Command Palette
Search for a command to run...
Expérience Pratique | Exercices d'optimisation d'opérateurs Elementwise Basés Sur La Plateforme De Cloud Computing HyperAI
La plateforme informatique HyperAI a été officiellement lancée, offrant aux développeurs des services informatiques extrêmement stables et accélérant la concrétisation de leurs idées grâce à un environnement prêt à l'emploi, des prix GPU avantageux et d'abondantes ressources sur site.
Voici un partage d'expériences d'utilisateurs d'HyperAI concernant l'optimisation des opérateurs Elementwise sur la plateforme ⬇️
Une petite annonce concernant un événement !
Le programme de test bêta d'HyperAI recrute toujours, avec une prime maximale de $200. Cliquez ici pour en savoir plus :Jusqu'à $200 peuvent être obtenus ! Le recrutement pour la bêta d'HyperAI est officiellement ouvert !
Objectif principal :Optimiser un opérateur d'addition élément par élément simple (C = A + B) à partir de son implémentation de base pour se rapprocher des performances natives de PyTorch (c'est-à-dire se rapprocher de la limite de bande passante mémoire du matériel).
Principaux défis :Elementwise est un opérateur typique à contrainte de mémoire.
- La puissance de calcul n'est pas le facteur limitant (les GPU effectuent des additions incroyablement rapidement).
- Le goulot d'étranglement réside dans l'équilibre entre l'offre et la demande du côté « émission des instructions » et du côté « transport de la mémoire vidéo ».
- L'essence de l'optimisation est de déplacer le plus de données (octets) avec le moins d'instructions.
Préparation de l'environnement expérimental et de la puissance de calcul
L'optimisation de l'opérateur Elementwise exploite au maximum la bande passante de la mémoire GPU. Afin d'obtenir des données de référence aussi précises que possible, cet exercice pratique a été réalisé sur la plateforme de cloud computing HyperAI (hyper.ai). J'ai spécifiquement choisi une instance haut de gamme pour tirer le meilleur parti des performances de l'opérateur.
- GPU : NVIDIA RTX 5090 (32 Go de VRAM)
- BÉLIER: 40 Go
- Environnement: PyTorch 2.8 / CUDA 12.8
Bonus : Si vous souhaitez également tester la RTX 5090 et reproduire le code de cet article, vous pouvez utiliser mon code de réduction exclusif « EARLY_dnbyl » lors de votre inscription sur app.hyper.ai pour recevoir 1 heure de puissance de calcul gratuite sur une 5090 (valable 1 mois).
Lancez rapidement une instance RTX 5090
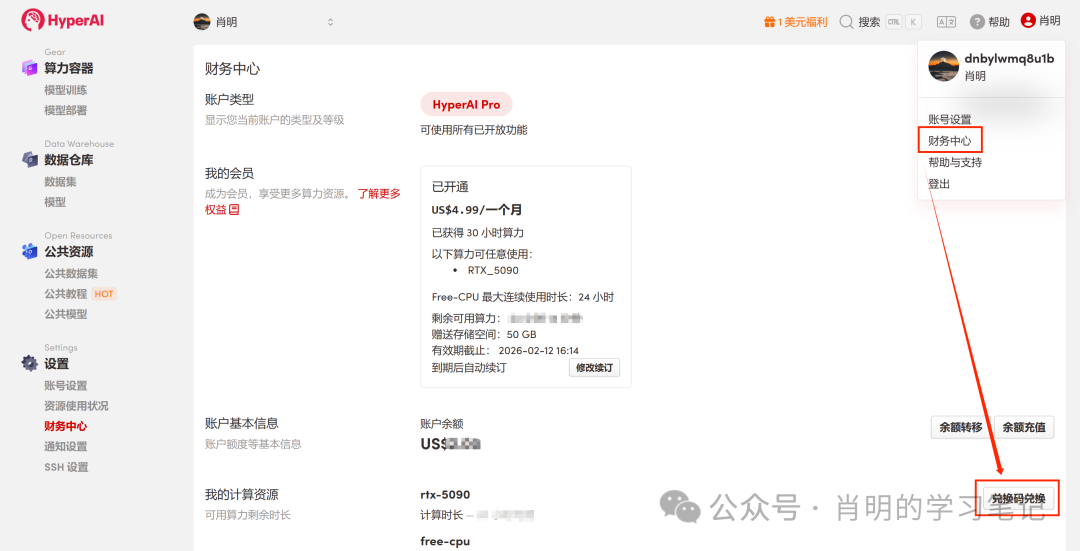
1. Inscription et connexion : Après avoir créé un compte sur app.hyper.ai, cliquez sur « Centre financier » dans le coin supérieur droit, puis sur « Utiliser un code » et saisissez « EARLY_dnbyl » pour recevoir une puissance de calcul gratuite.
