Command Palette
Search for a command to run...
Du Modèle Cardiaque Entier À l'analyse Du Réseau De Maladies Basée Sur Le LLM, Li Dong De l'hôpital Tsinghua Chang Gung Analyse La Tendance De Développement Des Grands Modèles Médicaux Du Point De Vue Des Données

À mesure que l'intelligence artificielle progresse, elle a également profondément transformé le domaine médical. En intégrant des données multi-sources et des algorithmes intelligents, elle a apporté de nouvelles solutions pour améliorer l'efficacité et la précision des diagnostics dans le secteur médical. Les données médicales, véritables carburants des grands modèles et vecteurs essentiels de la prise de décision médicale, jouent un rôle essentiel.Surtout dans le contexte de la transformation numérique accélérée du système médical chinois, l’analyse des modèles médicaux du point de vue des données est une voie inévitable vers l’innovation.
Récemment, lors de la conférence Zhiyuan de Pékin 2025, le professeur Li Dong, directeur du Centre des sciences des données médicales de l'hôpital Tsinghua Chang Gung, s'est exprimé lors du forum « AI+Science & Medicine ».Le thème est « Comment utiliser les données médicales pour mener des recherches innovantes à l’ère des soins de santé intelligents ».Combiné à l'expérience pratique de l'hôpital commémoratif Tsinghua Chang Gung,Du point de vue des données, plusieurs dimensions, notamment le modèle de mise en œuvre du grand modèle, les limitations techniques, la reconstruction des ressources et l'exploration des applications, ont été partagées.

HyperAI a compilé et résumé les propos approfondis du professeur Li Dong sans en compromettre l'intention initiale. Voici la transcription de son discours.
Application et défis des grands modèles dans les scénarios médicaux
Application en mode « Déploiement local + développement personnalisé + utilisation hors ligne »
DeepSeek est un modèle à grande échelle qui a connu un grand succès ces dernières années. Il propose trois principaux modes d'utilisation dans le domaine médical : un mode d'utilisation simplifié sur mobile, un mode d'accès au cloud et un déploiement local + développement personnalisé + utilisation hors ligne.
Parmi ces trois méthodes d’accès,« Déploiement local + développement personnalisé + utilisation hors ligne » est devenu la solution optimale dans la pratique.En raison de la restriction de la politique « les données ne peuvent pas quitter l'hôpital », le modèle cloud ne peut pas utiliser de données réelles pour l'entraîner, ce qui en fait un « modèle statique ». De plus, l'application mobile légère ne peut gérer que des consultations simples et ne peut répondre aux besoins médicaux essentiels. Bien que la combinaison « déploiement local + développement personnalisé + utilisation hors ligne » permette d'éviter les risques de fuite et de pollution des données (comme le mélange de données d'hallucinations exogènes), elle implique également que l'hôpital doit assumer seul les coûts élevés de puissance de calcul.
Les défis des grands modèles dans le secteur de la santé
Le processus de mise en œuvre du grand modèle à l’hôpital comporte de nombreux défis.Par exemple, les défauts algorithmiques, les problèmes d’hallucinations, les pièges de puissance de calcul, l’équité de l’IA, etc.
* Défauts d'algorithme :La popularité de DeepSeek s'explique par son open source et son faible coût. Le « mode expert mixte » sur lequel il repose abaisse le seuil de puissance de calcul en divisant le réseau neuronal, mais il présente des limites dans les situations médicales : d'une part, il ne prend pas en charge la consultation multimodale, et la prise de décision par un seul expert est sujette à des diagnostics manqués face à des cas complexes ; d'autre part, afin de préserver la puissance de calcul, les données seront publiées aléatoirement en ligne, ce qui peut entraîner la perte d'informations clés (comme les antécédents allergiques ou chirurgicaux) et présenter des risques cachés pour le diagnostic et le traitement.
