Command Palette
Search for a command to run...
Tutoriel En Ligne : SpikingBrain-1.0 : Accélération Centuplée : Améliorations Considérables De l'efficacité Des Inférences

Le développement rapide de l'intelligence artificielle est largement indissociable d'une architecture fondamentale : le Transformer. Depuis son lancement en 2017, le Transformer, avec ses capacités de calcul parallèle et ses puissants résultats de modélisation, est devenu la norme pour les architectures de modèles à grande échelle. Qu'il s'agisse des séries GPT, LLaMA ou Qwen, toutes reposent sur le Transformer.
Cependant, à mesure que la taille du modèle continue de s’étendre, Transformer expose progressivement certains problèmes difficiles à ignorer.Par exemple, la surcharge de formation augmente de manière quadratique avec la longueur de la séquence, et l’utilisation de la mémoire pendant l’inférence augmente de manière linéaire avec la longueur de la séquence, ce qui entraîne une consommation de ressources et limite sa capacité à traiter des séquences extrêmement longues.
À l'opposé, le cerveau biologique adopte une approche totalement différente de l'efficacité énergétique et de la flexibilité. Le cerveau humain ne consomme qu'environ 20 watts, mais est capable de gérer un large éventail de tâches, notamment la perception, la mémoire, le langage et le raisonnement complexe. Ce contraste a incité les chercheurs à se demander : si les grands modèles étaient conçus et calculés de manière plus proche du cerveau, pourraient-ils surmonter les obstacles posés par le Transformer ?
Sur la base de cette exploration,L'Institut d'automatisation de l'Académie chinoise des sciences, en collaboration avec le Laboratoire national de la cognition cérébrale et de l'intelligence cérébrale et d'autres institutions, s'est inspiré des mécanismes complexes de fonctionnement des neurones cérébraux et a proposé une architecture de modèle à grande échelle « basée sur la complexité endogène ». En septembre dernier, ils ont publié un modèle à grande échelle d'impulsions cérébrales, produit localement et contrôlable indépendamment : « SpikingBrain-1.0 ».Ce modèle établit théoriquement un lien entre la dynamique intrinsèque des neurones à pointes et les modèles d'attention linéaire, révélant que les mécanismes d'attention linéaire existants constituent une simplification spécialisée du calcul dendritique et ouvrant une voie nouvelle et viable pour améliorer continuellement la complexité et les performances des modèles. Par ailleurs, l'équipe de R&D a construit et publié en open source un nouveau modèle fondamental inspiré du cerveau, basé sur les neurones à pointes, avec une complexité linéaire et linéaire mixte. Elle a également développé un cadre d'apprentissage et d'inférence efficace pour les clusters de GPU domestiques, la bibliothèque d'opérateurs Triton, des stratégies de parallélisation de modèles et des primitives de communication de cluster.
Grâce à la vérification expérimentale,SpikingBrain-1.0 a réalisé des avancées dans quatre aspects de performance : obtenir une formation efficace avec des volumes de données extrêmement faibles, obtenir une amélioration d'un ordre de grandeur de l'efficacité de l'inférence, construire un écosystème de modèles à grande échelle de type cérébral, indépendant et contrôlable, produit localement, et proposer un mécanisme de parcimonie multi-échelle basé sur des impulsions de seuil dynamiques.Le modèle SpikingBrain-7B a permis d'accélérer le temps d'obtention du premier jeton (TTF) jusqu'à 100 fois plus rapidement pour une séquence de 4 millions de jetons. L'entraînement du modèle SpikingBrain-7B a fonctionné de manière stable pendant des semaines sur des centaines de GPU MetaX C550, atteignant un taux d'utilisation FLOP de 23,41 TP3T.Le schéma d'impulsions proposé atteint une rareté de 69,15%, permettant ainsi un fonctionnement à faible consommation d'énergie.
