Command Palette
Search for a command to run...
Tutoriel En Ligne | SAM 3 Améliore La Segmentation Des Concepts Suggérés Avec Des Performances Doublées, Traitant 100 Objets De Détection En 30 Millisecondes

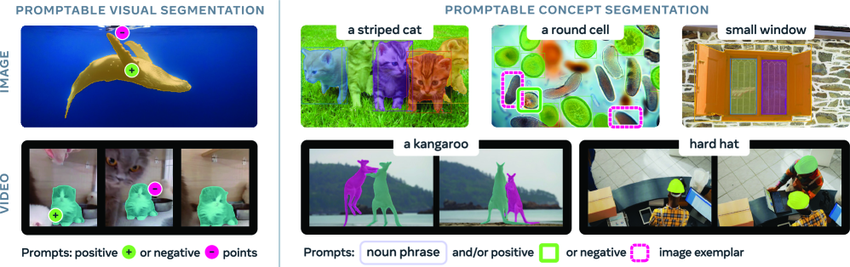
La capacité à identifier et segmenter des objets arbitraires dans des scènes visuelles est un fondement essentiel de l'intelligence artificielle multimodale, avec de nombreuses applications en robotique, création de contenu, réalité augmentée et annotation de données. SAM (Segment Anything Model) est un modèle d'IA généraliste, publié par Meta en avril 2023, qui propose une tâche de segmentation d'images et de vidéos basée sur des indices, et prend principalement en charge la segmentation de cibles individuelles à partir d'indices tels que des points, des boîtes englobantes ou des masques.
Bien que les modèles SAM et SAM2 aient réalisé des progrès significatifs en matière de segmentation d'images, ils ne permettent toujours pas de trouver et de segmenter automatiquement toutes les occurrences d'un concept dans le contenu d'entrée. Pour combler cette lacune,Meta a publié sa dernière version, SAM 3, qui non seulement surpasse considérablement les performances de son prédécesseur en matière de segmentation visuelle indicable (PVS), mais établit également une nouvelle norme pour les tâches de segmentation de concepts indicables (PCS).
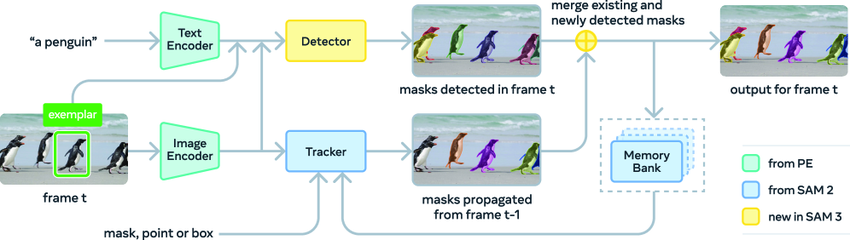
L'architecture SAM 3 comprend un détecteur et un traqueur, qui partagent tous deux le même encodeur visuel.Le détecteur repose sur le framework DETR et peut recevoir du texte, des informations géométriques ou des images d'exemple comme entrées conditionnelles. Afin de relever les défis de la détection de concepts à vocabulaire ouvert, les chercheurs ont introduit un module de présence distinct pour dissocier les processus de reconnaissance et de localisation.
Le module de suivi utilise l'architecture encodeur-décodeur Transformer de SAM 2, prenant en charge la segmentation vidéo et l'optimisation interactive. Cette conception, qui sépare la détection et le suivi, évite efficacement les conflits entre les deux tâches : le détecteur doit préserver son indépendance vis-à-vis des objets, tandis que le module de suivi a pour objectif principal de distinguer et de maintenir l'identité des différents objets présents dans la vidéo.
SAM 3 a obtenu des résultats de pointe (SOTA) sur les tâches PCS d'image et de vidéo du benchmark SA-Co, avec des performances deux fois supérieures à celles de son prédécesseur.De plus, sur le GPU H200, la nouvelle version peut traiter une seule image contenant plus de 100 objets de détection en seulement 30 millisecondes.Ce modèle peut également être étendu au domaine de la reconstruction 3D, contribuant à des applications telles que la prévisualisation de la décoration intérieure, le montage vidéo créatif et la recherche scientifique, et fournissant ainsi une impulsion puissante pour le développement futur de la vision par ordinateur.
