Command Palette
Search for a command to run...
Tutoriel En Ligne : Actualisation Du Modèle TTS SOTA, OpenAudio S1 Est Formé Sur La Base De 2 Millions d'heures De Données Audio, Comprenant En Profondeur Les Émotions Et Les Détails De La Parole

Ces dernières années, le modèle TTS (Text-to-Speech) a connu de nombreuses évolutions, passant de la synthèse vocale concaténée à la synthèse statistique des paramètres, puis à la synthèse vocale neuronale. Il a montré une tendance à la fusion de bout en bout et de modules au niveau technique, et a démontré un effet amélioré en termes de multilinguisme, de naturalité et de richesse émotionnelle au niveau applicatif.
Les modèles TTS étant largement utilisés dans les assistants vocaux virtuels, les humains numériques, le doublage IA, le service client intelligent et d'autres domaines, la demande de l'industrie en matière de retour d'information en temps réel augmente progressivement.Vient ensuite le compromis entre la vitesse d’inférence et les paramètres du modèle.Ce dernier limite dans une certaine mesure le coût de déploiement et les scénarios d’application du modèle TTS.
Compte tenu de cela,Fish Audio a lancé un nouveau modèle TTS open source, OpenAudio S1.Il comprend deux versions : OpenAudio-S1 et OpenAudio-S1-mini. Selon la documentation officielle, OpenAudio S1 est entraîné sur un ensemble de données à grande échelle de plus de 2 millions d’heures audio. L’équipe a étendu les paramètres du modèle à 4 milliards et a introduit un mécanisme de modélisation de récompense développé en interne. Parallèlement, elle a également appliqué l’apprentissage par renforcement basé sur le retour d’information humain (RLHF, selon la méthode GRPO).
Sur cette base, OpenAudio S1 élimine avec succès les artefacts et le vocabulaire incorrect causés par la perte d'informations lorsque la plupart des autres modèles utilisent des modèles uniquement sémantiques, surpassant ainsi de loin les modèles précédents en termes de qualité audio, d'expression émotionnelle et de similitude des locuteurs.Une sortie TTS de haute qualité peut être générée avec seulement 10 à 30 secondes d'échantillon vocal en entrée.Il est actuellement en tête du classement d'évaluation subjective humaine HuggingFace TTS-Arena-V2, atteignant un faible CER (taux d'erreur de caractère) d'environ 0,4% et un WER (taux d'erreur de mot) d'environ 0,8% sur Seed-TTS Eval.
