Command Palette
Search for a command to run...
L'université De Yale a Proposé MOSAIC, Un Projet Qui Consiste À Constituer Une Équipe De Plus De 2 000 Experts En Chimie De l'IA, Permettant Une Spécialisation Efficace Et l'identification Des Voies De Synthèse optimales.
La chimie de synthèse moderne est confrontée à une contradiction majeure entre l'accumulation rapide des connaissances et l'efficacité de leur application et de leur transformation. Des centaines de milliers d'articles scientifiques sont publiés chaque année, et le volume total de connaissances exploitables en synthèse se chiffre en millions. Cependant, la majeure partie de ces connaissances est dispersée dans différentes bases de données sous forme de texte non structuré, ce qui engendre une fragmentation importante. Le recours aux méthodes traditionnelles de recherche bibliographique et de sélection manuelle est non seulement long et fastidieux, mais aussi difficile pour couvrir systématiquement les différents types de réactions dans divers domaines. Il en résulte une quantité considérable d'informations précieuses, enfouies dans la littérature, qu'il est difficile d'extraire et de transformer en protocoles expérimentaux applicables.
Face à ce dilemme de gestion des connaissances, le besoin fondamental de la pratique de la synthèse se concentre de plus en plus sur la manière d'obtenir efficacement des protocoles expérimentaux complets et hautement reproductibles. Ces protocoles impliquent de nombreux paramètres clés tels que le choix des réactifs, le contrôle de la stœchiométrie, la programmation de la température et les étapes de post-traitement.
à l'heure actuelle,Le développement de ce domaine est principalement limité par deux aspects.Premièrement, l'expertise peine à couvrir l'espace réactionnel en constante expansion, ce qui engendre souvent des coûts élevés liés aux essais et erreurs dans les synthèses interdisciplinaires. Deuxièmement, malgré le développement rapide de l'intelligence artificielle, l'application de modèles généralistes en chimie souffre encore d'une fiabilité insuffisante, d'une sensibilité aux illusions et d'un manque d'évaluation de la confiance, ne permettant pas d'atteindre la précision requise pour les expériences. Par conséquent, la transformation de connaissances chimiques massives et fragmentées en un guide de synthèse structuré et fiable est devenue essentielle pour surmonter les obstacles à l'efficacité du domaine.
Dans ce contexte,Une équipe de recherche de l'université de Yale a récemment proposé le modèle MOSAIC, qui transforme un modèle de langage généralisé de grande taille en un système collaboratif composé de nombreux experts en chimie spécialisés.En supprimant efficacement les illusions de modélisation grâce à une division professionnelle du travail, elle fournit des évaluations quantifiables de l'incertitude et réalise la génération systématique, de la description de la réaction aux protocoles expérimentaux complets, ce qui devrait améliorer considérablement l'efficacité de la recherche scientifique dans des domaines tels que la découverte de médicaments et le développement de matériaux.
Les résultats de cette recherche, intitulée « Intelligence collective pour les synthèses chimiques assistées par l'IA », ont été publiés dans la revue Nature.

Adresse du document :
https://www.nature.com/articles/s41586-026-10131-4
Suivez notre compte WeChat officiel et répondez « MOSAIC » en arrière-plan pour obtenir le PDF complet.
Autres articles sur les frontières de l'IA :
À partir de la base de données Pistachio, nous allons créer des « experts en chimie IA » dotés de leurs points forts respectifs.
Cette recherche a été menée à l'aide de la base de données Pistachio, une base de connaissances commerciale et hautement structurée sur les réactions chimiques, principalement issue de la littérature brevetaire mondiale. Grâce à l'extraction et à la normalisation systématiques des descriptions textuelles des réactifs, produits, solvants, rendements et étapes clés documentées dans les brevets, la base de données encode uniformément ces descriptions dans un format lisible par machine (tel que la chaîne « SMILES »).Au lieu d'utiliser directement l'ensemble des données, l'équipe de recherche a mené un processus rigoureux de sélection de la qualité. Le critère principal était que les comptes rendus de réaction devaient inclure des descriptions détaillées et exploitables des procédures expérimentales.Plutôt que de se limiter à la relation de correspondance entre les réactifs et les produits, cela garantit que le modèle en cours d'entraînement apprend « comment réaliser la réaction » plutôt que simplement « quel est le résultat de la réaction ».