Le modèle de segmentation visuelle « SAM3 » est désormais disponible dans la section tutoriels du site web HyperAI (hyper.ai). Lancez-vous dès maintenant dans votre aventure créative !
Lien du tutoriel :
Voir le document :
https://hyper.ai/papers/2511.16719
Essai de démonstration
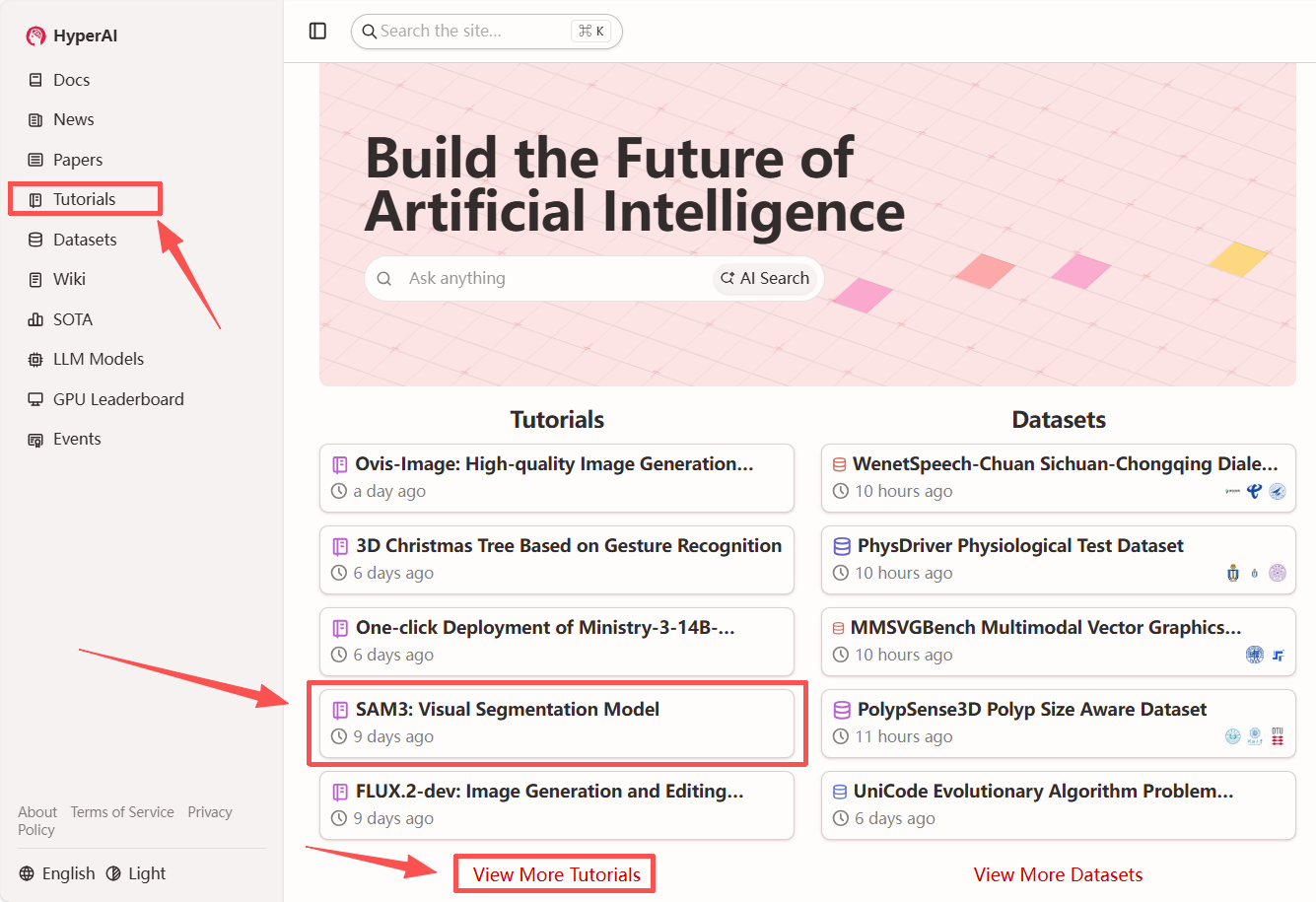
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez « SAM3 : Modèle de segmentation visuelle » ou sélectionnez-le depuis la page « Tutoriels ». Cliquez ensuite sur « Exécuter ce tutoriel en ligne ».