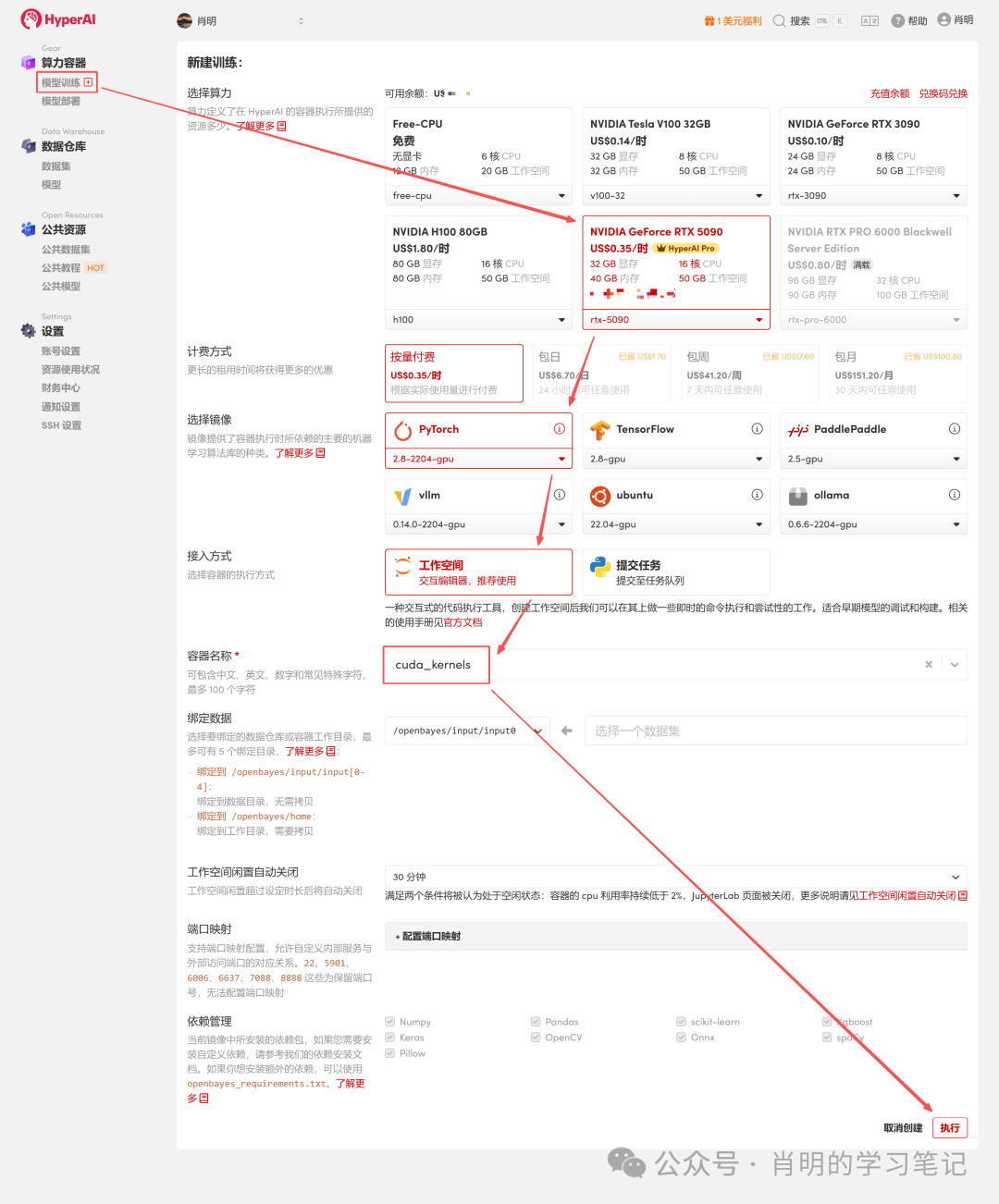
2. Créer un conteneur : Cliquez sur « Entraînement du modèle » dans la barre latérale gauche -> « Sélectionnez la puissance de calcul : 5090 » -> « Sélectionnez l’image : PyTorch 2.8 » -> « Méthode d’accès : Jupyter » -> « Nom du conteneur : Saisissez n’importe quel nom, par exemple cuda_kernels » -> « Exécuter ».