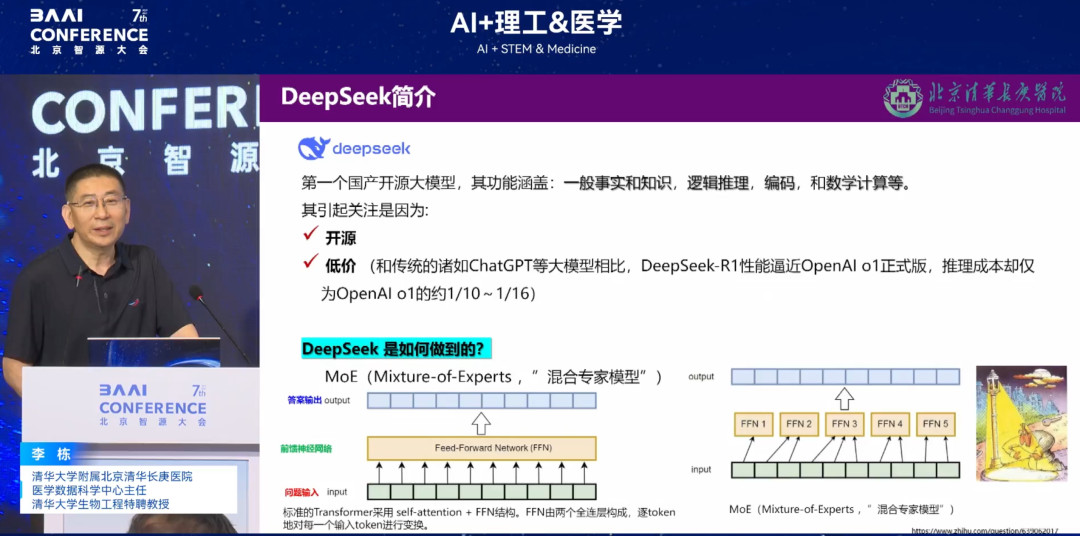
* Problèmes d'hallucinations :DeepSeek présente un certain pourcentage d'hallucinations dans certains cas médicaux spécifiques. Nous utilisons un mécanisme de triple vérification (dépistage initial par algorithme, examen par un médecin et comparaison avec la base de connaissances) pour réduire les risques, mais cela augmente le temps nécessaire au diagnostic et au traitement.
* Piège de puissance de hachage :La consommation d’énergie des petits centres de calcul est déjà stupéfiante, et la formation de modèles médicaux plus complexes et de grande taille nécessite un investissement continu.
* Équité de l'IA :Les principaux hôpitaux monopolisent les modèles avancés en exploitant leurs avantages en matière de ressources, ce qui peut exacerber la « fracture numérique ».
Reconstruction des normes d'évaluation médicale : de la « norme à trois niveaux » à la « concurrence à six facteurs »
Le déploiement de modèles à grande échelle dans le domaine médical est bien plus complexe que prévu. La Commission nationale de la santé espérait initialement remédier au déséquilibre des ressources médicales grâce à l'IA, mais trois mois après son déploiement, nous avons constaté que les résultats étaient contre-productifs. Loin d’améliorer le déséquilibre des ressources médicales, le grand modèle remodèle le paysage concurrentiel des hôpitaux tertiaires.
Les critères d'évaluation des hôpitaux tertiaires traditionnels sont « des médecins renommés, des équipements et un environnement matériel », mais à l'ère des grands modèles, trois nouveaux seuils ont été ajoutés :
Le premier est une puissance de calcul puissante.L'hôpital Chang Gung Memorial possédait autrefois la deuxième plus grande capacité informatique parmi les établissements médicaux de Pékin, mais il ne pouvait toujours pas assurer la formation à long terme. La mise en service d'un petit centre informatique pouvait même provoquer une panne de courant dans la moitié du bâtiment.
