Command Palette
Search for a command to run...
Tutoriel En Ligne | L'équipe IA De WeChat Propose WeDLM, Un Modèle De Langage De Diffusion Qui Triple La Vitesse d'inférence Pour Le Déploiement De Modèles De Réalité Augmentée Par Rapport À vLLM.

Dans les déploiements à grande échelle et les applications commerciales, la vitesse d'inférence revêt une importance croissante, surpassant même souvent le nombre de paramètres du modèle et devenant un facteur déterminant de sa valeur technique. Bien que le paradigme de génération autorégressive (AR) demeure la méthode de décodage dominante en raison de sa stabilité et de son écosystème mature,Cependant, son mécanisme inhérent de génération jeton par jeton rend presque impossible pour le modèle d'utiliser pleinement les ressources de calcul parallèle pendant la phase d'inférence.Cette limitation est particulièrement marquée dans les scénarios impliquant la génération de longs textes, un raisonnement complexe et des services à haute concurrence, et elle augmente directement la latence d'inférence et les coûts de calcul.
Pour surmonter ce goulot d'étranglement, la communauté de recherche a exploré sans relâche ces dernières années des voies de décodage parallèles.Parmi eux, les modèles de langage de diffusion (DLM) sont considérés comme l'une des alternatives les plus prometteuses en raison de leur caractéristique de « générer plusieurs jetons par étape ».Cependant, un écart important persiste entre l'idéal et la réalité : dans des environnements de déploiement concrets, de nombreux DLLM n'ont pas réussi à démontrer le gain de vitesse escompté, et peinent même à surpasser des moteurs d'inférence AR hautement optimisés (tels que les vLLM). Le problème ne provient pas du parallélisme en lui-même, mais plutôt d'un conflit plus profond, latent au niveau de la structure du modèle et du système.De nombreuses méthodes de diffusion existantes reposent sur des mécanismes d'attention bidirectionnels, ce qui compromet la pierre angulaire de l'efficacité des systèmes d'inférence modernes — la mise en cache des valeurs clés préfixées — et oblige le modèle à recalculer le contexte de manière répétée, annulant ainsi les avantages potentiels du parallélisme.
Dans ce contexte,L'équipe d'IA de WeChat de Tencent a proposé WeDLM (WeChat Diffusion Language Model).Il s'agit du premier modèle de langage de diffusion à surpasser les modèles AR comparables en termes de vitesse d'inférence grâce à l'optimisation par moteur d'inférence de niveau industriel (vLLM). Son principe fondamental consiste à conditionner chaque position masquée à l'ensemble des jetons observés, tout en maintenant un masquage causal strict. À cette fin, les chercheurs ont introduit une méthode de réordonnancement topologique, déplaçant les jetons observés vers des régions de préfixe physiques sans modifier leurs positions logiques.
Les résultats expérimentaux montrent que WeDLM accélère considérablement l'inférence tout en préservant la qualité de la génération de réseaux autorégressifs robustes. Plus précisément, il permet d'obtenir une accélération plus de trois fois supérieure à celle des modèles AR déployés par vLLM pour des tâches telles que le raisonnement mathématique, et une efficacité d'inférence plus de dix fois supérieure dans les scénarios de faible entropie.
Le framework de décodage de modèles de langage de grande taille à haute efficacité « WeDLM » est actuellement disponible dans la section « Tutoriels » du site web HyperAI. Vous pouvez accéder aux tutoriels en ligne via le lien ci-dessous ⬇️
Tutoriels en ligne :
Adresse open source :
https://github.com/tencent/WeDLM
Pour permettre à tous de profiter pleinement des tutoriels en ligne, HyperAI offre également des avantages en matière de puissance de calcul.Les nouveaux utilisateurs peuvent obtenir 2 heures de temps d'utilisation de la carte graphique NVIDIA GeForce RTX 5090 en utilisant le code de réduction « WeDLM » après leur inscription (la ressource est valable 1 mois).Quantités limitées, commandez le vôtre dès maintenant !
Essai de démonstration
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels », ou cliquez sur « Voir plus de tutoriels », sélectionnez « Cadre de décodage de modèle de langage large haute efficacité WeDLM », puis cliquez sur « Exécuter ce tutoriel en ligne ».
