Command Palette
Search for a command to run...
Rapport Hebdomadaire d'AI Paper | Un Rapport Spécial Sur La Recherche De Pointe Sur Les Transformers, Analysant Les Dernières Avancées En Matière De Parcimonie Structurelle, De Mécanismes De Mémoire Et d'organisation Du raisonnement.

Au cours des huit dernières années, Transformer a quasiment remodelé tout le paysage de la recherche en intelligence artificielle. Depuis que Google a proposé cette architecture dans « Attention Is All You Need » en 2017, le « mécanisme d’attention » est progressivement passé d’une technique d’ingénierie à un paradigme général pour l’apprentissage profond : du traitement automatique du langage naturel à la vision par ordinateur, de la parole et du calcul multimodal au calcul scientifique, Transformer s’impose comme le cadre de modélisation fondamental de facto.
Les acteurs de l'industrie, représentés par Google, OpenAI, Meta et Microsoft, repoussent sans cesse les limites de l'échelle et de l'ingénierie, tandis que des universités comme Stanford, le MIT et Berkeley produisent régulièrement des résultats clés en matière d'analyse théorique, d'améliorations structurelles et d'exploration de nouveaux paradigmes. À mesure que la taille des modèles, les paradigmes d'entraînement et les champs d'application s'étendent, la recherche dans le domaine des Transformers se caractérise par une forte différenciation et une évolution rapide, rendant indispensable une revue systématique et une sélection d'articles représentatifs.
Afin de permettre à davantage d'utilisateurs de connaître les derniers développements dans le domaine de l'intelligence artificielle dans le milieu universitaire, le site Web officiel d'HyperAI (hyper.ai) a désormais lancé une section « Derniers articles », qui met à jour quotidiennement les articles de recherche de pointe sur l'IA.
* Dernières publications sur l'IA:https://go.hyper.ai/hzChCCette semaine, nous avons soigneusement sélectionné pour vous 5 articles populaires sur les Transformers.Des équipes de l'Université de Pékin, de DeepSeek, de ByteDance Seed, de Meta AI et d'autres encore participent. Apprenons ensemble ! ⬇️
Recommandation de papier de cette semaine
- Mémoire conditionnelle via recherche évolutive : un nouvel axe de parcimonie pour les grands modèles de langage
Des chercheurs de l'Université de Pékin et de DeepSeek-AI ont proposé Engram, un module de mémoire conditionnelle évolutif avec une complexité de recherche O(1). En l'extrayant des premières couches du Transformer de recherche de connaissances statiques et en le complétant avec MoE, ces premières couches sont libérées pour des calculs d'inférence plus profonds. Des améliorations significatives sont obtenues sur les tâches d'inférence (BBH +5,0, ARC-Challenge +3,7), les tâches de code et de mathématiques (HumanEval +3,0, MATH +2,4) et les tâches à contexte long (Multi-Query NIAH : 84,2 → 97,0), tout en conservant le même nombre de paramètres et le même nombre d'opérations en virgule flottante (FLOPs).
