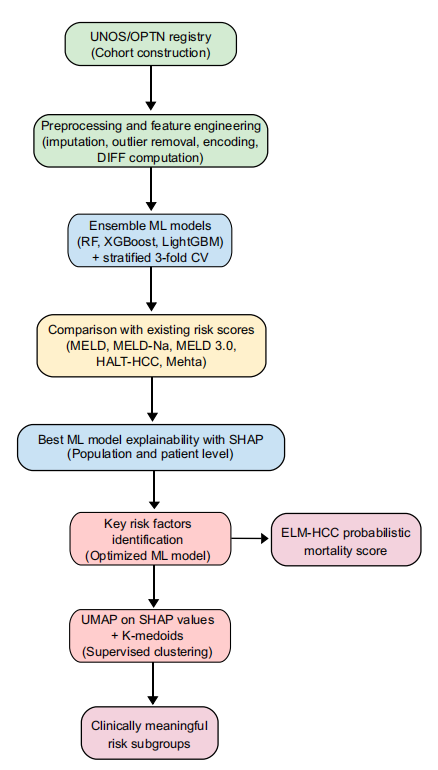
Premièrement, le modèle de base utilise un modèle d'arbre d'apprentissage d'ensemble.Ces types de modèles sont particulièrement efficaces pour le traitement des données tabulaires et hétérogènes. Afin de comparer plus précisément leurs performances, l'étude a utilisé trois modèles d'apprentissage ensemblistes de base : Random Forest, XGBoost et LightGBM. Les expériences ont été menées selon deux scénarios d'entraînement : le premier utilisait uniquement 25 variables statiques initiales ; le second utilisait 31 variables statiques et dynamiques combinées.
Deuxièmement, l’objectif de l’interprétabilité est de fournir une interprétation scientifique et raisonnable des résultats prévus, renforçant ainsi la base de la prise de décision clinique.À cette fin, l'équipe de recherche a intégré l'analyse d'interprétabilité SHAP dans le cadre afin d'identifier les principaux facteurs de risque et de révéler les prédictions du modèle.
Pour une interprétation globale, le calcul des valeurs SHAP quantifie la contribution de chaque caractéristique aux résultats de prédiction du modèle, identifiant ainsi les principaux facteurs de risque de mortalité et clarifiant la corrélation entre les caractéristiques et le risque de mortalité. Pour une interprétation locale, les graphiques de synthèse et les graphiques de force SHAP permettent de démontrer l'impact spécifique des valeurs de chaque caractéristique sur les résultats de prédiction, ainsi que la distribution des contributions des caractéristiques pour chaque patient. De plus, cette étape fournit un ensemble de caractéristiques de valeurs SHAP pour une analyse de regroupement ultérieure, remplaçant les données originales et améliorant l'interprétabilité clinique du regroupement.
Enfin, afin d'obtenir une stratification des risques plus précise pour les patients, l'attention s'est déplacée de la prédiction au niveau de la population vers une analyse spécifique à un sous-groupe.Le processus de recherche a intégré les méthodes de réduction de dimensionnalité UMAP et de clustering supervisé K-Medoids.Tout d'abord, les valeurs SHAP prédites sont intégrées dans l'espace UMAP de dimensionnalité réduite. Ensuite, l'algorithme K-Medoids est utilisé pour regrouper les valeurs SHAP intégrées dans l'espace UMAP 3D afin de découvrir des sous-groupes potentiels de patients présentant différentes caractéristiques cliniques. Cette méthode est appelée « clustering supervisé » car le regroupement est basé sur les valeurs SHAP et non sur les données originales.
Le nombre optimal de clusters a été déterminé par un premier criblage à l'aide d'indicateurs quantitatifs tels que le coefficient de silhouette et l'indice de Davies-Bouldin, puis par une validation clinique des caractéristiques de clustering via l'analyse SHAP. Le nombre optimal de clusters a finalement été fixé à 7.
Résultats expérimentaux : Le nouveau modèle a été entraîné en utilisant 8 méthodes d’évaluation traditionnelles à titre de comparaison et l’ensemble de caractéristiques optimal.
comparaison des performances du score de risque
L'étude compare les performances du cadre proposé avec huit méthodes traditionnelles d'évaluation des risques, notamment ALBI, Child-Pugh, AFP, Hazard associated with LT for HCC (HALT-HCC), le modèle Mehta, MELD et ses deux variantes MELD-Na et MELD 3.0.