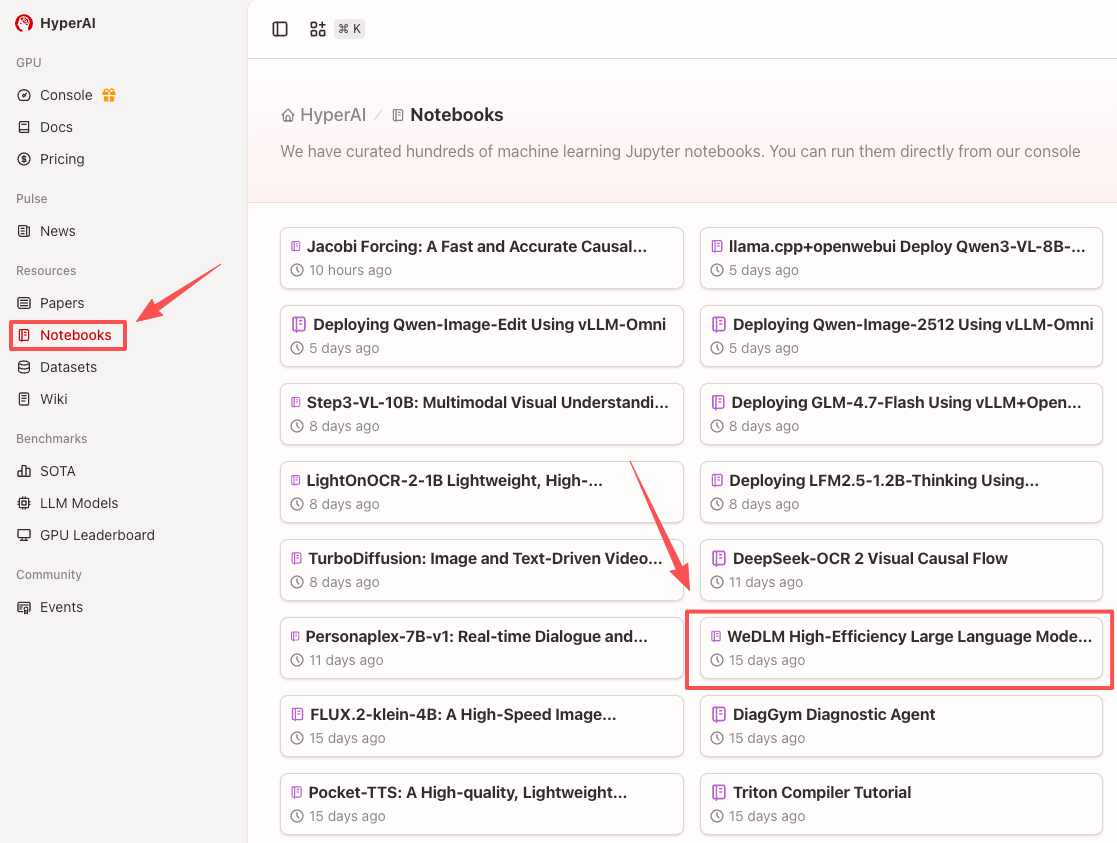
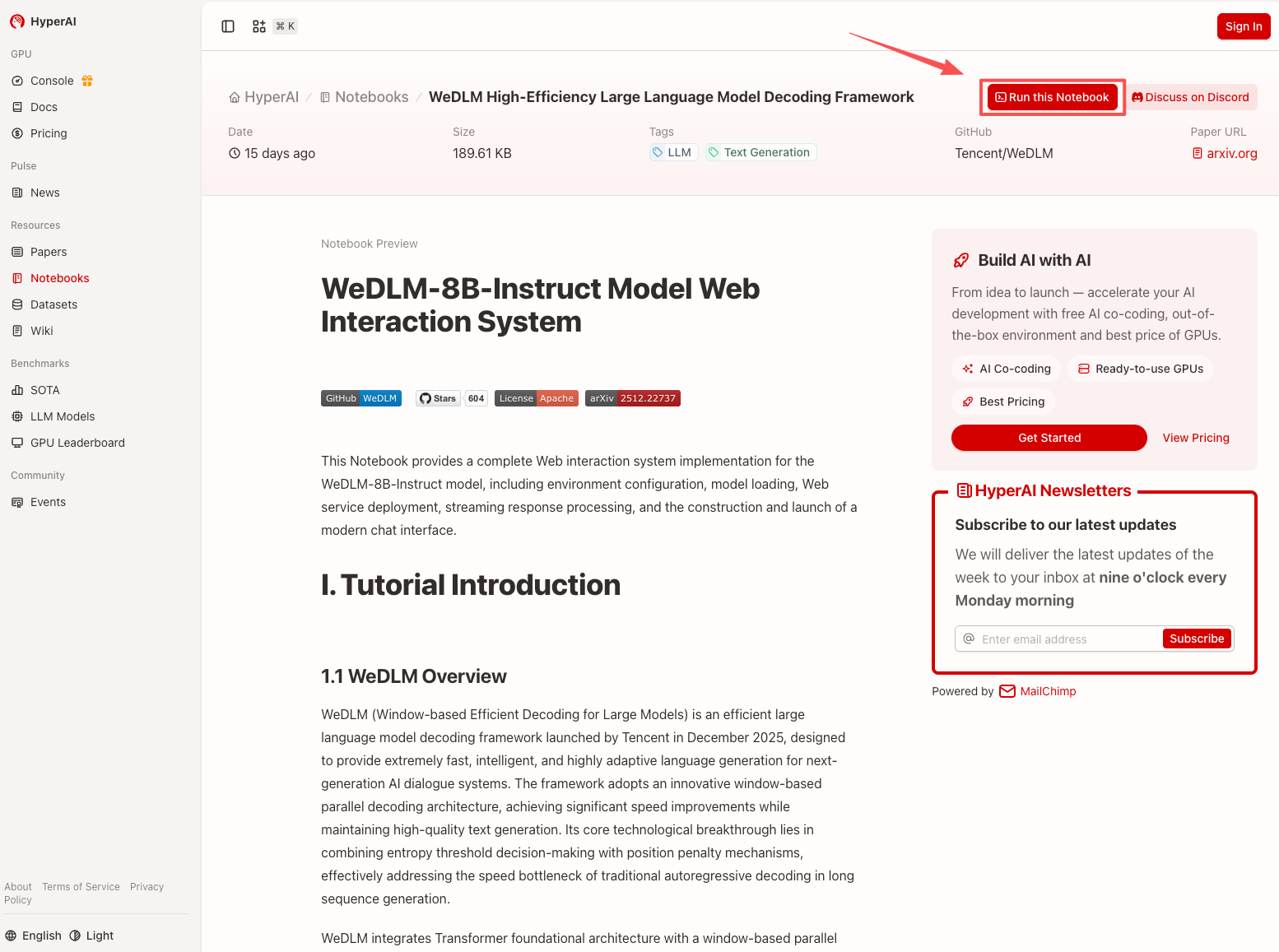
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
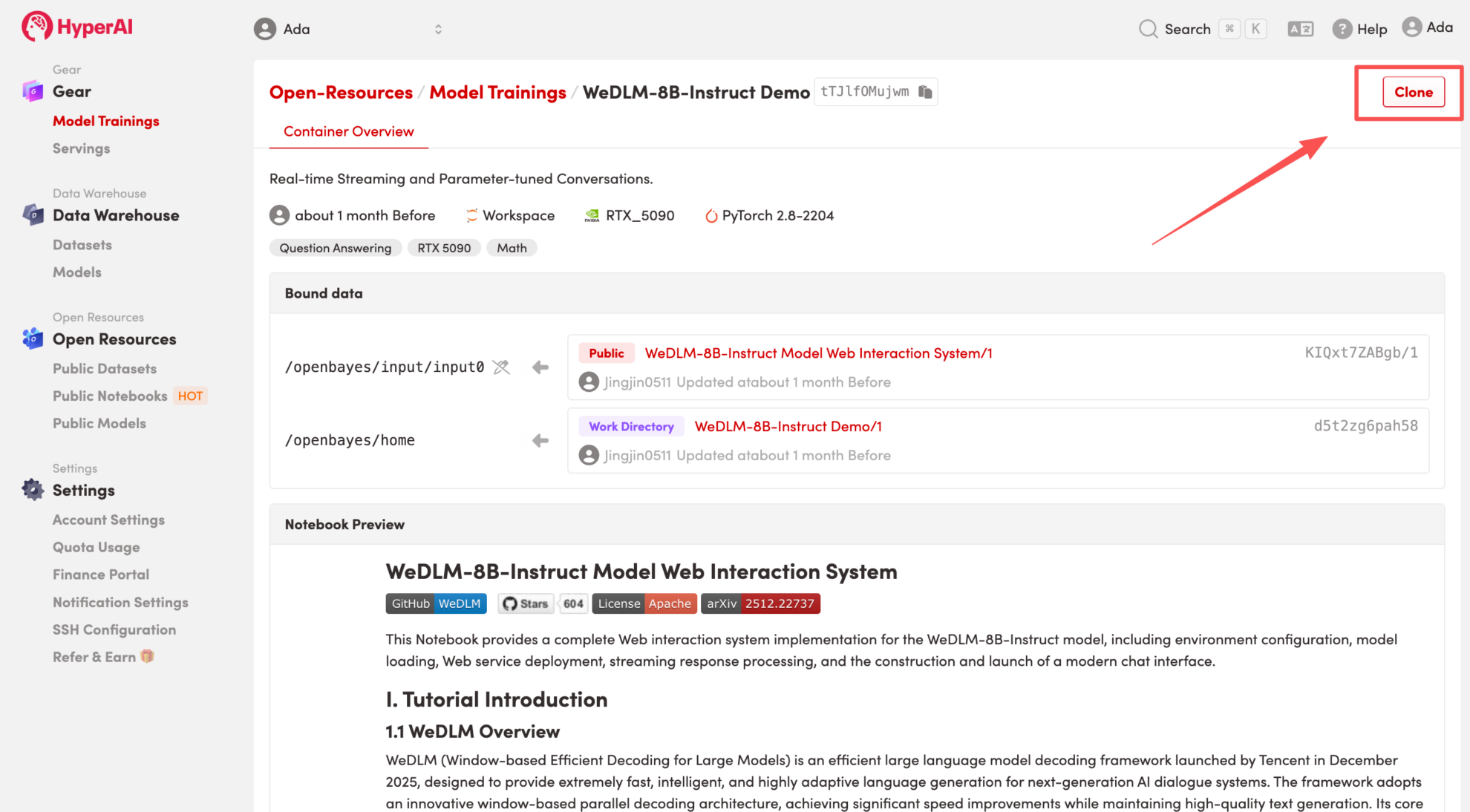
3. Sélectionnez les images « NVIDIA GeForce RTX 5090 » et « PyTorch », puis choisissez « Pay As You Go » ou « Daily Plan/Weekly Plan/Monthly Plan » selon vos besoins, puis cliquez sur « Continuer l’exécution de la tâche ».
HyperAI offre des avantages à l'inscription pour les nouveaux utilisateurs.Pour seulement $1, vous pouvez obtenir 20 heures de puissance de calcul RTX 5090 (prix d'origine $7).La ressource est valide en permanence.