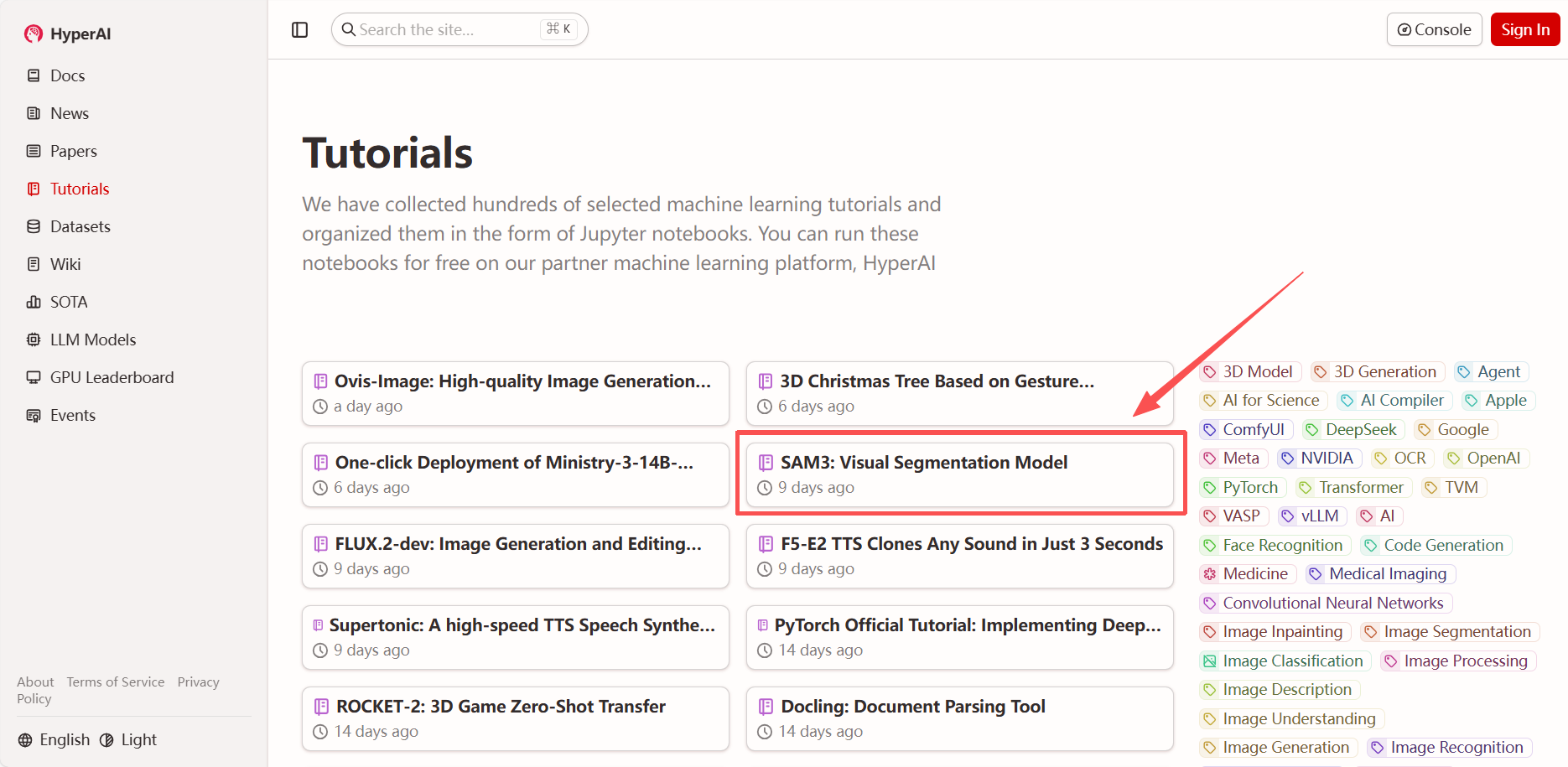
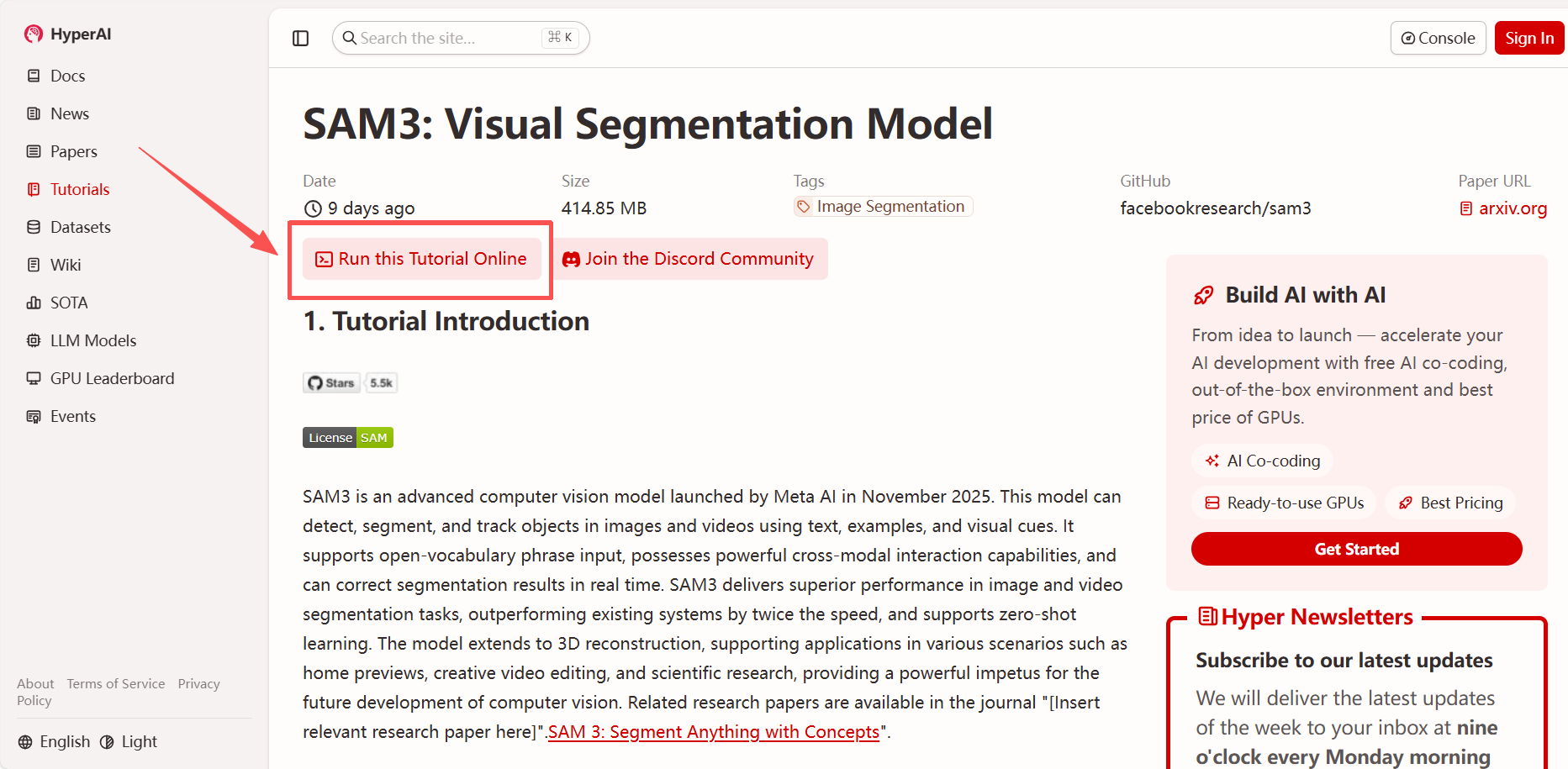
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
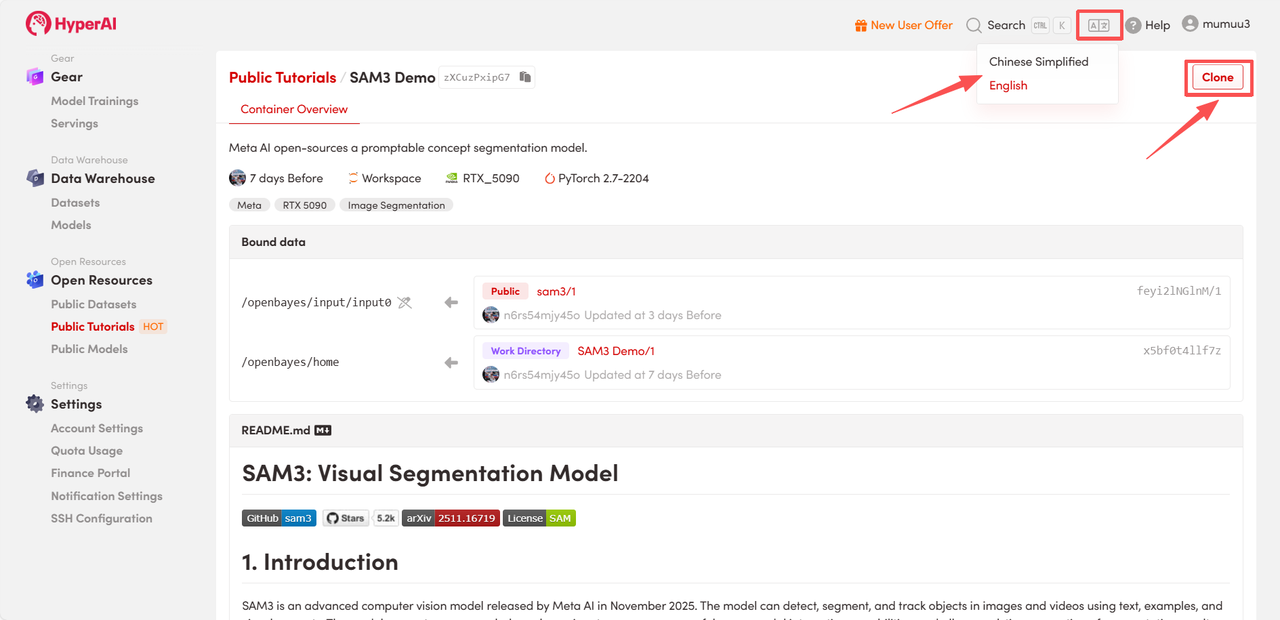
3. Sélectionnez les images « NVIDIA GeForce