3. Ouvrez Jupyter : une fois l’instance démarrée (son statut passe à « En cours d’exécution »), cliquez simplement sur « Ouvrir l’espace de travail » pour l’utiliser immédiatement.
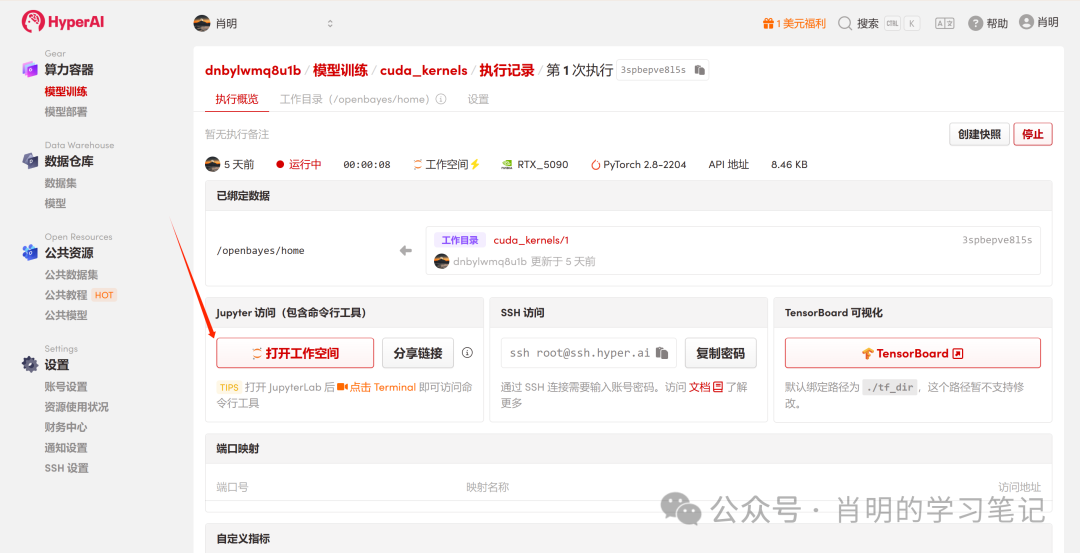
La plateforme permet de se connecter via Jupyter ou VS Code SSH Remote. J'utilise Jupyter et j'ai exécuté la commande suivante dans la première cellule :
import os
import torch
from torch.utils.cpp_extension import loadPhase 1 : Série d'optimisation FP32
Version 1 : FP32 Baseline (Version scalaire)
C'est la manière la plus intuitive de l'écrire, mais son efficacité du point de vue du GPU est moyenne.
Analyse approfondie des principes :
- Couche de commande :Le planificateur émet une instruction LD.E (chargement 32 bits).
- Couche d'exécution (Warp)Conformément au principe SIMT, les 32 threads du Warp exécutent simultanément cette instruction.
- Volume de données :Chaque thread déplace 4 octets. Volume total de données =32 threads × 4 octets = 128 octets .
- Transactions en mémoire :L'unité LSU (Load Store Unit) combine ces 128 octets en une seule transaction de mémoire vidéo.
- Analyse des goulots d'étranglement :Bien que la fusion de mémoire soit utilisée, l'efficacité des instructions reste faible. Pour déplacer 128 octets de données, le SM (Streaming Multiprocessor) doit consommer un cycle d'émission d'instruction. Face à des volumes de données importants, l'unité d'émission d'instructions est saturée et devient un goulot d'étranglement.