Document et interprétation détaillée :https://go.hyper.ai/SlcId
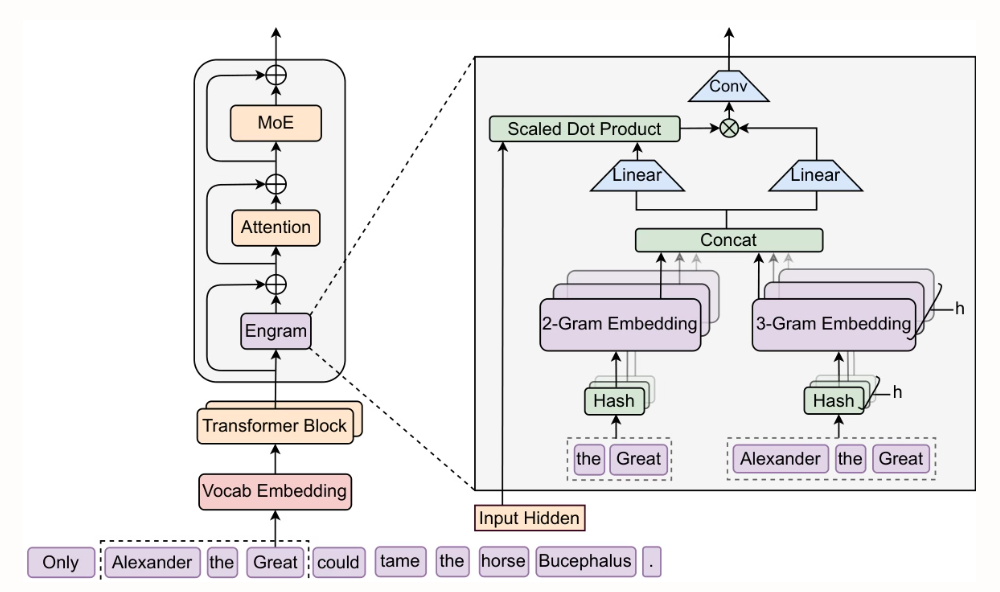
2. STEM : Mise à l’échelle des transformateurs grâce aux modules d’intégration
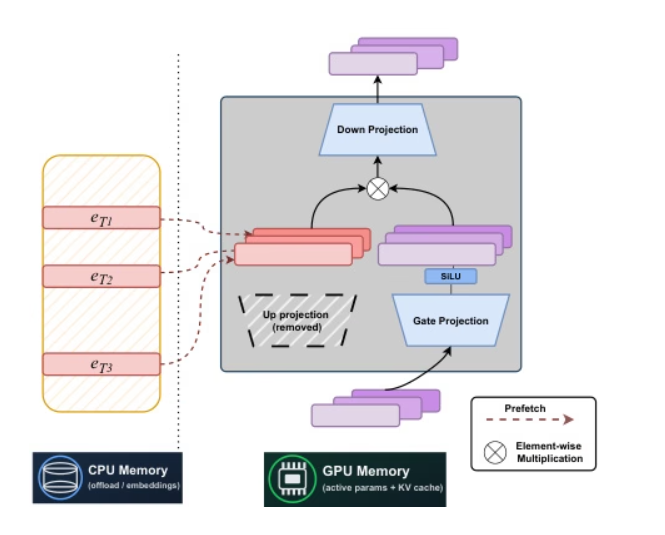
Des chercheurs de l'Université Carnegie Mellon et de Meta AI ont conjointement proposé STEM, une architecture clairsemée statique basée sur un index d'étiquettes. En remplaçant la surprojection de FFN par une recherche d'embeddings intra-couche, on obtient un entraînement stable, réduisant d'environ un tiers le nombre d'opérations en virgule flottante par étiquette et le nombre d'accès aux paramètres. De plus, les performances en contexte long sont améliorées grâce à une activation des paramètres évolutive. En découplant la capacité de calcul et de communication, STEM prend en charge le préchargement asynchrone pour décharger le processeur, exploite les embeddings avec de larges distributions angulaires pour atteindre une capacité de stockage des connaissances plus élevée et permet l'injection de connaissances interprétables et modifiables sans altérer le texte d'entrée. Dans les benchmarks de connaissances et de raisonnement, elle atteint des gains de performance allant jusqu'à 3 à 41 TP3T environ par rapport aux architectures denses de référence.