RTX 5090 » et « PyTorch », puis choisissez « Pay As You Go » ou « Daily Plan/Weekly Plan/Monthly Plan » selon vos besoins, puis cliquez sur « Continuer l’exécution de la tâche ».
HyperAI offre des avantages à l'inscription pour les nouveaux utilisateurs.Pour seulement $1, vous pouvez obtenir 5 heures de puissance de calcul RTX 5090 (prix d'origine $2.45).La ressource est valide en permanence.
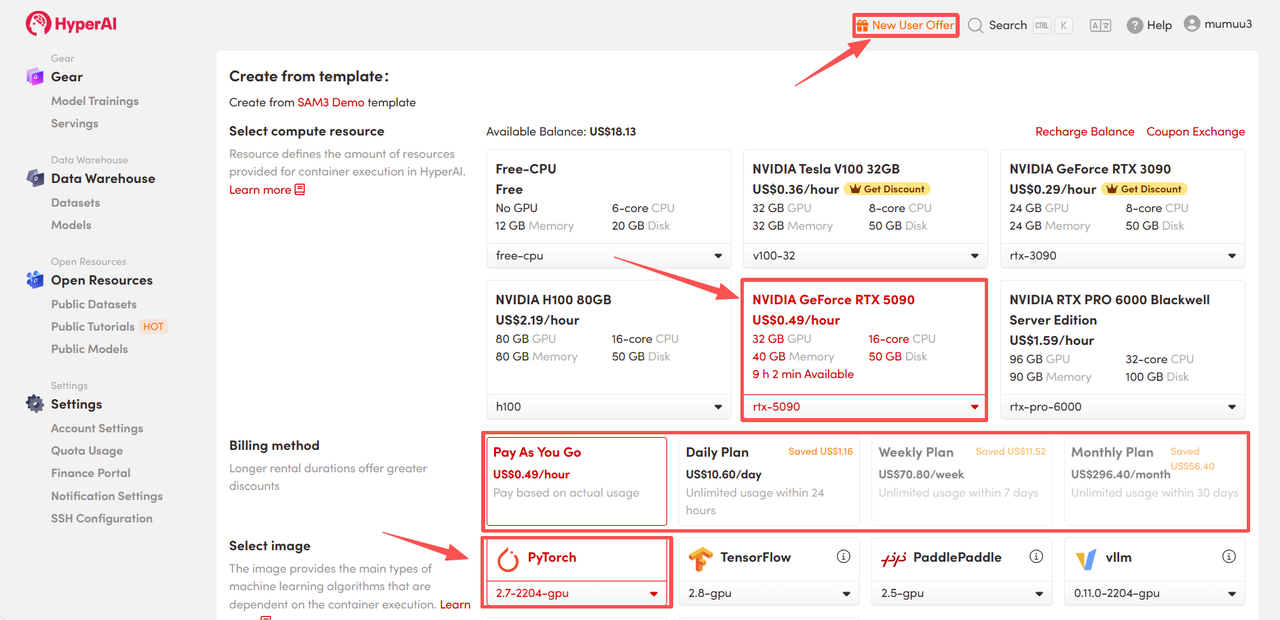