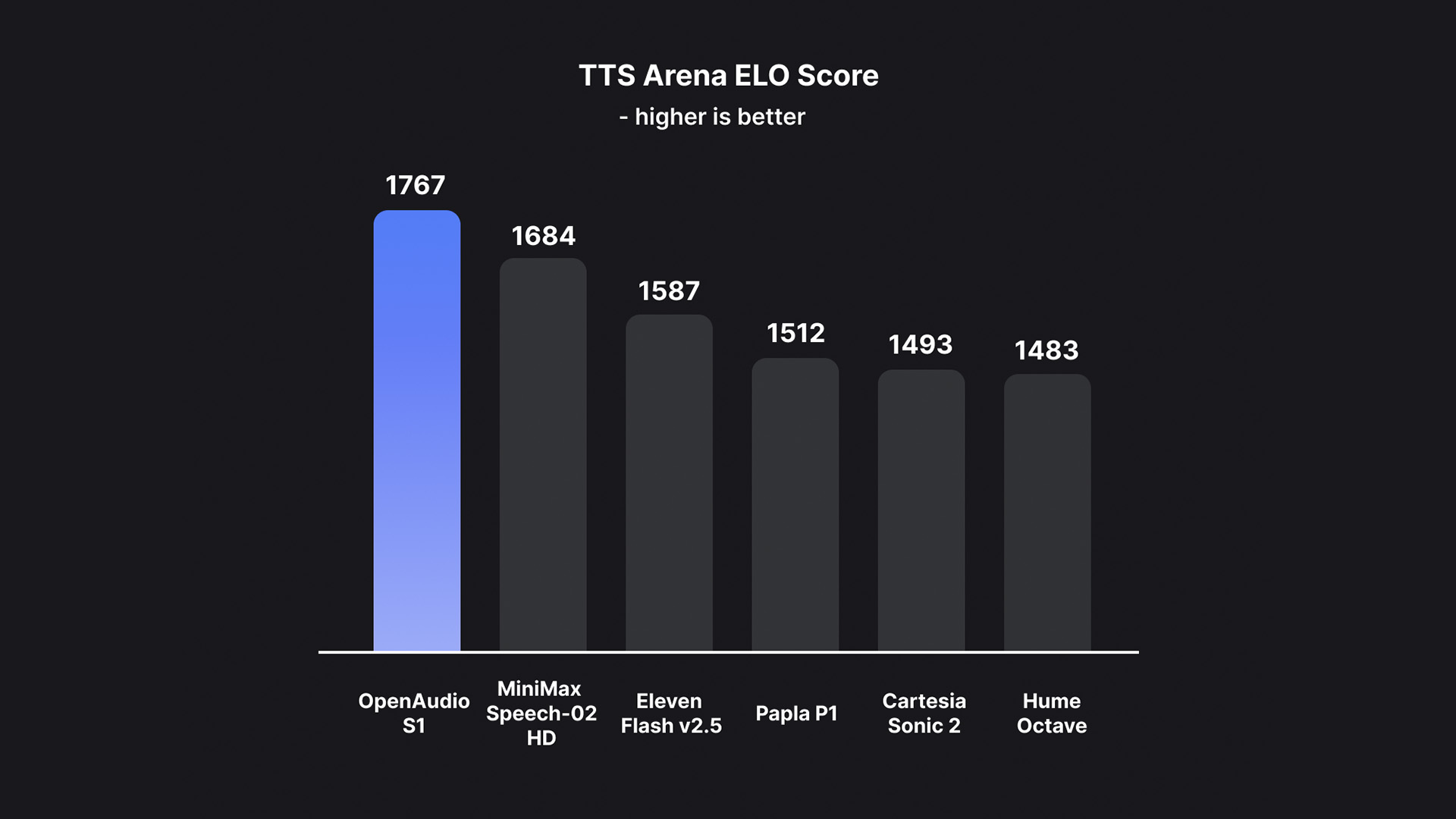
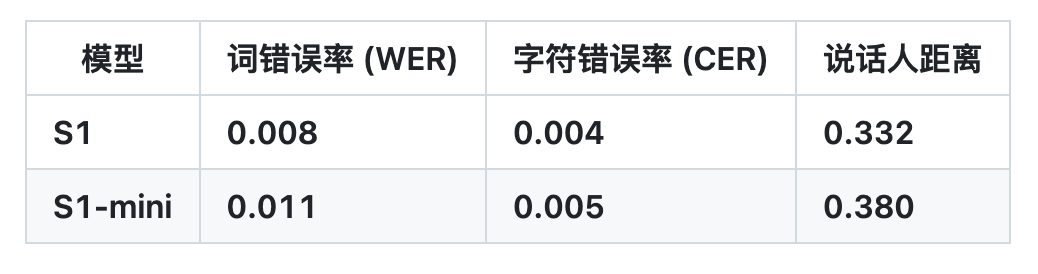
Selon l'équipe,Ce qui rend OpenAudio S1 vraiment unique, c'est sa capacité à comprendre et à exprimer en profondeur les émotions humaines et les détails de la parole.Il prend en charge un riche ensemble de balises pour un contrôle précis de la parole synthétisée. Afin d'entraîner le modèle TTS à suivre des instructions, l'équipe a également développé un modèle de conversion de la parole en texte (bientôt disponible) capable de générer des sous-titres audio contenant des émotions, l'intonation, des informations sur le locuteur, etc. Plus de 100 000 heures d'audio ont été annotées aléatoirement à partir de ce modèle pour entraîner OpenAudio S1.
C'est pourquoi OpenAudio S1 prend en charge de multiples émotions, intonations et marqueurs spéciaux pour améliorer la synthèse vocale. Outre les émotions de base comme la colère, la surprise et la joie, il prend également en charge des émotions plus complexes comme le mépris, le sarcasme et l'hésitation. Concernant l'intonation, il prend en charge les chuchotements, les cris, les sanglots, etc. Concernant les langues, l'anglais, le chinois et le japonais sont actuellement pris en charge.
Ce qui mérite d’être mentionné davantage, c’est qu’en termes d’équilibre entre performance et coût de déploiement,L'équipe affirme qu'il s'agit du premier modèle SOTA qui ne coûte que 15 $ par million d'octets ($15/million d'octets, environ 0,8 $/heure).
Afin de permettre à chacun de profiter plus rapidement des puissantes performances d'OpenAudio S1,La section tutoriel du site officiel d'HyperAI (hyper.ai) a maintenant lancé « OpenAudio-s1-mini : outil efficace de génération de texte en parole ».
Lien du tutoriel :https://go.hyper.ai/rVvkS
Nous avons également préparé des avantages pour l'utilisation gratuite des ressources RTX 4090 pour les nouveaux utilisateurs inscrits. Utilisez le code d'invitation ci-dessous pour vous inscrire et découvrir gratuitement des modèles TTS de haute qualité.