Document et interprétation détaillée :https://go.hyper.ai/NPuoj
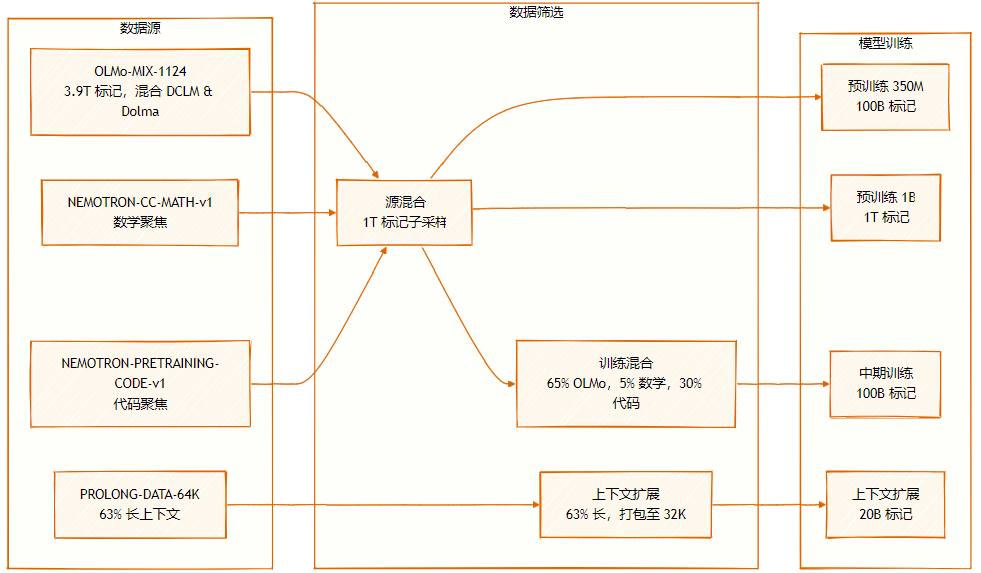
L'ensemble de données est constitué de plusieurs sources : OLMo-MIX-1124 (3.9T étiqueté), un mélange de DCLM et Dolma1.7 ; NEMOTRON-CC-MATH-v1 (orienté mathématiques) ; et NEMOTRON-PRETRAINING-CODE-v1 (orienté code).
3. SeedFold : Prédiction de la structure biomoléculaire à grande échelle
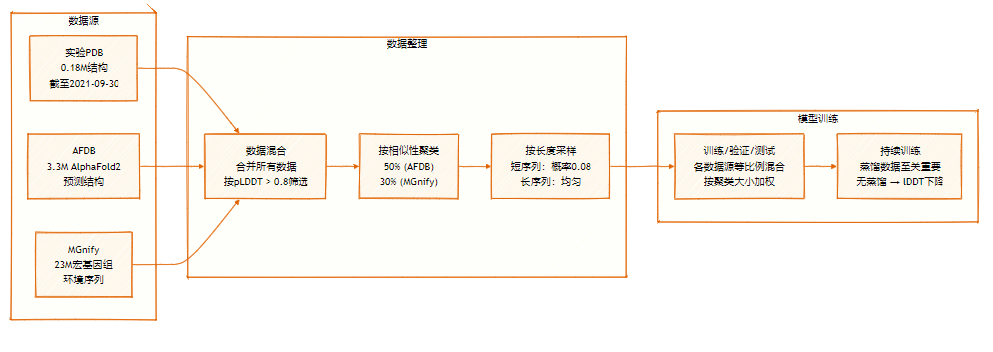
L'équipe Seed de ByteDance a proposé SeedFold, un modèle de prédiction de structures biomoléculaires évolutif. Ce modèle accroît sa capacité en élargissant la largeur du Pairformer, réduit la complexité de calcul grâce à un mécanisme d'attention triangulaire linéaire et atteint des performances de pointe sur FoldBench avec un jeu de données de distillation contenant 26,5 millions d'échantillons, tout en surpassant AlphaFold3 pour les tâches liées aux protéines.
Document et interprétation détaillée :https://go.hyper.ai/9zAID
L'ensemble de données SeedFold contient 26,5 millions d'échantillons, augmentés par distillation de données à grande échelle à partir de deux sources principales : l'ensemble de données expérimental (0,18M) et l'ensemble de données distillées d'AFDB et MGnify.