Code (v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}Version 2 : FP32x4 vectorisé
Méthode d'optimisation : Utiliser le type float4 pour forcer la génération d'instructions de chargement de 128 bits.
Analyse approfondie des principes (points d'optimisation clés) :
- Couche de commande :Le planificateur émet une instruction LD.E.128 (chargement 128 bits).
- Couche d'exécution (Warp) :Le warp comporte 32 threads fonctionnant simultanément, mais cette fois chaque thread déplace 16 octets (float4).
- Volume de données:Volume total de données = 32 threads x 16 octets = 512 octets.
- Transactions en mémoire :Lorsque l'unité LSU détecte une requête continue de 512 octets, elle initie quatre transactions mémoire consécutives de 128 octets.
- Comparaison de l'efficacité :Valeur de référence : 1 instruction = 128 octets. Valeur vectorisée : 1 instruction = 512 octets.
- en conclusion:L'efficacité des instructions est multipliée par 4. SM ne nécessite qu'un quart du nombre d'instructions initial pour exploiter pleinement la même bande passante mémoire. Cela libère totalement l'unité de distribution des instructions, déplaçant ainsi le goulot d'étranglement vers la bande passante mémoire.
Code (v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");Deuxième phase : Série d'optimisation FP16
3. Version 3 : FP16 Baseline (Scalaire demi-précision)
Utilisez la moitié (FP16) pour économiser la mémoire vidéo.
Analyse approfondie des principes sous-jacents (Pourquoi est-ce si lent ?) :
- Mode d'accès à la mémoire :Dans le code, idx est consécutif, donc l'accès par 32 threads est complètement fusionné.
- Volume de données :32 threads × 2 octets = 64 octets (nombre total de requêtes pour un warp).
- Comportement du matériel :Le contrôleur de mémoire (LSU) génère deux transactions de secteur mémoire de 32 octets. Remarque : aucune bande passante n’est gaspillée ; toutes les données transmises sont valides.
Le véritable goulot d'étranglement :
1. Instructions reliées :
C'est la raison principale. Pour saturer la bande passante de la mémoire vidéo, nous devons transférer des données en continu.Dans cette version, une instruction ne peut déplacer que 64 octets.Comparée à la version float4 (qui déplace 512 octets par instruction), l'efficacité des instructions de cette version n'est que de 1/8.
en conséquence deMême lorsque le répartiteur d'instructions du SM fonctionne à plein régime, la quantité de données véhiculées par les instructions émises ne permet pas d'exploiter pleinement l'énorme bande passante de la mémoire vidéo. C'est comme si le contremaître s'époumonait à donner des instructions, mais que les ouvriers n'arrivaient toujours pas à déplacer suffisamment de briques (de données).
2. La granularité des transactions en mémoire est trop faible :
* Couche physique :La plus petite unité de transfert de mémoire vidéo est un secteur de 32 octets ; les couches de cache sont généralement gérées par unités de lignes de cache de 128 octets.
* statu quo:Bien que les 64 octets de données demandés par le Warp aient rempli deux secteurs, ils n'ont utilisé que la moitié de la ligne de cache de 128 octets.
* en conséquence de:Ce transfert de données par petits paquets, de type « vente au détail », est extrêmement inefficace à ce débit comparé au transfert « en gros » de quatre lignes de cache complètes (512 octets) simultanément, comme c’est le cas avec le format float4, et il ne peut masquer la latence élevée de la mémoire vidéo. Pour exploiter pleinement la bande passante de la mémoire vidéo, un transfert de données continu est nécessaire.
Code (v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4.Version 4 : FP16 vectorisé (Half2)
Présentez la moitié 2.
Analyse approfondie des principes :
- données:demi2 (4 octets).
- couche de commandement:Émettez une commande de chargement 32 bits.
- Couche de calcul :En utilisant __hadd2 (SIMD), une seule instruction peut effectuer deux additions simultanément.
- statu quo:L'efficacité d'accès à la mémoire est équivalente à celle de la référence FP32.(1 instruction = 128 octets). Bien que plus rapide que la V3, elle n'atteint toujours pas le pic de 512 octets/instruction de float4.