Le deuxième est un ingénieur en gouvernance des données de premier ordre.Les données médicales comprennent les dossiers médicaux électroniques, les images, les tests et autres types de données, qui doivent être nettoyés, étiquetés et structurés. Nous avons investi 5 millions dans un cycle de gouvernance des données, mais l'impact n'a pas été significatif ;
Enfin, un ingénieur algorithmique de premier ordre.Les algorithmes doivent être personnalisés en fonction des scénarios médicaux pour résoudre le problème de la « boîte noire » et la reconnaissance des « hallucinations ».
Soins de santé intelligents : innovation basée sur les données dans les modèles de soins de santé
Comme le montre la figure ci-dessous, depuis 1950, le nombre de nouveaux médicaments approuvés pour chaque milliard de dollars d'investissement en R&D a diminué de moitié presque tous les neuf ans. Cette tendance est restée très stable au cours des 60 dernières années. Ce phénomène est connu sous le nom de « loi anti-Moore » dans l'industrie pharmaceutique.Le coût de développement de nouveaux médicaments est de plus en plus élevé, et la recherche et le développement de médicaments sont confrontés à une grave crise de productivité.
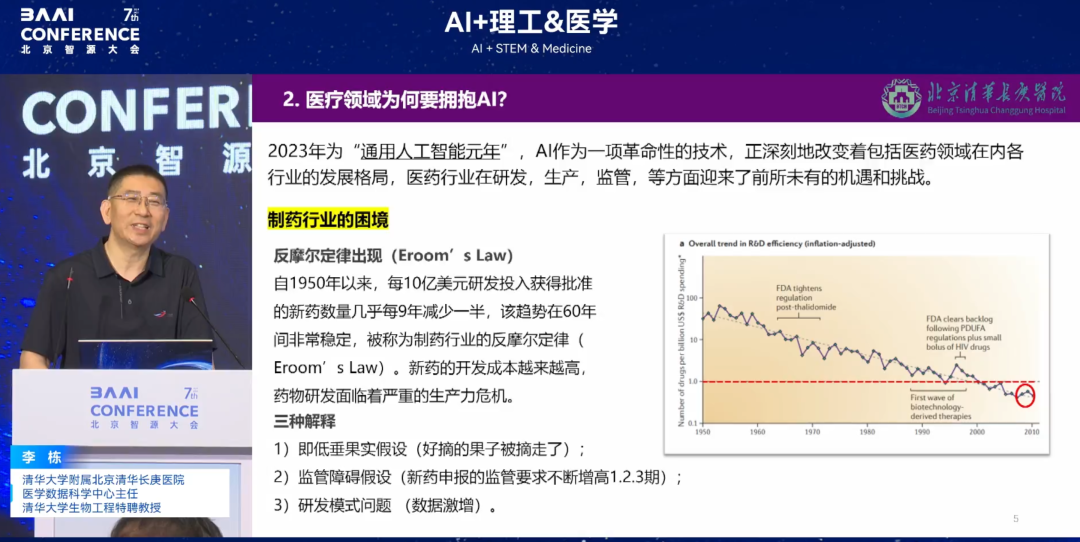
Cela vaut non seulement pour l'industrie pharmaceutique, mais aussi pour l'ensemble du secteur médical. Comme le montre la figure ci-dessous :Selon les statistiques de 2018, le nombre d'hôpitaux de classe III en Chine représentait 7 631 TP3T du pays, mais ils étaient responsables de 50 971 TP3T du volume de patients ambulatoires du pays.Une série de problèmes sont apparus, notamment une répartition inégale des ressources médicales, une faible efficacité des diagnostics et des traitements, et la pression exercée par l'évolution du spectre des maladies due au vieillissement de la population. Par conséquent, à l'ère des soins de santé intelligents, l'IA est impérative pour accélérer la transformation médicale.