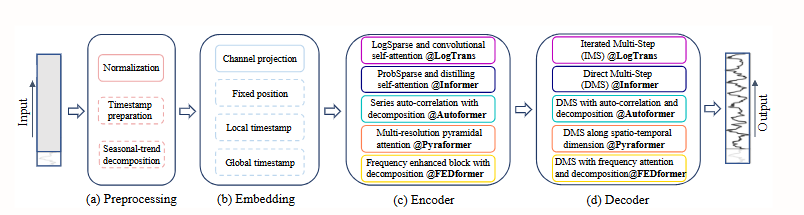
4. Les transformateurs sont-ils efficaces pour la prévision des séries temporelles ?
Cet article montre que, malgré la popularité croissante des Transformers pour la prédiction de séries temporelles, l'invariance par permutation de leur mécanisme d'auto-attention entraîne une perte d'informations temporelles cruciales. Des expériences comparatives démontrent que des modèles linéaires monocouches simples surpassent significativement les modèles Transformers complexes sur de multiples jeux de données réels. Ce résultat remet en question les orientations de recherche actuelles et appelle à une réévaluation de l'efficacité des Transformers pour les tâches de prédiction de séries temporelles.
Document et interprétation détaillée :https://go.hyper.ai/Hk05h
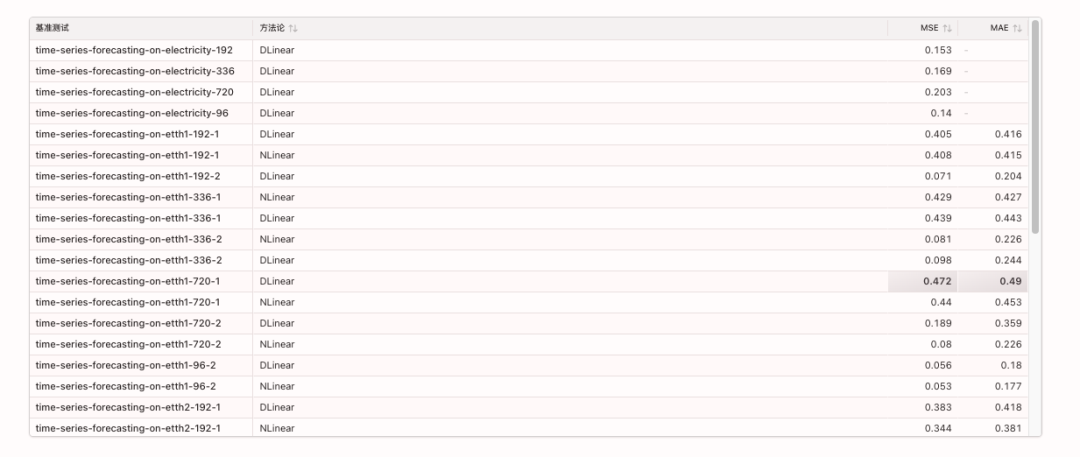
Les indicateurs de référence pertinents sont les suivants :
5. Les modèles de raisonnement engendrent des sociétés de pensée
Des chercheurs de Google, de l'Université de Chicago et du Santa Fe Institute suggèrent que les performances supérieures des modèles de raisonnement avancés tels que DeepSeek-R1 et QwQ-32B ne sont pas uniquement dues à la longueur des chaînes de pensée, mais plutôt à la simulation implicite d'une « société de pensées » : un dialogue multi-agents entre diverses perspectives, dotées de personnalités et d'expertises différentes au sein du modèle. Grâce à une interprétabilité mécaniste et à un apprentissage par renforcement contrôlé, ils démontrent avec précision une relation causale entre les comportements conversationnels (questionnement, conflit et réconciliation) et la diversité des perspectives. Ils montrent notamment que l'utilisation du marqueur d'expression « surprise » peut doubler les performances du raisonnement. Cette organisation sociale des pensées permet une exploration systématique de l'espace des solutions, ce qui suggère que les principes de l'intelligence collective – diversité, débat et coordination des rôles – constituent un fondement essentiel d'un raisonnement artificiel efficace.