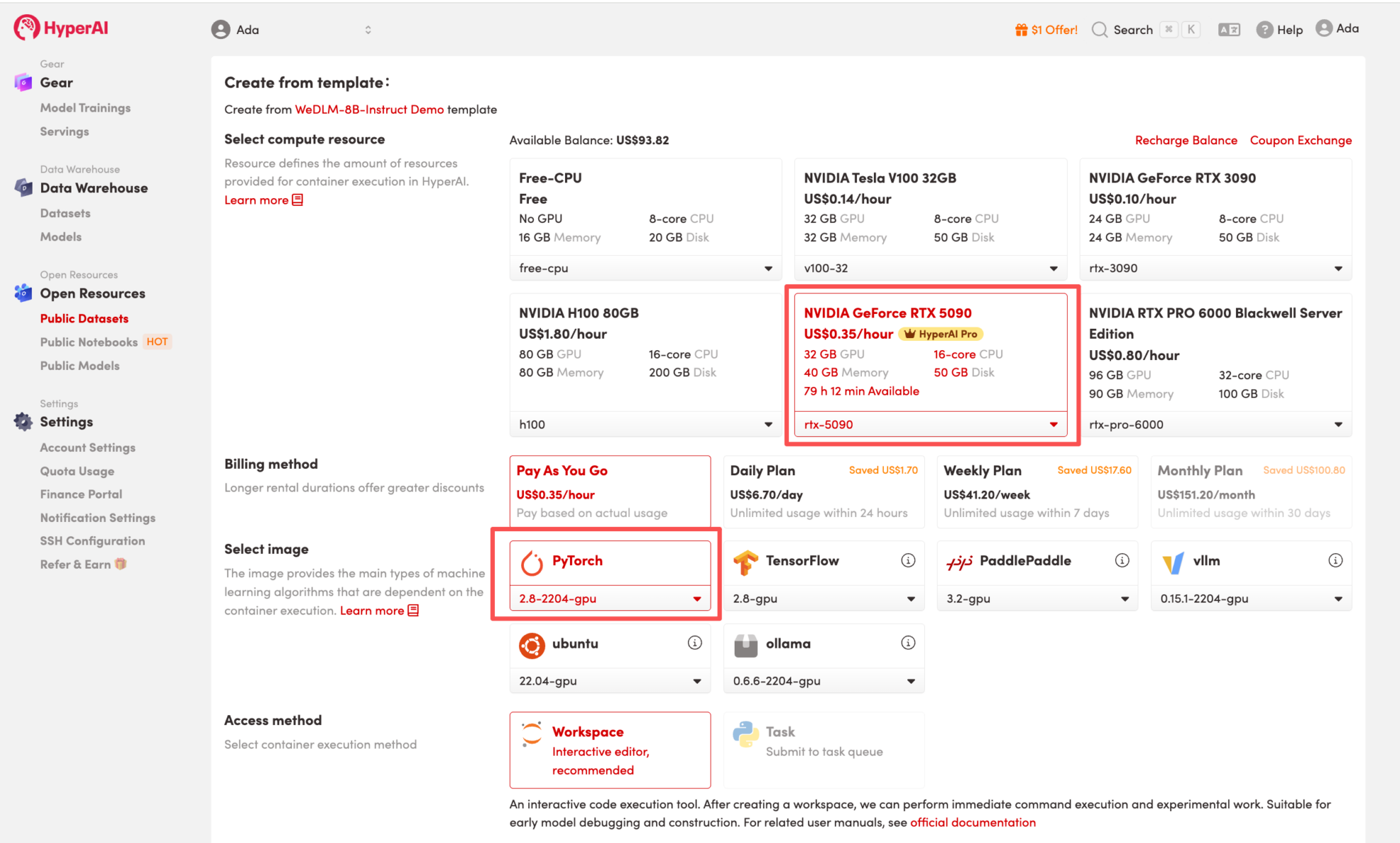
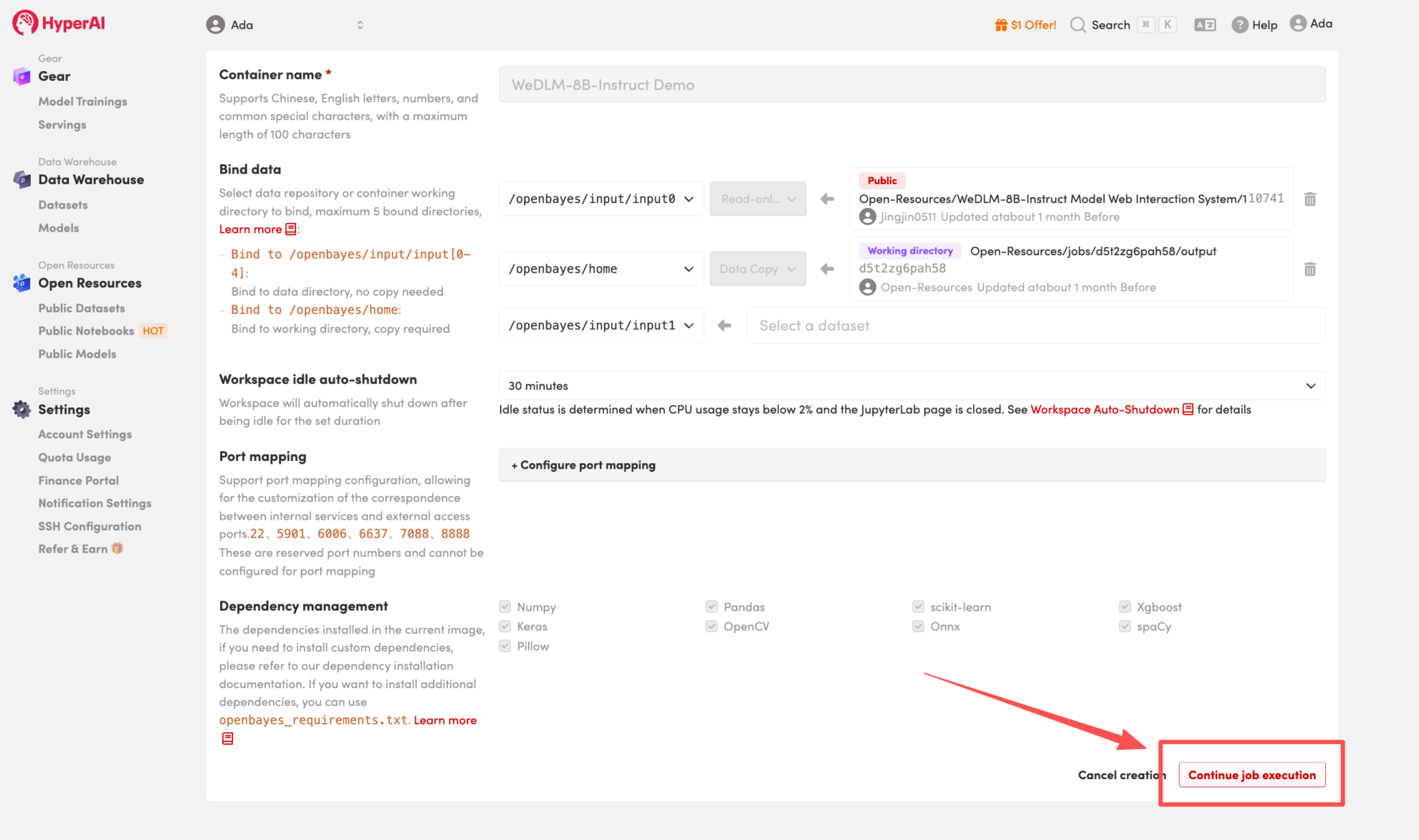
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