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
Essai de démonstration
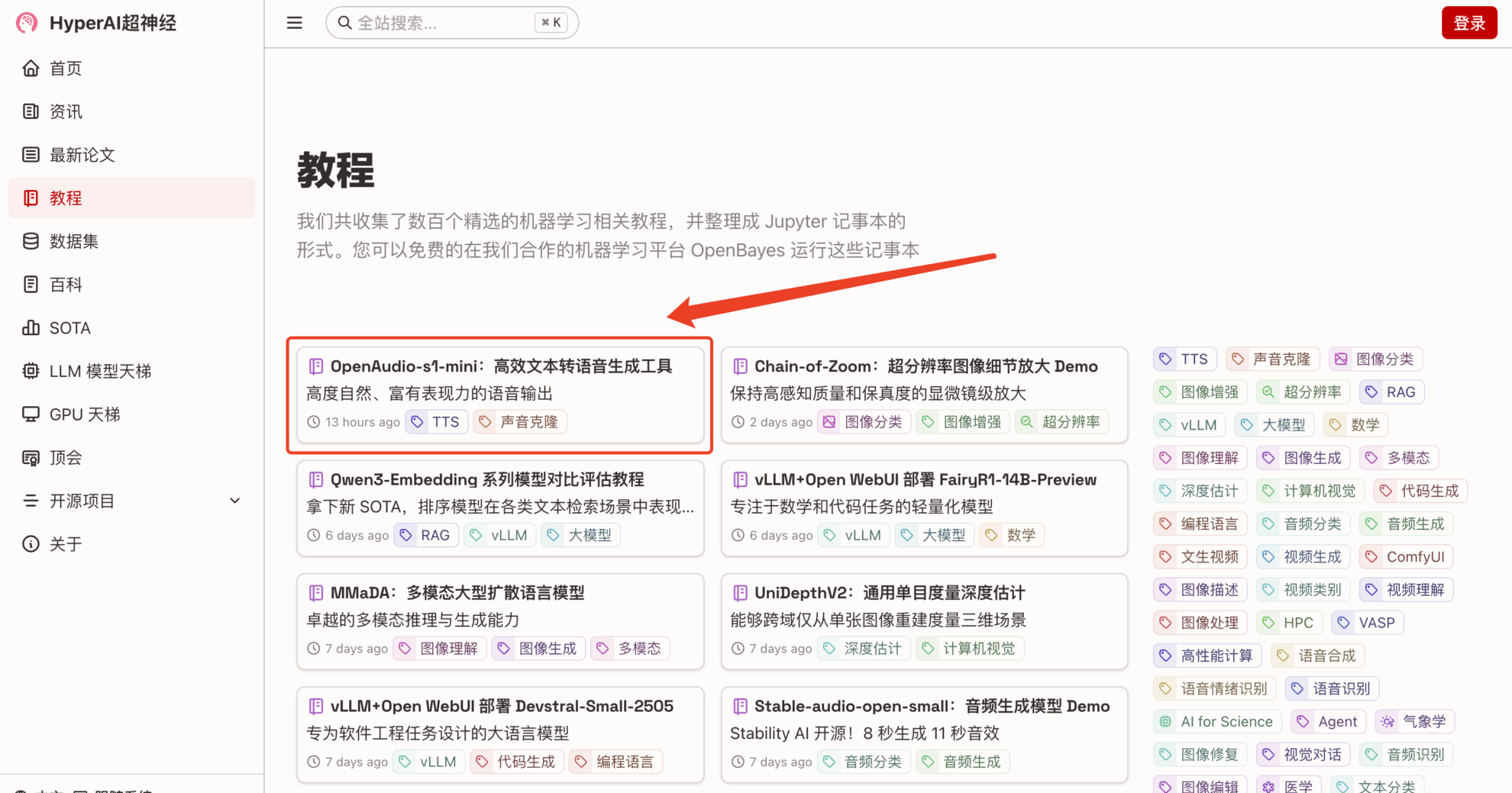
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez la page « Tutoriel », sélectionnez « OpenAudio-s1-mini : outil efficace de génération de texte en parole » et cliquez sur « Exécuter ce tutoriel en ligne ».
