Command Palette
Search for a command to run...
Sur La Base De Plus De 176 000 Données d'inscription, Google DeepMind a Publié Aeneas, Qui a Pour La Première Fois Réussi À Restaurer Des Inscriptions Romaines Antiques De Longueur arbitraire.

Tous les souvenirs des premières civilisations humaines sont cachés dans des inscriptions et des mots. Les inscriptions sont l'une des premières formes d'écriture, offrant une fenêtre sur la pensée, la langue et l'histoire des civilisations anciennes. Des décrets de l'empereur aux pierres tombales des esclaves, ces mots gravés sur des tablettes de pierre et des bronzes sont devenus des preuves directes permettant de déterminer l'âge et de comprendre la culture. On estime que 1 500 nouvelles inscriptions latines sont encore découvertes chaque année, mais l'étude de l'épigraphie se heurte à de nombreuses difficultés, telles que des textes incomplets, des difficultés d'interprétation et des connaissances limitées.
Le 23 juillet 2025, des chercheurs de Google DeepMind, en collaboration avec l'Université de Nottingham, l'Université de Warwick et d'autres universités, ont publié un article de recherche intitulé « Contextualiser les textes anciens avec des réseaux neuronaux génératifs » dans la revue universitaire de premier plan au monde, Nature.
Cette recherche comporte trois points forts innovants majeurs :
* Énée est capable de recevoir à la fois des transcriptions de textes et des images d'inscriptions. Ces images sont traitées par un réseau neuronal visuel superficiel et combinées à des caractéristiques textuelles, ce qui est particulièrement utile pour les tâches d'attribution géographique.
* Auparavant, l'IA ne pouvait réparer que des textes de longueur connue, mais Énée a dépassé les limites de la réparation et a été le pionnier de la capacité de « réparer des textes de n'importe quelle longueur » pour la première fois.
* La compétence principale d'Énée est de trouver les « textes parallèles » les plus pertinents pour l'inscription cible. Ces textes parallèles contiennent non seulement des expressions similaires, mais aussi des liens profonds, tels que le contexte culturel et les fonctions sociales, bien au-delà des limites de la recherche traditionnelle de correspondances de chaînes.
Architecture du modèle : Réseau neuronal génératif multimodal Aeneas
Aeneas est un réseau neuronal génératif multimodal.Un décodeur basé sur Transformer traite les données textuelles et graphiques de l'inscription, tandis qu'un réseau neuronal visuel superficiel extrait les inscriptions similaires de l'ensemble de données d'inscriptions latines et les trie par pertinence. Le texte d'entrée est traité par la partie centrale du modèle, le « torse ».
Aeneas est conçu pour l'analyse contextuelle des inscriptions latines. Son architecture comprend un traitement des entrées, des modules centraux, des en-têtes de tâches et des mécanismes de contextualisation.
Traitement des entrées :L'entrée est la séquence de caractères de l'inscription et une image en niveaux de gris de 224 × 224. La séquence peut contenir jusqu'à 768 caractères. « - » indique les caractères manquants de longueur connue, « # » ceux manquants de longueur inconnue, et < indique le début de la phrase.
Modules de base :Le texte est traité par un torse amélioré du décodeur T5 Transformer, avec 16 couches, 8 têtes d'attention par couche et intégration de la rotation de position relative. L'image est traitée par un réseau visuel ResNet-8. Les sorties du torse et des réseaux visuels sont ensuite dirigées vers des réseaux neuronaux dédiés dans les têtes, qui utilisent le texte pour gérer les tâches de restauration et de datation des caractères. Chaque tête est personnalisée pour gérer trois tâches épigraphiques clés.
En-tête de tâche (chef de tâche):Le résultat comporte des tâches dédiées à la réparation de texte (y compris des tâches auxiliaires pour la réparation de longueur inconnue, en utilisant la recherche de faisceau pour générer des hypothèses), à l'attribution géographique (combinaison de texte et de caractéristiques visuelles pour classer 62 provinces romaines) et à l'attribution chronologique (cartographie des dates en 160 intervalles de décennie discrets), le tout avec des cartes de saillance.