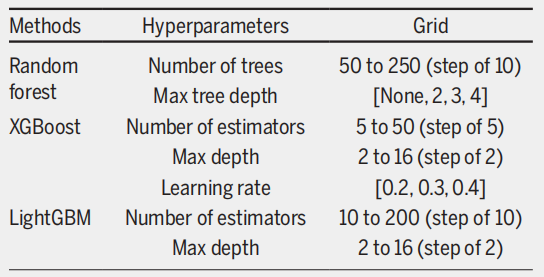
Compte tenu du fort déséquilibre des classes dans l'ensemble de données, l'étude a sous-échantillonné le groupe majoritaire (sur liste d'attente) afin de générer 30 sous-ensembles de taille similaire à celle du groupe minoritaire (décès survenus pendant la période d'attente). Une validation croisée à trois plis a été réalisée sur chaque sous-ensemble équilibré pour garantir que toutes les observations d'un même patient soient affectées soit à l'ensemble d'entraînement, soit à l'ensemble de test. Les configurations optimales d'hyperparamètres pour les trois modèles d'ensemble ont ensuite été déterminées par une recherche exhaustive, comme illustré dans la figure ci-dessous.
Les résultats montrent queDans les systèmes de notation traditionnels, le modèle Mehta est le plus performant avec une AUROC de 0,782, suivi par le HALT-HCC avec une AUROC de 0,763.Plus important encore, ces deux modèles offrent un meilleur équilibre entre sensibilité et spécificité. Si le MELD 3.0 surpasse les modèles MELD et MELD-Na de base, il souffre d'un déséquilibre entre ces deux paramètres.
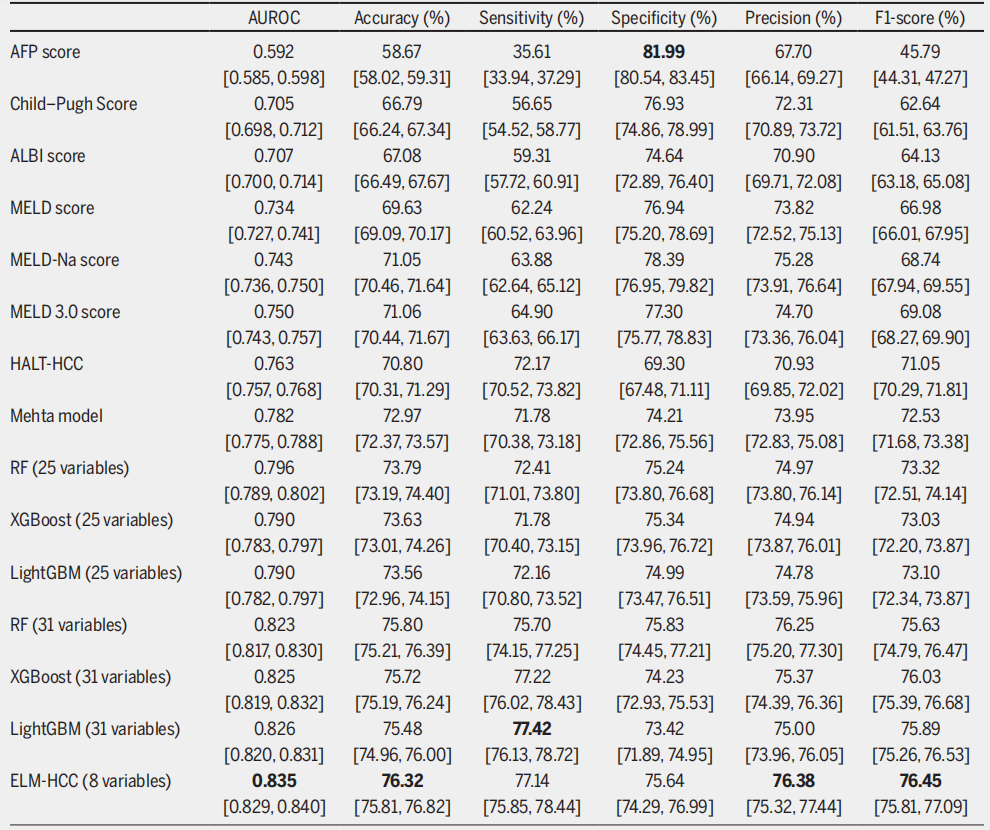
Lorsque l'expérience a été étendue à un cadre d'apprentissage d'ensemble, la précision de tous les modèles entraînés sur 25 variables statiques a surpassé celle des systèmes de notation traditionnels. Le modèle RF a obtenu les meilleurs résultats, avec une aire sous la courbe ROC (AUROC) de 0,796, et sa sensibilité (72,41 TP3T) et sa spécificité (75,241 TP3T) étaient également bien équilibrées. Après l'introduction de 31 variables dynamiques et statiques combinées, tous les modèles d'apprentissage d'ensemble ont atteint des performances encore meilleures.LightGBM a atteint une AUROC de 0,826 et la sensibilité la plus élevée de 77,42%, ce qui en fait le modèle le plus efficace pour identifier les patients à haut risque.