Code (v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}Voir l'annexe pour un exemple d'exécution d'hyper Jupyter.
5. Version 5 : Déroulement FP16x8 (Déroulement manuel de la boucle)
Pour explorer plus en détail les performances, nous avons essayé de faire gérer huit moitiés par un seul thread (c'est-à-dire quatre demi-2).
Analyse approfondie des principes sous-jacents (où se situent les améliorations par rapport à la version 4 ?) :
- pratique:Écrivez manuellement quatre lignes consécutives d'opérations de lecture half2 dans le code.
- Effet:Le planificateur émettra quatre commandes de chargement 32 bits successivement.
- revenu:Parallélisme au niveau des instructions (ILP) et masquage de la latence. Problèmes avec la V4 (FP16x2) :Émettre une instruction -> attendre le retour des données (attente) -> effectuer le calcul. Pendant cette période d'attente, le GPU reste inactif. Améliorations de la version 5 :Il exécute quatre instructions en succession rapide. Pendant que le GPU attend encore le retour des premières données de la mémoire, il a déjà exécuté les deuxième, troisième et quatrième instructions. Ceci exploite pleinement les intervalles entre les instructions, masquant ainsi la latence mémoire, coûteuse en ressources.
- Limites:La densité d'instructions reste très élevée.Bien que l'ILP ait été utilisé, il a néanmoins initié quatre transferts de données de 32 bits. Pour déplacer 128 bits de données, le SM a tout de même consommé quatre cycles d'émission d'instructions. L'émetteur d'instructions est resté très sollicité, sans parvenir à réaliser l'exploit de « déplacer une montagne avec une seule instruction ».
Code (v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}Voir l'annexe pour un exemple d'exécution d'hyper Jupyter.
Version 6 : Pack FP16x8 (Optimisation ultime)
Il s'agit du plafond de l'optimisation des opérateurs Elementwise. Nous combinons le « transport à large bande passante » de la version 2 avec le « parallélisme au niveau des instructions » de la version 5 et introduisons une technologie de mise en cache des registres.
Analyse approfondie de la magie fondamentale :
1. Usurpation d'adresse :
* question:Nos données sont de type half, et le GPU ne possède pas d'instruction native load_8_halfs.
* Contre-mesures : Le type float4 occupe exactement 128 bits (16 octets), et 8 demis occupent également 128 bits.
* fonctionner :Nous convertissons de force l'adresse du demi-tableau (reinterpret_cast) en float4*.
* Effet:Lorsque le compilateur rencontre `float4*`, il génère une ligne. LD.E.128 Instructions. Le contrôleur de mémoire vidéo ne tient pas compte de ce que vous déplacez ; il ne déplace que des flux binaires de 128 bits à la fois.
2. Tableau des registres :
half pack_a[8] : Bien que ce tableau soit défini dans le noyau, sa taille fixe et très réduite permet au compilateur de l'affecter directement au fichier de registres du GPU plutôt qu'à la mémoire locale, plus lente. Cela équivaut à disposer d'un cache haute vitesse.
3. Réinterprétation de la mémoire :
Définition de la macro LDST128BITS :C'est là le cœur du code. Il convertit l'adresse de n'importe quelle variable en un float4* et récupère sa valeur.
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* Côté droit :Allez dans la mémoire globale a[idx] et récupérez 128 bits de données.
* gaucheÉcrivez ces données de 128 bits directement dans le tableau pack_a (en commençant par l'élément 0, en remplissant instantanément 8 éléments).
* résultat:Une seule instruction permet de transférer instantanément 8 éléments de données.
Code (v6_f16x8_pack.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}Phase 3 : Combinaison des indicateurs de performance et de l'analyse visuelle
Pour évaluer de manière exhaustive l'effet de l'optimisation, nous avons conçu un plan de test de scénario complet couvrant des scénarios sensibles à la latence (petites données) jusqu'à des scénarios sensibles à la bande passante (grandes données).
1. Conception de la stratégie de test
Nous avons sélectionné trois ensembles de données représentatifs, chacun correspondant à différents goulots d'étranglement au niveau de la mémoire GPU :
- Latence du cache (1 million d'éléments) :La taille des données est extrêmement petite (4 Mo) et le cache L2 est entièrement utilisé.L'élément central du test est la surcharge liée au lancement du noyau et l'efficacité de l'émission des commandes.