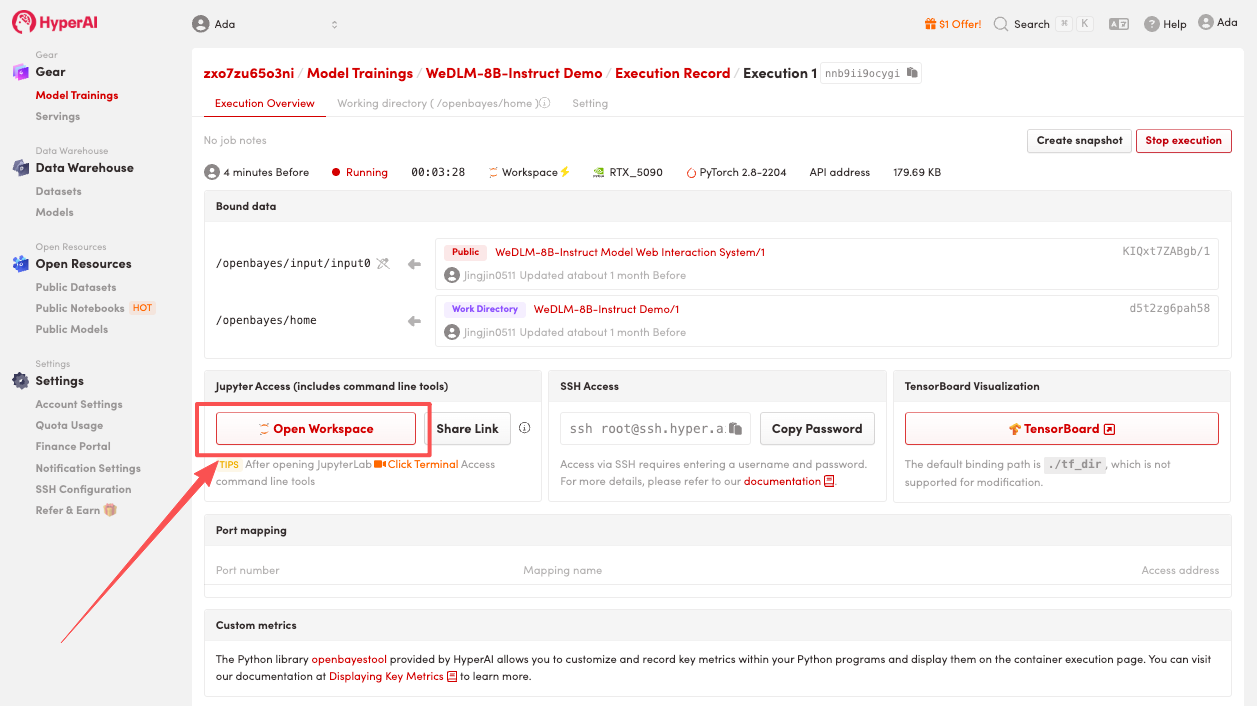
Démonstration d'effet
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