Analyse de la capacité à identifier les principaux facteurs de risque
Une fois les modèles entraînés, la recherche utilisera uniquement les caractéristiques les plus pertinentes pour évaluer leurs performances. À cette fin, l'équipe de recherche a utilisé deux méthodes d'évaluation de l'importance des caractéristiques, l'importance du gain et l'importance globale SHAP, afin de sélectionner les caractéristiques clés du modèle LightGBM le plus performant.
Sur la base du modèle LightGBM (le modèle le plus performant), les 8 principales caractéristiques sélectionnées à l'aide de l'importance globale SHAP permettent d'obtenir des performances optimales du modèle.Avec une aire sous la courbe ROC (AUROC) de 0,835, une sensibilité de 77,141 % (TP3T) et une spécificité de 75,641 % (TP3T), ce modèle a non seulement surpassé les résultats du criblage par importance du gain (AUROC de 0,812 avec 8 caractéristiques et atteignant un maximum de 0,828 avec 12 caractéristiques), mais également les performances de LightGBM sur un ensemble complet de 31 variables (AUROC de 0,826). Il a donc été sélectionné par l'équipe de recherche comme ensemble de caractéristiques optimal.
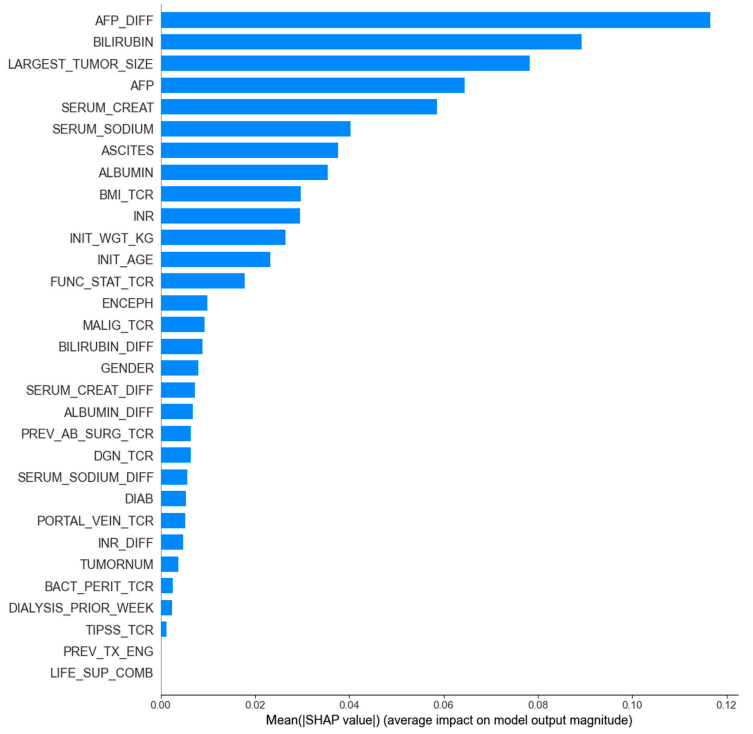
En définitive, l'étude a permis d'identifier et de construire un score de mortalité probabiliste pour les patients atteints de CHC, appelé ELM-HCC, basé sur le modèle LightGBM entraîné avec l'ensemble de caractéristiques optimal. Il convient de mentionner que…LightGBM a obtenu de meilleurs résultats en termes d'AUROC sur l'ensemble de variables simplifié par rapport à l'ensemble complet de 31 variables, démontrant ainsi que les 8 variables sélectionnées avaient un pouvoir prédictif plus fort.Par ailleurs, l'apparition d'AFP_DIFF dans les principales caractéristiques pertinentes souligne également l'importance d'intégrer des informations dynamiques.