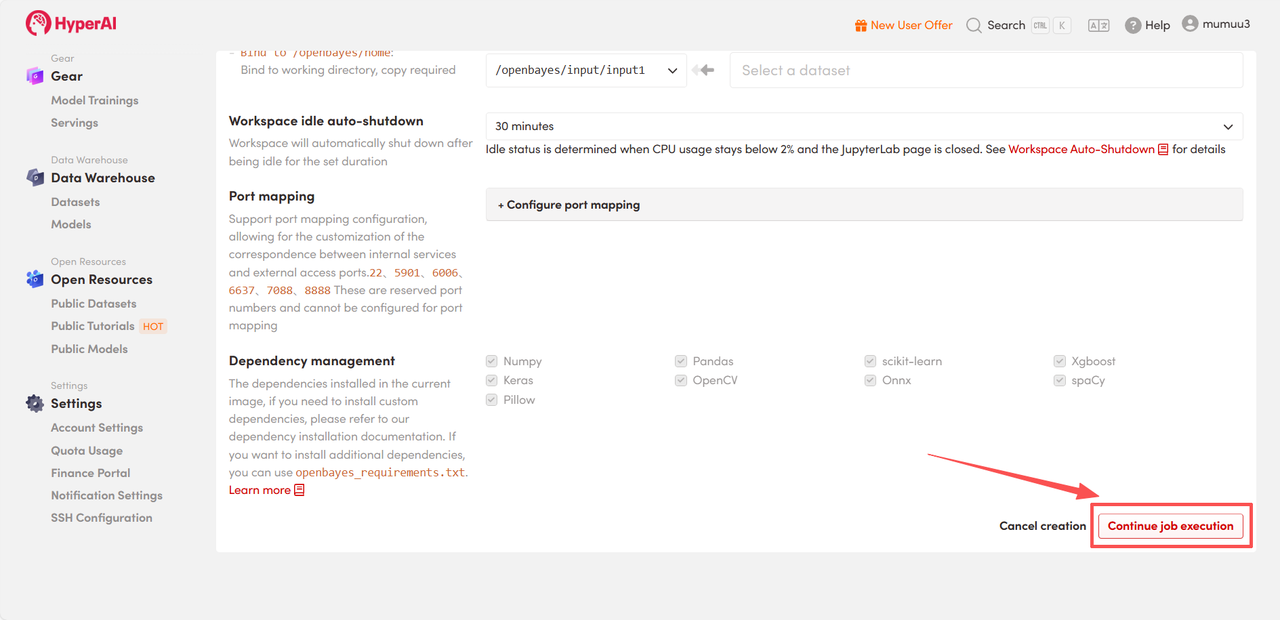
4. Patientez pendant l'allocation des ressources. Le premier clonage prendra environ 3 minutes. Une fois l'état passé à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration.