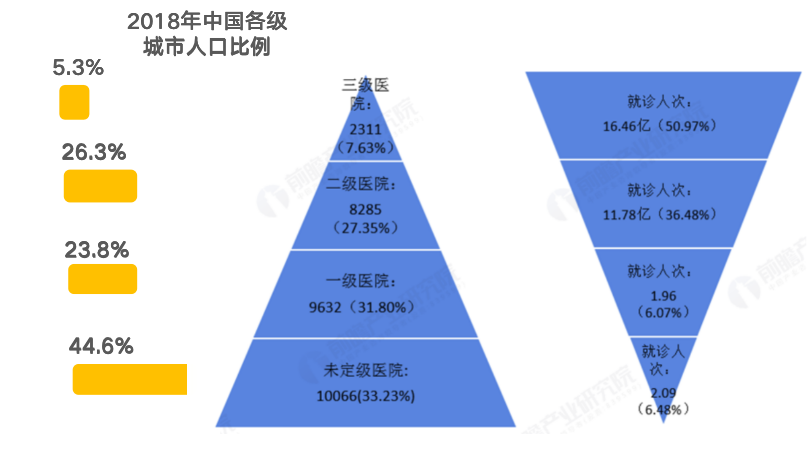
(Unité : ménage, 100 millions de personnes, %), Source : Commission nationale de la santé (organisée par le Prospective Industry Research Institute)
Algorithme de pilotage de régression logistique traditionnel comme référence
Alors que les domaines clinique et pharmaceutique adoptent la tendance de l'IA, la régression logistique traditionnelle peut être utilisée en recherche clinique, mais elle présente des lacunes importantes. Prenons l'exemple de l'évaluation quantitative de la corrélation entre pollution atmosphérique à long terme et fibrose myocardique : les méthodes traditionnelles collectent généralement des caractéristiques sociodémographiques, des biomarqueurs et des rapports d'imagerie (analyses omiques non liées à l'imagerie), intègrent des variables telles que les PM2,5 et PM10 au modèle et analysent leur corrélation avec des maladies (comme la fibrose corporelle).
Cependant, ce type d'analyse de corrélation, pratiqué depuis les années 1970, présente des failles fondamentales : la recherche médicale doit explorer la causalité, mais les méthodes traditionnelles ne peuvent découvrir que la corrélation de variables prédéfinies et ne peuvent identifier de nouveaux facteurs de risque qui n'ont pas été présélectionnés dans le modèle, tombant ainsi dans le paradoxe du cycle de « l'œuf et de la poule ». De plus,L'analyse de corrélation traditionnelle peine à gérer les interactions entre variables et ne peut généralement analyser que celles de deux ou trois facteurs. Elle ne peut pas prendre en compte des centaines, voire des milliers de variables, ni accéder directement aux données d'images.
En revanche,L'analyse algorithmique présente des avantages significatifs : elle peut gérer des interactions multivariées, incorporer des quantités massives de données (y compris des images) et, grâce à un entraînement répété des jetons (exécuté 10 000, voire 100 millions de fois),Si un facteur de risque persiste, il peut être considéré comme « causal », ce qui est plus proche de la relation causale requise pour la recherche médicale.
Reconstruire les 4 éléments de l'IA médicale : allocation des ressources priorisée par scénario
La santé intelligente est un nouveau modèle médical qui utilise les technologies de l'information modernes pour améliorer les services et la gestion médicaux, afin d'accroître l'efficacité médicale, de réduire les coûts médicaux et d'améliorer l'expérience des patients. Son fondement repose sur le big data, le cloud computing, l'Internet des objets et l'IA.
Dans la cognition traditionnelle, les trois éléments de l’intelligence artificielle sont les algorithmes, la puissance de calcul et les données.Cependant, dans le scénario médical, nous proposons la « théorie des quatre éléments », à savoir l'algorithme, la puissance de calcul, les données et les scénarios d'application, leurs proportions respectives étant de 10%, 30%, 40% et 20%.Étant donné la faible différence entre les algorithmes nationaux et internationaux, et leur caractère majoritairement open source, ils représentent la plus faible part des éléments d'IA médicale. La puissance de calcul peut être allégée par la location de ressources cloud ; les scénarios d'application sont utilisés comme auxiliaires pour fournir la sémantique permettant de convertir les besoins cliniques en « tâches » compréhensibles par le modèle. Nous avons ainsi constaté que les « données » sont le facteur déterminant. La Chine est le leader mondial en termes de volume de données médicales, mais son faible taux d'informatisation en a fait une « mine d'or inexploitée ». On estime que d'ici 2028, la croissance des données médicales structurées traditionnelles dans le monde sera difficile à satisfaire aux besoins des grands modèles (la collecte de données a débuté en 1550), et la Chine deviendra la base de données centrale de la recherche et du développement médicaux mondiaux, faute d'informatisation complète de ses données historiques.