Il convient de noter queC'est la première fois que mon pays propose une architecture de modèle de base linéaire de type cerveau à grande échelle, et la première fois qu'un cadre de formation et d'inférence pour un modèle d'impulsion de type cerveau à grande échelle est construit sur un cluster de calcul GPU national.Sa capacité de traitement de séquences ultra-longues présente des avantages potentiels significatifs en termes d'efficacité dans les scénarios de modélisation de tâches de séquences ultra-longues tels que l'analyse de documents juridiques et médicaux, la simulation multi-agents complexe, les expériences de physique des particules à haute énergie, l'analyse de séquences d'ADN et les trajectoires de dynamique moléculaire.
« SpikingBrain-1.0 : Un modèle de stimulation cérébrale basé sur la complexité intrinsèque » est disponible sur le site officiel d'HyperAI, dans la section « Tutoriel ». Cliquez sur le lien ci-dessous pour accéder au tutoriel de déploiement en un clic ⬇️
Lien du tutoriel :
Essai de démonstration
1. Après avoir visité la page d'accueil de hyper.ai, sélectionnez la page « Tutoriels », choisissez « SpikingBrain-1.0 : un grand modèle de pics semblable à un cerveau basé sur la complexité intrinsèque » et cliquez sur « Exécuter ce tutoriel en ligne ».
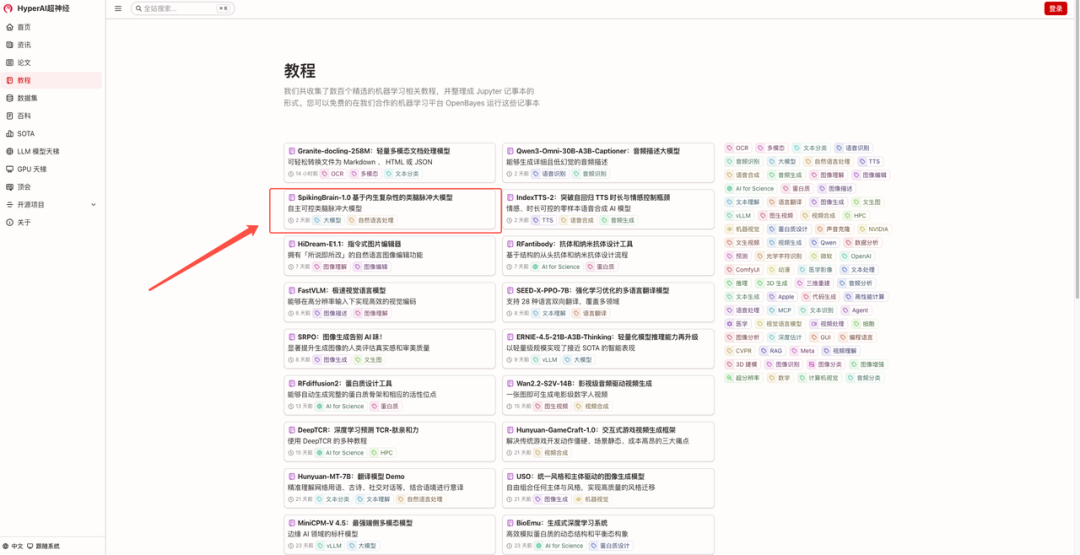
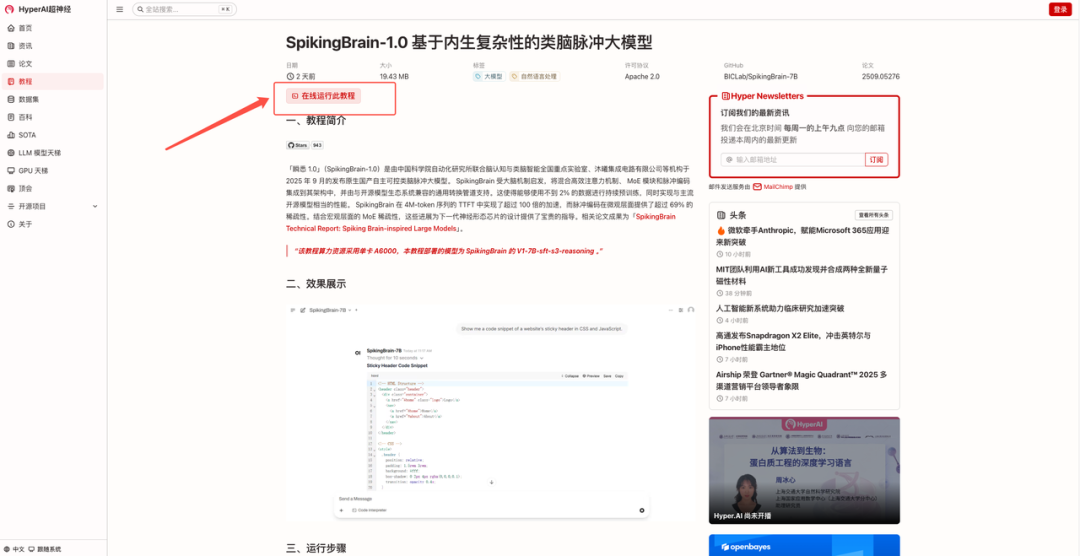
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
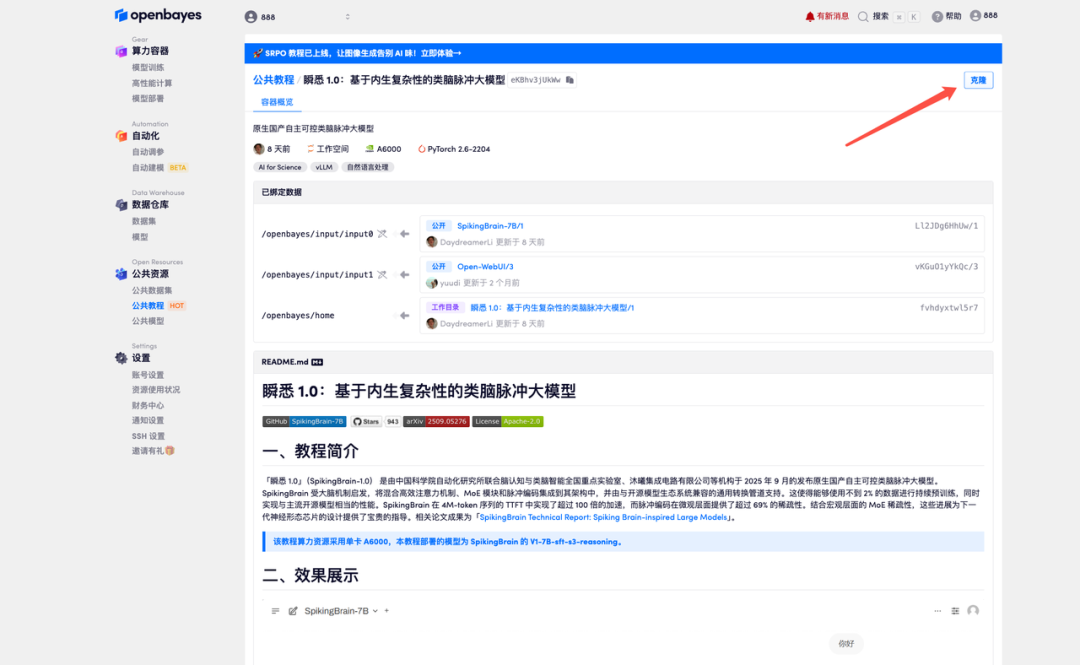
