Command Palette
Search for a command to run...
Tutoriel En Ligne : Qwen3-Coder-Flash Actualise La Programmation d'IA Open Source À La Pointe De La Technologie, En Comparant Les Capacités d'agentic À Celles De Claude4

L'équipe Tongyi Qianwen d'Alibaba a une fois de plus ouvert son logiciel au public.Le modèle de programmation Qwen3-Coder-Flash est officiellement lancé, ciblant les besoins fondamentaux des utilisateurs avec son positionnement « niveau dessert ».Tout en offrant une efficacité de déploiement de modèle léger, il permet d'atteindre des capacités de traitement de tâches complexes proches des meilleurs modèles à source fermée.
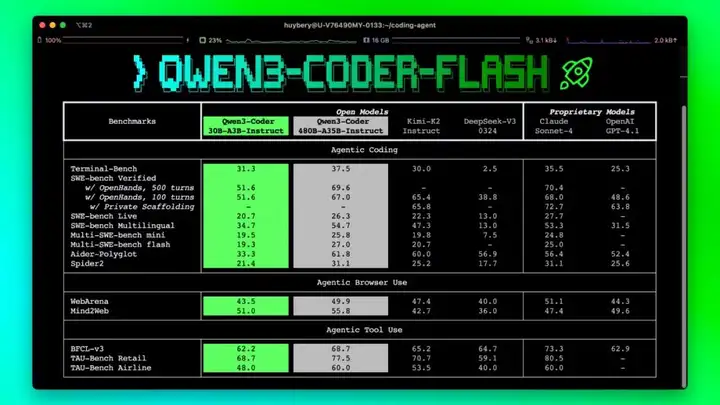
Qwen3-Coder-Flash a réalisé des avancées significatives dans les capacités des agents.Dans les tâches de codage agentique, d'utilisation agentique de navigateur et d'utilisation agentique d'outils, il obtient des résultats SOTA parmi plusieurs modèles open source, comparables à Claude Sonnet4. Il prend en charge nativement 256 000 jetons et YaRN, extensible à 1 M de jetons.La compréhension du contexte long au niveau du référentiel permet de comprendre l’architecture globale du projet.Améliore efficacement les limites de la découpe traditionnelle de fragments de code qui conduisent à la fragmentation ;Dans le même temps, l'utilisation multiplateforme est obtenue en concevant une interface d'appel de fonction.
Ces dernières années, la mise à niveau et le développement des modèles sont progressivement passés d’une expansion à l’échelle d’un seul paramètre à une plus grande importance accordée à l’innovation architecturale.L'open source de Qwen3-Coder-Flash confirme également cette tendance. Il est devenu un moteur d'efficacité conçu et constamment mis à jour pour des scénarios de développement concrets, redéfinissant l'architecture et les limites potentielles des outils d'IA légers, et aboutissant à une véritable normalisation de la productivité de l'IA.