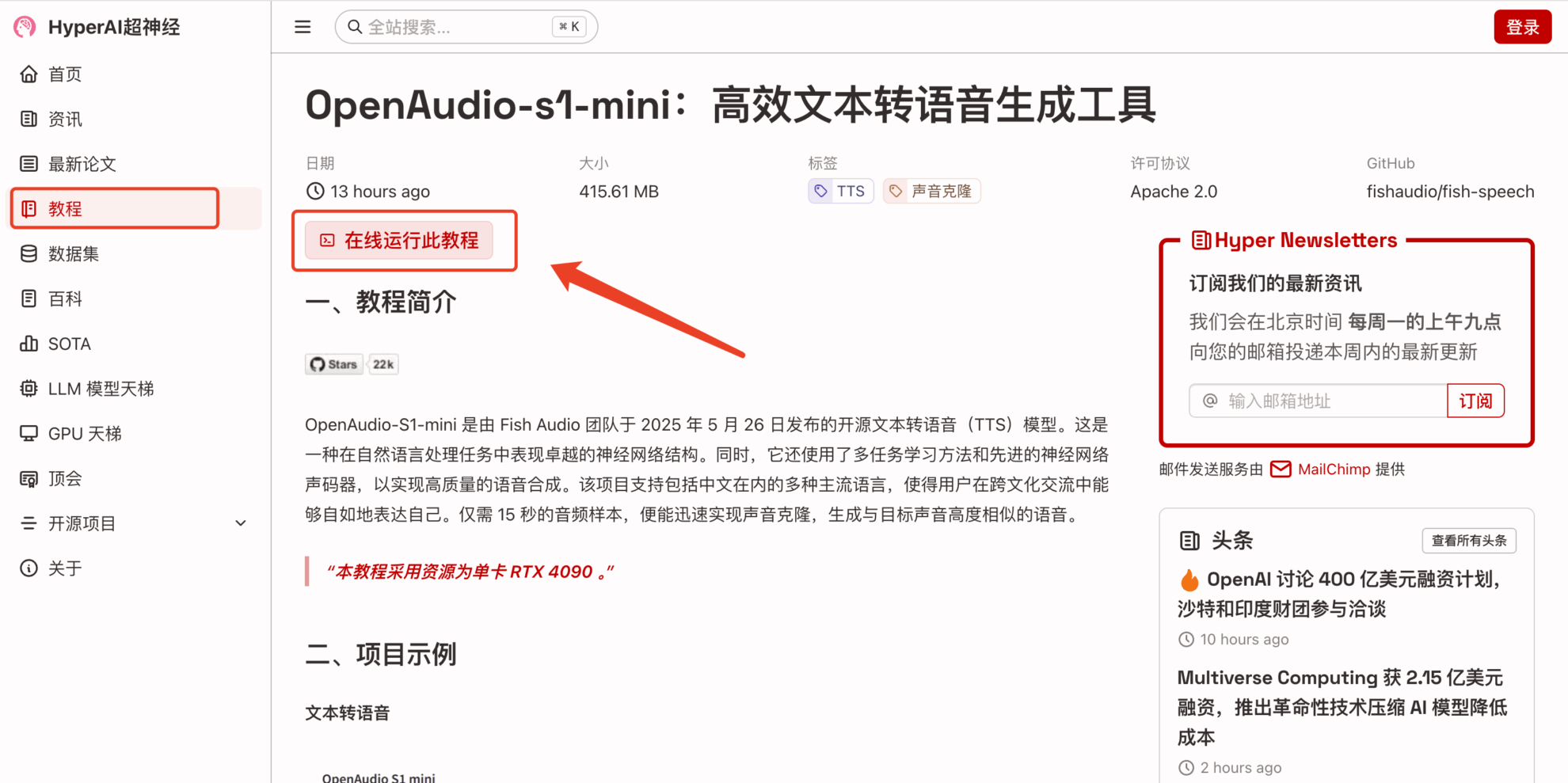
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
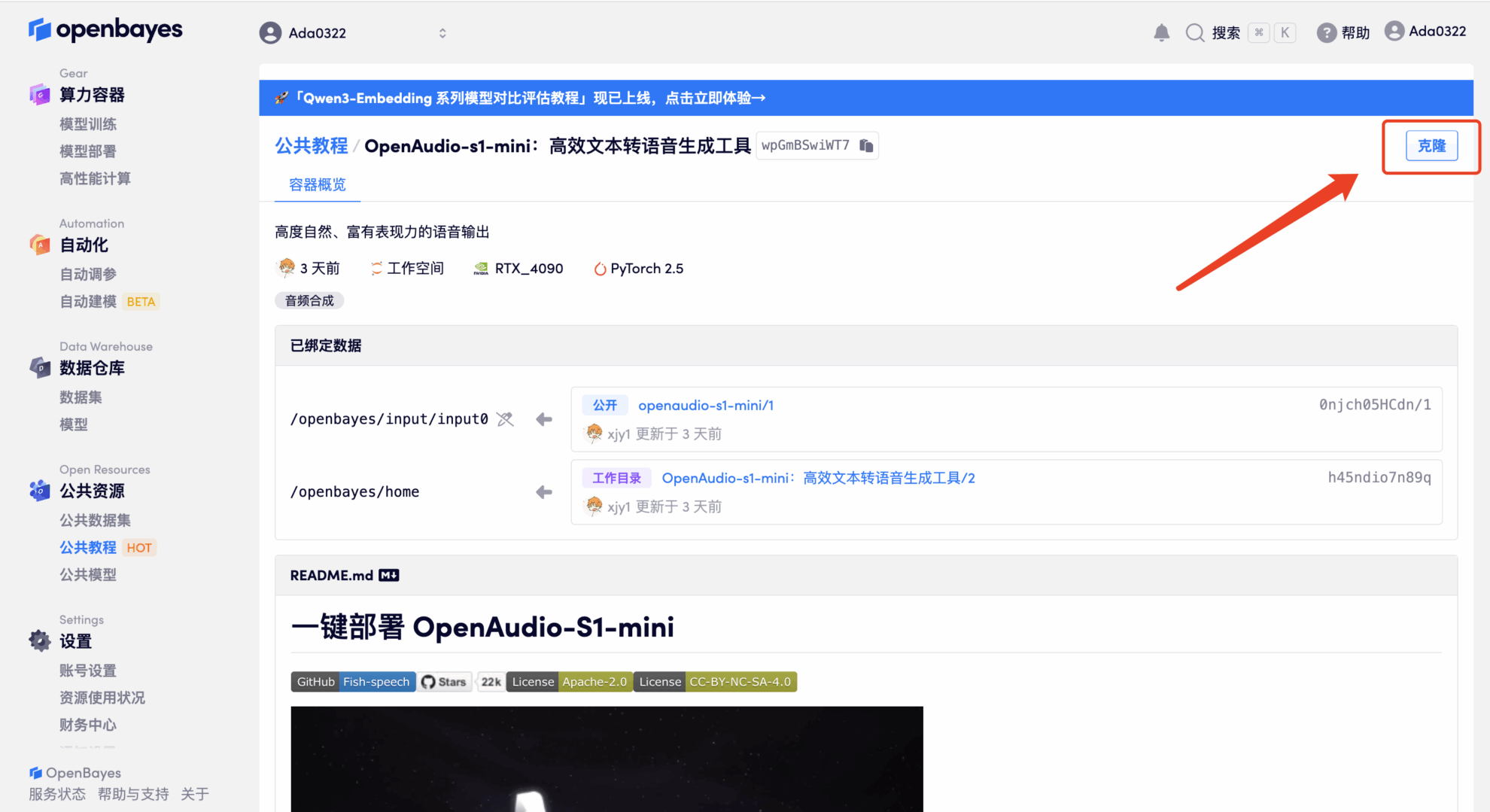
3. Sélectionnez les images « NVIDIA RTX 4090 » et « PyTorch ». La plateforme OpenBayes propose quatre modes de facturation. Vous pouvez choisir entre « Paiement