Mécanisme de contextualisation :En intégrant la représentation intermédiaire du torse et de la tête de tâche pour générer des incorporations historiquement enrichies, des inscriptions parallèles pertinentes sont récupérées sur la base de la similarité cosinus pour aider les historiens dans leurs recherches.
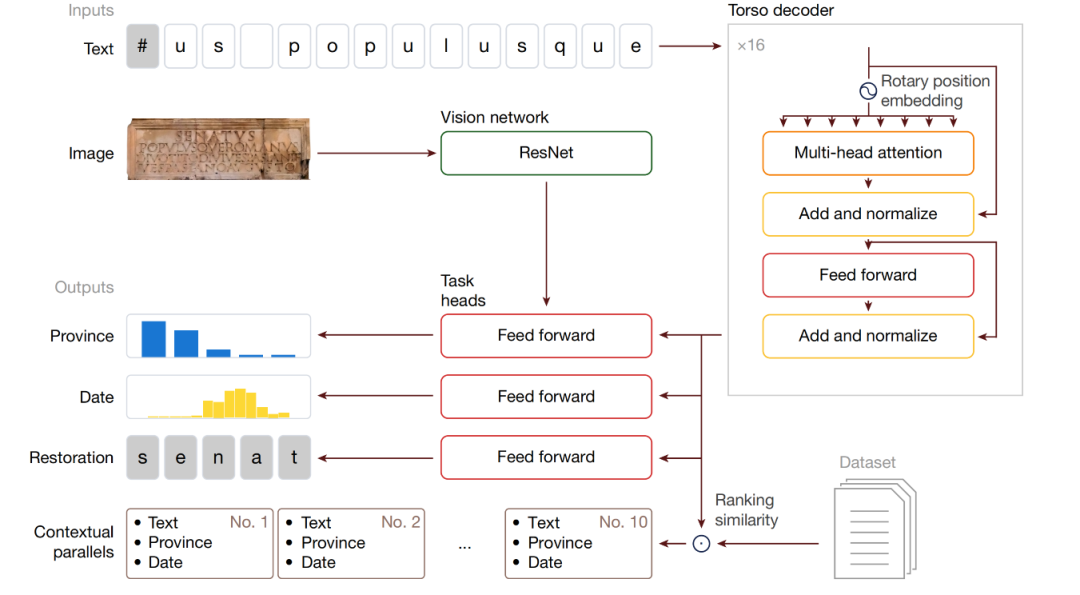
Prenons l'exemple du traitement par Énée de l'expression « Senatus populusque Romanus » : à partir de l'image d'une inscription et de sa transcription textuelle (où les parties endommagées de longueur inconnue sont marquées « # »), Énée traite le texte à l'aide de torses. Les têtes sont responsables de la récupération des caractères, de la datation et de l'attribution géographique (la tâche d'attribution géographique intègre également des caractéristiques visuelles). Les représentations intermédiaires des torses sont fusionnées en un vecteur d'intégration unifié et historiquement riche afin de récupérer les inscriptions similaires dans le Latin Inscriptions Dataset (LED) et de les trier par pertinence.
Il convient de noter queLe modèle d'Énée intègre des données supplémentaires provenant du réseau de vision uniquement pour les tâches de géo-attribution ; les tâches de retouche de texte et d'attribution chronologique n'utilisent pas la modalité visuelle.La tâche de restauration exclut toute entrée visuelle afin d'éviter toute fuite accidentelle d'informations. Étant donné qu'une partie du texte est artificiellement masquée et que sa position exacte dans l'image est inconnue, le modèle peut utiliser des indices visuels pour déduire et restaurer les caractères masqués, compromettant ainsi l'intégrité de la tâche.