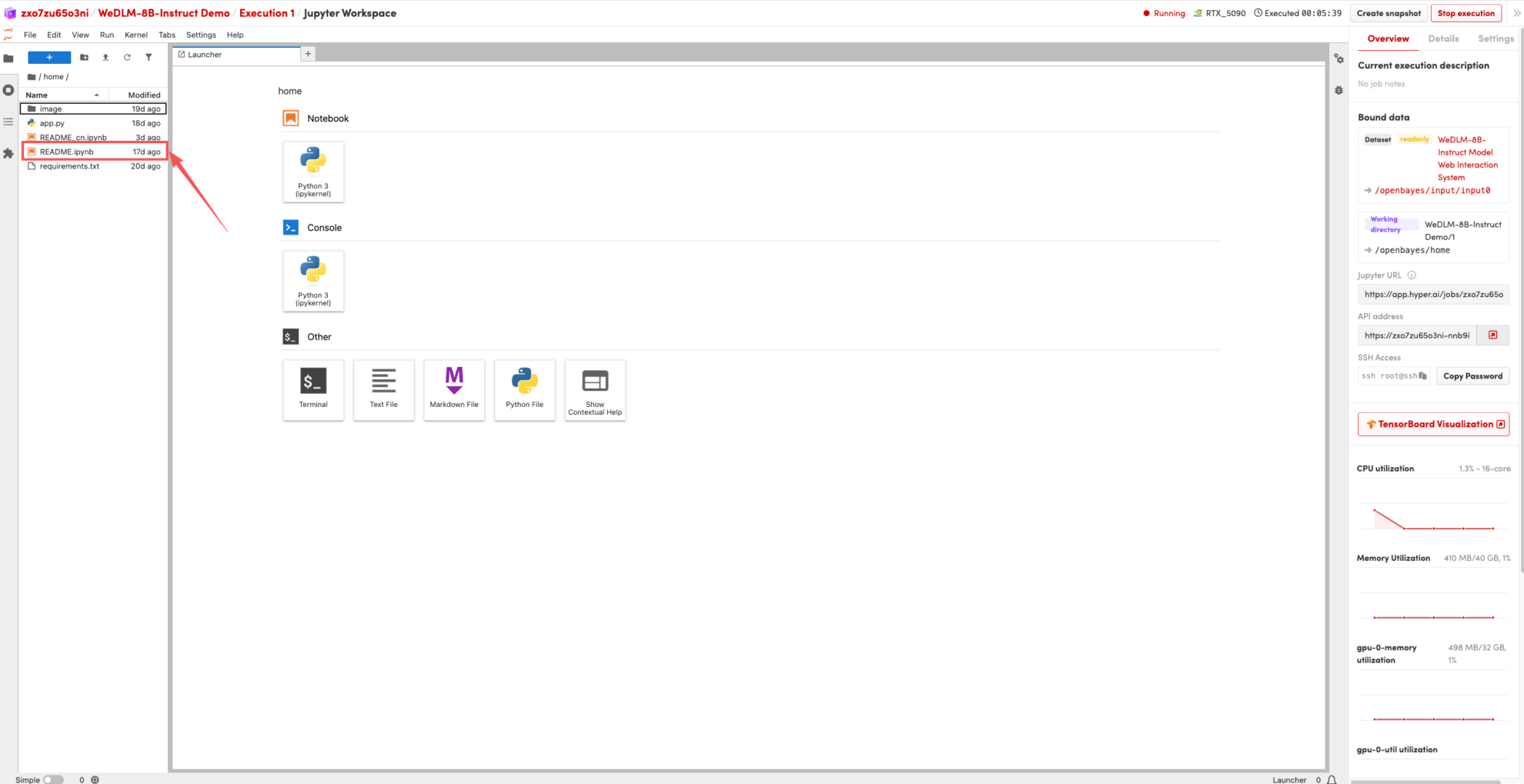
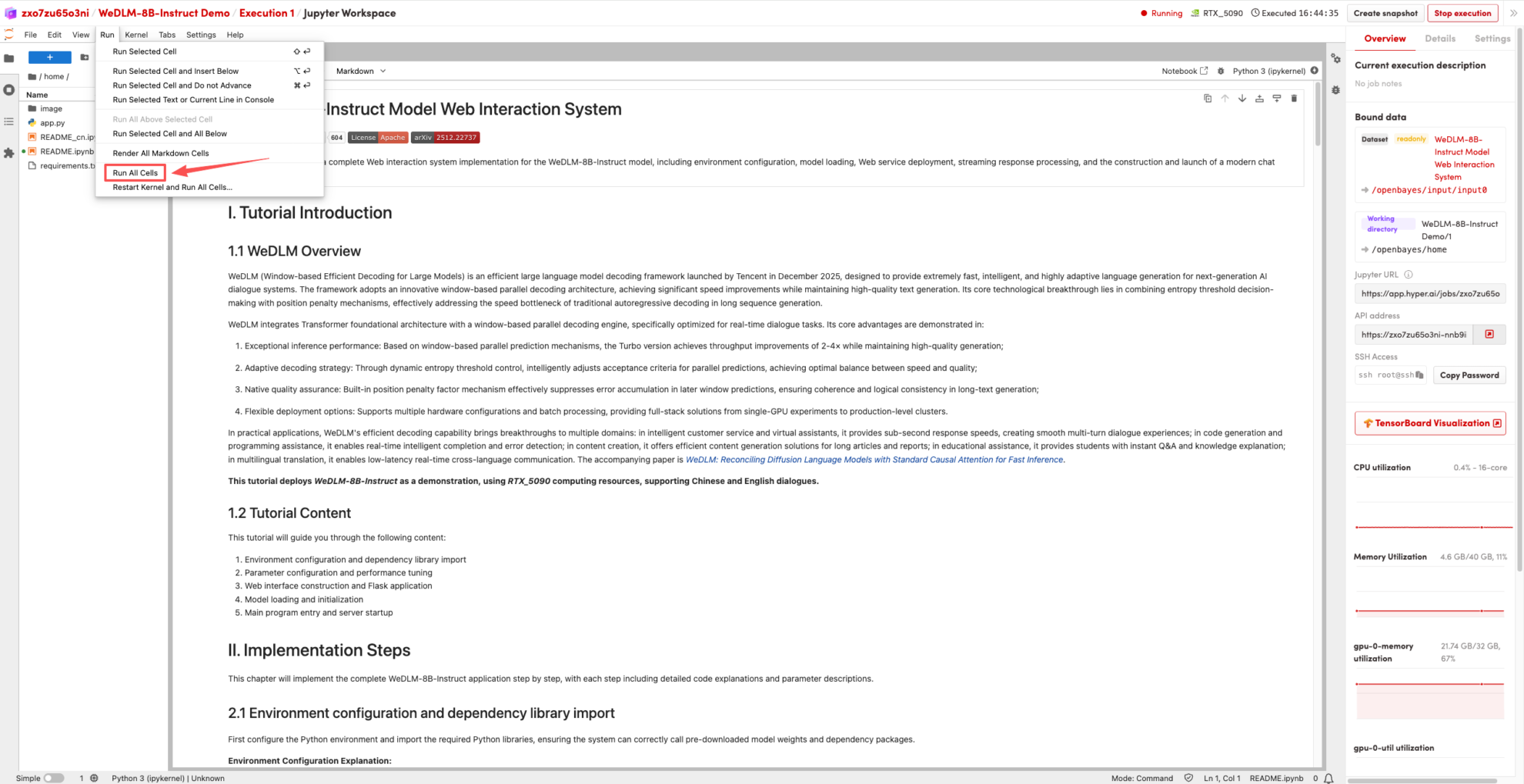