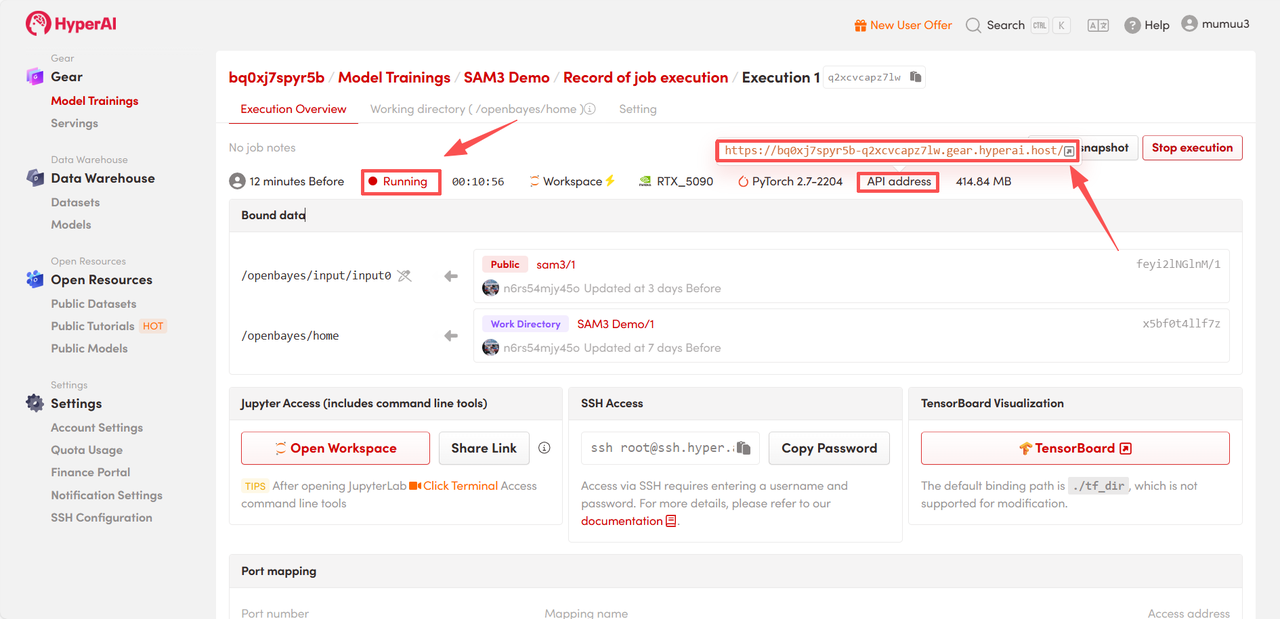
Démonstration d'effet
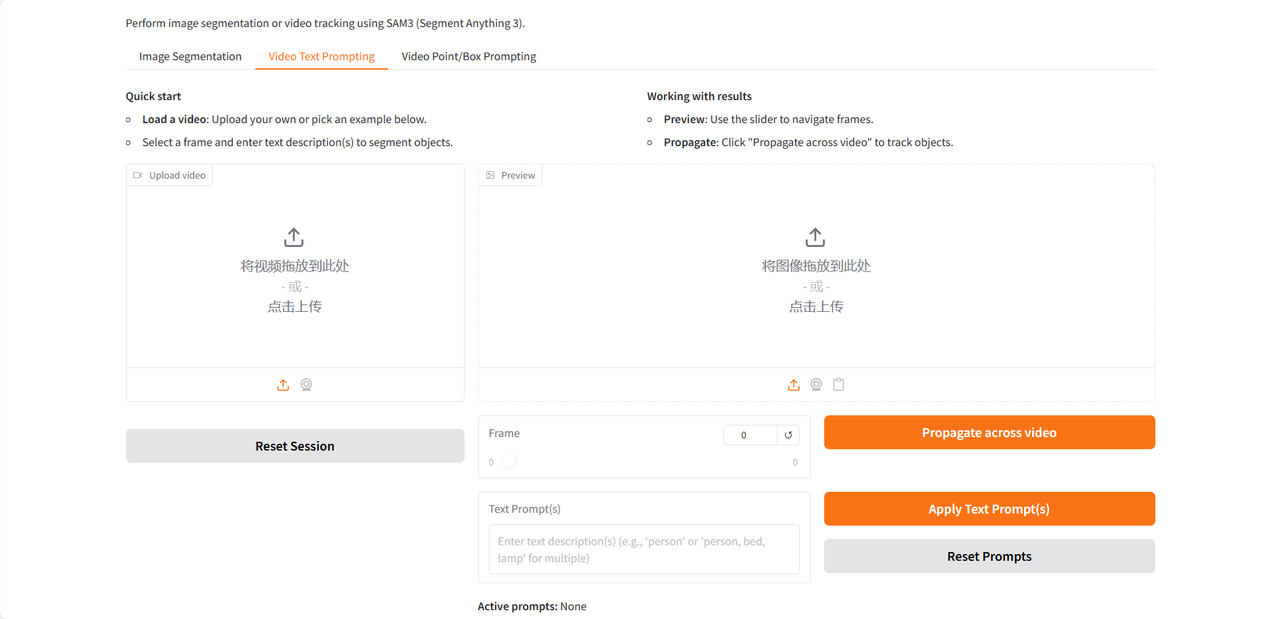
La page de démonstration propose trois fonctionnalités : segmentation d’image, affichage de texte dans la vidéo et affichage de points/boîtes dans la vidéo. Elle ne prend en charge que la saisie en anglais. Ce tutoriel utilise l’affichage de texte dans la vidéo comme exemple.