Les données filtrées ont été transformées en empreintes digitales spécifiques à chaque réaction, de dimension 128, grâce à un réseau métrique à noyau spécialement conçu. Cette représentation numérique vise à capturer les caractéristiques transformatives essentielles des réactions chimiques, et l'ensemble des vecteurs d'empreintes digitales constitue un « univers de réactions » représentant un vaste espace de connaissances chimiques. À partir de cet espace vectoriel, l'étude a utilisé un algorithme de clustering de Voronoi non supervisé (implémenté à l'aide de la bibliothèque FAISS) pour le diviser en 2 489 régions spécialisées non chevauchantes, chaque région regroupant des types de réactions aux propriétés chimiques très similaires.
Finalement, le texte de réponse dans chaque région de Voronoi a été utilisé pour affiner indépendamment un modèle Llama-3.1-8B-Instruct dédié.Il en a résulté 2 489 « experts en chimie IA », chacun possédant ses propres atouts.Le champ d'application et les limites de capacités de l'ensemble du cadre MOSAIC sont fondamentalement déterminés par cet ensemble de données d'entraînement centré sur les brevets. Ceci explique également pourquoi les performances du système sont relativement limitées dans certains domaines de pointe en développement rapide (comme la photochimie) : ces contenus ne sont pas encore intégralement couverts par les bases de données de brevets existantes.
MOSAIC : Un système collaboratif décentralisé composé de nombreux experts chimistes professionnels.
L'idée de conception centrale du modèle MOSAIC est de transformer le modèle de langage généraliste Llama-3.1-8B-instruct en un système collaboratif décentralisé composé de nombreux experts en chimie professionnels.Cette architecture axée sur la recherche réduit considérablement les besoins en ressources matérielles, ne nécessitant qu'une configuration de calcul de taille modérée (par exemple, 4 GPU) pour l'entraînement de sous-ensembles de tâches spécifiques, sans avoir recours à des clusters de calcul à grande échelle. Le système élimine efficacement les illusions du modèle grâce à un mécanisme de division du travail entre experts et fournit des évaluations d'incertitude quantifiables, tout en permettant l'intégration dynamique de nouveaux experts sans réentraînement complet du système, ce qui démontre des avantages significatifs en termes de flexibilité et de pérennité.
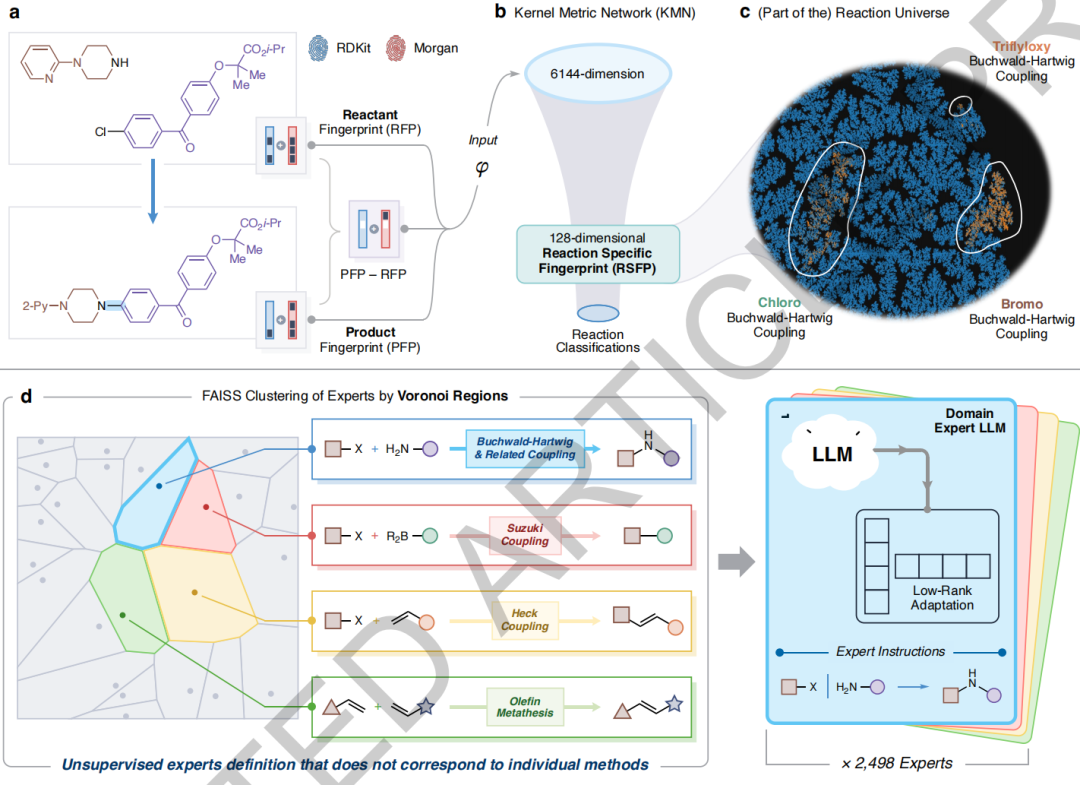
Pour surmonter les problèmes de calcul et de coordination rencontrés par les grands modèles de langage lors de leur entraînement sur des ensembles de données massifs, MOSAIC est construit à partir de trois composants progressifs :
Mesure de similarité des réponses :
Cette étude a conçu une méthode de cartographie non linéaire basée sur un réseau neuronal (réseau métrique à noyau, KMN) pour quantifier la similarité entre les réactions chimiques. Elle transforme les réactions encodées par SMILES en empreintes digitales spécifiques à la réaction (RSFP) de dimension 128, permettant ainsi à leur distance euclidienne d'approximer les relations entre les catégories de réactions, et de capturer de ce fait les caractéristiques essentielles de transformation des réactions.