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour accéder à la page de démonstration.
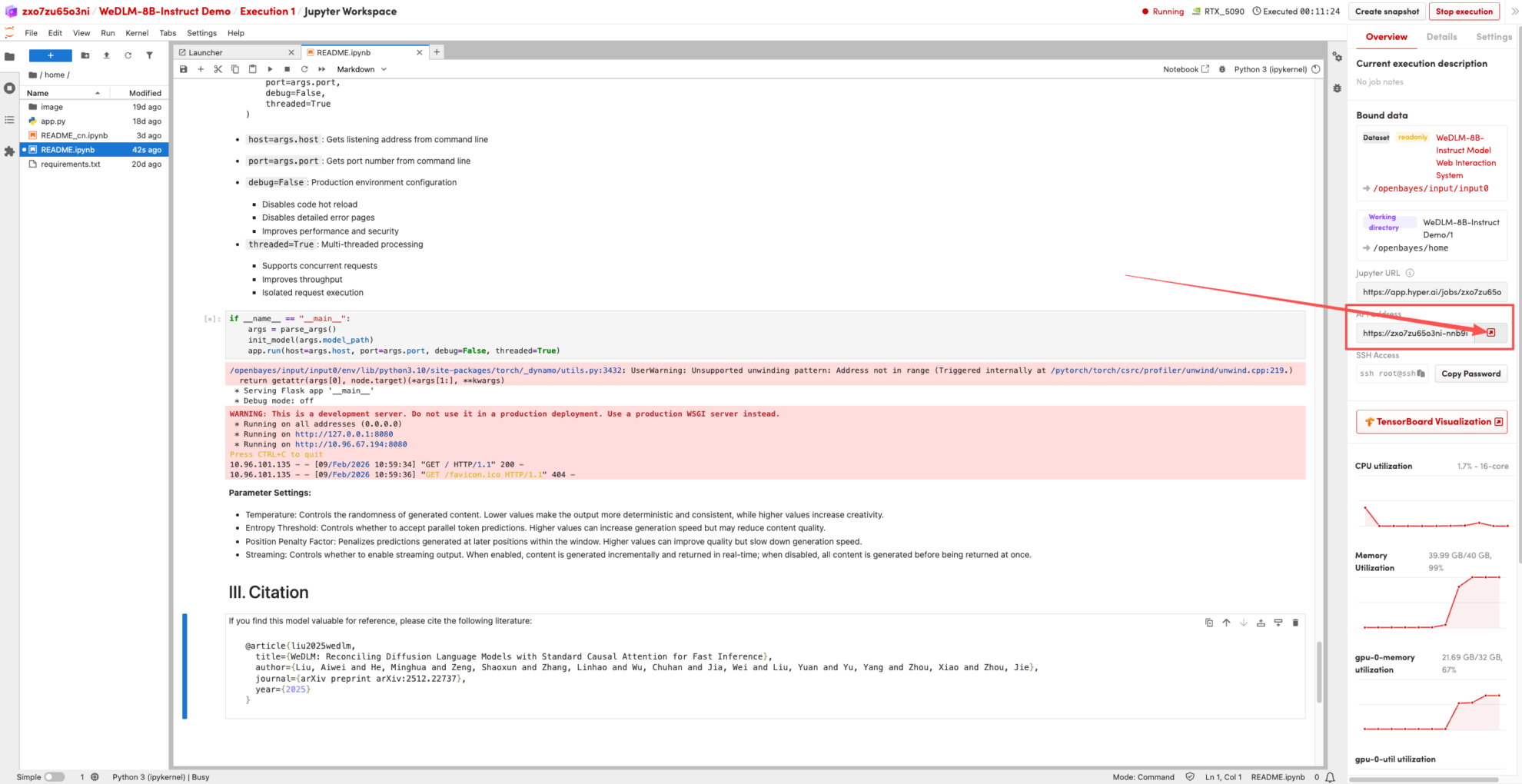