Le module « Déploiement en un clic Qwen3-Coder-30B-A3B-Instruct » est désormais disponible dans la section « Tutoriels » du site officiel d'HyperAI (hyper.ai). Découvrez un nouveau paradigme pour une programmation efficace !
Lien du tutoriel :
Essai de démonstration
1. Sur la page d'accueil hyper.ai, sélectionnez la page Tutoriels, sélectionnez Déploiement en un clic de Qwen3-Coder-30B-A3B-Instruct, puis cliquez sur Exécuter ce tutoriel en ligne.
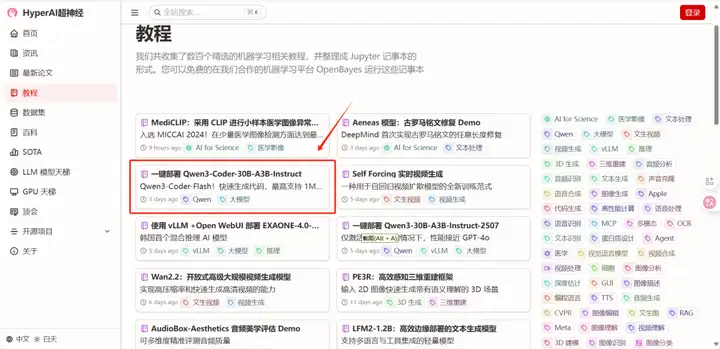
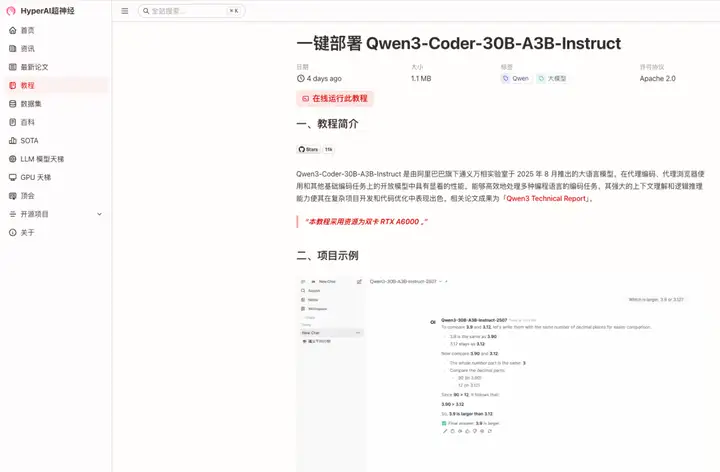
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
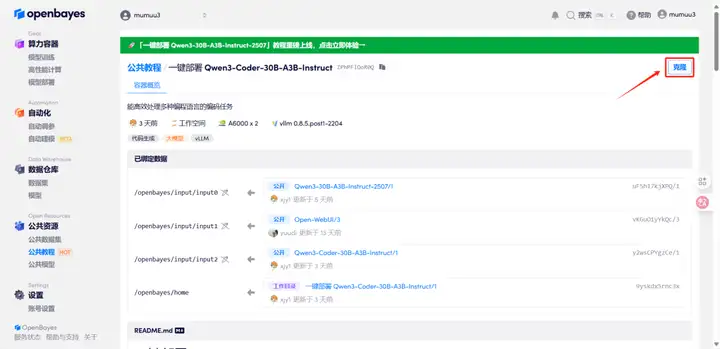
3. Sélectionnez la carte NVIDIA RTX A6000-2 48 Go et l'image vllm, choisissez un forfait à la carte ou journalier/hebdomadaire/mensuel selon vos besoins, puis cliquez sur Continuer. Les nouveaux utilisateurs peuvent s'inscrire via le lien d'invitation ci-dessous pour recevoir 4 heures de RTX 4090 et 5 heures de temps processeur gratuits !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
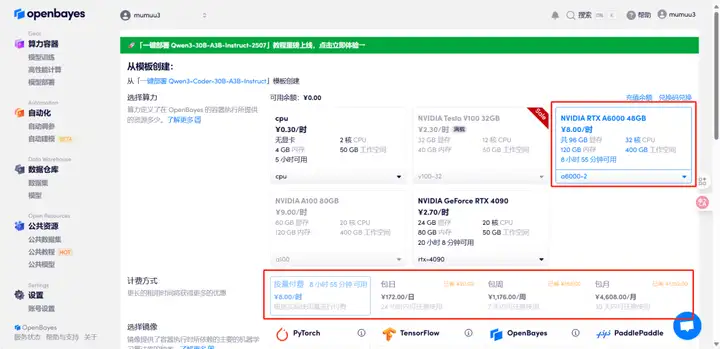
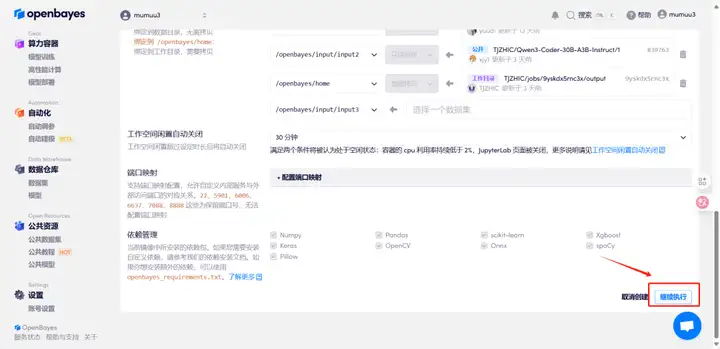
4. Attendez que les ressources soient allouées. Le premier clonage prendra environ 3 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent s'authentifier avec leur nom réel avant d'utiliser l'adresse API.
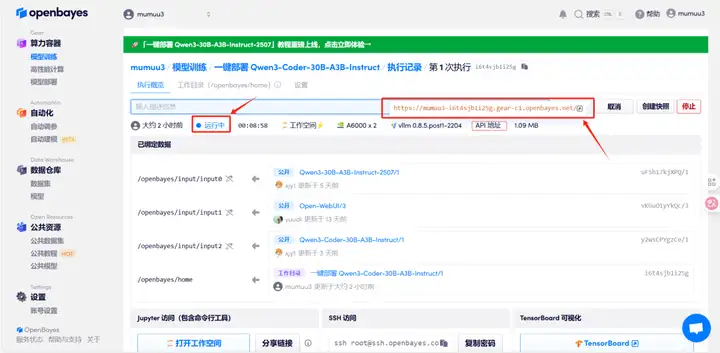
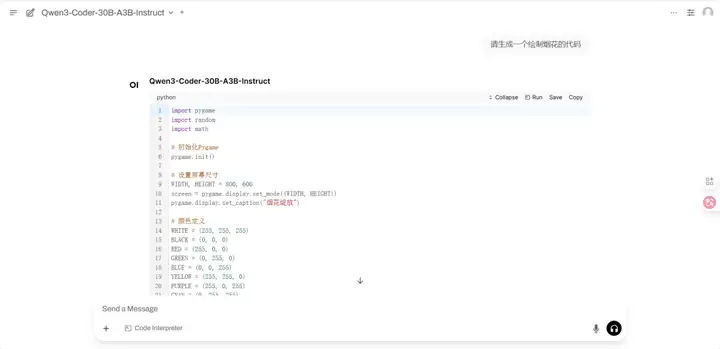
Démonstration d'effet
Après avoir accédé à la page d'exécution, saisissez le mot clé dans la boîte de dialogue et exécutez. L'auteur a utilisé le modèle pour obtenir le code permettant de dessiner des feux d'artifice simples. Non seulement il fonctionne normalement, mais il produit également de bons résultats.