à l'utilisation » ou « Paiement journalier/hebdomadaire/mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire via le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 et 5 heures de temps processeur gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
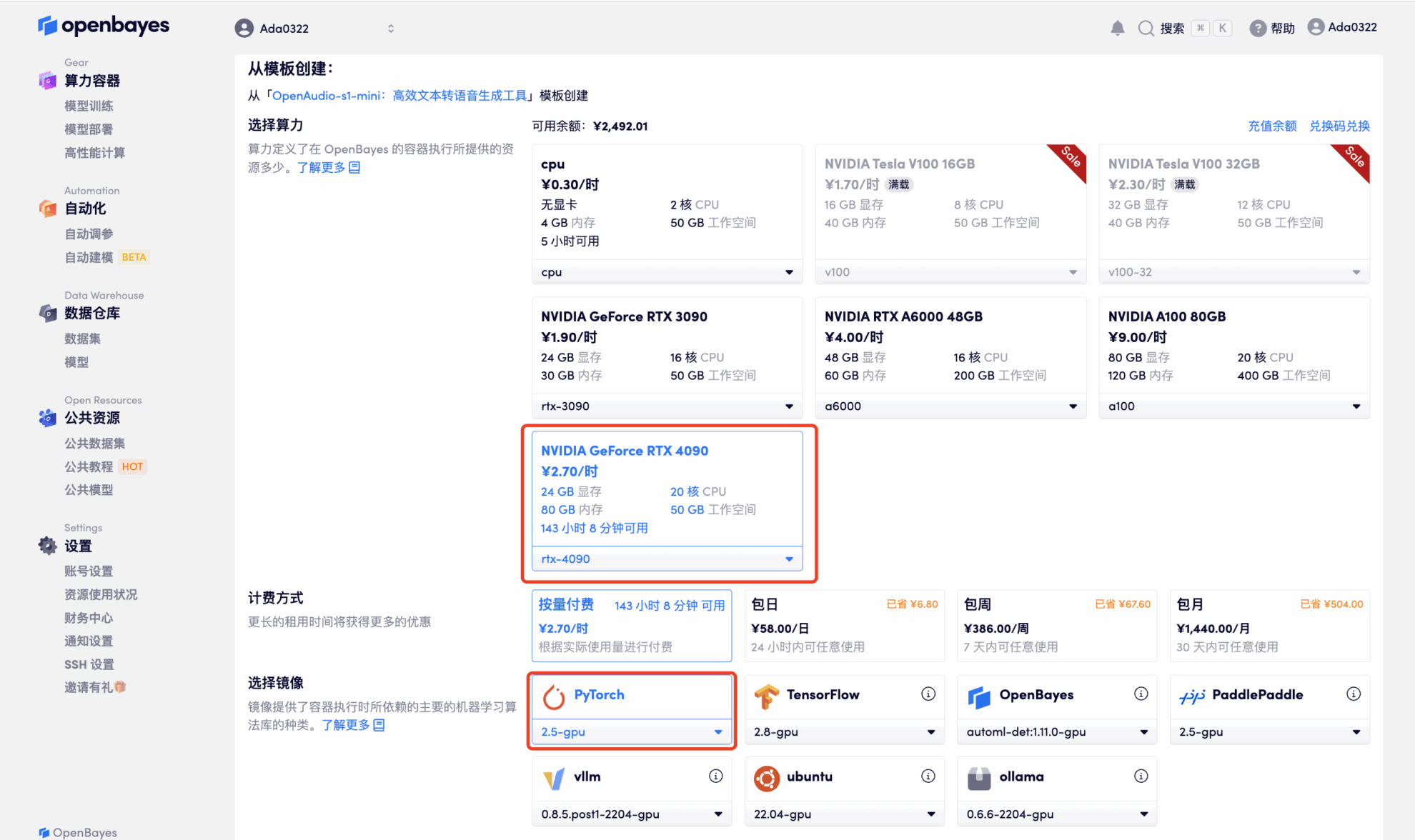