3. Sélectionnez les images NVIDIA RTX A6000 48 Go et PyTorch, puis cliquez sur Continuer. La plateforme OpenBayes propose quatre options de facturation : paiement à l'utilisation ou forfait journalier, hebdomadaire ou mensuel. Les nouveaux utilisateurs peuvent s'inscrire via le lien d'invitation ci-dessous pour recevoir 4 heures de carte graphique RTX 4090 et 5 heures de temps processeur gratuits !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
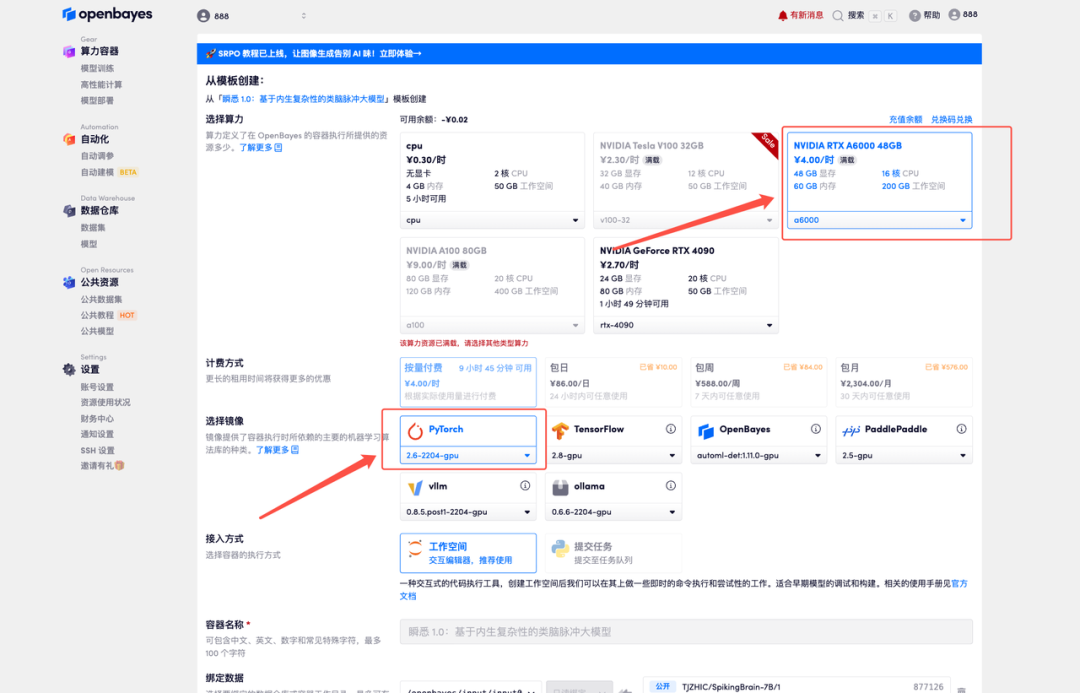
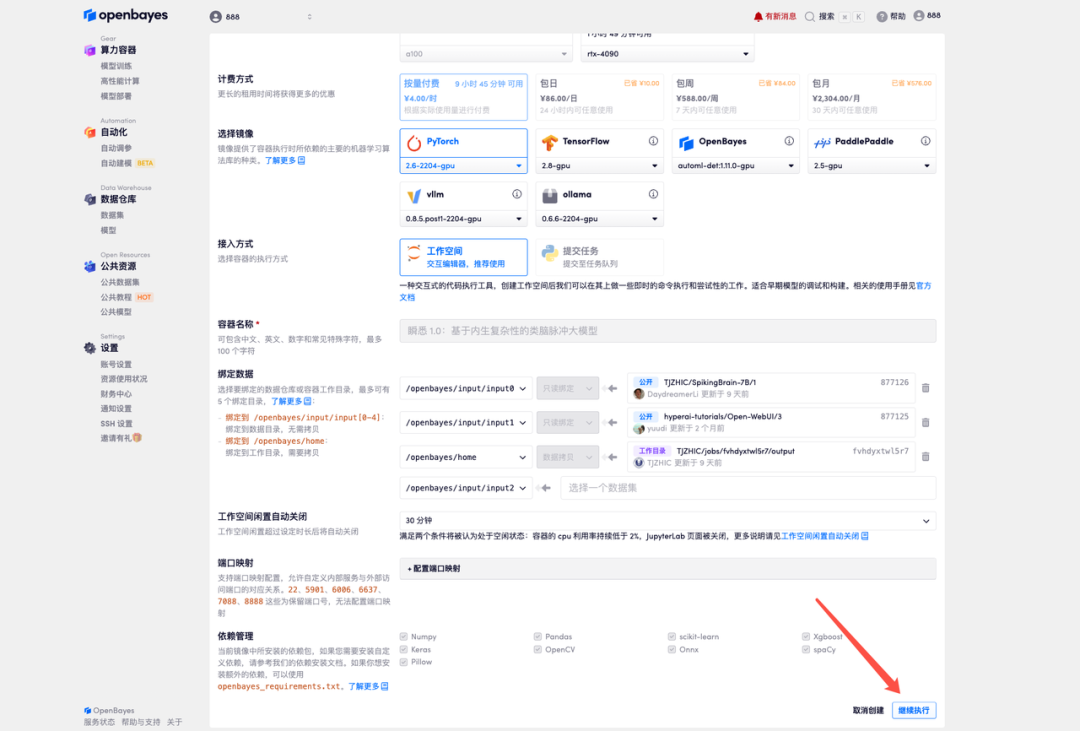
4. Attendez que les ressources soient allouées. Le premier clonage prendra environ 3 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent s'authentifier avec leur nom réel avant d'utiliser l'adresse API.