Stratification des risques et analyse des sous-groupes
L'étude a identifié sept sous-groupes de patients présentant des caractéristiques cliniques et des niveaux de risque différents, grâce à un regroupement supervisé basé sur les valeurs SHAP. La figure B ci-dessous illustre clairement l'analyse stratifiée de la mortalité, avec des probabilités de mortalité augmentant progressivement du groupe 1 au groupe 7.
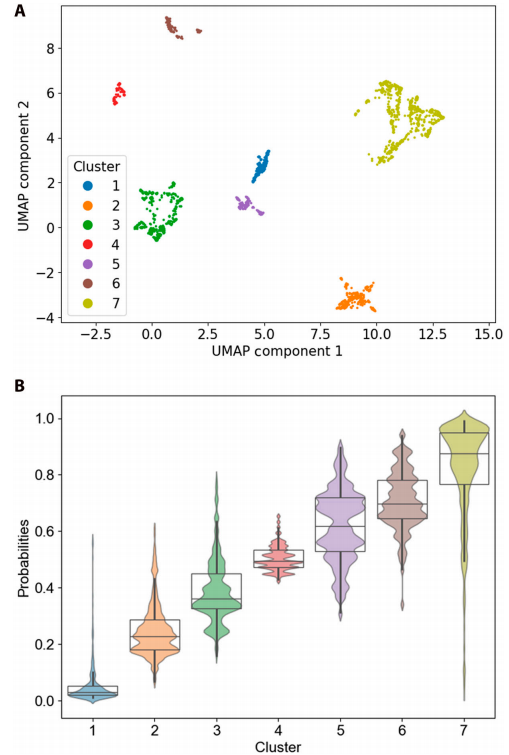
B représente le diagramme en boîte et le diagramme de population des probabilités de mortalité pour 7 observations groupées.
Une analyse plus poussée, basée sur le test de Kruskal-Wallis, a révélé des différences entre les variables des différents groupes. Comme le montre le graphique SHAP, la probabilité de décès a augmenté progressivement du groupe 1 au groupe 7 ; par exemple, la probabilité de décès pour un patient représentatif est passée de 0,03 à 0,98.Cette tendance est cohérente avec les classements observés dans les diagrammes en boîte, ce qui souligne l'efficacité de la méthode de regroupement.
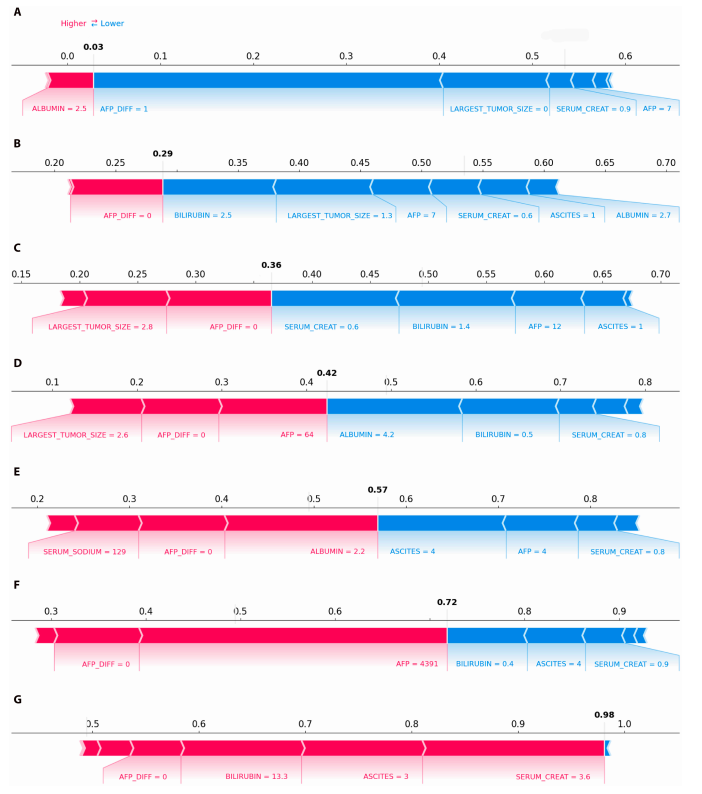
En outre, l'analyse de sous-groupes a clairement révélé deux causes principales de risque de mortalité élevé : l'insuffisance hépatique sévère (caractérisée par une bilirubinémie élevée, une créatininémie élevée et une ascite modérée, qui correspondent toutes à des valeurs SHAP positives et augmentent significativement le risque de décès) et la progression tumorale active (caractérisée par des taux élevés d'AFP).