Deux approches de la formation aux données médicales
De nombreux sceptiques s'expriment quant à l'entraînement de modèles de grande taille, notamment quant à la possibilité d'utiliser directement les données hospitalières pour l'entraînement. Cependant, l'expérience montre que cette approche n'est pas réalisable.Il existe deux approches pour former de grands modèles.
Tout d’abord, les besoins en données des grands modèles dépassent de loin ceux de la recherche clinique.Bien qu'il soit difficile pour les hôpitaux de gérer les données de manière à ce qu'elles puissent être utilisées pour la recherche clinique, l'apprentissage des grands modèles impose des exigences plus élevées en matière de données. En effet, même si les grands modèles disposent de capacités d'apprentissage non supervisé, s'appuyer uniquement sur cet apprentissage revient à transformer un médecin en médecin-chef : ce processus est trop lent et ne répond pas aux besoins réels. Pour accélérer l'apprentissage, il est nécessaire de l'équiper d'un arbre de décision médical. Ainsi, il ne suffit pas d'introduire les données dans le grand modèle, mais de les traiter et de les optimiser plus en profondeur.
Deuxièmement, si les hôpitaux souhaitent utiliser directement de grands modèles pour la formation, ils doivent adopter le modèle de gouvernance des données « bibliothèque + bibliothèque spécialisée + bibliothèque de maladies spéciales + bibliothèque de projets spéciaux ».Ce modèle, développé après l'intégration de l'exploration pratique de plusieurs hôpitaux, dont l'hôpital Tiantan, est considéré comme un modèle de données actuellement plus adapté à l'entraînement de modèles à grande échelle. Cette structure hiérarchique de gouvernance des données permet de fournir des données systématiques et de haute qualité pour les modèles à grande échelle de manière plus ciblée, améliorant ainsi l'efficacité et l'efficacité de l'entraînement de ces modèles.

Recherche sur les maladies cardiovasculaires et le diabète : un modèle d'innovation basée sur les données
Enfin, permettez-moi de parler brièvement de deux études que nous avons menées sur la base de soins de santé intelligents.
IA cardiovasculaire : des « dispositifs portables » aux « modèles cardiaques complets »
Selon les prévisions de Statista concernant la taille du marché mondial des soins de santé intelligents en 2025, le secteur cardiovasculaire représentera un quart de ce marché, ce qui en fait le segment de marché le plus important. La numérisation intervient tout au long des phases aiguës et de guérison des maladies cardiovasculaires.
Après le lancement de la première génération d'Apple Watch, sa sonde unique a permis des prédictions plus précises que douze sondes et a permis d'identifier la fibrillation auriculaire (FA) et d'autres types d'arythmies chez le porteur, innovant ainsi en soins primaires. Fort de cette inspiration,Notre équipe a proposé l'hypothèse suivante : « Étant donné que la forme d'onde de l'électrocardiogramme (ECG) basée sur des appareils portables peut prédire l'arythmie de manière précoce, d'autres appareils portables sans fonction ECG peuvent-ils obtenir le même effet uniquement via la fréquence cardiaque ? »Après une série de vérifications, nous avons constaté que d'autres appareils pouvaient obtenir le même effet avec une précision allant jusqu'à 99,67%. Notre équipe a collecté les battements cardiaques par minute de bracelets de sport ordinaires sur une période de 24 heures afin de prédire la durée de l'arythmie.