Document et interprétation détaillée :https://go.hyper.ai/0oXCC
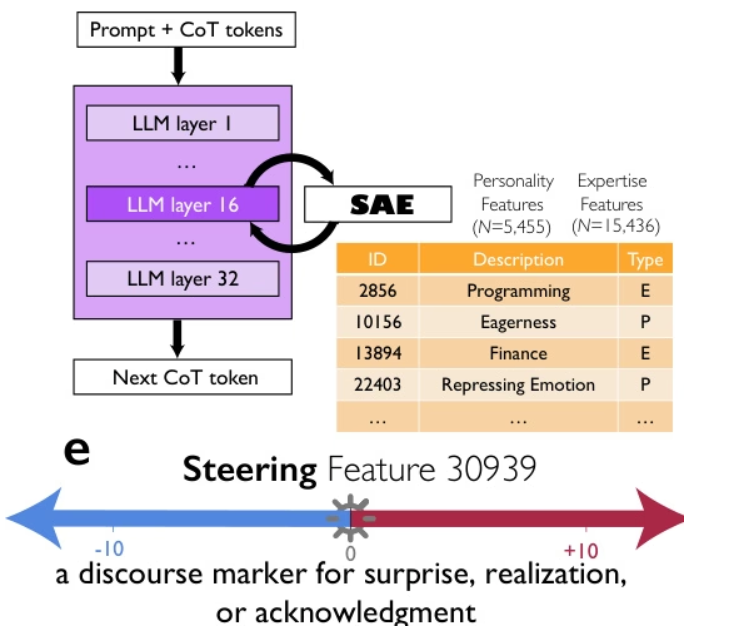
L'ensemble de données contient 8 262 problèmes de raisonnement issus de multiples domaines, couvrant la logique symbolique, la résolution mathématique, le raisonnement scientifique, le suivi d'instructions et le raisonnement multi-agents. Il prend en charge le raisonnement multi-perspectives et est utilisé pour l'entraînement et l'évaluation de modèles.
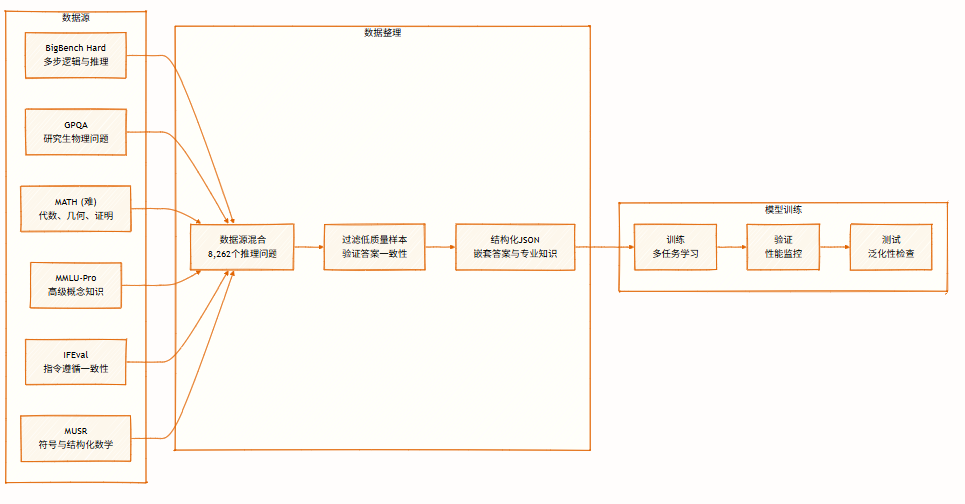
Voici l'intégralité du contenu de la recommandation d'article de cette semaine. Pour découvrir d'autres articles de recherche de pointe en IA, veuillez consulter la section « Derniers articles » du site officiel d'hyper.ai.
Nous invitons également les équipes de recherche à nous soumettre des résultats et des articles de haute qualité. Les personnes intéressées peuvent ajouter leur compte WeChat NeuroStar (identifiant WeChat : Hyperai01).
À la semaine prochaine !