- Débit L2 (16 millions d'éléments) :La taille des données est modérée (64 Mo), proche de la limite de capacité du cache L2.L'élément central du test est le débit de lecture et d'écriture du cache L2.
- Bande passante VRAM (256M éléments) :Le volume de données est énorme (1 Go), dépassant largement la capacité du cache L2. Les données doivent être déplacées depuis la mémoire vidéo (VRAM).C’est là le véritable champ de bataille pour les opérateurs à grande échelle ; le test fondamental consiste à déterminer si la bande passante de la mémoire physique est pleinement utilisée.
2. Script de test de performance (Python)
Le script charge directement le fichier .cu défini ci-dessus et calcule automatiquement la bande passante (GB/s) et le temps (ms).
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. Données réelles : performances de la RTX 5090
Voici les données réelles obtenues en exécutant le code ci-dessus sur une NVIDIA GeForce RTX 5090 :
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. Interprétation des données
Ces données démontrent clairement les caractéristiques physiques de la RTX 5090 sous différentes charges :
Phase 1 : Très petite échelle (1 million d'éléments / 4 Mo)
- Phénomène:Toutes les versions ont affiché un temps d'exécution remarquablement constant de 0,0041 ms.
- la vérité :Il s'agit d'une situation où la latence est un facteur limitant. Quelle que soit la taille des données, le temps de lancement fixe nécessaire au GPU pour démarrer un noyau est d'environ 4 microsecondes. Du fait de cette limitation temporelle, le volume de données pour FP16 est deux fois moins important que pour FP32, et la bande passante calculée est donc naturellement deux fois moindre. Ce qui est mesuré ici, ce n'est pas la vitesse de transmission, mais la « vitesse de lancement ».
Deuxième phase : Taille moyenne (16 millions d'éléments / 64 Mo contre 32 Mo)
C’est dans ce domaine que l’on observe le mieux la fonction du cache L2 :
- FP32 (64 Mo) :Le volume total de données A+B+C est d'environ 192 Mo. Cela dépasse la capacité du cache L2 de la RTX 5090 (environ 128 Mo). Ce dépassement de capacité a forcé le système à lire et écrire dans la VRAM, ce qui a entraîné une chute de la bande passante à 1 700 Go/s (proche de la bande passante physique de la mémoire vidéo).
- FP16 (32 Mo) :Volume total de données.Il s'insère parfaitement dans le cache L2 ! Les données circulent dans le cache, ce qui fait grimper la bande passante à 2890 Go/s.
- La magie noire de PyTorch :À noter que PyTorch a atteint 6815 Go/s en FP16. Cela démontre que, dans un scénario de cache pur, l'optimisation du pipeline d'instructions du compilateur JIT reste supérieure à un simple noyau écrit à la main.
Phase 3 : Grande échelle (268 millions d'éléments / 1024 Mo)
Voici un scénario réel d'entraînement/d'inférence avec un modèle de grande taille (limité par la mémoire) :
- Tous les êtres sont égaux :Que ce soit en FP32 ou FP16, en mode de base ou optimisé, la bande passante est toujours bloquée à 1570-1580 Go/s.
- Mur physique :Nous avons atteint la limite physique de la bande passante mémoire GDDR7 de la RTX 5090. Cette bande passante est limitée ; il est impossible de l'augmenter.
- La valeur de l'optimisation :Bien que la bande passante soit restée la même.Cependant, il a été constaté que le temps FP16 (1,02 ms) n'était que la moitié de celui du FP32 (2,04 ms).En réduisant de moitié le volume de données tout en maximisant la bande passante, on obtient une accélération de bout en bout de 2x. V6 contre V3Bien que la version 3 semble fonctionner à pleine capacité, cela est dû à l'optimisation automatique du compilateur NVCC et au masquage de la latence matérielle du GPU. Cependant, pour les opérateurs plus complexes (comme FlashAttention), l'implémentation de la version 6 garantit des performances optimales.