Ensemble de données : Le plus grand ensemble de données lisible par machine d'inscriptions latines
La base de données du corpus utilisée pour former le modèle d'Énée est appelée Latin Inscriptions Dataset (LED) dans l'étude, qui est le plus grand ensemble de données d'inscriptions latines exploitable par machine à ce jour. Les données du corpus complet de l'ensemble de données LED proviennent des trois bases de données d'inscriptions latines les plus complètes : la base de données des inscriptions romaines (EDR), la base de données des inscriptions de Heidelberg (EDH) et la base de données Clauss-Slaby. Ces bases contiennent des inscriptions du VIIe siècle avant J.-C. au VIIIe siècle après J.-C. La couverture géographique s'étend des provinces romaines de Bretagne (aujourd'hui la Grande-Bretagne) et de Lusitanie (Portugal) à l'ouest jusqu'à l'Égypte et la Mésopotamie à l'est. Afin de garantir la cohérence de l'ensemble des données LED, l'étude a utilisé des identifiants de la plateforme de données Trismegistos pour gérer les ambiguïtés des données et appliqué un ensemble de règles de filtrage pour traiter systématiquement les annotations humaines afin que le texte puisse être traité par des machines.
Pour obtenir des métadonnées standardisées,L’étude a converti toutes les métadonnées liées aux dates et aux périodes historiques en nombres allant de 800 avant J.-C. à 800 après J.-C.Les inscriptions hors de cette plage ont été exclues. Afin d'améliorer les capacités d'apprentissage et de généralisation du modèle, le contenu textuel substantif de l'ensemble de données a été converti dans un format exploitable par machine, conformément à la norme :
* Supprimer ou normaliser les annotations des historiens sur l'inscription et conserver la version la plus proche de l'inscription originale.
* Les abréviations latines ne sont pas analysées, tandis que les formes de mots qui affichent des orthographes alternatives pour des raisons diachroniques, bidirectionnelles ou flexionnelles sont conservées afin que le modèle apprenne leurs variations épigraphiques, géographiques ou chronologiques spécifiques.
* Conservez les caractères manquants qui ont été restaurés par l'éditeur ou qui n'ont pas pu être finalement restaurés, utilisez des signes dièse (#) comme espaces réservés lorsque le nombre exact de caractères manquants est incertain et réduisez les espaces supplémentaires pour garantir une sortie concise.
* Supprimez les caractères non latins, en ne laissant que les caractères latins, les signes de ponctuation prédéfinis et les espaces réservés.
* Filtrer les inscriptions en double. Les textes dépassant le seuil de similarité de contenu 90% sont considérés comme des doublons.
Après avoir converti le format, l'étude a divisé les LED en ensembles d'entraînement, de validation et de test en fonction du dernier chiffre de l'identifiant d'inscription unique, garantissant une répartition uniforme des images entre les sous-ensembles.

Après avoir mis en œuvre le processus de filtrage automatique, l'étude a obtenu des images d'inscription utilisables à partir de l'ensemble de données en appliquant un seuil à l'histogramme des couleurs pour éliminer les images principalement composées d'une seule couleur pure, en utilisant la variance de la matrice laplacienne pour identifier et éliminer les images floues, et en convertissant les images nettoyées en images en niveaux de gris. L'ensemble de données LED contient un total de 176 861 inscriptions, mais la plupart d'entre elles sont partiellement endommagées et seules les inscriptions 5% peuvent produire des images correspondantes utilisables.
Conclusion/performance expérimentale
Les chercheurs ont évalué la performance du modèle Aeneas sous trois aspects : l’exécution des tâches, la base de référence onomastique, le mécanisme de contextualisation et l’efficacité de la recherche.
* L'onomastique est l'étude de l'origine, de la structure, de l'évolution et de la signification des noms propres tels que les noms de personnes, de lieux, de tribus et de dieux.
Indicateurs d'exécution des tâches
Cette étude utilise trois indicateurs de restauration de texte, l’attribution géographique et l’attribution temporelle pour former un cadre d’évaluation.Parmi eux, les chercheurs ont utilisé des méthodes artificielles pour détruire du texte de longueur arbitraire et ont soumis le modèle pour générer des objets réparés ; dans la tâche d'attribution géographique, les indicateurs de précision standard Top-1 et Top-3 ont été utilisés pour évaluer les performances ; pour l'attribution temporelle, un indicateur explicable a été utilisé pour évaluer la proximité temporelle entre les résultats prédits et les données réelles.