Regroupement des espaces de connaissances :
Tirant parti des capacités d'indexation efficaces de la bibliothèque FAISS, un clustering Voronoi non supervisé est effectué sur l'espace vectoriel RSFP, le divisant automatiquement en 2 498 régions spécialisées avec des propriétés chimiques hautement regroupées, chaque région représentant un domaine spécifique de connaissances chimiques.
Formation d'experts du domaine :
Pour chaque ensemble de données de réaction, un modèle expert dédié est affiné indépendamment. L'étude utilise une stratégie d'apprentissage en deux étapes : d'abord, le modèle de base est affiné sur l'ensemble des données, puis les connaissances du domaine des experts concernés sont approfondies à l'aide des données de chaque ensemble, ce qui leur permet de conserver une compréhension générale de la chimie tout en possédant des connaissances professionnelles pointues.
MOSAIC encode d'abord la réaction demandée au format RSFP, puis utilise FAISS pour localiser rapidement sa région de Voronoi et l'expert correspondant. Par exemple, pour une réaction de couplage de Buchwald-Hartwig d'un hydrocarbure chloroaromatique, le système fera appel à un expert du domaine afin de générer un protocole de synthèse complet et lisible.La vérification expérimentale montre qu'en suivant exactement la procédure, le produit cible peut être obtenu avec un rendement de 96%.
MOSAIC a atteint une couverture de composants TP3T de 94,81 % et un taux de réussite de synthèse TP3T de 711 %.
Cette étude a confirmé la performance globale du modèle MOSAIC grâce à un système d'évaluation multidimensionnel. Sa principale valeur réside dans la transformation d'une quantité massive de connaissances issues de la littérature en une intelligence synthétique hautement fiable.
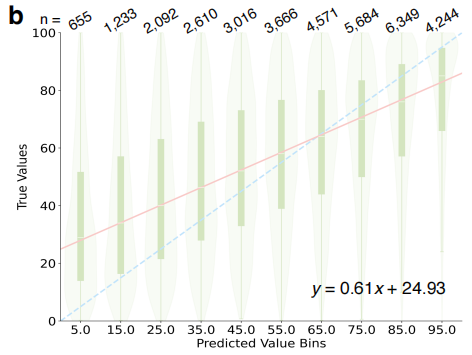
En termes de prévision du rendement et d'identification des composants essentielsLe modèle MOSAIC permet une prédiction quantitative des rendements réactionnels grâce à l'analyse du protocole expérimental complet. Comme illustré dans la figure ci-dessous, après application de la stratégie de discrétisation, le centre de l'intervalle prédit présente une corrélation significative avec la médiane du rendement réel (R² = 0,811). Le modèle démontre une excellente capacité d'identification des composants clés de la réaction (réactifs, solvants).Après avoir intégré les prédictions des trois meilleurs experts, le taux de réussite global d'identification d'au moins certains des composants corrects atteint 94,8%.Il convient de noter que même si les conditions de prédiction ne sont pas entièrement cohérentes avec les données de la littérature, le résultat est souvent une alternative chimiquement réalisable, témoignant d'un haut niveau de jugement professionnel.