Après avoir importé la vidéo de test, saisissez les groupes nominaux à identifier et à segmenter dans le champ « Invite(s) de texte », puis cliquez sur « Appliquer l’invite(s) de texte » et « Propager à la vidéo » pour appliquer les invites. Enfin, cliquez sur « Rendu MP4 pour une lecture fluide » afin de générer une vidéo avec la cible identifiée mise en évidence.
Jetons un coup d'œil au test que j'ai effectué en utilisant un extrait de la bande-annonce du film « Zootopia 2 », récemment sorti 👇
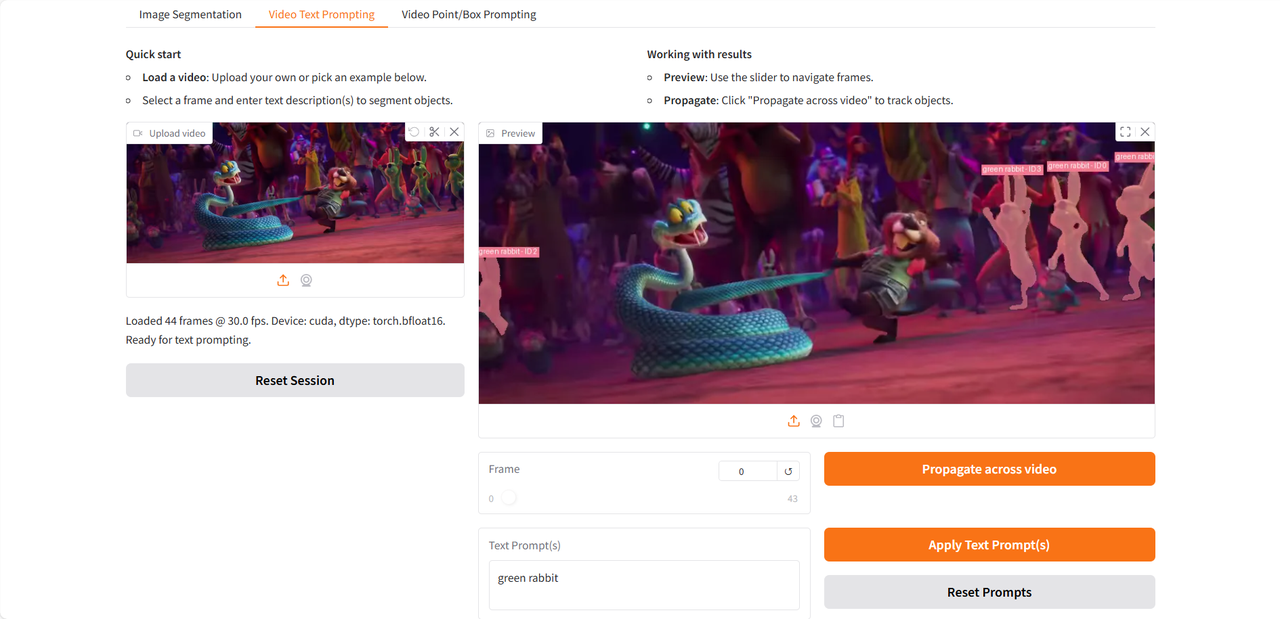
Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :