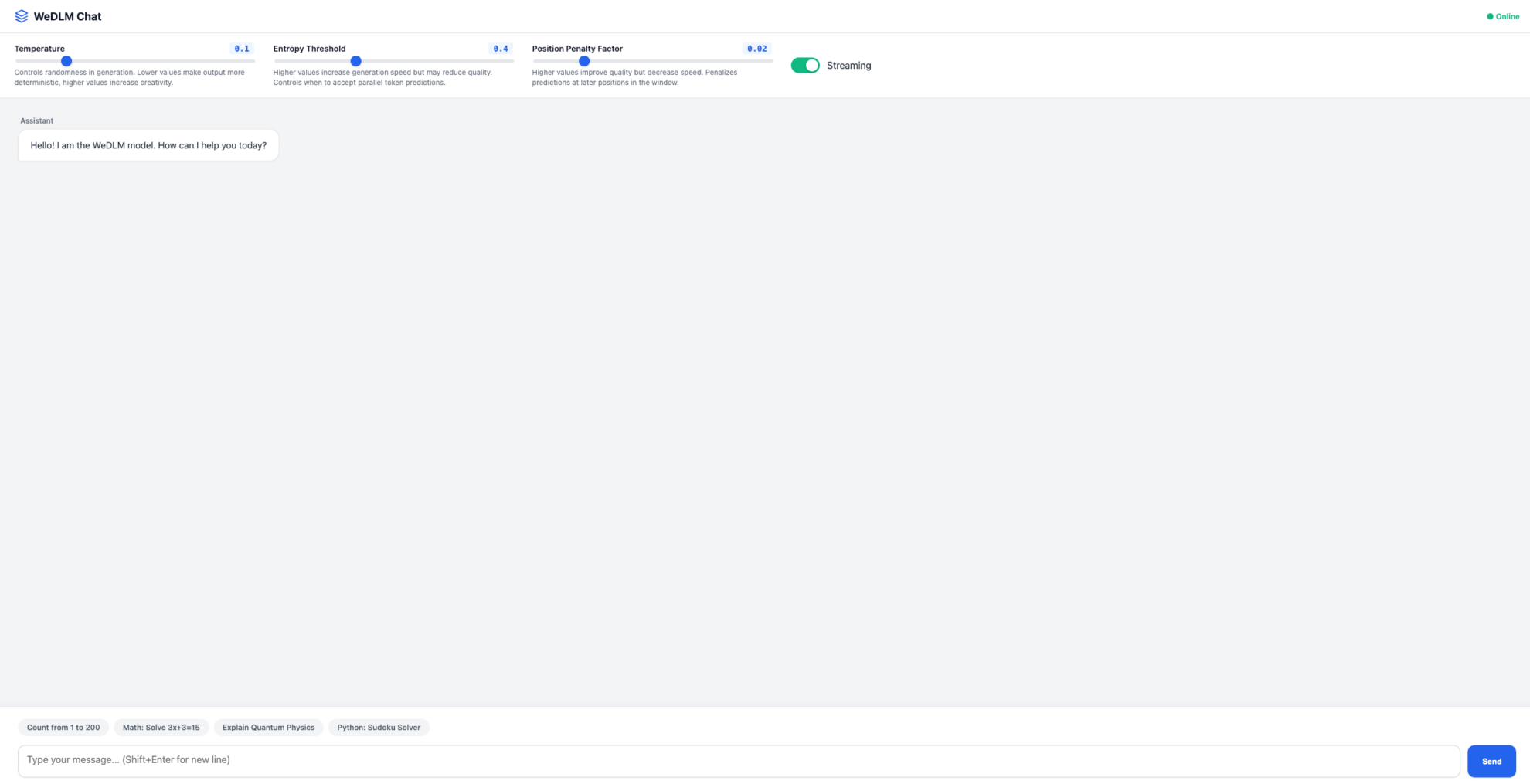
Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :https://go.hyper.ai/qf0Y6