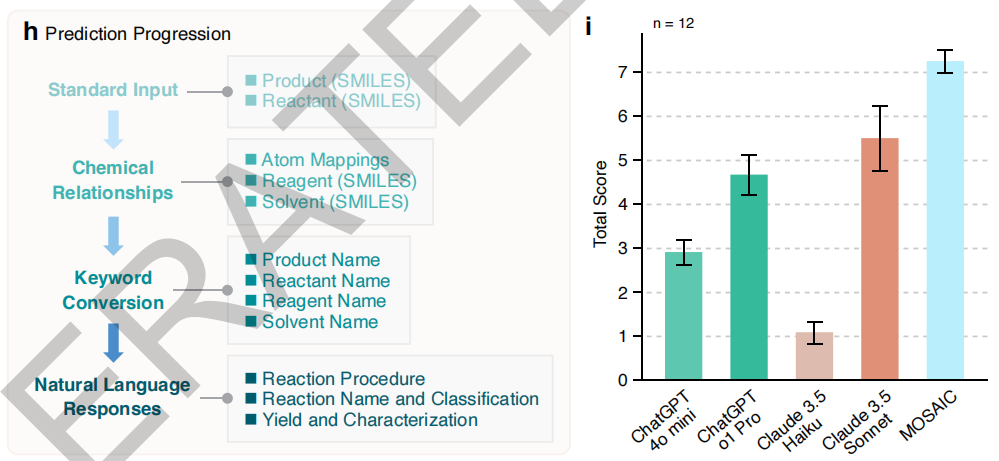
Lors de tests comparatifs portant sur 12 réactions importantes (couplage de Suzuki, amination de Buchwald-Hartwig, etc.), comme illustré dans la figure ci-dessous, MOSAIC surpasse systématiquement les modèles à usage général tels que ChatGPT-4o et Claude 3.5 en fournissant des indications de synthèse claires et réalisables. Cet avantage est d'autant plus évident que le modèle ne comporte que 8 milliards de paramètres, ce qui démontre l'efficacité d'un réglage fin spécifique au domaine. Plus important encore,MOSAIC surmonte les problèmes communs aux modèles généraux dans les tâches de chimie, tels que le respect instable des instructions et les réponses arbitraires, et fournit une sortie stable et fiable.C'est crucial pour les expériences concrètes.
Afin d'évaluer la praticité, la polyvalence et la fiabilité du cadre proposé, cette étude a également mené une validation expérimentale approfondie en réalisant des prédictions précises et performantes de réactions fondamentales en synthèse chimique moderne. Les chercheurs se sont concentrés sur des réactions catalytiques largement applicables, essentielles au développement de médicaments et de matériaux. Les liaisons carbone-azote formées par les aminations de Buchwald-Hartwig sont omniprésentes dans les molécules médicamenteuses, et les conditions de ces réactions complexes ont été prédites avec précision. Un assemblage efficace de structures de qualité pharmaceutique a été réalisé, démontrant des avantages particuliers dans les transformations d'oléfines, cruciales pour des applications allant des produits naturels aux matériaux fonctionnels.
De plus, la praticité du modèle MOSAIC a été fortement démontrée par la synthèse réussie d'un grand nombre de nouveaux composés.Parmi les 37 composés cibles synthétisés, 35 ont été retenus dès la première recommandation du modèle, avec un taux de réussite global de 71%.Le champ d'application de la validation couvre tout, des réactions de couplage classiques aux transformations sélectives, et comprend une étude de cas innovante démontrant la capacité à guider le développement de nouvelles méthodes de cyclisation d'azaindole.