En résumé, le cadre d'apprentissage automatique ELM-HCC, basé sur LightGBM et l'analyse d'interprétabilité SHAP, proposé dans cette étude, présente des performances nettement supérieures aux systèmes de score traditionnels pour la prédiction du risque de décès durant les trois mois d'attente pour une transplantation hépatique chez les candidats atteints de carcinome hépatocellulaire. Parallèlement, grâce à un regroupement supervisé, il identifie des sous-groupes de patients présentant des caractéristiques de risque différentes, offrant ainsi un outil d'évaluation des risques plus précis et interprétable pour la prise de décision clinique.
Méthodes innovantes d'évaluation des risques chez les candidats à la transplantation hépatique ; une approche globale comble une lacune de la recherche.
Comme mentionné précédemment, le cancer du foie représente un enjeu majeur de santé publique à l'échelle mondiale. Face à la gravité croissante de la maladie et aux exigences médicales accrues, un plan scientifiquement rigoureux et rationnel pour la sélection des candidats à la transplantation hépatique est indispensable. Dès 2002, le score MELD (Model for End-Stage Liver Disease) a été utilisé pour prioriser ces candidats. Cependant, malgré plusieurs révisions, l'attribution de ce score ne permet toujours pas de satisfaire équitablement tous les candidats.
L’apprentissage automatique, grâce à sa capacité à traiter des données multidimensionnelles et multimodales, est désormais devenu la meilleure solution pour prédire le risque de mortalité des candidats à la transplantation d’organes.
Des modèles d'apprentissage automatique ont déjà été utilisés pour prédire les taux de mortalité après une transplantation hépatique. Par exemple, une équipe conjointe du MIT, de l'UC San Francisco et de l'Université du Texas a proposé OPOM, un modèle de prédiction optimisé du taux de mortalité basé sur des arbres de classification optimaux (OCT).Sur la base de ce modèle d'attribution des foies, le nombre de décès par an peut être réduit d'environ 418 par rapport au modèle MELD, avec une diminution significative du nombre de décès/prélèvements dans toutes les régions UNOS et à tous les niveaux de gravité de la maladie.De plus, le modèle a également ajusté le nombre de foies attribués aux patients avec et sans CHC, ce qui a permis d'optimiser considérablement l'attribution des greffes de foie et de réduire la mortalité des candidats.
Titre de la thèse : Développement et validation d’une prédiction optimisée de la mortalité chez les candidats à la transplantation hépatique
Adresse du document :
https://www.sciencedirect.com/science/article/pii/S1600613522090335
Cependant, bien qu'OPOM ait donné de bons résultats, ce modèle repose sur une cohorte mixte de patients atteints et non atteints de CHC et ne prend pas spécifiquement en compte le double risque d'insuffisance hépatique et de progression tumorale auquel sont confrontés les patients atteints de CHC. ELM-HCC comble sans aucun doute cette lacune.
Enfin, cette étude non seulement améliore et approfondit les recherches antérieures, mais surtout, comme l'ont indiqué les auteurs, elle comble une lacune dans la recherche actuelle. En proposant la toute première prédiction interprétable et précise de la mortalité durant la période d'attente de trois mois pour les candidats à une transplantation hépatique pour carcinome hépatocellulaire, elle ouvre la voie à une nouvelle approche de l'apprentissage automatique appliquée à l'évaluation des risques chez les candidats à la transplantation d'organes.
Références :
1. Une équipe de recherche de Telecom Sud-Paris et de l'Université Paris-Saclay en France a proposé un cadre d'apprentissage automatique qui intègre l'apprentissage d'ensemble avec l'analyse SHAple Additive exPlanations (SHAP), offrant une nouvelle solution pour évaluer le risque de mortalité des candidats à la transplantation hépatique pour carcinome hépatocellulaire.
2.https://www.sciencedirect.com/science/article/pii/S1600613522090335