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Étant donné que le modèle est volumineux, il faut environ 3 minutes pour afficher l'interface WebUI, sinon « Bad Gateway » s'affichera. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
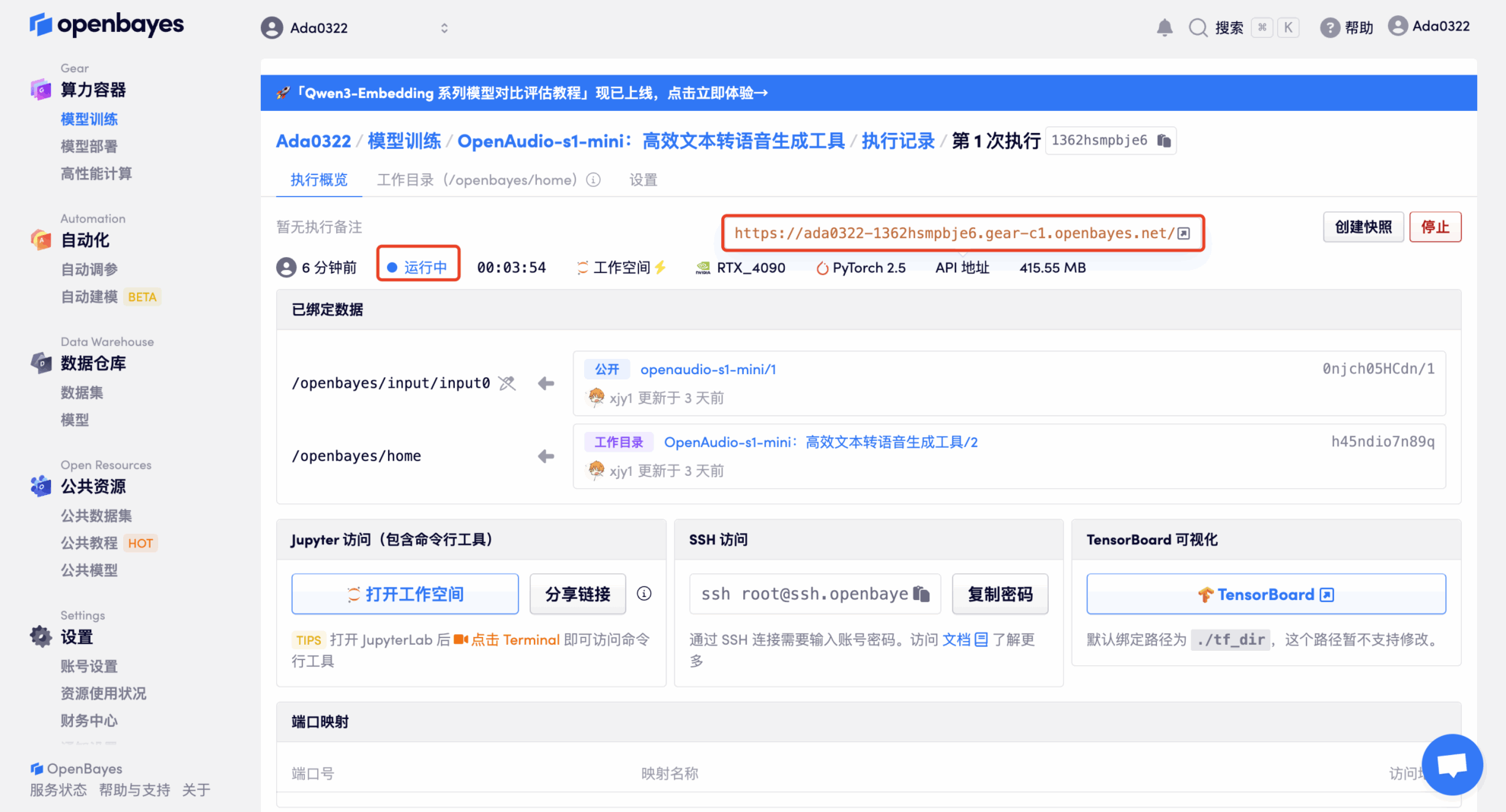