Plus important encore, l'indice de confiance (distance au centroïde expert le plus proche) au sein du modèle présente une corrélation positive nette avec le taux de réussite expérimental : le taux de réussite des prédictions à haute confiance (distance < 100) dépasse 75%. Ceci fournit aux chimistes une aide précieuse à la décision quantitative, leur permettant d'allouer efficacement leurs ressources entre les objectifs à fort taux de réussite et les tentatives exploratoires.
La synthèse chimique entre dans une nouvelle ère de fabrication intelligente de précision.
Dans le cadre du processus mondial de promotion de la synthèse chimique intelligente, le monde universitaire et l'industrie collaborent sur des voies complémentaires pour remodeler l'ensemble de la chaîne, de la découverte moléculaire à la production du procédé.
La recherche universitaire s'apparente à une exploration pionnière de l'inconnu, visant à dépasser les limites de l'informatique sous-jacente et à innover dans les paradigmes de la recherche scientifique.Des chercheurs du MIT ont astucieusement transposé le « modèle de diffusion » utilisé pour la génération d'images au domaine des réactions chimiques.Il permet un calcul ultra-rapide des structures clés de « l'état de transition », compressant des tâches qui prendraient normalement des jours à réaliser en quelques secondes, et fournissant des informations microscopiques sans précédent sur les prédictions de réactions avec une précision atomique de 0,08 angströms.
Parallèlement, l'équipe de l'université de Stanford s'attache à remodeler la manière dont la recherche elle-même est menée.Le système construit un « laboratoire virtuel » piloté par l'IA, capable de former de manière autonome des équipes virtuelles multidisciplinaires.Coordonnées par une « IA de recherche principale », les collaborations et les débats s'effectuent en quelques secondes, faisant émerger des idées novatrices qui transcendent les approches conventionnelles dans des domaines complexes tels que la conception de vaccins. Par ailleurs, les recherches menées dans des institutions comme l'Université Harvard ont repoussé les limites de la simulation par l'intelligence artificielle à l'échelle macroscopique. Leur cadre unifié a permis de réaliser avec succès des simulations précises de matériaux ferroélectriques complexes contenant des millions d'atomes, offrant ainsi un outil numérique puissant pour la conception fondamentale des matériaux fonctionnels de nouvelle génération.
Comparée à l'esprit pionnier du monde universitaire, l'innovation en entreprise se concentre davantage sur la transformation d'algorithmes de pointe en gains de productivité et de compétitivité sur le marché, afin de résoudre des problèmes concrets. Le géant chimique allemand BASF a déployé l'IA à l'échelle mondiale, en lançant non seulement « AI Chemist Copilot » pour faciliter la recherche et le développement, mais aussi…Le cycle de développement de nouveaux matériaux a été considérablement raccourci par le 60%.De plus, l'IA est profondément intégrée à l'optimisation de la production, à la planification logistique et à la maintenance prédictive, permettant ainsi des gains d'efficacité tout au long de la chaîne de valeur, du laboratoire à l'usine.
Dans le secteur pharmaceutique, des entreprises comme Novartis, dont le siège social est en Suisse, intègrent l'IA de manière globale. Grâce à des collaborations étroites avec des sociétés spécialisées telles qu'Isomorphic Labs et Schrödinger, elles appliquent l'intelligence artificielle à chaque étape clé, de la découverte de nouvelles cibles, la génération de composés et la prédiction de leur innocuité, jusqu'à l'optimisation de la conception des essais cliniques, améliorant ainsi considérablement la fiabilité et le taux de réussite du développement de médicaments.
Au vu de ces avancées majeures, tant dans le monde universitaire qu'industriel, la recherche chimique – discipline traditionnelle autrefois fortement axée sur l'expérience personnelle et la méthode empirique – est profondément transformée par les données et les algorithmes, évoluant inexorablement vers une nouvelle ère de science précise, prévisible, planifiable et automatisée. Des médicaments innovants qui vainquent les maladies aux matériaux écologiques qui contribuent au développement durable, cette transformation profonde de la synthèse chimique intelligente forge des compétences fondamentales sans précédent pour nous aider à relever les défis les plus urgents de notre époque.
Articles de référence :
1.http://edu.people.com.cn/n1/2025/0730/c1006-40532541.html
2.https://cen.acs.org/pharmaceuticals/drug-development/Q-Novartiss-biomedical-research-head/103/web/2025/01