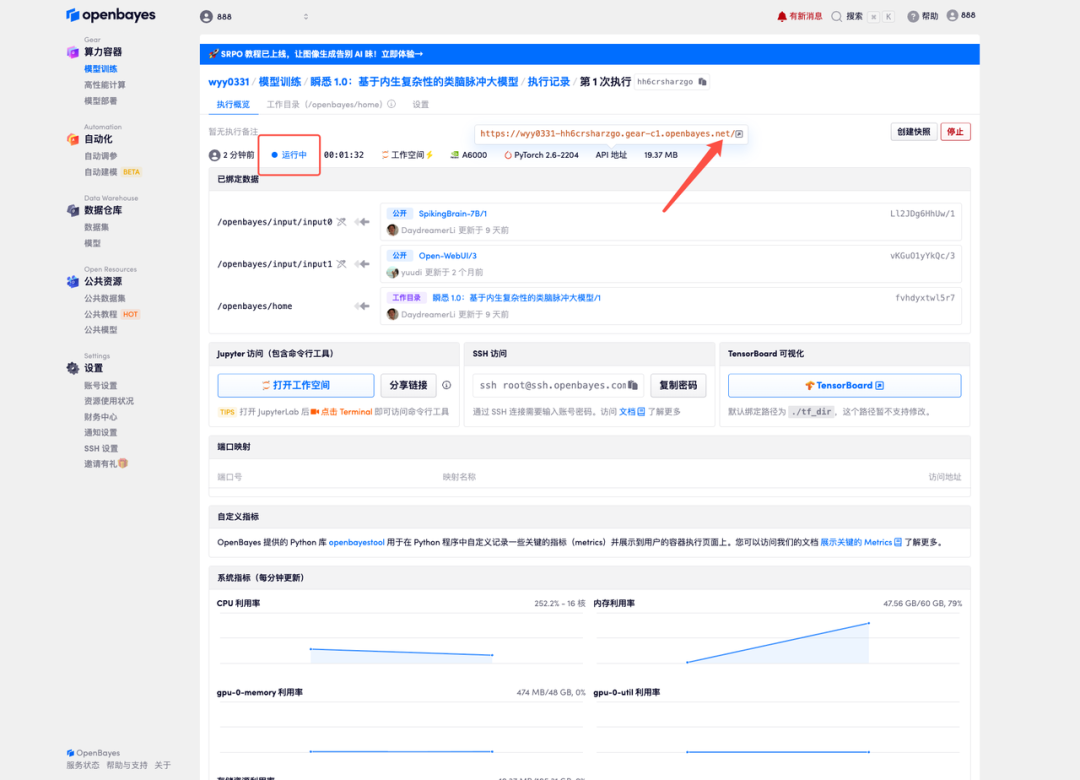
5. Saisissez la question dans la boîte de dialogue pour commencer à répondre.
Démonstration d'effet
J'ai posé la question « Montrez-moi un extrait de code de l'en-tête fixe d'un site web en CSS et JavaScript » à titre d'exemple. Le résultat est présenté dans la figure ci-dessous :

Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :