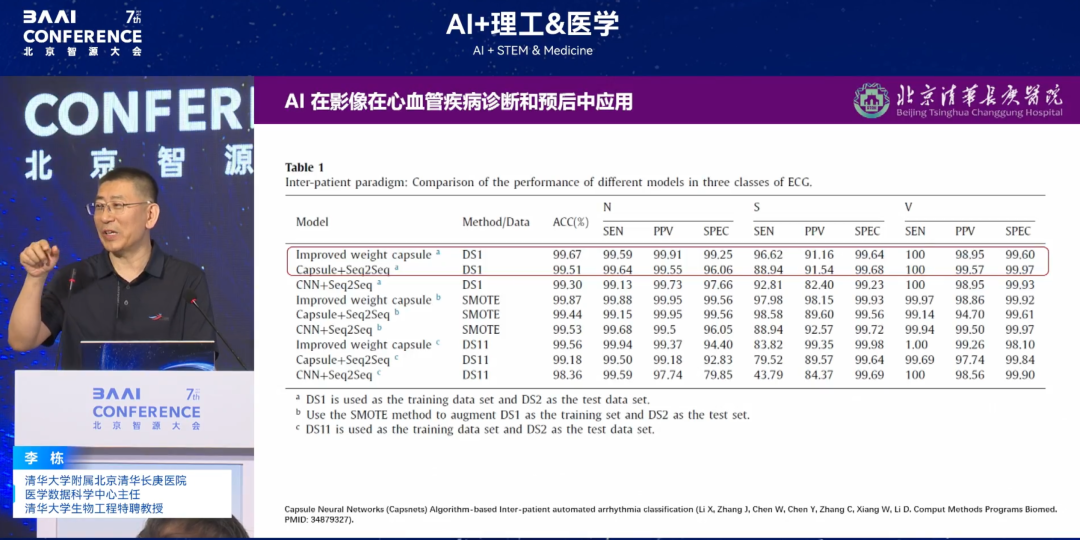
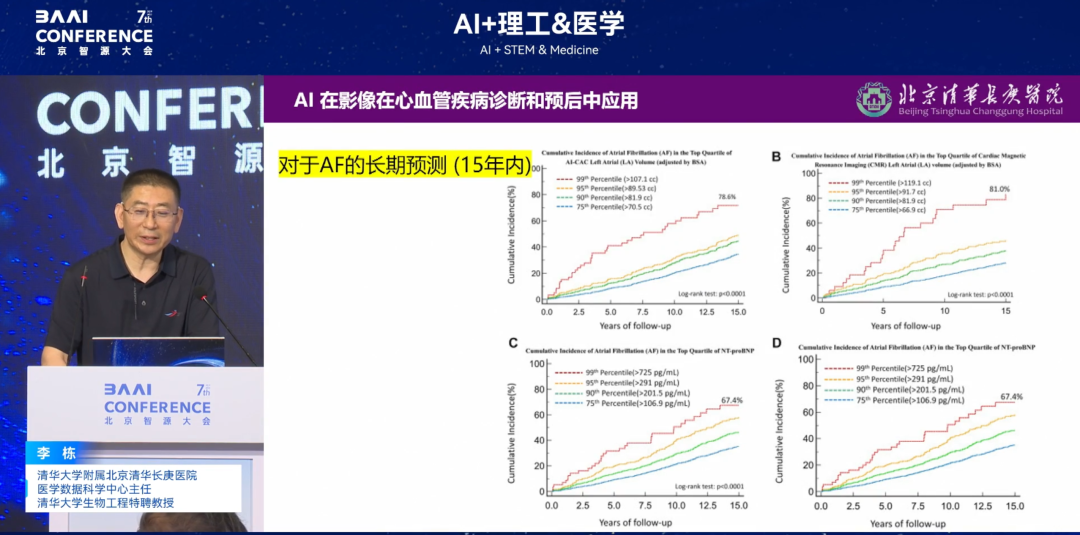
Allant plus loin,Nous avons proposé une deuxième hypothèse : « Outre les courbes ECG et la fréquence cardiaque, peut-on prédire précocement les arythmies ? La contraction/relaxation des quatre cavités cardiaques est-elle impliquée dans les arythmies ? Si oui, peut-on la prédire ? »Après vérifications complémentaires, le « modèle cardiaque complet », qui intègre des données multidimensionnelles telles que les fonctions cardiovasculaires, nerveuses et musculaires, peut « emballer » le cœur grâce à des algorithmes. Les résultats finaux montrent que l'intégration de toutes les données de la fonction cardiaque pour prédire le risque d'arythmie permet de prédire avec précision le risque de maladie jusqu'à 15 ans. Les résultats pertinents ont été publiés dans une sous-revue du JACC (facteur d'impact 24+).
* Titre de l'article :La volumétrie de la chambre cardiaque par tomodensitométrie assistée par IA prédit la fibrillation auriculaire et l'AVC de manière comparable à l'IRM
* Adresse du document :https://www.jacc.org/doi/abs/10.1016/j.jacadv.2024.101300
Recherche sur le diabète : du « spectre des complications » au « mécanisme causal »
Une autre étude est une analyse de réseau de maladies basée sur un modèle à grande échelle. Auparavant, on pensait que le diabète à début précoce (avant 40 ans) était moins grave que le diabète à début normal. Par exemple, une personne qui développe un diabète à 20 ans peut avoir une tension artérielle et des lipides sanguins normaux et ne présenter aucune complication à 30 ans, tandis qu'une personne qui développe un diabète à 40 ans peut présenter des indicateurs anormaux et d'autres maladies à 50 ans. Cependant, l'étude du spectre des complications du diabète dans l'ensemble de l'organisme a révélé queLes interactions systémiques des complications du diabète à début précoce sont plus intenses et il existe des associations de voies vectorielles, qui sont différentes de la cognition inhérente des individus.
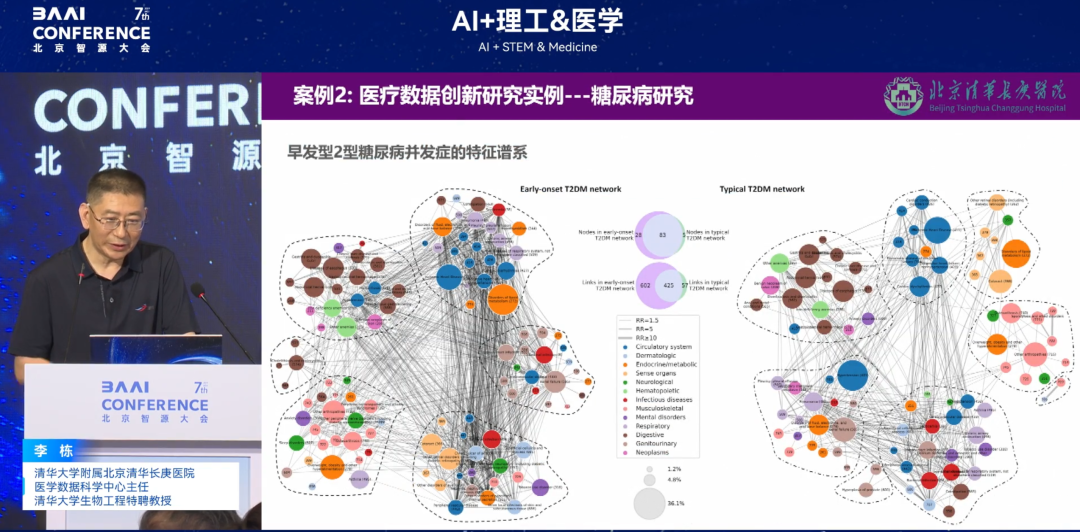
(À gauche : diabète à début précoce ; à droite : diabète normalement diagnostiqué ; chaque cercle de couleurs différentes représente un système différent)
Perspectives d'avenir : un nouveau paradigme pour les soins de santé à l'ère de l'intelligence des données
Ces dernières années, l'IA médicale chinoise s'est accélérée. Comme l'a déclaré l'académicien Li Guojie : « L'humanité est désormais à l'ère de l'information et évolue vers l'ère de l'intelligence. Le paradigme de la recherche scientifique intelligente a émergé et pourrait devenir le cinquième paradigme de la recherche scientifique. Nous ne pouvons pas nous tromper dans notre compréhension de l'époque. Si nous manquons l'occasion de cette transformation, nous subirons un coup historique de réduction dimensionnelle. »
À l’avenir, nous devrons travailler sur les domaines suivants :
* Niveau docteur :Les données sont une tendance inévitable à l’avenir, et la coopération interdisciplinaire (combinant la médecine et l’ingénierie) est une condition nécessaire pour mener des recherches innovantes utilisant les données.Cultiver des talents amphibies « médicaux + données » est une priorité absolue.Les médecins doivent maîtriser certaines connaissances en IA (telles que l’évaluation des modèles et l’interprétation des données) afin de mieux collaborer avec les ingénieurs en algorithmes et les scientifiques des données pour améliorer l’effet d’application de l’IA dans les soins de santé.