FAQ principale : Dérivation poussée de la conception des paramètres
Dans tous les noyaux de cette expérience, nous avons unanimement fixé le paramètre : threads_per_block = 256. Ce nombre n’a pas été choisi au hasard, mais plutôt comme une solution mathématiquement optimale entre les limitations matérielles et l’efficacité de la planification.
Q : Pourquoi threads_per_block est-il toujours fixé à 128 ou 256 ?
A : Il s'agit d'une « plage optimale » obtenue grâce à quatre niveaux de filtrage.
Nous considérons le processus de sélection de block_size comme un entonnoir, filtrant couche par couche :
1. Alignement de la déformation -> Doit être un multiple de 32
La plus petite unité d'exécution dans un GPU est un warp (ensemble de threads), qui se compose de 32 threads consécutifs (architecture SIMT, multithreading à instruction unique).
- Limitations strictes :Si vous demandez 31 threads, le matériel planifiera tout de même un warp complet. Bien que la position du thread restant soit inactive, elle occupe les mêmes ressources matérielles.
- en conclusion: La taille des blocs devrait idéalement être un multiple de 32 afin d'éviter le gaspillage de puissance de calcul.
2. Taux d'occupation au sol -> Doit être ≥ 96
Taux d'occupation = Nombre de threads simultanés actuellement exécutés sur SM / Nombre maximal de threads pris en charge par SM.
- arrière-plan:Pour masquer la latence mémoire, un nombre suffisant de warps actifs est nécessaire. Si la taille des blocs est trop petite, la limite « Max Blocks » du SM sera atteinte avant la limite « Max Threads ».
- Estimation:Les architectures courantes (telles que Turing/Ampere/Ada) requièrent généralement : taille_bloc > (nombre maximal de threads dans le SM / nombre maximal de blocs dans le SM). Les rapports courants sont 64 ou 96.
- en conclusion:Pour atteindre théoriquement une occupation de 100%, la taille des blocs ne doit pas être inférieure à 96.
3. Planification de l'atomicité -> Verrouillage 128, 256, 512
Un bloc est la plus petite unité atomique allouée à un SM. Le SM doit pouvoir consommer intégralement un nombre entier de blocs.
- Divisibilité:Pour éviter de gaspiller la capacité du SM, la taille des blocs devrait idéalement être divisible par la capacité maximale de threads du SM.
- filtre:La capacité maximale des SM d'architecture courante est généralement de 1024, 1536, 2048, etc. Leur diviseur commun est généralement 512. En combinant les deux étapes précédentes (>=96 et un multiple de 32), notre liste de candidats est réduite à : 128, 192, 256, 384, 512.
4. Pression d'enregistrement -> Exclure 512+
C'est le plafond de verre final.
- Limitations strictes :Le nombre total de registres disponibles pour chaque bloc est limité (le nombre total de registres dans le SM est généralement de 64K 32 bits).
- risque:Si la taille du bloc est grande (par exemple, 512) et que le noyau est légèrement plus complexe (chaque thread utilise plusieurs registres), alors la situation se produira où 512 * Regs/Thread > Max_Regs_Per_Block.
- en conséquence de:Échec du démarrage : Message d'erreur direct. Débordement de registres : Les registres débordent dans la mémoire locale lente, provoquant une chute de performances en cascade.
- en conclusion:Pour des raisons de sécurité, nous évitons généralement d'utiliser 512 ou 1024. Les routes 128 et 256 sont les « zones désertiques » les plus sûres.
Résumer
Après quatre tours d'élimination, il ne restait plus que deux candidats :
- 128Elle possède la plus grande polyvalence.Même avec un noyau complexe (qui utilise de nombreux registres), il peut toujours garantir un démarrage réussi et un bon taux d'occupation.
- 256 :Opérateur Elementwise préféréPour les opérateurs logiquement simples comme les opérations élément par élément, la pression sur les registres est minimale. 256 offre un meilleur potentiel de fusion mémoire que 128 et réduit la surcharge liée à l'ordonnancement des blocs.
Cela explique également pourquoi, dans l'implémentation naïve, une fois que nous avons déterminé threads_per_block = 256, grid_size est également déterminé (tant que la quantité totale couvre N).
Annexe : Exemples d’exécution avec Jupyter