Les expériences montrent que l’architecture d’Énée offre des capacités multimodales.Capable de récupérer des séquences de texte de longueur inconnue,Il peut également être adapté à n’importe quelle langue ancienne et à n’importe quel support écrit tel que le papyrus et les pièces de monnaie, capturant le lien entre les inscriptions et l’histoire dans le processus de contextualisation de la recherche sur les textes anciens.
Base de référence de l'onomastique
L'évaluation automatisée des métadonnées dérivées de l'onomastique par le modèle Aeneas devient un indicateur clé de ses capacités de prédiction d'attribution.Comme il n’existe pas de liste pré-compilée de noms propres romains,L’équipe de recherche a supprimé manuellement 350 éléments du référentiel de noms propres qui ne représentaient pas des noms propres.Les entrées plus courtes ou contenant des caractères non latins en raison d'une ambiguïté d'utilisation ont été exclues, ce qui a donné lieu à une liste organisée d'environ 38 000 noms propres.
Pour améliorer la robustesse de l'approche, les mots les plus courants dans l'ensemble de données ont été identifiés et filtrés pour ne contenir que des entrées provenant d'une liste organisée de noms propres, et leur distribution temporelle et géographique moyenne dans l'ensemble de données de formation a ensuite été calculée afin que le modèle d'Énée puisse exploiter les données de noms propres traitées pour prédire la date et la provenance des nouvelles inscriptions lors de leur analyse.
La méthode d’évaluation du modèle Aeneas pour cette tâche peut être appliquée à l’ensemble des données et permet d’obtenir une évolutivité améliorée.
Mécanisme de contextualisation et efficacité de la recherche
L’étude a évalué l’efficacité du mécanisme de contextualisation du modèle d’Énée comme outil fondamental pour la recherche historique. 23 épigraphistes d’horizons divers ont participé anonymement à l’évaluation.Sur la base de l'expérience de l'exécution de trois tâches d'inscription, l'efficacité de l'utilisation du mécanisme de contextualisation d'Aeneas comme outil auxiliaire de recherche a été évaluée :
* Le modèle d’Énée peut réduire considérablement le temps passé à rechercher des informations pertinentes, permettant aux chercheurs de se concentrer sur une interprétation historique plus approfondie et sur la construction de questions de recherche.
* Les informations récupérées par le modèle d'Énée sont exactes et fournissent des informations précieuses sur le type et le contexte de l'inscription, contribuant ainsi à faire avancer la tâche de recherche.
* Énée élargit la recherche et affine les résultats en identifiant des informations connexes importantes mais jusque-là inaperçues et des caractéristiques textuelles négligées.
Certains experts doutent de l'authenticité
« Énée marque le début de l'intelligence artificielle dans le domaine de l'histoire », a déclaré David Galbraith, expert technique en intelligence artificielle. La percée d'Énée constitue non seulement une avancée technique, mais aussi un signe de l'intégration profonde des sciences humaines et de l'IA. Pour les historiens, il ne s'agit pas d'un substitut aux chercheurs, mais plutôt d'un « super assistant » permettant de réduire le travail mécanique et d'élargir les horizons de la recherche. Parallèlement, dans le domaine de l'IA, il démontre le potentiel des modèles multimodaux et contextualisés pour le traitement de données complexes en sciences humaines et fournit un modèle pour le développement futur de la recherche sur d'autres langues anciennes.
Énée a encore des limites. Face à sa percée, un autre expert en intelligence artificielle s'est inquiété du fait qu'une « dépendance excessive à l'IA pour combler les lacunes soulèverait des questions d'authenticité ».

Certes, l'IA est un outil, et non un véritable substitut. Dans les données d'entraînement, seules 5% d'inscriptions sont dotées d'images, et le nombre d'inscriptions dans certaines régions (comme la Sicile) et périodes (comme avant 600 av. J.-C.) est insuffisant, ce qui entraîne une baisse de la précision des prédictions. Tout cela indique que la technologie actuelle de l'IA est encore immature et que nous devons choisir rationnellement sa place dans la recherche scientifique et la vie quotidienne.