* Niveau de l'algorithme :Aujourd'hui, les modèles basés sur les données sont confrontés à des coûts de formation élevés. À l'avenir, nous espérons développer des modèles légers, mieux adaptés aux scénarios médicaux.Abaisser le seuil de puissance de calcul et améliorer l’interprétabilité et la fiabilité de l’application clinique de l’algorithme.En particulier, cela augmentera l’acceptation de l’IA parmi les médecins et les patients et intégrera l’IA dans les soins médicaux.
* Niveau hospitalier :En l'absence d'idées de recherche pertinentes et en manque d'innovation, autant commencer par les données et exploiter les dernières méthodes de recherche en sciences de l'information. Les hôpitaux doivent donc encourager et soutenir activement la recherche scientifique. Les salles de données doivent être équipées des infrastructures informatiques, de stockage, de réseau, de sécurité et autres nécessaires pour fournir des services essentiels à l'innovation médicale au niveau des données.
Bien que le modèle global ne soit pas la panacée, la réflexion sur les données qui le sous-tend redéfinit l'essence même de la médecine. Lorsque nous apprendrons véritablement à raconter des histoires avec les données et à trouver des réponses grâce aux algorithmes, nous pourrons intégrer en profondeur « intelligence des données et essence médicale » pour prendre l'initiative de l'innovation médicale et faire en sorte que la médecine intelligente serve véritablement les patients et contribue à la société.
À propos du professeur Li Dong
Le professeur Li Dong, docteur en médecine, est un expert de renommée internationale en science des données médicales. Il est actuellement directeur du Centre de science des données médicales de l'hôpital Tsinghua Chang Gung de Pékin, affilié à l'université Tsinghua, et professeur émérite de bio-ingénierie à cette même université. Le professeur Li Dong a été le premier directeur chinois du Centre de recherche clinique du Harbor Medical Center de l'université de Californie à Los Angeles, et a été nommé professeur émérite à l'hôpital de Chine occidentale de l'université du Sichuan.

Le professeur Li Dong a publié plus de 100 articles scientifiques scientifiques dans des revues universitaires internationales de premier plan, qui ont été cités près de 4 000 fois au cours des cinq dernières années. Il a également publié plus de 220 résumés de conférences universitaires. Il a également été invité à donner plus de 40 conférences universitaires, a participé à la rédaction de quatre monographies universitaires et est titulaire de deux brevets d'invention.
Ses recherches couvrent un large éventail de domaines, notamment la conception, la mesure et l'évaluation de la recherche clinique, l'analyse de modélisation, l'exploration de données médicales et l'application de l'intelligence artificielle en médecine. Fort d'une vaste expérience dans la direction d'équipes de recherche clinique chargées de l'exploration de données médicales massives et du développement de systèmes intelligents d'analyse des décisions médicales, il est une autorité reconnue dans ce domaine.