Démonstration d'effet
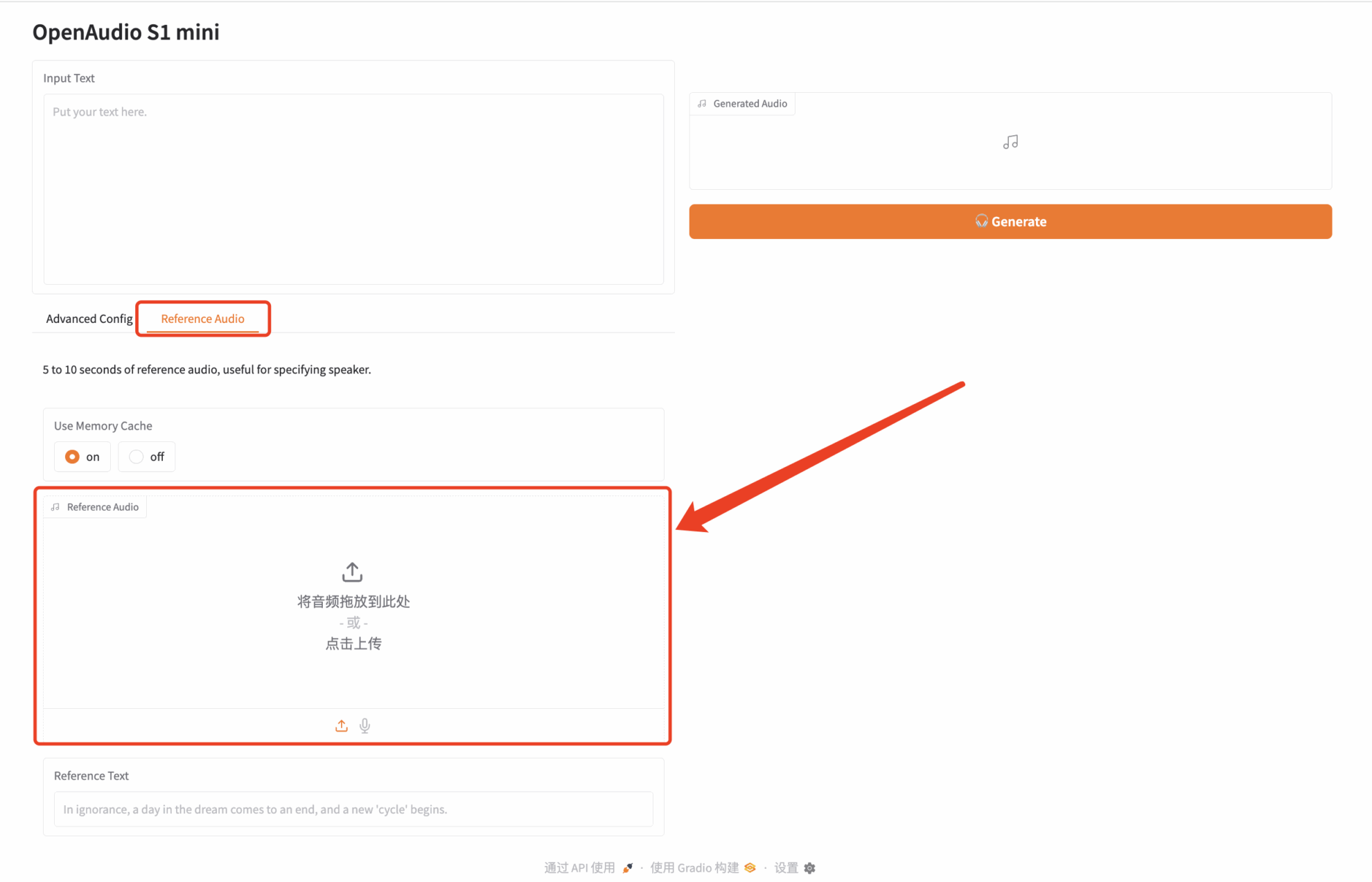
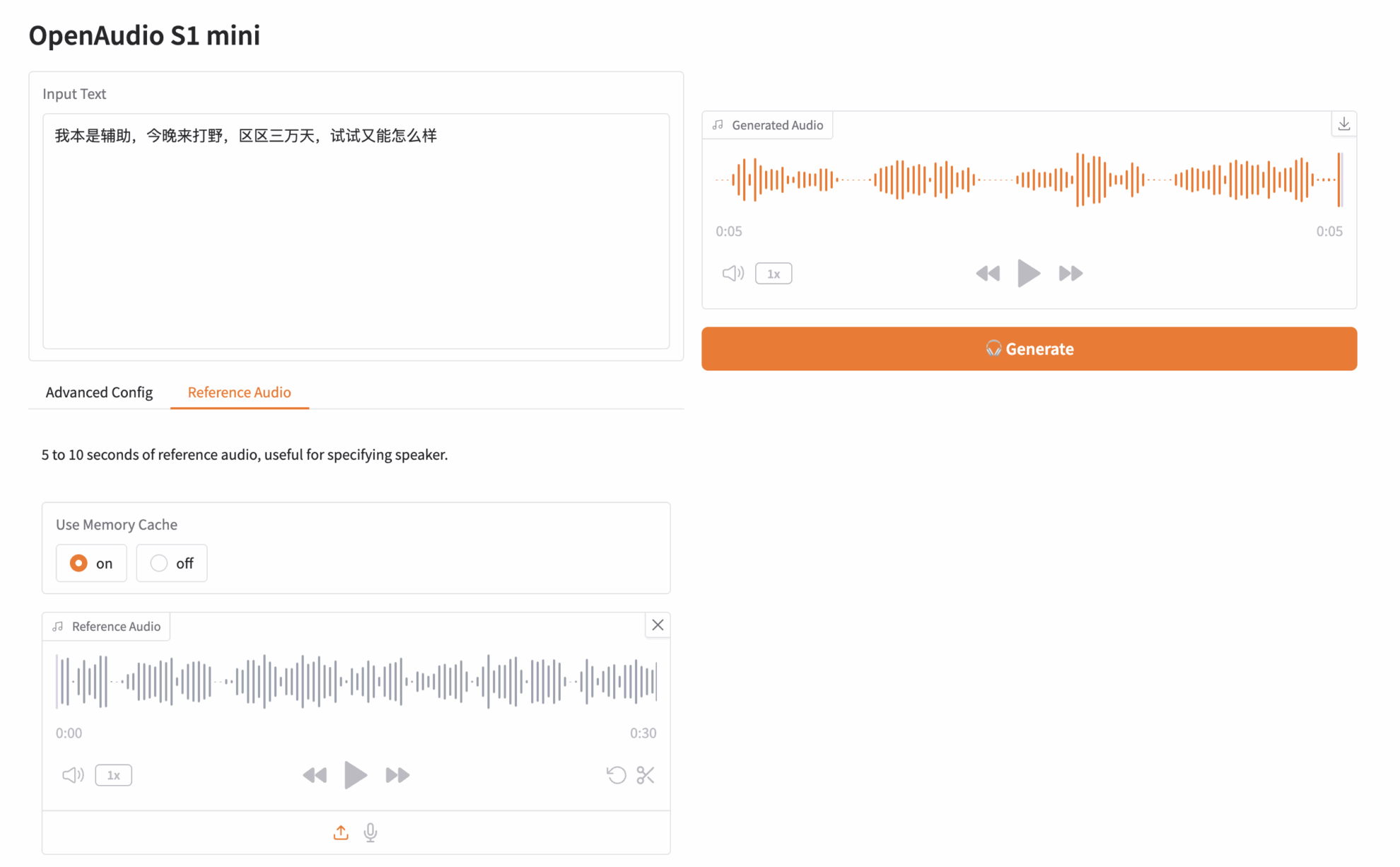
Cliquez sur « Adresse API » pour découvrir le modèle. J'ai téléchargé un extrait audio de « Paimon », un personnage de Genshin Impact. Le texte saisi est le suivant :
J'étais initialement support, mais je suis venu ce soir pour jouer à la jungle. On n'est que dans 30 000 jours, alors quel mal y a-t-il à essayer ?
Ensuite, cliquez sur Générer à droite pour générer l'audio :
Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. N'hésitez pas à le découvrir en ligne :








